谷歌AlphaGenome破解98%基因非编码区,精准预测基因突变影响,为理解生命“逻辑”提供新视角。
原文标题:刷屏 Nature!人类终于读懂 98% 的基因暗物质
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、AlphaGenome在癌症突变预测中表现出色,成功预测了T细胞白血病中一个危险基因的激活路径。那么,这项技术在癌症治疗方面有哪些潜在应用?除了预测突变,它还能在哪些方面帮助我们对抗癌症?
3、AlphaGenome被称为“基因组版AlphaGo”,你觉得这个比喻恰当吗?AI在生命科学领域的应用,除了AlphaFold和AlphaGenome,未来还会有哪些突破性的发展方向?
原文内容

来源:新智元本文约2600字,建议阅读5分钟
本文介绍了谷歌 AlphaGenome 登 Nature 封面,破解 98% 基因非编码区并精准预测基因突变影响。
谷歌AlphaGenome登上了Nature封面!

去年5月,谷歌DeepMind重磅发布了新一代「阿尔法」模型——AlphaGenome。
它可一次性「读入」100万个DNA碱基对,并预测任何基因突变如何改变分子的功能。
AlphaGenome不仅限于单个基因预测,而是贯穿了整个调控基因组。

论文地址:https://www.nature.com/nature/volumes/649/issues/8099
若要回答「某个基因的活性是会增强还是减弱」这一问题,生物学家们需要在实验室中,往往耗费数月进行重复实验。
如今,AlphaGenome只需读入一段DNA序列,提取调控基序与表征活性,便可对数千种分子特性高度预测。
谷歌科学家表示,这类非编码基因组占DNA 98%,对人类健康和疾病至关重要。

AlphaGenome已在GitHub开源:https://github.com/google-deepmind/alphagenome_research
诺奖得主、DeepMind掌门人Demis Hassabis更是放出豪言:「未来十年,AI将治愈所有疾病」。
AlphaGenome的横空出世,堪称「基因组版AlphaGo」,正以颠覆性计算范式重构生命科学的底层逻辑。
评论区下方,网友激动表示,「自然遗留的代码」终于有了合适的代码检查工具。

AlphaGenome荣登Nature封面
基因组,是深植于每个细胞核心的生命底层代码。
这套宏大的DNA指令集,不仅精准勾勒出我们的外貌与机能,更在幕后操控着生长、繁衍乃至抵御疾病的每一处细节。
2003年,人类基因组计划宣告完成,我们首次窥见了这本「生命之书」的全貌。

然而,那些深藏在双螺旋间的遗传密码始终未被唤醒:
一个碱基的微小错位如何引发生命的巨震,依旧是生命科学研究的核心议题。
6年前,AlphaFold的诞生以海啸般的势头席卷生物界,连续斩获Nature、Science年度十大科学突破。
从初代AlphaFold到AlphaFold 3,精准预测了98.5%人类蛋白质结构。
它更用2024年的诺贝尔奖证明了,AI正在接管生物学的未来。

最新AlphaGenome,再一次拓展了AI在DNA领域的研究。
人类基因约有30亿个碱基,但其中只有不到2%的序列,用于编码蛋白质,其余98%被称为非编码区。
然而,它们对调控基因的活性至关重要,并包含了大量与疾病相关的变异位点。
直到现在,生物学家实际上无法看清它是如何运作的。
AlphaGenome正是为解读这些广阔的非编码序列及其内部变异,提供了全新的视角。
一次100万对,90%精准预测
从论文角度,一起拆解下AlphaGenome背后工作原理。

总言之,AlphaFold解决了蛋白质折叠问题,AlphaGenome则研究接下来的问题——
DNA实际上是如何控制基因的?
当前,问题的核心是:98%的人类基因突变其实发生在基因之外,也就是那些负责调控基因在何时、何地、以及表达多少的「调控区」。
科学家们很清楚,这些区域至关重要。
可问题是,想要预测这些区域里的某个特定突变到底会起什么作用,难度可就直接翻倍了。

为什么会如此困难?
因为某个位置的一个小突变,可能会影响到远在50万个「字母」(letters)之外的基因。
以前的AI工具不得不做「单选题」:要么看得远,但视野模糊;要么看得清,但只能盯着附近那一小部分地方。
也就是说,鱼和熊掌,过去的AI还没法兼得。还有一个问题是,目前的工具都是「专才」。
想知道突变是否影响基因表达?用一个模型剪接(Splicing),用另一个染色质(Chromatin),再换一个.....
但基因突变并不只影响单一环节,生物学是环环相扣的。
基于谷歌之前的Enformer模型,AlphaGenome这次一口气解决了上述两个痛点:
-
既能「望远」也能「微距」:它能一次性吞掉100万个DNA字母,而且预测精度依然能细化到每一个字母。
-
从「偏科生」变成「全才」:基因表达、剪接、染色质状态、蛋白质结合——这些复杂的生物过程,现在只需这一个模型就能同时搞定。
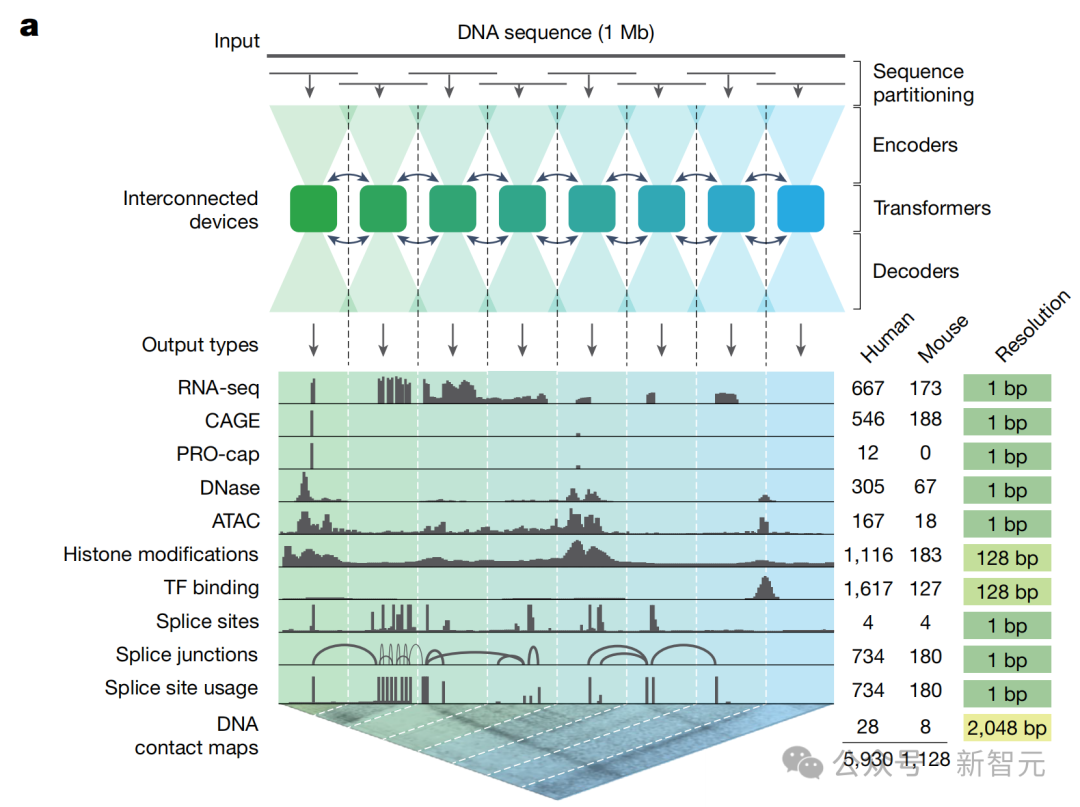
战果一:更擅长预测突变如何影响基因活性
在90%的准确率下,之前的最佳模型发现了19%已知变异位点,AlphaGenome直接找出了41%,性能足足提升一倍多。
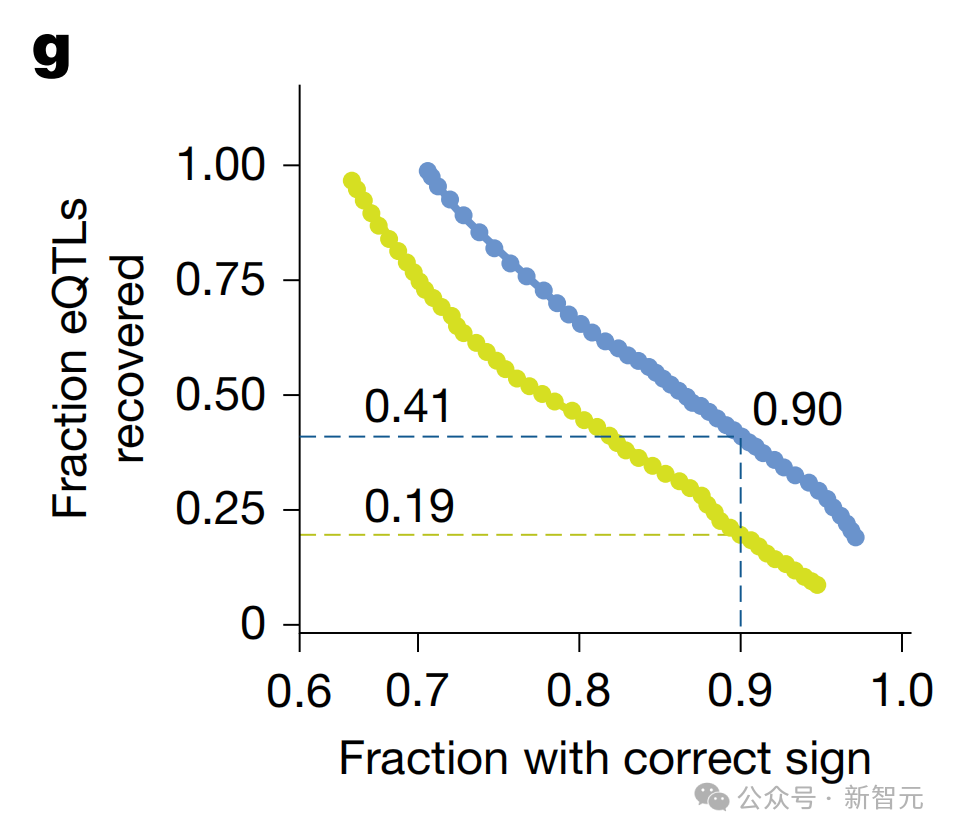
战果二:精准识别破坏「剪接」的突变
所谓的「剪接」(Splicing),其实就是细胞在给基因片段搞「剪剪贴贴」,最后拼成一份能指导生命活动的最终指令。
如果这一步搞错了,拼出来的蛋白质就是个「报废品」。别小看这些错误,它们导致了大约15%遗传病。
而在这一领域的七项权威基准测试中,AlphaGenome在其中6项都拿到了第一,完全碾压了现有的工具。
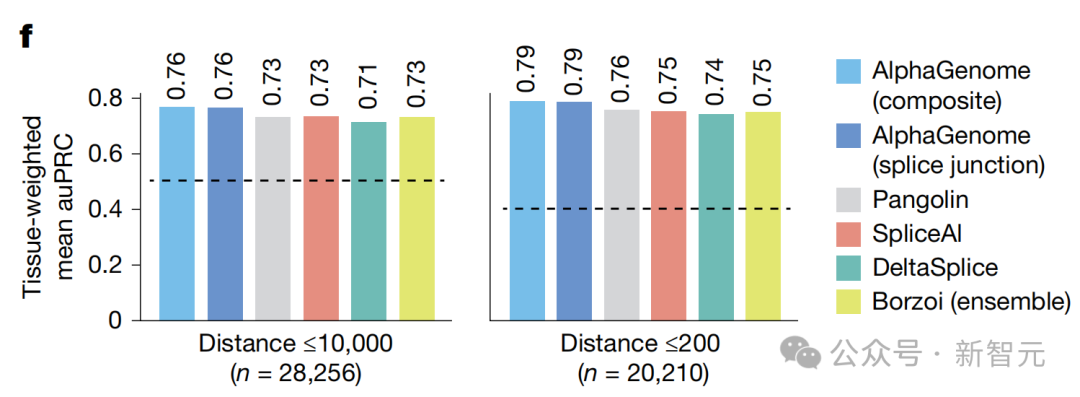
战果三:更精准地预判DNA的「封装」变化(染色质)
DNA紧紧地缠绕在蛋白质周围,松开它,基因就能开启。收紧它,基因就保持关闭。
在预测突变何时改变这一过程方面,AlphaGenome的表现优于专业工具。
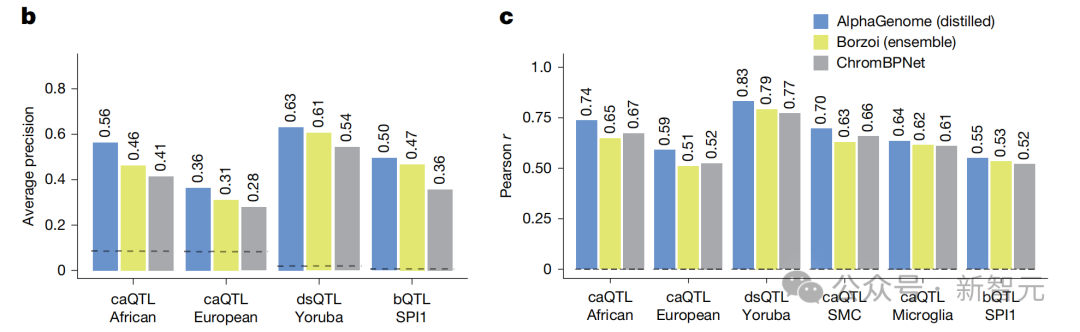
战果四:在「实战」中精准预判癌症突变
为了验证真本事,研发团队拿真实的癌症突变给AlphaGenome来了场「实战演习」。
在T细胞白血病中,某些特定的突变会像合上电闸一样,意外激活一个极其危险的基因——TAL1。
AlphaGenome不仅准确预测出了这种激活的具体路径,而且其预测结果与科学家在实验室里忙活多年才得出的结论完全吻合。
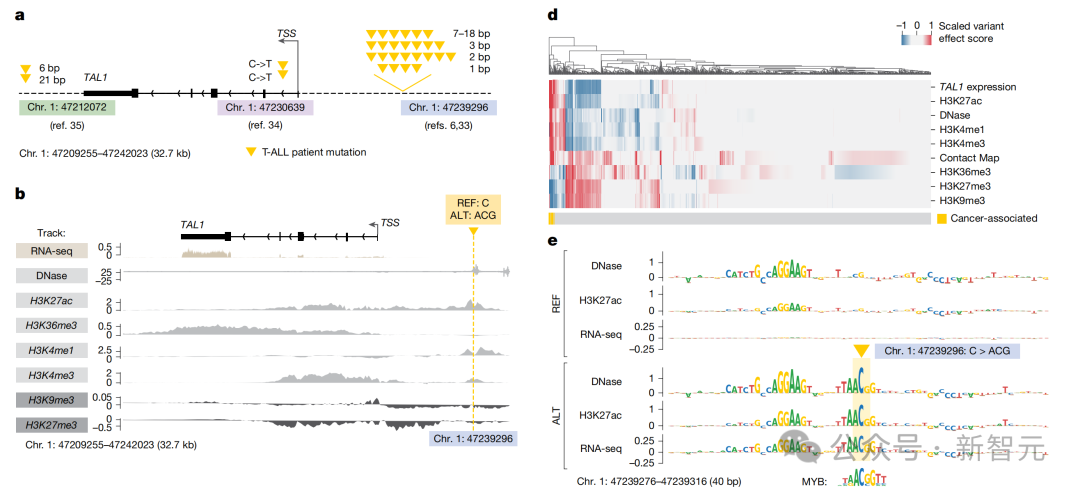
和去年五月论文不同之处,研究科学家给出了以下两点:

有网友对此表示,AlphaGenome的出现让科学家们离读懂人类基因组又近了一步。
破译「生命源代码」,2年搞定
谷歌DeepMind还出了一期AlphaGenome的访谈,科学家Žiga Avsec和背后团队坐在一起,阐述了新模型背后的故事。
团队打造一款统一的DNA序列-功能预测模型,其初衷便是预测遗传变异的功能影响。
他们希望,AI可以最终译被称为「生命源代码」的DNA序列,这对人类健康和罕见病诊断具有重要意义。
AlphaGenome的出世恰恰填补了这一空白。

AI 要做的事情之一,是把序列变化与细胞里的分子机制变化连接起来,尤其要回答「一个小小的变异会带来什么后果」。
这背后有一个长期痛点:大量罕见遗传病患者仍旧没有明确诊断线索,研究和临床经常卡在「看见变异、读不懂影响」。
同时,人类基因组里编码蛋白的区域只占很小部分,更多变异发生在非编码区。
AlphaGenome把关注点放在这片「基因组的绝大部分」,试图让非编码区的功能影响也能被系统地预测。

那么,为什么要做一个统一的「序列-功能」(sequence-to-function)的模型?
访谈中,他们提到过往路线:此前有Enformer,行业里也出现了不少同类工作,还有大量针对单任务的模型,分别解决剪接、可及性、3D互作等问题。
而AlphaGenome试图解决的是「拼模型」的成本与缺口:
-
需要覆盖更多模态(更多类型的生物学读数)
-
输入序列要足够长,能看到远距离调控
-
输出要足够细,能落到单碱基层级解释
它把这几件事放进一个框架里,让研究者不用在不同模型之间来回切换,也更容易把变异影响放到更完整的上下文里理解。
更关键的是,AlphaGenome从午餐灵感到论文发布,周期不到两年。

从AlphaFold揭示生命的「形态」,到AlphaGenome破译生命的「逻辑」,我们正身处一场前所未有的范式转移之中。
AlphaGenome把曾经一度被视为「暗物质」的98%非编码区,变成了生命最精密的调控阀门。
这一次,人类不仅是在观察生命,更是在理解生命的运行代码。
参考资料:
https://x.com/GoogleDeepMind/status/2016542480955535475
https://www.nature.com/nature/volumes/649/issues/8099
https://deepmind.google/blog/alphagenome-ai-for-better-understanding-the-genome/
https://x.com/DrDominicNg/status/2016626988031889836?s=20
编辑:于腾凯
校对:杨学俊
