人形机器人真机强化学习新范式:LIFT框架通过大规模预训练和物理信息增强的世界模型,实现安全高效的真机微调,解决传统方法在真实世界中学习的难题。
原文标题:人形机器人的真机强化学习! ICLR 2026 通研院提出人形机器人预训练与真机微调新范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、物理信息增强的世界模型在 LIFT 框架中起到了什么作用?为什么它比纯粹的 Ensemble 网络更有效?
3、LIFT 框架在真机微调时,如何保证安全性和效率?确定性动作采集和世界模型探索是如何平衡的?
原文内容

目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?
目前主流仍然是大量域随机化的 Sim2Real 路线,“仿真里练到很强,上真机直接用”,一旦部署,策略网络往往就被冻结,真实世界大量未知的变化包括摩擦、载荷、温度、设备老化等都可能让机器人表现打折,系统通常只能回到仿真里重新调参或重训;而想在真机上再学习,又会面临两道门卡:安全(随机探索可能摔倒、损坏)和数据(真机交互昂贵、速度慢、次数有限),这使得机器人缺少真正意义上持续学习的能力。
来自北京通用人工智能研究院和西安电子科技大学的研究团队提出的 LIFT 给出了一条更现实的路径:先用离策略(Off-policy)强化学习算法 SAC(Soft Actor-Critic) 在仿真中进行大规模预训练,充分利用数据复用带来的样本效率;再在预训练数据之上学习一个物理信息增强(Physics-informed)的世界模型。
到了真实世界,机器人主要执行确定性、更可控的动作来采集数据与微调,把 “试错” 和 “探索” 尽可能放进世界模型里发生,从而在保证安全的前提下,用有限的真机交互下实现更快的微调与提升,绕开部分 sim2real 的硬瓶颈。
论文的第一作者黄维东是北京通用人工智能研究院的研究工程师,研究方向为强化学习和世界模型等,研究目标是构建在复杂环境中可高效持续学习的智能体,通讯作者为北京通用人工智能研究院的研究员张精文。

-
论文标题:Towards Bridging the Gap between Large-Scale Pretraining and Efficient Finetuning for Humanoid Control
-
论文主页:https://lift-humanoid.github.io/
-
论文链接:https://arxiv.org/abs/2601.21363
-
代码链接:https://github.com/bigai-ai/LIFT-humanoid
背景与动机:
人形机器人真机强化学习的不安全性
目前机器人界广泛依赖在策略(On-policy)算法 PPO (Proximal Policy Optimization)进行预训练。PPO 虽然在仿真中有较快的(Wall-time)收敛性能,但由于不能有效复用旧数据,并且依赖随机探索,这使其在真实人形机器人上做后续微调或持续学习几乎不可行:既不安全,也不经济。
传统强化学习中,有两种有潜力的方案:
-
离策略 RL(Off-policy RL)(如 SAC):能复用旧数据,提高样本效率;
-
基于世界模型的 RL(Model-based RL)(如 MBPO/ Dreamer):用模型生成数据减少真实交互。
但作者发现把这些方法直接搬到人形机器人的预训练和微调上会遇到新的瓶颈:
1. 确定性数据采集 + 数据多样性不足会让常规 off-policy /model-based 的训练变得不稳定或极慢;
2. 世界模型误差在人形高维接触动力学下更容易积累,导致生成的数据质量较差,难以被策略利用;
3. 若像 MBPO 或 Dreamer 那样 “边与环境交互边训练世界模型和策略,在数千并行仿真下 wall-time 代价不可接受。
因此核心问题是:能否既不牺牲大规模预训练速度,又能让微调阶段足够样本高效、并且安全可控?
LIFT:大规模预训练与高效微调
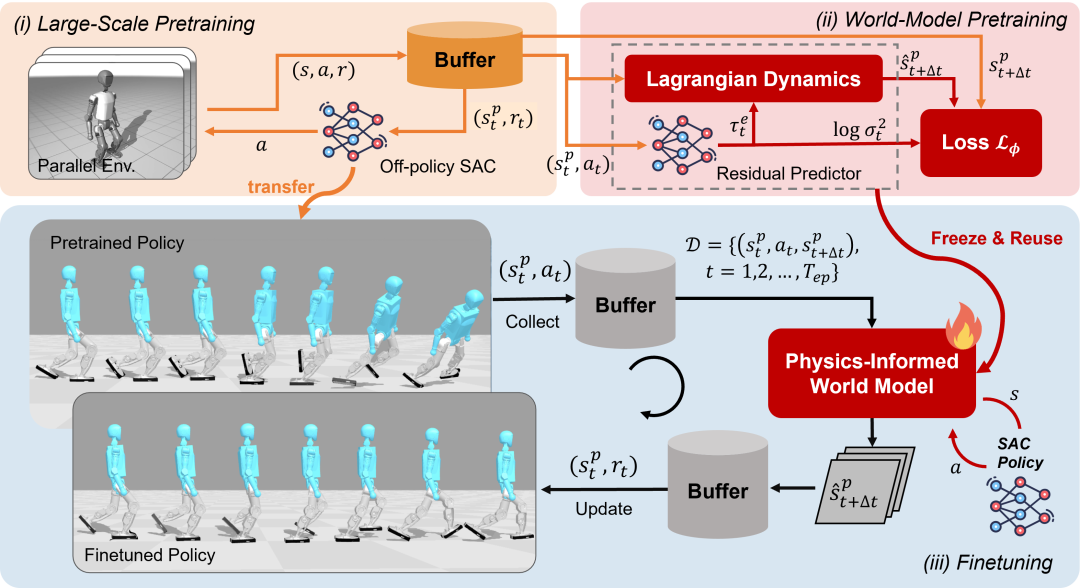
图 1. LIFT 框架图
为了解决上述问题,作者提出了 LIFT (Large-Scale PretraIning and Efficient FineTuning) 框架(如图 1 所示)。LIFT 的框架的设计基于以下三个核心洞察:
洞察一:SAC 比 PPO 在数据量和数据多样性受限时更具优势。
先前的方法(如 SSRL)已经证明使用 SAC 在世界模型中探索和学习,可以在真实世界从头开始训练一个四足机器人完成行走任务。一种自然的做法是将 SSRL 中的 SAC 替换成 PPO,因为 PPO 具有大量并行训练的基础设施。
然而,作者发现,SAC 相比 PPO 具有两个优势:它的离策略的特性使得它在数据量和数据多样性不足时,样本效率仍然很高;它的与状态有关的随机策略能够促进其在世界模型中的探索,生成更多样和更有效的训练数据。因此, 作者后续围绕 SAC 打造合适的预训练和微调框架。
洞察二:经过 SAC 大规模预训练的策略能在真实世界零样本部署。
作者使用 Jax 实现了 SAC 并使用了 Optuna 框架对 SAC 的超参数进行了系统性地搜索。在 Booster T1 的行走预训练任务上,优化后的 SAC 收敛时间能从原先的 7 个小时下降到半小时以内。
在固定其他超参数不变后,该研究发现提升 UTD,Batch Size,Replay Buffer Size 均能降低收敛所需的样本数量,并且无需使用额外复杂的技巧(如 ensemble/dropout critic)就能得到一个在真机可零样本部署的基础策略,该策略可作为后续持续学习的稳定起点。同时,可把预训练时的 Replay Buffer 存盘,再离线训练世界模型,避免拖慢大规模并行预训练的速度;
洞察三:物理信息增强的世界模型能提升模型预测性能和策略微调性能。
作者将 Ensemble 网络与人形机器人动力学模型(公式 2)结合以提升世界模型的预测性能:
Ensemble 网络只需要输出接触力与预测的不确定性(方程 3)就可以通过方程(2)计算出加速度,然后积分出下一个时刻的状态:
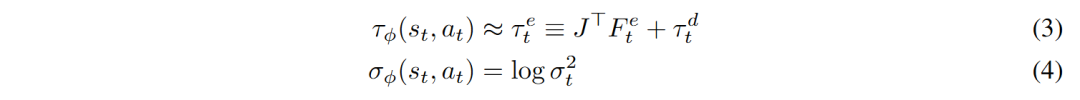
作者修正了 SSRL 中的机器人特权状态空间到广义状态空间的映射关系,并引入构建人形机器人动力学所需的状态(如身体的高度)到特权状态空间中,使得世界模型能准确预测下一个时刻的人形机器人状态。
在真实环境微调时,该方法只需要用:确定性动作(action mean) 在真实环境采集一小段数据;用新数据微调世界模型;用 SAC 随机策略在世界模型里探索生成合成轨迹,再用这些合成轨迹更新 actor-critic;更新后的策略再回到真实环境,进入下一轮迭代。这就把 “探索的风险” 尽可能留在世界模型里,实现安全且高效率的持续学习。
实验结果
作者在两款人形平台 Booster T1 与 Unitree G1 上进行了预训练和微调实验,对比基线包括 PPO、SAC 等。相比于基线方法,LIFT 展现了显著的优势:
1. 策略预训练的收敛时间:在 MuJoCo Playground 的人形机器人任务上,相同运行时间内,LIFT 的 预训练回报与 PPO、FastTD3 相当或更高,这说明该框架没有使得策略预训练的时间变长。如图 2 所示,策略可以直接零样本部署到真机,作为后续微调的初始化策略。

图 2. 真机零样本部署
2. 样本效率:作者将预训练策略迁移到 Brax 仿真器进行微调,并设计了三种场景:
-
分布内(In-Distribution):目标速度落在预训练范围内;
-
长尾分布(Long-Tail):预训练中很少出现的目标速度;
-
分布外(Out-of-Distribution):目标速度超出预训练范围。
如图 3 所示,LIFT 在三类场景中均能在 4×10⁴的环境样本数量级下收敛(约为真实世界的 800 秒)并准确跟踪目标速度。
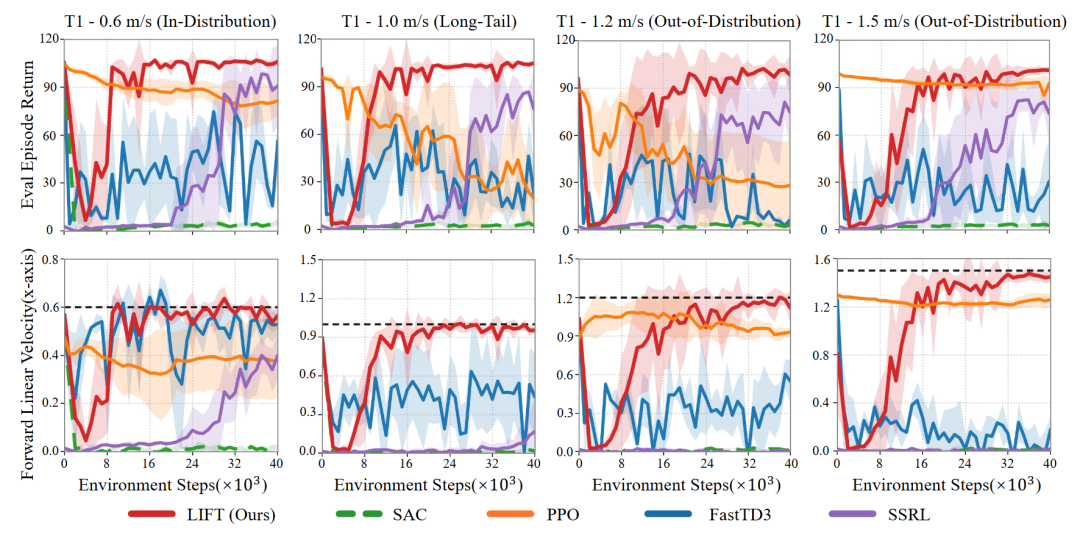
图 3. 在 Brax 中微调的训练曲线图
微调效果如下所示, Booster T1 在微调前无法准确跟踪预训练时未见过的目标速度(1.5 m/s 的速度向前行走),微调后的策略能准确追踪该目标,并且微调后步态更平顺、身体摆动更小、速度偏差显著降低。
 Booster T1 预训练策略的效果
Booster T1 预训练策略的效果

图4. 在Brax中微调前后的效果对比图
作者进一步在 Booster T1 真机上进行了微调实验:以一个仿真预训练后迁移到真机失败的预训练策略为起点,LIFT 通过多轮迭代,仅用 约 80–590 秒 的真实数据,就能逐步修正策略的不稳定行为(如图 5 所示)。

图 5. 在 Booster T1 真机上微调的过程
在消融实验中(图 6),作者发现去掉世界模型预训练算法仍能收敛,但收敛速度明显更慢;而完全去除预训练则容易陷入局部最优。
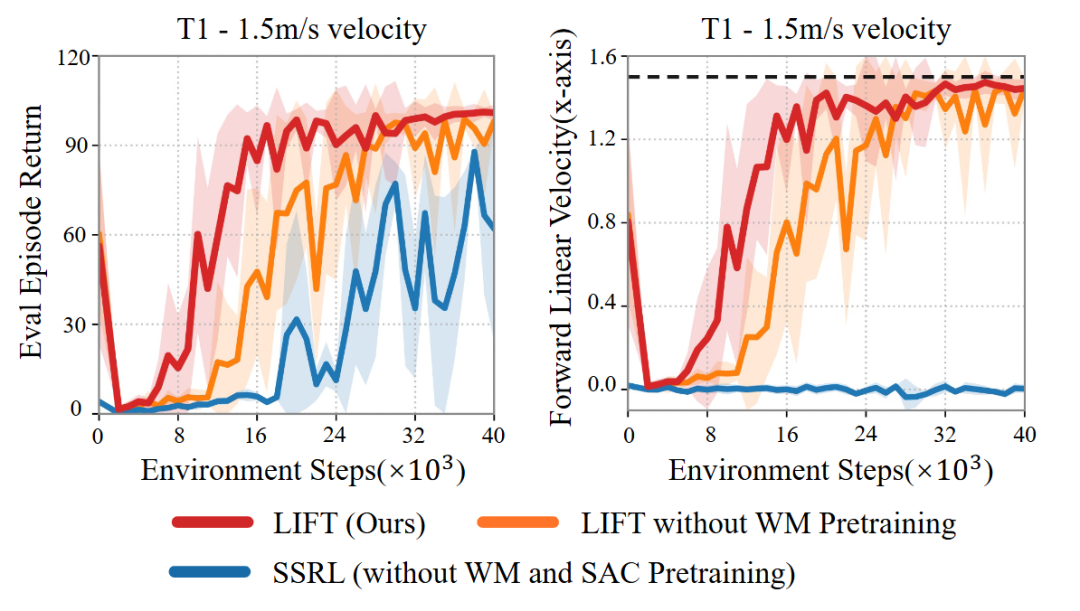
图 6. 预训练的消融实验
而另外一项消融实验(图 7)表明使用纯 ensemble 网络构建的世界模型更容易给出物理上不合理的预测(如异常的身体高度),导致 critic loss 爆炸并阻碍策略提升。相比之下,LIFT 提供了更强的归纳偏置,在有限数据下表现更稳健。
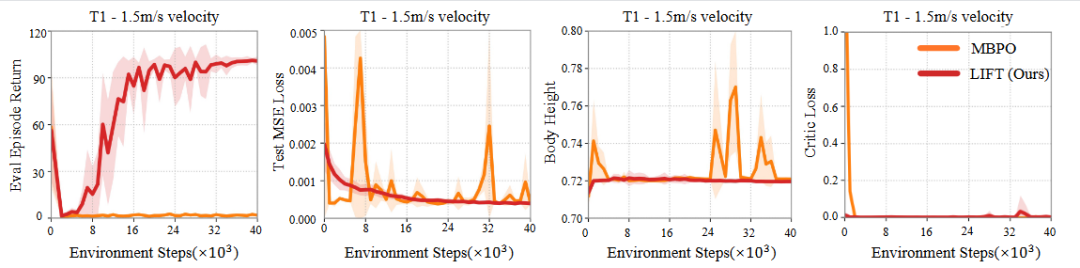
图 7. 物理信息增强的世界模型消融实验
此外,作者也将同一预训练框架拓展到 Unitree G1 的全身跟踪类任务。
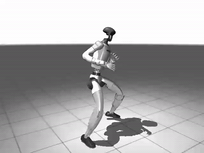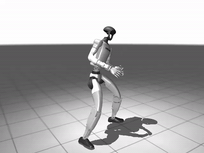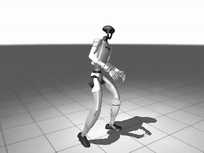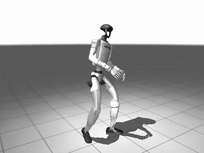

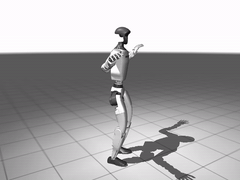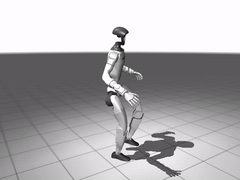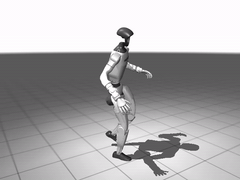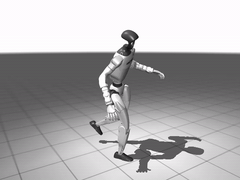


图 8. 全身跟踪的预训练效果
结语
如果把在真实世界的机器人上扩展强化学习当成一条通向通用人工智能的路径,那么关键不在于机器人某一次演示能跑多酷,而在于:我们能否把机器人的学习过程在真实世界闭环,即构建一个可持续、可扩展、自动化的学习系统。
当前的结果说明,用更可控的真实数据采集,把高风险探索尽量转移到世界模型里,是让强化学习在真实人形机器人上变得可行的一种方向;但要把它 “规模化”,仍然有几类瓶颈需要被解决。
一是观测与状态估计。如果关键物理量(例如机器人基座高度、速度)仍依赖外部动捕或存在累积漂移,那么系统就很难脱离人工与场地约束,也难以在开放环境中长期运行。
二是安全与重置机制。即便采取确定性执行,依然有可能因为策略误差与建模误差导致策略失控。需要设计更自动化的安全保护机制 —— 包括不确定性驱动的保护、恢复策略。
三是系统吞吐量。需要设计异步的数据采集与强化学习训练系统,保证策略推理时也在进行持续学习。当这些要素逐步到位时,强化学习才能在真实世界发挥重要作用。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com