利用阿里云 RDS MySQL 向量存储能力,轻松搭建 AI 驱动的儿童科普动画应用,解决家长在儿童教育中遇到的难题。
原文标题:春节带娃不崩溃指南:用 MySQL 一键部署AI驱动的儿童科普动画片,娃安静一整天!
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章中提到了 RAG 技术在儿童科普应用中的重要性,可以通过私域知识库快速召回知识点,但构建高质量的私域知识库的挑战有哪些?我们应该如何有效地管理和维护这些知识库,确保其准确性和时效性?
3、文章中提到,可以将用户画像、偏好、历史对话等信息存储在 MySQL 数据库中,以实现“记住用户”的功能,这是否会带来隐私方面的问题?我们应该如何平衡个性化推荐和保护儿童隐私之间的关系?
原文内容

阿里妹导读
孩子们的好奇心永远不会被满足,孩子们的问题也永远是天马行空。当孩子问「天上那道彩色的桥是什么?」时,传统 AI 往往只懂「彩虹的形成原理」——知识不是问题的答案,而是思考的起点。为了让 AI 既能听懂儿童千奇百怪的问法,又能从私域知识库里精准召回知识点,再自动生成适龄科普内容,并悄悄埋下下一个「为什么」的种子,我们基于 RDS MySQL 向量存储能力支持搭建了一个儿童科普生成应用:《知深识易》。
要做到「听得懂、召得准、记得住」,离不开两样能力:从知识库里按语义召回内容的 RAG,以及记住用户、越用越懂你的 长期记忆——二者都依赖向量存储与检索。AI应用自身也需要数据库来持久化存储自身的元数据,若各搭一套向量库和元数据库,架构难免分裂,运维成本也会翻倍。阿里云 RDS MySQL 将把向量能力集成到数据库内核中,用「一套实例、统一存储、原生支持」的方式,让这两类能力都落在你最熟悉的 MySQL 上,支持开发者一站式完成AI应用的快速开发。
一、背景
在学龄前(3–6岁)和小学阶段(7–12岁),孩子每天都在问“为什么”。但教育者和家长面临三大难题:
-
内容难整合:优质科普知识散落在绘本、视频、网站甚至私域材料中,查找费时。
-
制作门槛高:剪辑+配音+脚本=2–4小时/条,普通人难以持续产出。
-
注意力匹配难:孩子专注力仅3–10分钟,长视频无效,而适龄优质短内容极度稀缺。
更深层的问题是:
即使找到答案,也常是孤立碎片。孩子问“彩虹怎么来的?”,得到一句解释就结束了——没有关联“光的折射”“水滴形状”“太阳位置”,知识无法生长成认知网络。
而当孩子换个方式问:“天上那道彩色的桥是什么?”—— 传统系统可能直接告诉你“我现在还不会哦,请换一个问题问吧”。
为此,我们打造了一个端到端系统,基于私域教材 + 公域权威资源(例:《十万个为什么》),通过 数据 + 向量检索 + AI框架 + 基础大模型,实现:
多源接入 → 智能提取 → 信息泛化 → 知识召回 → 模型回答 → 多模态生成
这样的内容生成核心能力链路。
二、应用介绍
应用展示:
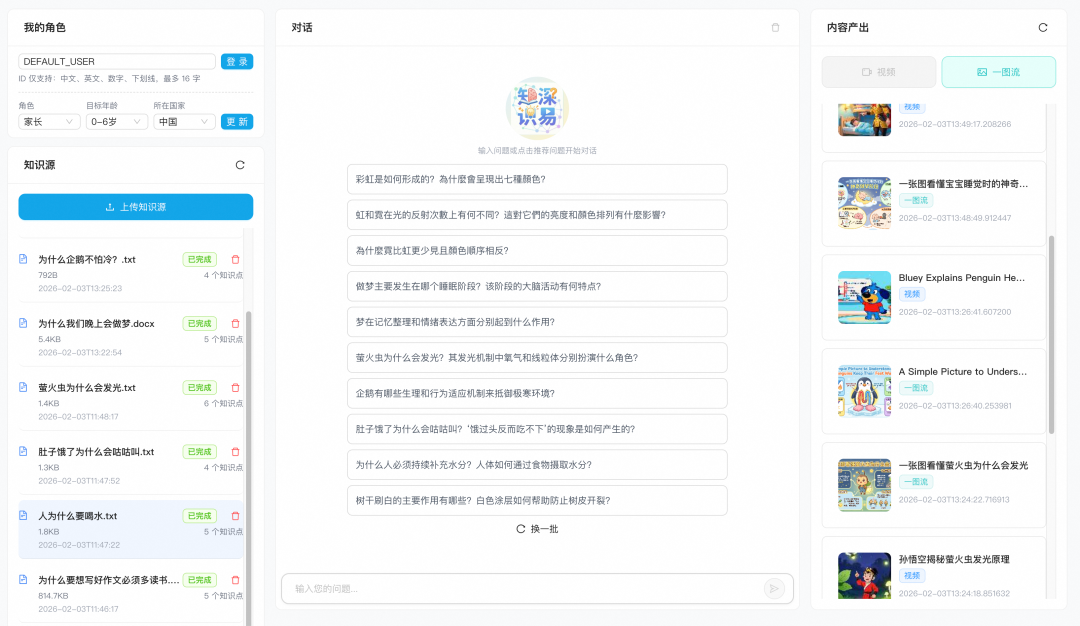
2.1 知识源管理功能
-
知识入库:知识点拆分、向量化存入数据库、问题泛化 系统会帮你把复杂、多形式的知识源(图片、PDF、文档、文本)拆成清晰的知识点,并对每条知识点做 embedding 向量化后写入 RDS MySQL,用于后续语义检索。
-
问题挖掘泛化:通过「设问」形式预先挖掘拓展知识点中的问题。有问题才有学习,平铺直叙的知识介绍往往印象并不深刻,预设问题的形式一方面简化了用户的操作学习路径,一方面带来更好的学习效果。
-
向量化构建 RAG:知识源经过模型拆分提取出知识点,经过向量化处理后存放在RDS MySQL向量表中,为 LLM 提供「从私域知识库快速召回」的能力。
知识源管理示例:
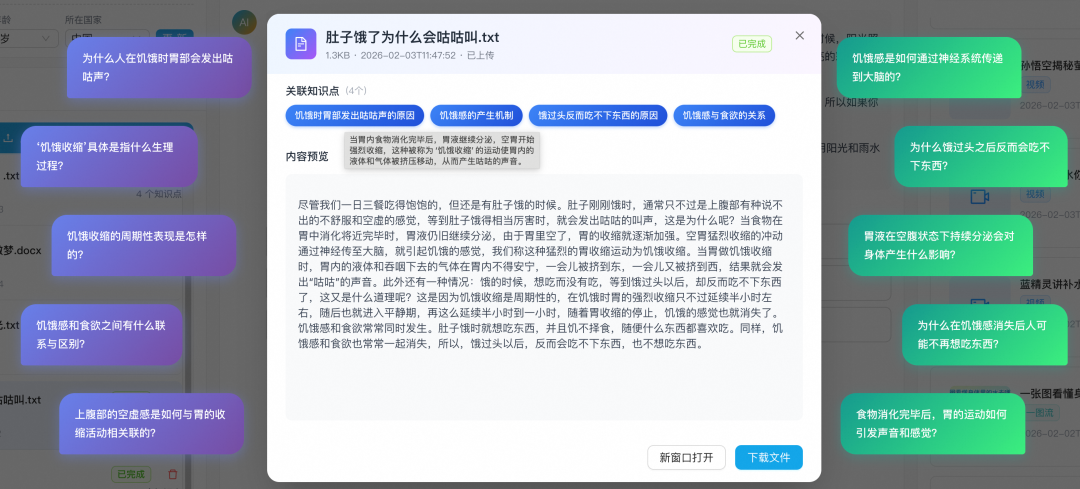
2.2 内容脚本生成功能
-
问题提取:用户提问时,我们通过记忆存储的用户画像,将孩子们天马行空的问题进行归一化处理,转化为可供向量检索的标准问题,例如我们可以预先让模型知道提供的用户可能是学龄前儿童,在提示词中着重问题联想,找到用户问法背后的真实问题。
-
RAG 知识召回:将真实问题用与入库一致的 Embedding 模型(如 Qwen-Embedding)转为向量,再在 RDS MySQL 中做向量相似度检索,召回 Top-K 相关片段,从私域知识库获取定制知识点提供给大模型,作为生成脚本的上下文。
-
长期记忆:用户画像、偏好、历史对话等以记忆向量 + 元数据的形式存在同一 MySQL 实例中(可配合基于 mem0 的 MCP 等方案),实现「记住用户」并自动生成对应受众的内容脚本。
-
内容脚本生成:在 RAG 与记忆的基础上,由大模型生成回答,再对结果做针对性蒸馏,得到适合视频、图片生成的 prompt。
AI问答和内容脚本生成示例:

2.3 多模态内容生成功能
-
可扩展架构:可快速扩展需要生成的产出类型(视频、信息图等),要接入一种新的产出内容类型,只需要在内容脚本生成流中,添加对应的prompt生成节点,并提供给对应的模型。
-
关于视频、图片模型的 prompt:针对轻科普脚本,我们先用大模型把脚本压缩成「核心知识概念」,再交给视频/图像模型,减少长文本对多模态模型的干扰。例如,图片生成的示例规则如下:
将用户输入提取 3~4 个核心的概念知识点,以及一个标题,标题格式是「一张图看懂xxxx」。你的输出需要严格遵守下面的输出格式范例,替换其中的标题和核心知识点以及一句话解释,不要有多余内容,具体知识点数量根据输入情况自行判断。
输出格式
「生成信息图:通俗易懂,适合{age}年龄段的儿童,语言和用户输入语言相同。标题:一张图看懂xxxx,内容:1. 核心概念知识点:一句话解释。2. 省略,同1。3. xxx 4. xxx」。
有了核心概念后,模型能在不偏离主题的前提下生成媒体内容,并减少过多文字对画面质量的干扰。
多模态内容生成示例一:
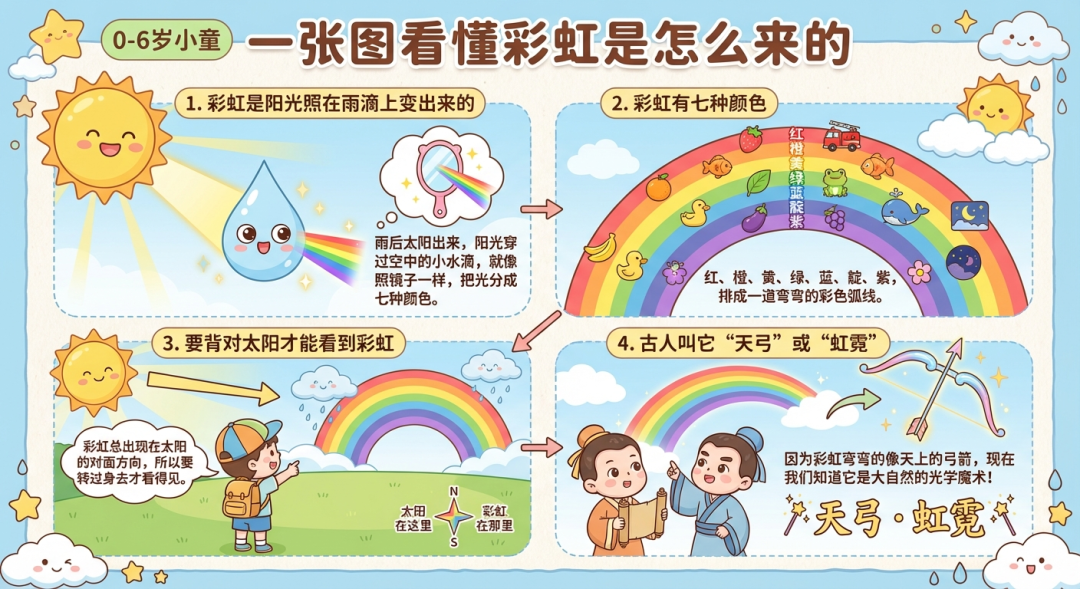
多模态内容生成示例二:

三、技术框架与向量集成
技术架构图示:
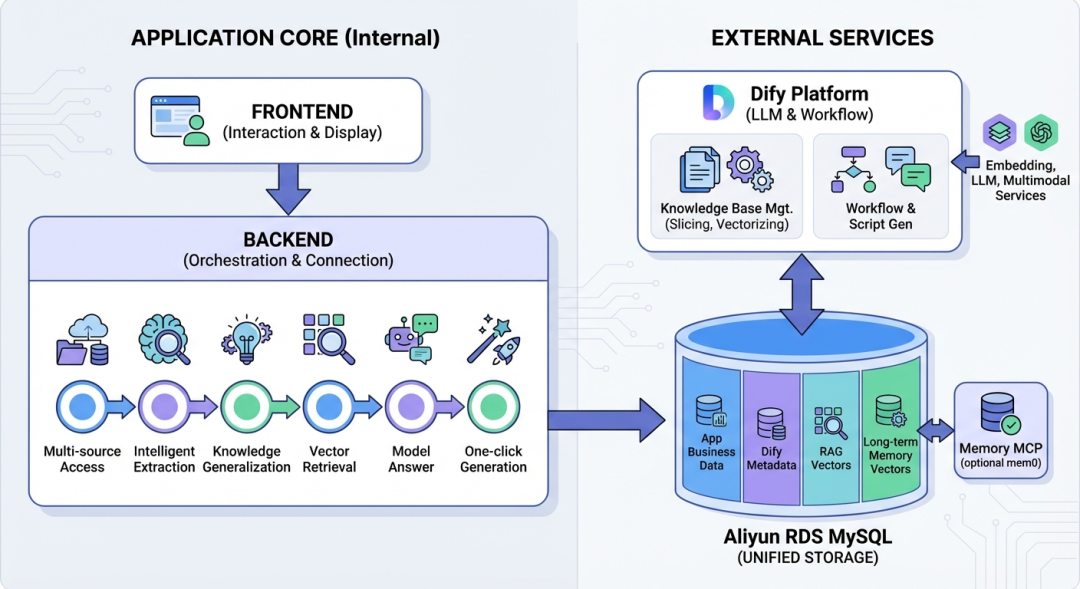
如何使用RDS MySQL 搭建 RAG 服务
RAG 是 AI 应用中的重要组成部分,基本实现方式是:
知识库文档/问法 → embedding → 写入 MySQL 向量表 → 查询时向量检索
RDS MySQL 当前已经集成 Dify、LangChain、LlamaIndex 等知名 AI 框架,下面以 Dify 与 LangChain 为例进行介绍。
使用 Dfiy 搭建基于 RDS MySQL 的 RAG 服务
通过「知识库」+ 数据集(Dataset)管理文档,底层可配置为 RDS MySQL 向量,实现「文档 → 切片 → 向量化 → 存入 MySQL → 工作流中检索」。
准备 RDS MySQL
-
使用阿里云 RDS MySQL 8.0,小版本 ≥ 20251031,并开启向量能力[1]。
-
创建好数据库与账号。
部署 Dify,使用 Dify v1.11.0 及以上版本。
配置向量存储为阿里云 MySQL,环境变量中配置:VECTOR_STORE=alibabacloud_mysql
创建知识库与数据集
-
在 Dify 控制台创建「知识库」,选择底层向量库为已配置的 RDS MySQL;上传或录入文档后,Dify 会完成切片、向量化并写入 MySQL。
-
在「工作流」中通过「知识库检索」节点即可从该 MySQL 向量库做 RAG 召回。
使用 LangChain 搭建基于 RDS MySQL 的 RAG 服务
通过 langchain-alibabacloud-mysql 等集成,用 AlibabaCloudMySQL 作为 VectorStore,在代码中完成文档入库与相似度检索,再接入 Chain/Agent。
以下展示如何用 RDS MySQL 向量 创建简单 RAG:初始化向量库、写入文档、检索、再接到 LLM。
环境变量(与 Dify 对齐):
-
ALIBABACLOUD_MYSQL_HOST、ALIBABACLOUD_MYSQL_PORT、ALIBABACLOUD_MYSQL_USER、ALIBABACLOUD_MYSQL_PASSWORD、ALIBABACLOUD_MYSQL_DATABASE -
若用 DashScope Embedding:
DASHSCOPE_API_KEY
安装:
pip install -U langchain-alibabacloud-mysql
初始化向量库与 Embedding:
import os from langchain_alibabacloud_mysql import AlibabaCloudMySQL from langchain_community.embeddings import DashScopeEmbeddingsembeddings = DashScopeEmbeddings(
model=“text-embedding-v4”,
dashscope_api_key=os.environ.get(“DASHSCOPE_API_KEY”),
)vector_store = AlibabaCloudMySQL(
host=os.environ.get(“ALIBABACLOUD_MYSQL_HOST”, “localhost”),
port=int(os.environ.get(“ALIBABACLOUD_MYSQL_PORT”, “3306”)),
user=os.environ.get(“ALIBABACLOUD_MYSQL_USER”, “root”),
password=os.environ.get(“ALIBABACLOUD_MYSQL_PASSWORD”, “”),
database=os.environ.get(“ALIBABACLOUD_MYSQL_DATABASE”, “test”),
embedding=embeddings,
table_name=“langchain_vectors_rag”,
distance_strategy=“cosine”,
hnsw_m=6,
)
写入文档与相似度检索:
from langchain_core.documents import Documentdocs = [
Document(page_content=“彩虹是阳光穿过水滴发生折射和反射形成的”, metadata={“source”: “科普”}),
Document(page_content=“光的折射与波长有关,不同颜色的光折射角不同”, metadata={“source”: “物理”}),
]
vector_store.add_documents(documents=docs)检索
results = vector_store.similarity_search(query=“彩虹的形成原理”, k=3)
for doc in results:
print(doc.page_content, doc.metadata)
接入 RAG Chain(检索 + LLM 生成):
from langchain_community.chat_models.tongyi import ChatTongyi from langchain_classic.chains import create_retrieval_chain from langchain_classic.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplateretriever = vector_store.as_retriever(search_kwargs={“k”: 3})
prompt = ChatPromptTemplate.from_template(
“仅根据以下上下文回答问题。\n\n上下文:{context}\n\n问题:{input}”
)
llm = ChatTongyi()
document_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, document_chain)response = rag_chain.invoke({“input”: “天上那道彩色的桥是什么?”})
print(response[“answer”])
Langchain文档:
https://docs.langchain.com/oss/python/integrations/vectorstores/alibabacloud_mysql
如何使用 RDS MySQL 搭建记忆服务
记忆服务用于提供用户画像、对话历史等持久化与召回等能力,典型实现方式是:
记忆 MCP(如基于 Mem0 + RDS MySQL)或自建记忆表 + 向量检索
使用 Mem0 MCP 搭建基于 RDS MySQL 的记忆服务
阿里云RDS MySQL提供了基于 Mem0 的、底层使用 RDS MySQL 的记忆 MCP Server,可一键部署到函数计算等环境中,让 Agent 通过 MCP 协议读写长期记忆。
-
项目入口(供参考):mcp-rds-mysql-openmemory
-
部署后,在 Cursor/IDE 或自建 Agent 中配置该 MCP,即可在应用里使用「记忆」能力,而无需自建向量记忆表。
应用逻辑与元信息存储:统一数据库存储的价值
应用逻辑的实现由顶尖的c姓代码手独立完成,这里不多赘述,值得一提的是,使用 RDS MySQL 作为 RAG 与长期记忆的底层向量存储的同时,还可以把应用元数据(用户、文档、会话、配置等)也放在同一实例中。这带来的好处是:一个数据库完成 AI 应用所需的关系型数据 + 向量数据,避免「业务库 + 向量库」双系统带来的数据一致性、运维和技能栈分裂问题;在阿里云 RDS 上还可借助内核级向量优化(如 HNSW、量化等),在单实例内达到接近专用向量库的性能与规模。
四、在AgentRun平台一键部署《知深识易》
你可以按照前文的步骤自己动手开发一个集成了RAG和记忆的AI应用,此外,我们也将应用接入了AgentRun平台的官方应用模板,你可以在这里快速部署知深识易进行实战体验。地址链接:
https://functionai.console.aliyun.com/cn-hangzhou/agent/explore
AgentRun是阿里云提供的以高代码为核心,开放生态、灵活组装的一站式Agentic AI基础设施平台,为企业级Agentic 应用提供开发、部署与运维全生命周期管理。
需要准备的资源:开启了向量功能的RDS MySQL实例,根据https://functionai.console.aliyun.com/cn-hangzhou/agent/infra/memory-storages指引创建记忆存储服务,底层选用自定义的RDS MySQL实例,将创建的记忆服务名称作为一键部署的参数传入;百炼平台API KEY,用于视频、图片内容的生成
五、小结
RDS MySQL向量能力在知深识易里主要做了两件事:一是把知识「压」进数据库——知识点与归一问法经同一套 Embedding 落进 MySQL,查询时用语义相似度召回,给大模型一份「按题取料」的上下文;二是把用户「记住」——用户画像和使用习惯以向量形式存于同库,需要时按需检索,让生成内容越用越贴人。二者共用一套 RDS MySQL 实例,不必再为 RAG 和记忆各起一套向量库,架构简单,运维也更可控。
欢迎加入“AliSQL向量存储开发者”钉钉群,群号: 174405004201
参考链接:
[1]https://www.alibabacloud.com/help/zh/rds/apsaradb-rds-for-mysql/vector-storage-1
[2]https://github.com/run-llama/llama_index/blob/main/docs/examples/vector_stores/AlibabaCloudMySQLDemo.ipynb