Anthropic和OpenAI发布新模型:Claude Opus 4.6擅长长文本处理,GPT-5.3-Codex聚焦编码性能,AI模型持续进化。
原文标题:硬碰硬!刚刚,Claude Opus 4.6与GPT-5.3-Codex同时发布
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Anthropic用16个智能体从零开始构建C语言编译器,并成功编译Linux内核,这给你带来了哪些启发?你觉得未来程序员的角色会发生哪些变化?
3、OpenAI 强调GPT-5.3-Codex的交互性,并允许用户实时互动、提出问题和探索解决方案,你认为这种交互方式对AI的应用和发展有哪些积极意义?又可能带来哪些挑战?
原文内容
在春节来临之前,海外大模型先来了一波硬碰硬的发布。
北京时间 2 月 6 日凌晨,Anthropic 与 OpenAI 相继推出了新版本基础大模型,分别是 Claude Opus 4.6 与 GPT-5.3-Codex。

昨天两家还在因为 AI 里面的广告而论战,今天在大模型发布上又撞车了。话不多说,直接看他们的模型能力如何。
Claude Opus 4.6
Claude Opus 4.6 是 Anthropic 对其旗舰人工智能模型的一次重大升级。在这代模型上,规划更加谨慎,能够维持更长时间的自主工作流程,并在关键的企业基准测试中超越了包括 GPT-5.2 在内的竞争对手。
新模型首次拥有 100 万 token 的上下文窗口,使 AI 能够处理和推理比以往版本多得多的信息。Anthropic 还在 Claude Code 中引入了类似于 Kimi K2.5 的「智能体团队」功能 —— 一项研究预览功能,它允许多个 AI 智能体同时处理编码项目的不同方面,并进行自主协调。
Anthropic 强调,Opus 4.6 可将其增强的功能应用于一系列日常工作任务,包括运行财务分析、进行研究以及使用和创建文档、电子表格和演示文稿。现在在 Cowork 环境中,Claude 可以自主地执行多任务,Opus 4.6 可以代表人类运用所有这些技能。
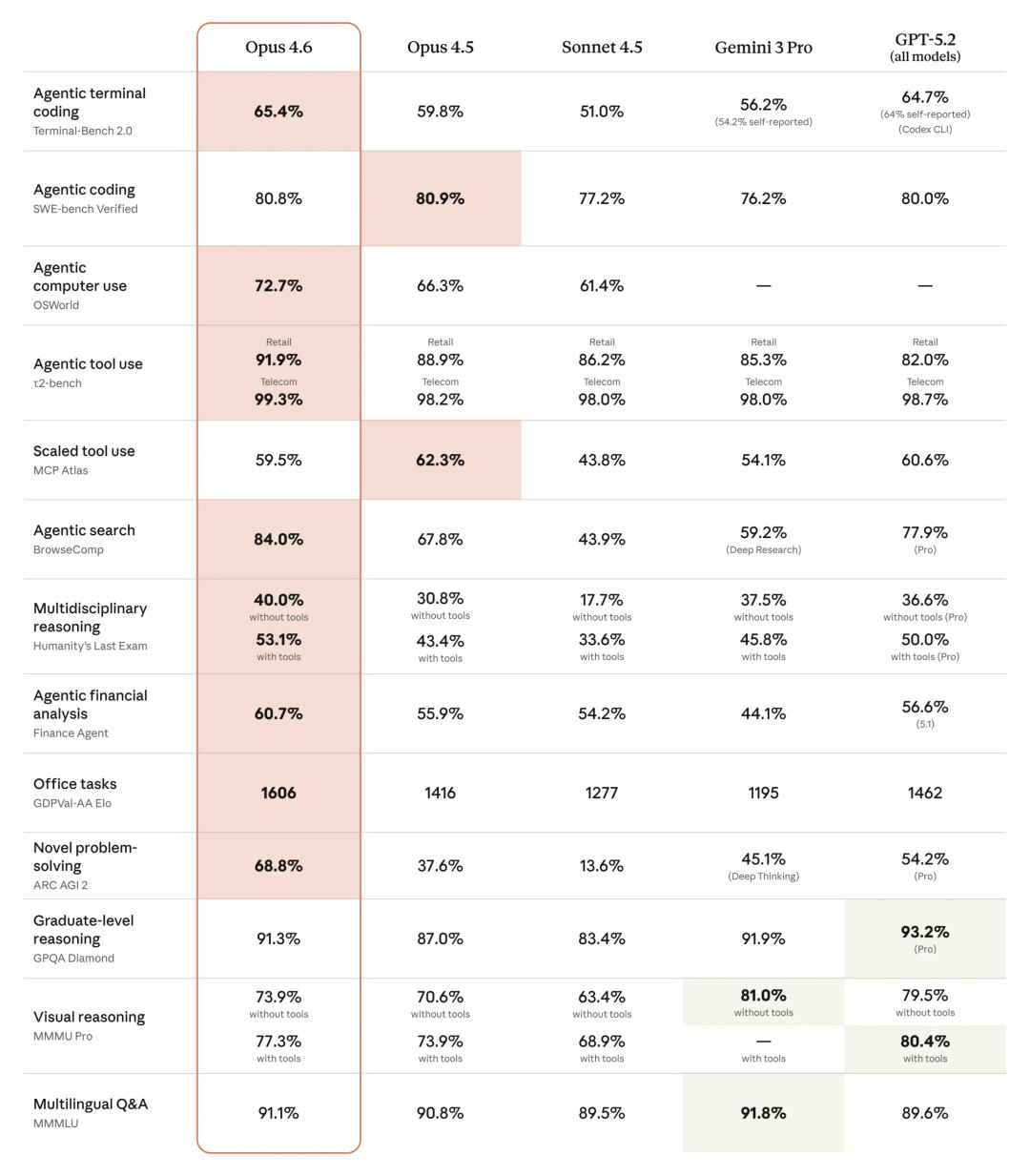
Opus 4.6 在多项评估中均表现出色。例如,它在智能体编码评估工具 Terminal-Bench 2.0 中取得了最高分,并在「人类最后的考试」(一项复杂的多学科推理测试)中领先于所有其他前沿模型。在 GDPval-AA(一项评估模型在金融、法律和其他领域中具有经济价值的知识工作任务上的表现的测试)中, Opus 4.6 的表现比业界次优模型(OpenAI 的 GPT-5.2)高出约 144 个 Elo 分数,比其前身(Claude Opus 4.5)高出 190 分。此外,Opus 4.6 在 BrowseComp 测试中也优于其他所有模型,该测试用于衡量模型在线查找难寻信息的能力。
Claude Opus 4.6 现已在 claude.ai、API 以及所有主流云平台上线,定价保持不变,每百万 token 5 美元 / 25 美元。
目前大模型的一个常见问题是「上下文腐烂」,即当对话 token 数量超过一定阈值时,模型性能会下降。Opus 4.6 的性能显著优于其前代产品:在 MRCR v2 的 8 针 1M 变体测试中(该测试如同大海捞针),Opus 4.6 的得分为 76%,而 Sonnet 4.5 的得分仅为 18.5%。这标志着模型在保持最佳性能的同时,能够利用的上下文信息量发生了质的飞跃。
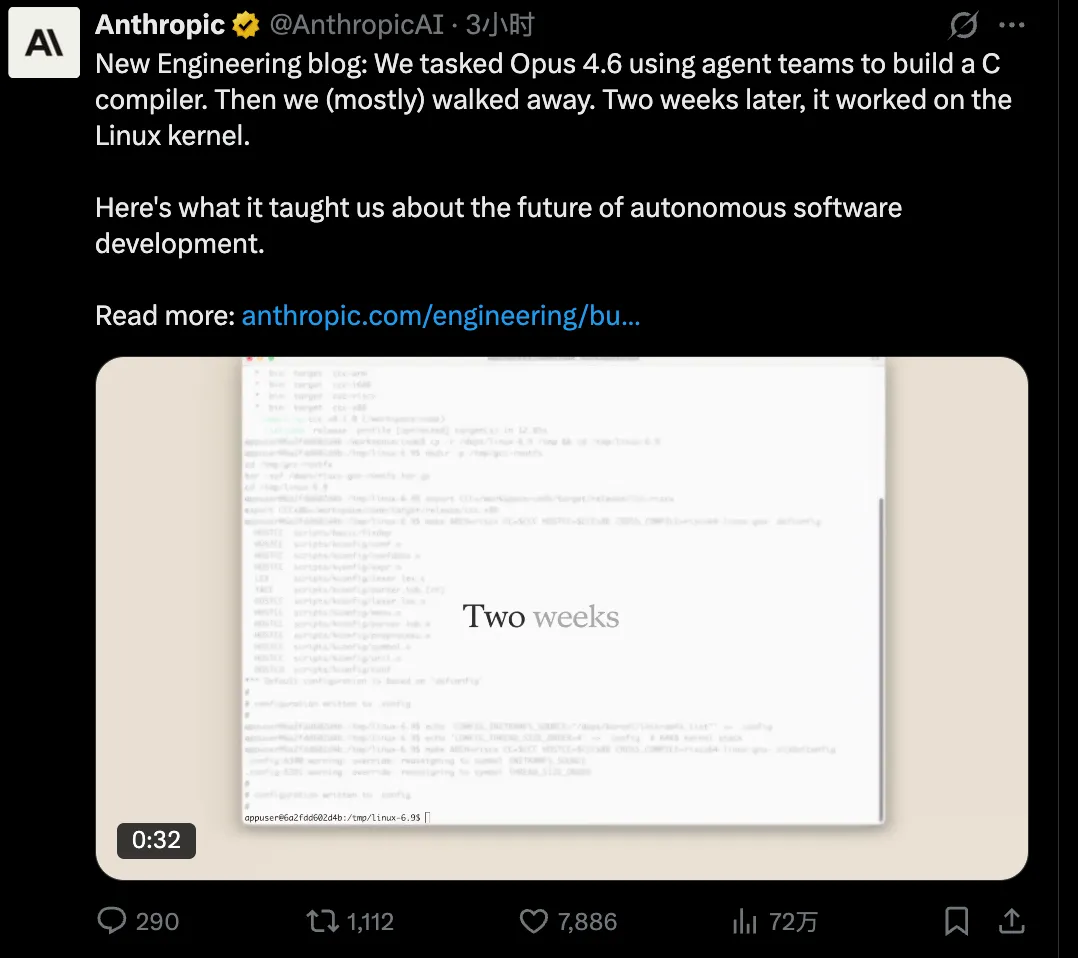
为了证明 Opus 4.6 的强大智能体能力,Anthropic 的一名研究员使用 16 个智能体从零开始构建了一个基于 Rust 的 C 语言编译器,设定任务后就基本放手不管了。最后 AI 输出的代码长达 10 万行,可以编译 Linux 内核,耗资 2 万美元,超过 2000 次 Claude Code 会话,历时两周。
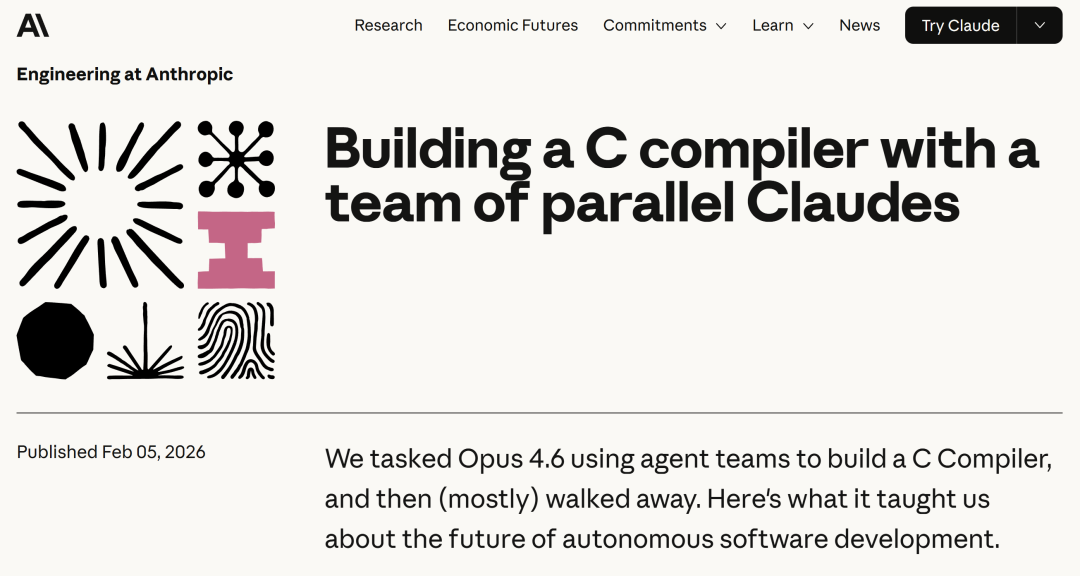
该编译器可以在 x86、ARM 和 RISC-V 上构建可启动的 Linux 6.9,它通过了 GCC 99% 的压力测试,可以编译 FFmpeg、Redis、PostgreSQL、QEMU,还通过了开发者的终极考验:编译并运行了 Doom 游戏。
该编译器的代码:https://github.com/anthropics/claudes-c-compiler
虽然没有人类参与编写代码,但研究人员不断重新设计测试,在智能体程序互相干扰时构建 CI 管道,并在所有 16 个智能体程序都卡在同一个 bug 时创建变通方法。
看起来,在未来加入 AI 的工作流程中,人的角色已经从编写代码转变为构建让 AI 能够编写代码的环境。
GPT-5.3-Codex
在 OpenAI 这边,新一代模型 GPT-5.3-Codex 的发布紧随其后。奥特曼称其拥有目前最佳的编码性能,进一步释放了 Codex 的潜能。
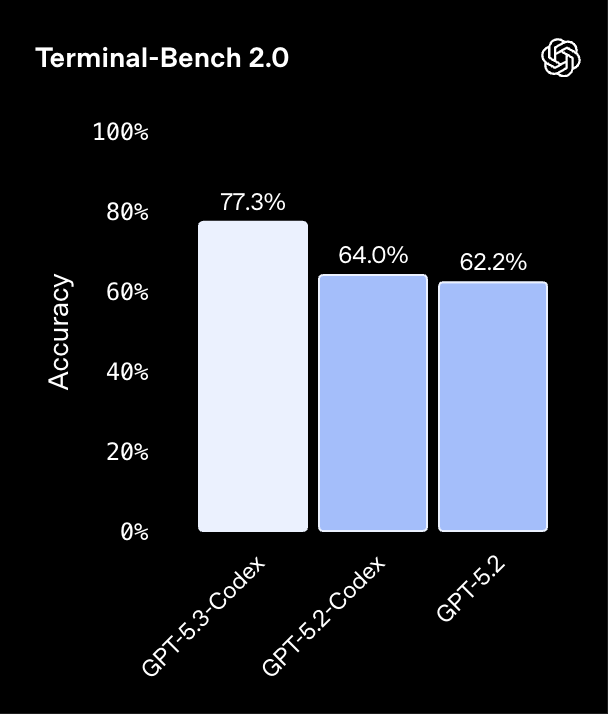
GPT-5.3-Codex 在多项基准上刷新纪录:在 SWE-Bench Pro 上达到 56.8%,在 Terminal-Bench 2.0 上达到 77.3%,同时相比此前版本运行更快、消耗的 token 更少。

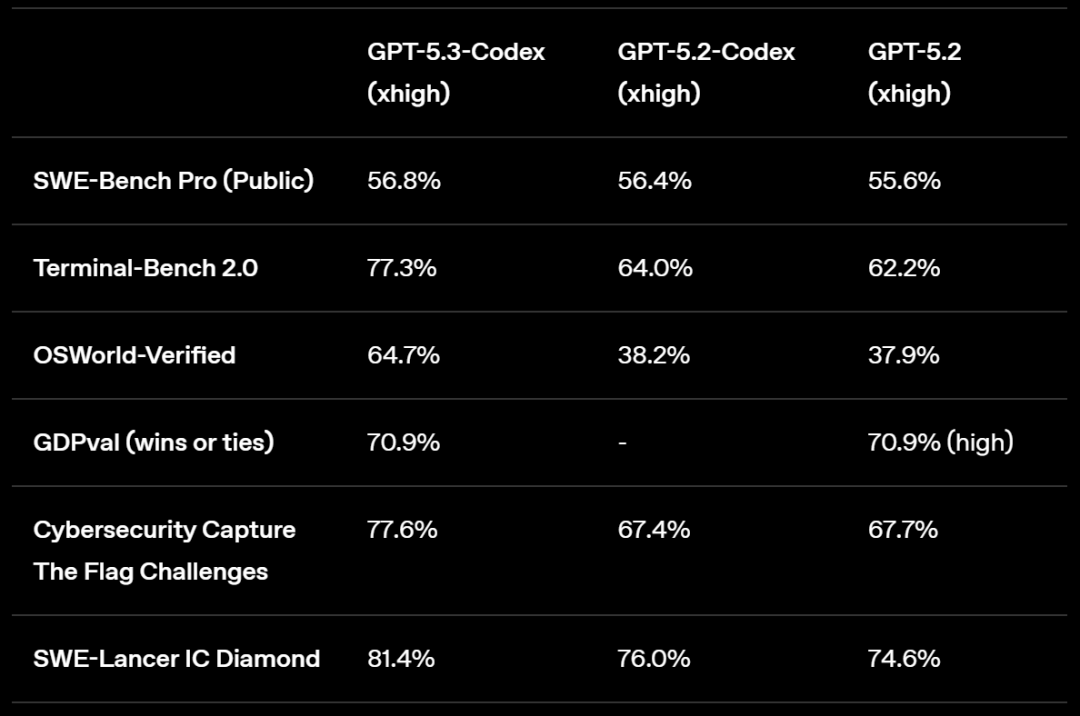
OpenAI 表示,该模型融合了 GPT-5.2-Codex 的前沿编码性能和 GPT-5.2 的推理及专业知识能力,速度提升了 25%。这使其能够胜任需要研究、工具使用和复杂执行的长时间任务。
它就像一位真正的同事一样,你可以在 GPT-5.3-Codex 工作时对其进行指导和交互,而不会丢失上下文信息。借助 GPT-5.3-Codex,Codex 从一个能够编写和审查代码的代理,变成了一个几乎可以执行开发人员和专业人士在计算机上的任何操作的代理。
除了更加强大的编码能力外,GPT-5.2-Codex 在 OpenAI 长期关注的美学方面又一次有了长足的进步。
在这次发布中,OpenAI 让 GPT-5.3-Codex 构建了两款游戏:一款是 Codex 应用发布时推出的赛车游戏的第二版,另一款是潜水游戏。

OpenAI 表示,GPT-5.3-Codex 利用其网页游戏开发技能以及预先设定的通用后续提示(例如「修复错误」或「改进游戏」),自主地迭代开发了数百万个 token。
这次发布的 GPT-5.3-Codex ,OpenAI 对其的期望远不止步于一个智能编码模型,而是一个能够「Beyond coding」,实现工作助理的智能体。
GPT-5.3-Codex 能够支持软件生命周期中的所有工作 —— 调试、部署、监控、编写产品需求文档、编辑文案、用户研究、测试、指标分析等等。
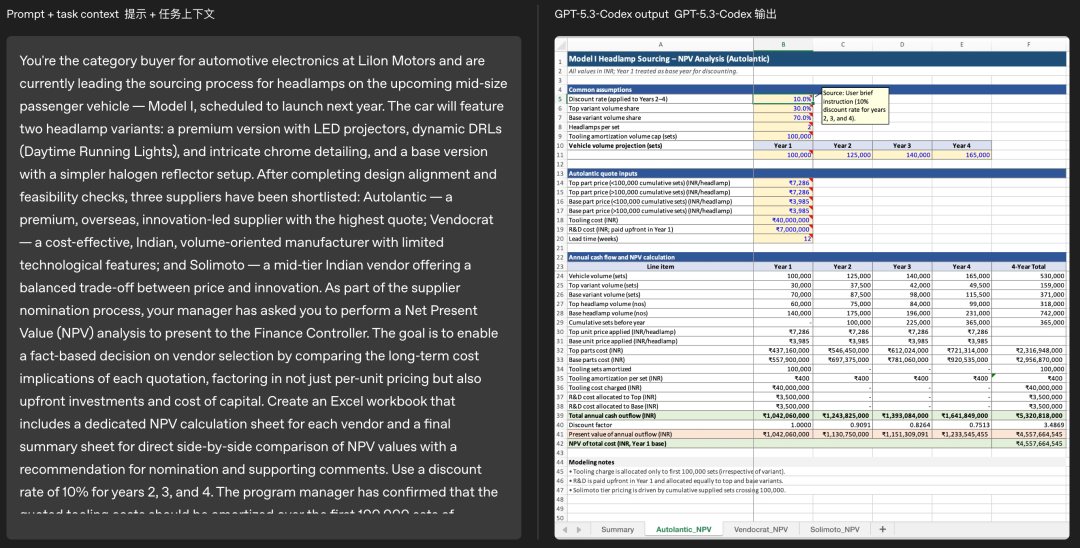
GPT-5.3-Codex 输出净值分析表格示例
OpenAI 认为,随着模型能力的不断增强,差距不再仅仅在于智能体能够做什么,而是在于人类如何轻松地与多个并行工作的智能体进行交互、指导和监督。鉴于此,Codex 应用可以让管理和指导智能体变得更加便捷,而 GPT-5.3-Codex 的加入更使其交互性更强。
借助新模型,Codex 会频繁更新,让你随时了解关键决策和进展。人们无需等待最终输出,即可实时互动 —— 提出问题、讨论方法,并共同探索解决方案。GPT-5.3-Codex 会语音播报其运行过程,响应反馈,并让你从始至终掌握整个流程。
最后,OpenAI 表示,GPT-5.3-Codex 的训练和部署使用了 Codex,OpenAI 的许多研究人员和工程师都表示,他们现在的工作与两个月前相比发生了根本性的变化。
例如,研究团队使用 Codex 来监控和调试本次版本的训练运行。它不仅加速了基础设施问题的调试,还帮助追踪整个训练过程中的模式,对交互质量进行深入分析,提出修复方案,并构建了丰富的应用程序,使研究人员能够精确地了解模型行为与先前模型之间的差异。
工程团队使用 Codex 对 GPT-5.3-Codex 框架进行了优化和适配。当出现影响用户的异常极端情况时,团队成员利用 Codex 识别上下文渲染错误,并找出缓存命中率低的根本原因。在整个发布过程中,GPT-5.3-Codex 通过动态扩展 GPU 集群来应对流量高峰并保持延迟稳定,持续为团队提供支持。
在 Alpha 测试期间,一位研究人员想要了解 GPT-5.3-Codex 每回合能完成多少额外工作,以及由此带来的生产力提升。GPT-5.3-Codex 生成了几个简单的正则表达式分类器,用于估算用户澄清请求的频率、正面和负面反馈以及任务进度,然后将这些分类器可扩展地应用于所有会话日志,并生成一份包含结论的报告。
GPT-5.3-Codex 已包含在 ChatGPT 的付费套餐中,但 API 还需要等待一段时间。
OpenAI 报告说,由于基础设施和推理堆栈的改进,Codex 用户现在运行 GPT-5.3-Codex 的速度也提高了 25%,从而实现了更快的交互和更快的结果。
结语
海外的大模型已经轮番上阵,在春节前的最后这几天,国内大模型也必然会卷起来,包括 DeepSeek v4 也许即将到来。

你期待住了吗?
参考内容:
https://www.anthropic.com/news/claude-opus-4-6
https://www.anthropic.com/engineering/building-c-compiler
https://openai.com/index/introducing-gpt-5-3-codex/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com