ICLR 2026 Workshop 聚焦终身智能体,解决Agent在长期运行中的挑战,打造可持续发展的AI Agent。
原文标题:ICLR 2026 Workshop二轮征稿开启:聚焦终身智能体的学习、对齐、演化
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Workshop 提到了“长期对齐”的重要性,并关注用户目标变化建模、个性化与公平性权衡等问题。如果让你设计一个AI Agent,你会如何确保它在长时间使用后仍然与用户的价值观和偏好保持一致?
3、文章提到要让AI Agent实现“自主进化”,并且能够进行“推理策略自优化,模块/技能自主扩展”。你认为目前的技术发展水平,在哪些领域更容易实现Agent的自主进化?又存在哪些主要的挑战?
原文内容

人工智能正在进入一个新的转折点。
以大语言模型(LLM)、强化学习(RL)和具身智能(Embodied AI)为核心的 AI Agent 迅速崛起,展现出规划、推理、工具调用、自主决策等多维能力。然而,当前主流的范式仍然存在关键瓶颈:
-
面对动态任务和 OOD 任务的迁移,模型灾难性遗忘仍然难以避免。
-
用户目标、环境反馈、上下文约束随时间变化时,Agent 对齐一致性下降。
-
真实世界长期运行带来的算力、token、能源、交互成本约束,使系统可持续性不足。
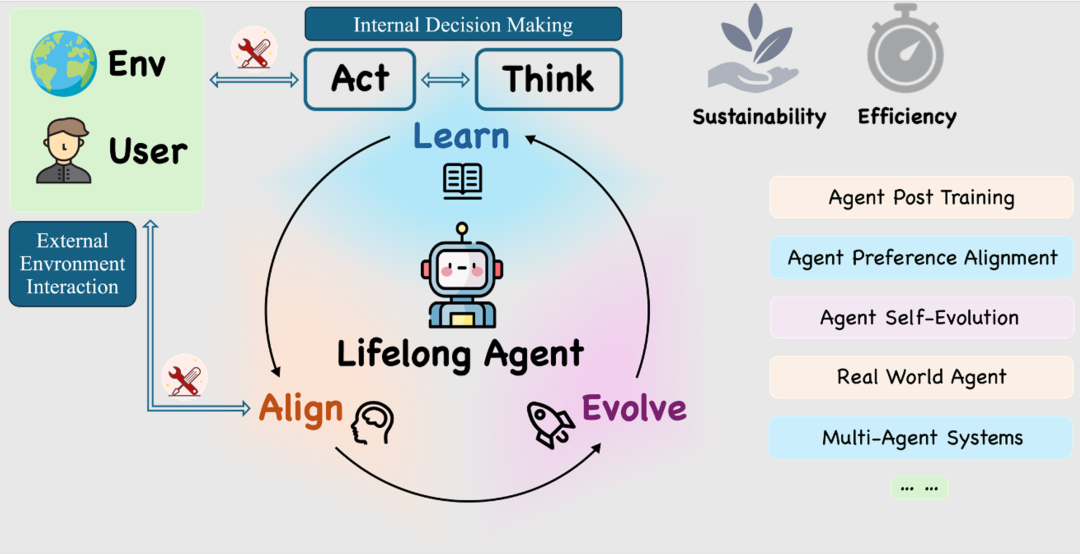
如果我们希望 AI Agent 真正走进开放世界,成为可靠的长期助手,我们必须迈向 Lifelong Agent(终身智能体),让 Agent 持续学习、长期对齐、自主进化、资源可感知、可持续部署。
在本届 ICLR 2026 会议期间,来自 UIUC, Edinburgh, Oxford, Princeton 等机构共同发起的 Lifelong Agent Workshop 中,便将会对以上所有问题进行深入探讨。
本次 Workshop 旨在打造首个跨领域统一论坛,系统性推动 Lifelong Agent 研究范式,打通语言智能、强化学习、具身系统、多智能体协作、AI4Science 等方向,共同定义 Agent 发展的下一座技术里程碑。
🗓️ Workshop 时间地点
-
📅 2026 年 4 月 26 日(或 27 日)
-
📍 Rio de Janeiro(里约热内卢),ICLR 2026 期间
-
🔎 形式:全日制 Hybrid(线下 + 线上实时参与)
-
🌍 官网:https://lifelongagent.github.io/
-
🎯 规模:预计 200–400 现场参会,500–600 线上覆盖
Workshop 官网已上线,Poster / 录播 / Q&A 资源会持续开放。
🧠 征稿方向(包括但不限于)
Workshop 鼓励跨领域、面向长期运行的 Agent 研究,并特别关注以下主题:
1 Lifelong Learning(持续学习)
-
memory-augmented RL、continual exploration
-
多模态 / 具身数据流整合、长短期记忆融合
-
终身学习 Benchmarks 与评估方法
2 Lifelong Alignment(长期对齐)
-
用户目标变化建模、个性化与公平性权衡
-
监督与安全保障机制
-
drift detection & correction、长期价值学习
3 Self-Evolving Agent(自主进化)
-
推理策略自优化、模块 / 技能自主扩展
-
多智能体终身协作生态、LLM + 小模型专精协同
-
Emergent behaviors、open-ended self-improvement
4 Embodied & Real-World Lifelong Agents(具身终身智能)
-
机器人终身学习、感知 - 行动长期闭环
-
不确定性建模、复杂环境下持续运行
5 Efficient & Sustainable Agents(高效与可持续)
-
Token/Compute/Energy 受限下的学习与推理
-
资源感知调度、长期部署系统设计
6 Multi-Agent Lifelong Systems(多智能体终身系统)
-
持续多智能体协作 / 竞争 / 谈判机制
-
群体行为监测 Benchmarks 与持久群体智能
7 AI Agents for Science(科学智能体)
-
自主假设生成、实验设计、科学知识发现
-
具身实验室 Agent、AI4Science 长期生态
8 Evaluation & Benchmarks(终身评估与基准)
-
long-horizon adaptability、alignment drift metrics
-
终身智能体持久性、可信度、可扩展增长评估
⏰ 投稿截止与论文类型
📌 投稿截止:2026/2/15 UTC(以 OpenReview 提交系统为准)
共支持两类论文投稿:
-
Full Paper(完整论文):最多 9 页,适合已完成工作
-
Short Paper(短论文):2–5 页,鼓励最新突破、轻量方法、Follow-up 实验、开源实现、理论洞察、案例分析
本次的投稿为非 Arxiv 性质,欢迎同时将投稿到 ACL 以及 ICML 的优秀工作同时投来本次 Workshop !
🔗 Workshop 详情与投稿入口
-
Workshop 官网: https://lifelongagent.github.io/(下方海报二维码可直达)
-
论文提交入口: https://openreview.net/group?id=ICLR.cc/2026/Workshop/LLA(OpenReview Group)
Lifelong Agent 不是某个单点任务的提升,而是智能范式的升级:
让 AI Agent 成为长期稳定、自主对齐、可持续成长、面向科学发现、跨模态交互、可复现部署的真实世界系统
这是 Agent 研究的 Next Frontier,也是 2026 年最值得关注的 Workshop 方向之一。
让我们一起推动 Lifelong Agent 走向下一座里程碑,让它成为 Agent 时代的 Next Big Thing!

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com