上海大学&南开大学揭示VLM中Attention偏置问题,提出去偏方法,提升模型可靠性与效率。
原文标题:Attention真的可靠吗?上海大学联合南开大学揭示多模态模型中一个被忽视的重要偏置问题
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提出的attention去偏方法无需重新训练模型,这在实际应用中有哪些优势?你认为这种“即插即用”的模块化设计思路,在多模态模型研究中还有哪些潜在的应用场景?
3、研究中提到,attention去偏后,模型保留的视觉区域更加集中于目标物体和关键细节位置。你认为这对于提升模型的鲁棒性、泛化能力,以及在实际场景中的应用(例如自动驾驶、医疗影像分析等)有哪些潜在的价值?
原文内容

近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
近日,上海大学曾丹团队联合南开大学研究人员,从 attention 可靠性的角度出发,系统揭示了 Vision-Language Models 中普遍存在的 attention 偏置问题,并提出了一种无需重新训练的 attention 去偏方法,在多个主流模型、剪枝策略及图像与视频基准上验证了其有效性,为多模态模型的高效、可靠部署提供了新的思路。

-
论文标题:Attention Debiasing for Token Pruning in Vision Language Models
-
论文链接:https://arxiv.org/abs/2508.17807
-
代码链接:https://github.com/intcomp/attention-bias
一、研究意义
近年来,视觉 — 语言模型(Vision-Language Models,VLMs)在图像理解、视觉问答、多模态对话等任务中表现突出,并逐渐成为通用人工智能的重要技术基础。然而,这类模型在实际部署时往往面临一个现实挑战:模型推理成本高,速度慢。
为提升效率,研究者通常会采用 visual token pruning(视觉 token 剪枝) 技术,即在不显著影响性能的前提下,丢弃不重要的视觉信息。其中,attention 机制 被广泛用作判断 “哪些视觉 token 更重要” 的核心依据。
但上海大学曾丹团队在研究中发现:attention 并不总是可靠的 “重要性指标”。在多模态模型中,attention 往往受到多种结构性偏置的影响,这些偏置与真实语义无关,却会直接左右剪枝结果,从而影响模型性能。
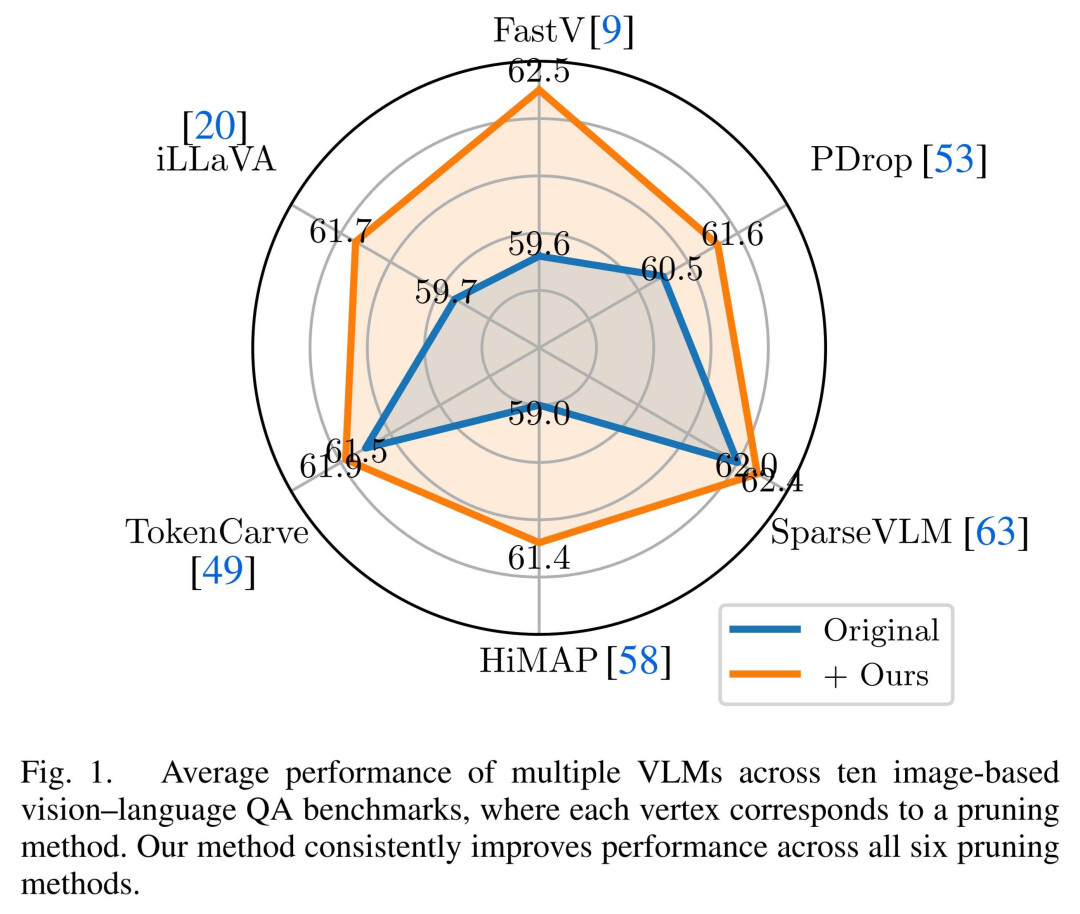
针对这一问题,该团队系统分析了 VLM 中 attention 的行为特性,提出了一种 Attention Debiasing(注意力去偏)方法,在无需重新训练模型的前提下,有效提升了多种主流剪枝方法的稳定性与可靠性。如下图所示,提出的方法应用于目前基于 attention 的剪枝方法上之后,都有提升。
二、研究背景
在直觉上,attention 机制往往被理解为 “模型更关注哪里”,因此被自然地视为语义重要性的体现。然而,曾丹团队的研究表明,在 Vision-Language Models 中,attention 往往并非只由内容决定,而是隐含着多种系统性偏置。
其中最典型的有两类:
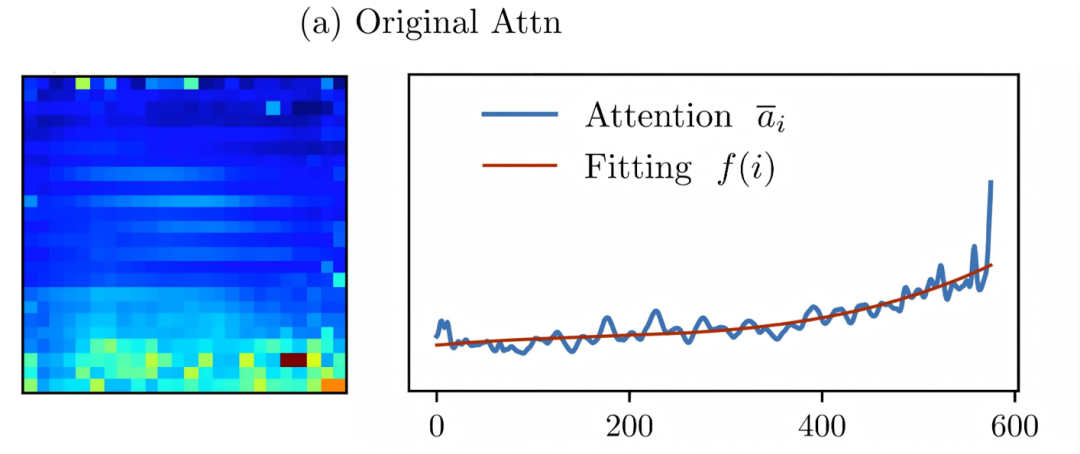
第一类是 位置偏置(recency bias)。研究发现,language-to-vision attention 会随着视觉 token 在序列中的位置不断增大,也就是说,模型更倾向于关注 “后面的 token”。如图所示,这通常表现为模型对图像下方区域给予更高 attention,即便这些区域并不包含关键信息。
第二类是 padding 引发的 attention sink 现象。在实际输入中,为了统一尺寸,图像往往需要 padding,但这些区域在语义上是 “空白” 的。然而,由于 hidden state 中出现异常激活,padding 对应的 token 反而可能获得较高 attention,从而被错误地保留下来。下图是 pad 区域填充不同的数值时,pad 区域对应的 attention score 数值以及 hidden states 的激活值。
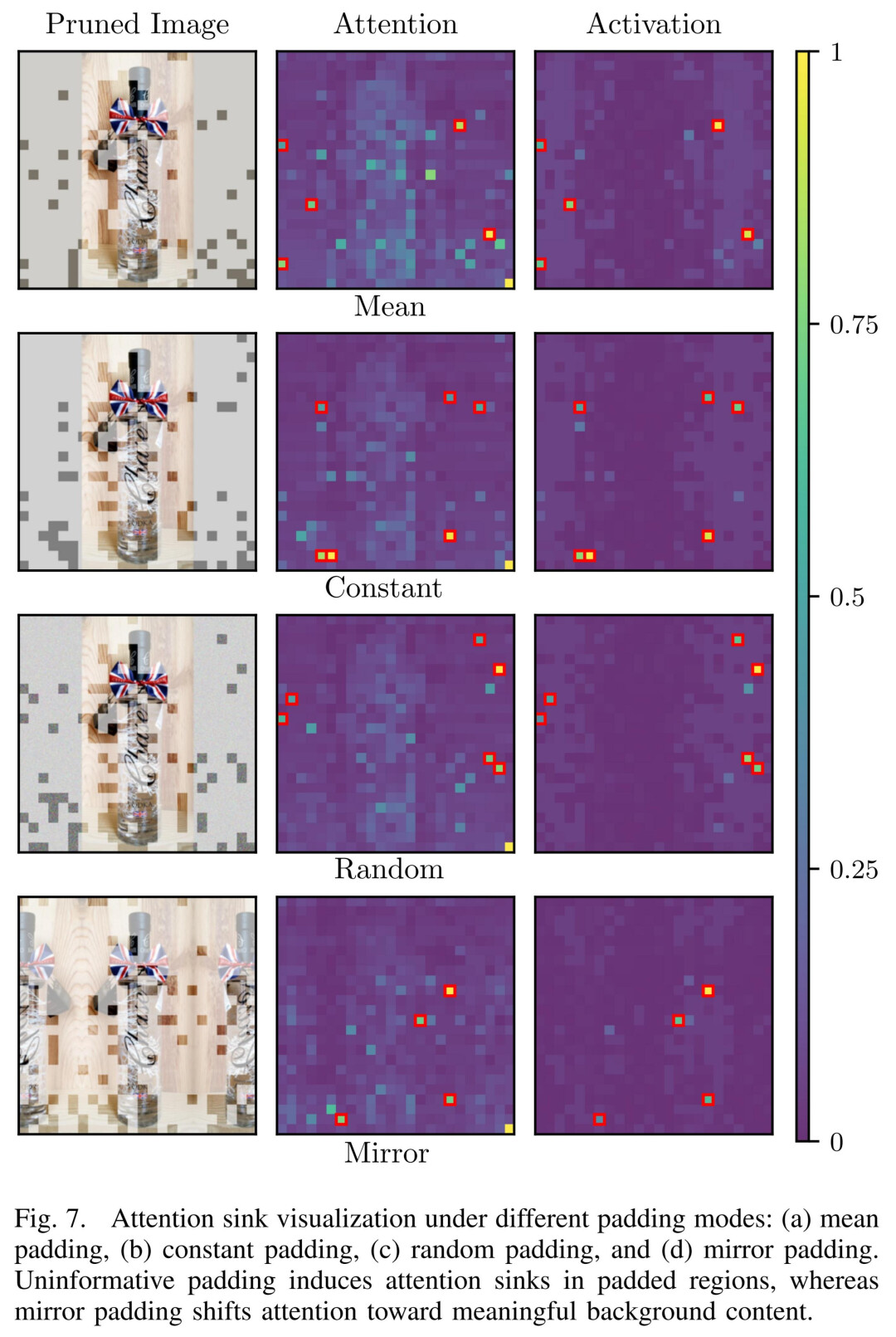
更值得注意的是,当 attention 被用于剪枝排序时,这些偏置并不会被削弱,反而会被进一步放大,最终导致剪枝结果偏离真实语义需求。
三、研究方法
针对上述问题,上海大学曾丹团队并没有提出新的剪枝算法,也没有对模型结构进行修改,而是从一个更基础的角度出发:既然 attention 本身是有偏的,是否可以先对 attention 进行修正?
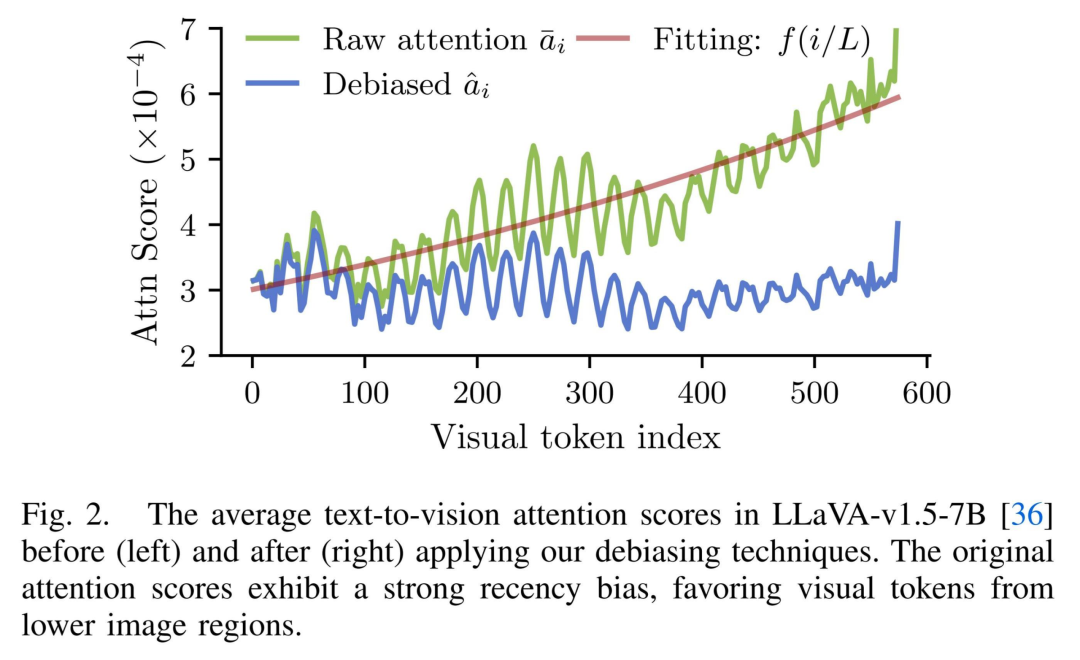
该团队观察到,attention 中的偏置并非随机噪声,而是呈现出稳定的整体趋势。因此,他们通过对 attention 随 token 位置变化的趋势进行拟合,构建了一条反映 “位置偏置” 的曲线,并在此基础上对原始 attention 进行去偏修正,显式削弱与内容无关的位置因素,使 attention 更接近真实的语义重要性。如下图所示。
与此同时,在剪枝阶段显式抑制 padding token 的影响,避免语义为空的区域干扰剪枝排序。整个过程无需重新训练模型,也不依赖特定的剪枝策略,可作为 plug-and-play 模块 直接集成到现有方法中。
四、实验结果
在实验验证中,该团队将 Attention Debiasing 方法集成到 FastV、PyramidDrop、SparseVLM、HiMAP、TokenCarve、iLLaVA 等 6 种主流 attention-based 剪枝方法中,在 10 个图像理解基准与 3 个视频理解基准 上进行了系统评估,并覆盖 LLaVA-7B / 13B 等多种主流 Vision-Language Models。
实验结果表明,在几乎所有设置下,经过 attention 去偏修正后,剪枝模型都能获得一致且稳定的性能提升,且在剪枝更激进、token 预算更紧张的情况下效果尤为明显。这说明,对 attention 进行去偏处理,有助于模型在 “更少信息” 的条件下做出更可靠的判断。
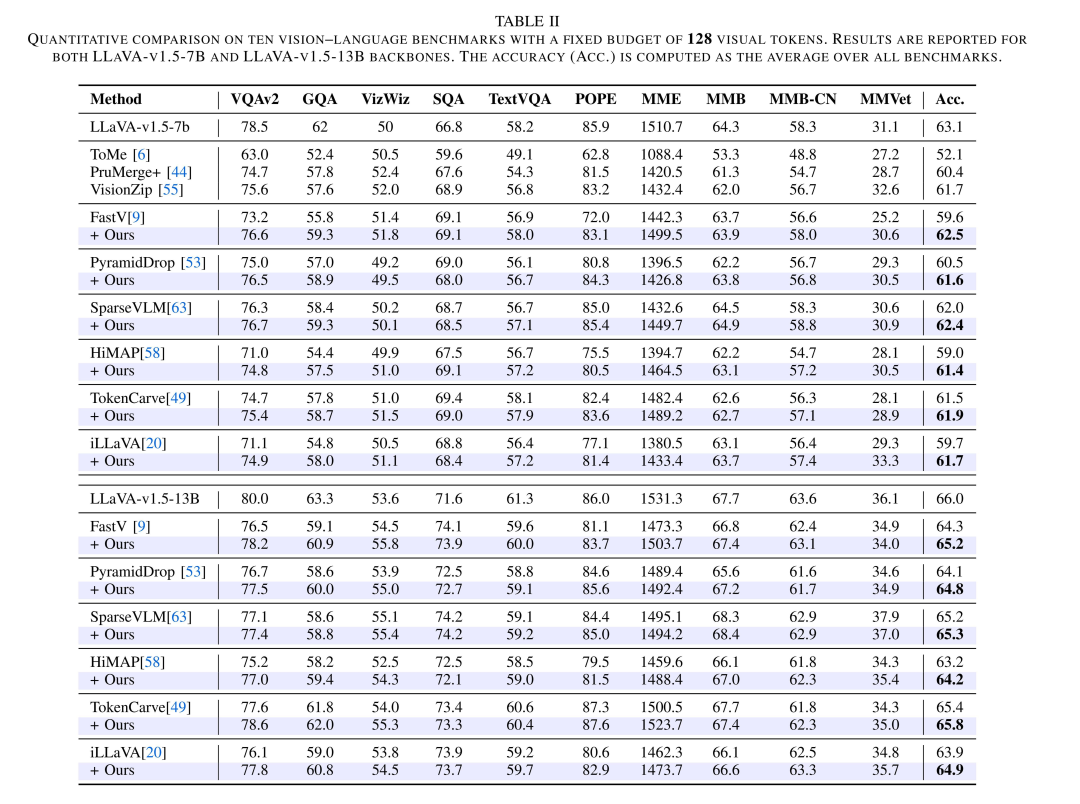
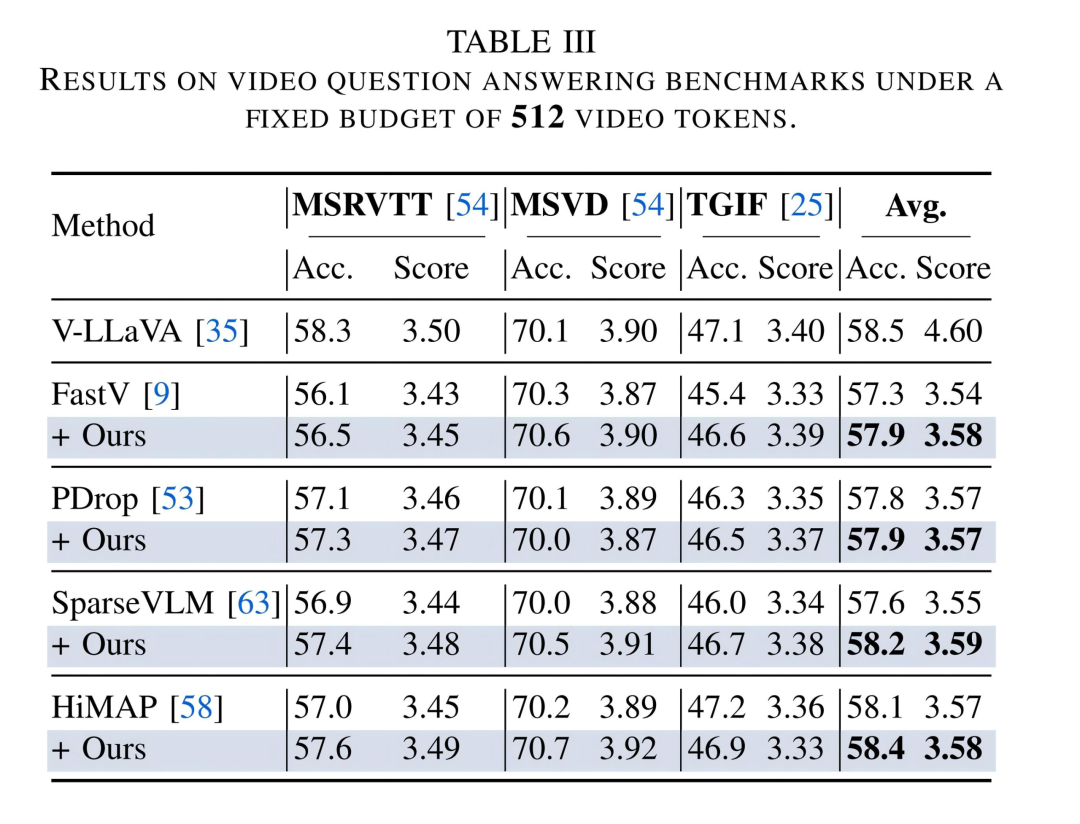
此外,通过对实验结果的可视化分析,原始 attention-based 剪枝方法往往保留了大量位于图像下方或 padding 区域的视觉 token,而与问题语义密切相关的关键区域却容易被忽略。引入 attention 去偏修正后,模型保留的视觉区域更加集中于目标物体及关键细节位置,有效减少了无关背景的干扰。该结果直观验证了 attention 去偏在提升剪枝合理性和可解释性方面的作用。

五、总结
该研究表明,attention 并非天然等价于语义重要性,尤其在 Vision-Language Models 中,如果忽视 attention 中潜在的结构性偏置,基于 attention 的剪枝策略可能会被误导。上海大学曾丹团队通过简单而有效的 attention 去偏方法,显著提升了多模态模型在效率与可靠性之间的平衡能力。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com