VL-LN Bench旨在评估AI在3D环境中“边走边问”寻找特定目标的能力,揭示了当前AI在感知对齐和提问策略上的短板。
原文标题:VL-LN Bench:模拟「边走边问找具体目标」的真实导航场景
原文作者:机器之心
冷月清谈:
怜星夜思:
2、VL-LN Bench 揭示了当前模型在实例级感知对齐上存在瓶颈,你认为可以通过哪些技术手段来提升机器人对物体实例的感知能力?
3、文中提到,目前AI的对话带来的增益弱于信息补全,你认为未来如何设计更有效的对话策略,才能让AI更好地通过提问来完成导航任务?
原文内容

本工作由上海人工智能实验室、中国科学技术大学、浙江大学、香港大学 的研究者们共同完成。

-
论文标题:VL-LN Bench: Towards Long-horizon Goal-oriented Navigation with Active Dialogs
-
项目主页:https://0309hws.github.io/VL-LN.github.io/
-
ArXiv 论文:https://arxiv.org/abs/2512.22342
-
Hugging Face 数据集: https://huggingface.co/datasets/InternRobotics/VL-LN-Bench
-
Hugging Face 模型:https://huggingface.co/InternRobotics/VL-LN-Bench-basemodel
-
GitHub 代码库:https://github.com/InternRobotics/VL-LN
交互式实例导航任务
(Interactive Instance Goal Navigation, IIGN)
如果将一台在视觉语言导航(VLN)任务中表现优异的机器人直接搬进家庭场景,往往会遇到不少实际问题。
首先是使用门槛偏高:传统 VLN 需要用户给出又长又精确的路线式指令,例如 “从门口直走三步,看到门右转,再往前……”,这会显著增加沟通成本,降低日常使用体验。
相比之下,人们更期待一种更自然的交互方式,比如只用随口一句 “找到我的背包” 即可。这样的设定更接近目标物体导航(ObjectNav)任务,但它也存在明显不足:机器人只会找到场景内任意一个背包交差,而无法定位用户真正需要的书包,这显然无法满足需求。
正因为真实场景里用户的表达常常简短且含糊,而机器人又必须把目标精确落实到某一个具体实例上,交互式实例导航才显得格外关键。机器人既不能指望用户一开始就把所有信息交代清楚,也不能用 “找到同类就算完成” 的方式草草应付;相反,它应在探索过程中主动提问、逐步澄清歧义,像人一样把 “到底是哪一个” 问明白,再高效准确地完成用户的需求。
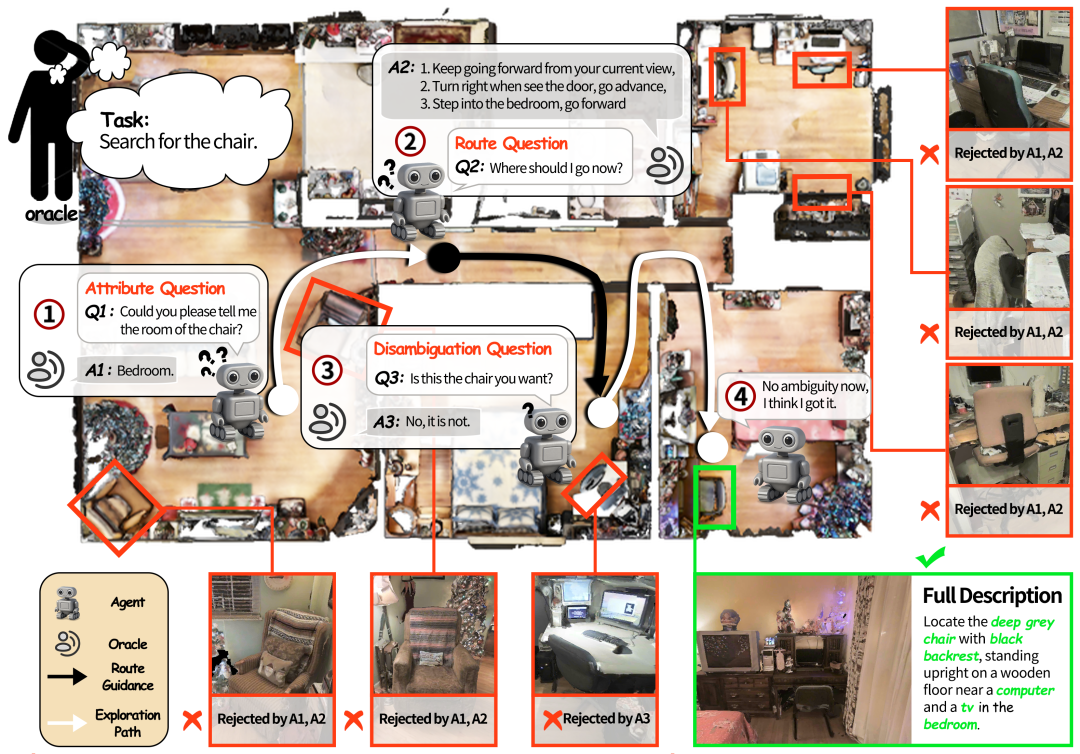
交互式实例导航示例:用户要求机器人找到场景中某一张凳子(绿框),但存在大量相似干扰项(红框),因此机器人需在探索中结合观察主动提问,逐步缩小候选范围,直到锁定目标。
构建 VL-LN 基准:
面向 IIGN 任务的自动化数据收集及评测
语言交互是人们日常交互最常见的形式之一,具身智能体要更好地融入人类生活也需要具有进行这种高效的信息交流形式的能力。不同于传统 VLN 仅仅聚焦 “导航动作(Navigation)执行得好不好”,VL-LN 还关注机器人能否在导航过程中与人类进行高效的语言交互(Language+Navigation)来提升任务的成功率与效率。
为此,VL-LN 面向交互式实例导航任务构建了一套自动化数据收集管线,并依托 InternVLA-N1 标准化模型训练与评测。
自动化数据收集管线
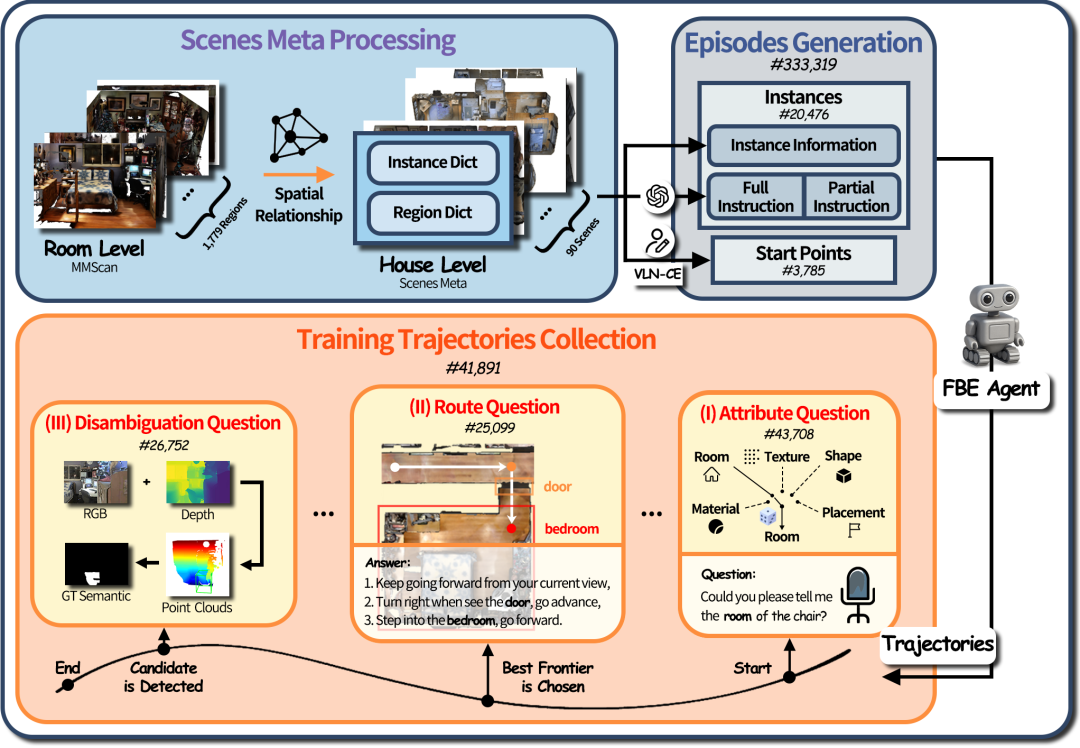
交互式实例导航数据收集流程
数据收集包含三个步骤,作者首先整理了场景元数据,进而生成能用于在线采样的序列(episode)数据,最后在规则驱动的交互机制下批量采集交互导航训练轨迹(trajectory),具体内容包括:
场景元数据处理:基于 MMScan 对 MP3D 场景的标注信息,将按房间分散的物体信息整合成全屋级的元数据,主要包括两个字典:目标实例字典(instance dictionary,存储每个物体的空间关系、属性等基本信息)和区域字典(region dictionary,存储房间的位置、物体等信息)
序列生成:每个有效序列由起始位姿、导航指令、目标实例的可停止视点三个主要信息组成。针对每一个目标实例作者均提供两个版本的导航指令。一种导航指令只有目标实例的类别(Partial instruction,用于交互式实例导航任务,必须靠对话消歧),另一种导航指令是能在场景内唯一锁定目标实例的完整描述(Full instruction,可用于评测训练非交互的任务)。可停止视点(view point)指机器人在导航过程中可以合法停止并判定 “已找到目标” 的一组视点位置。
交互导航轨迹采集:该阶段主要采用一个集成了基于边界点的探索算法(Frontier-Based Exploration)与目标实例分割器的智能体。在数据采集过程中,智能体除探索未知区域外,还会按规则主动提出三类问题:属性(目标实例长什么样?)、路线(如何到达目标?)和目标消歧(是否为眼前的实例?),从而生成相应的交互式导航轨迹。
通过该流程,作者构建了大规模交互式实例导航数据以支撑模型训练。下图给出了数据的总体统计。作为首个大规模交互式实例导航数据集,其主要优势在于:
-
规模:约 40k 导航序列,相比现有交互导航数据集(约 7k)提升一个量级;
-
多样性:覆盖 150+ 物体类别与 3 类问答(属性 / 位置 / 消歧),自由组合形成丰富训练样本;
-
难度覆盖:包含长时程轨迹(steps > 300)与多轮对话样本(dialog turns > 5),覆盖复杂困难场景。
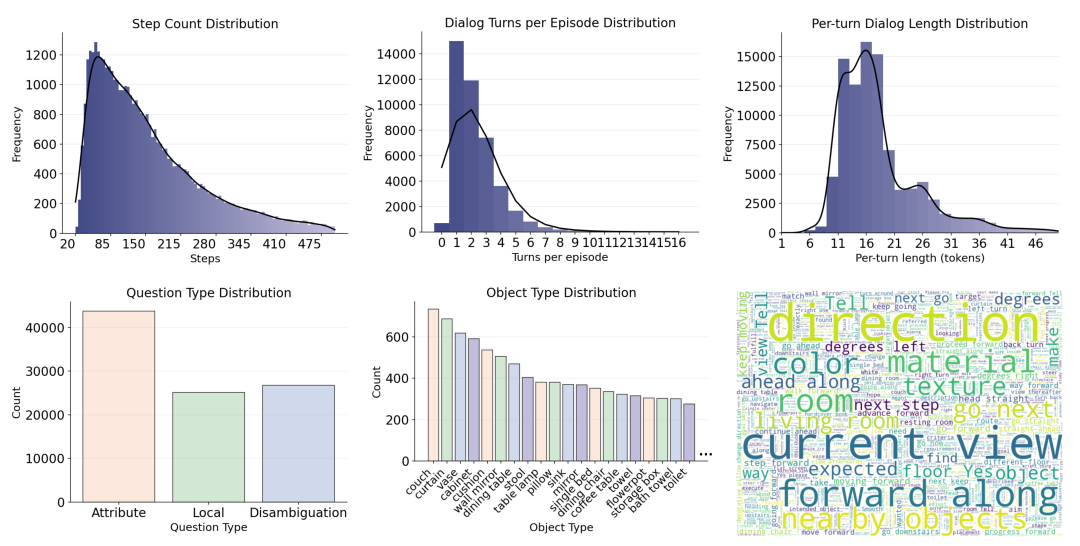
第一行分别展示了每条轨迹的路径步数、对话轮数和每轮对话长度的频率直方图;第二行展示了问题类型与目标类型的统计结果,以及对话中高频词的词云图。
NPC 支撑的自动化在线评测基准
为了评测智能体完成交互式实例导航(IIGN)的能力,并与非交互式实例导航(IGN)进行对比,VL-LN 基准提供了可用于测试两类任务的测试集。针对交互式实例导航的自动化评测,VL-LN 还实现了一个由 GPT-4o 驱动的 NPC,它能够回答智能体在导航过程中提出的问题。此外,为了评估智能体提问效率,VL-LN 定义新的指标 MSP(Mean Success Progress),用于衡量主动对话带来的增益。
从结果到原因:
交互式实例导航的能力与挑战
通过使用不同的数据对 Qwen2.5-VL-7B-Instruct 进行微调,作者训练了三个模型。具体训练所使用的数据如下:
-
VLLN-O (object):VLN + ObjectNav 轨迹数据
-
VLLN-I (instance):VLN + ObjectNav + IGN 轨迹数据
-
VLLN-D (dialog):VLN + ObjectNav + IIGN 轨迹数据(论文的核心模型)
评测同时覆盖两类任务:
-
IIGN(交互式实例导航):允许提问(对话轮数限制在 5 轮)
-
IGN(实例导航):不允许对话,但提供足以唯一锁定目标实例的全量指令
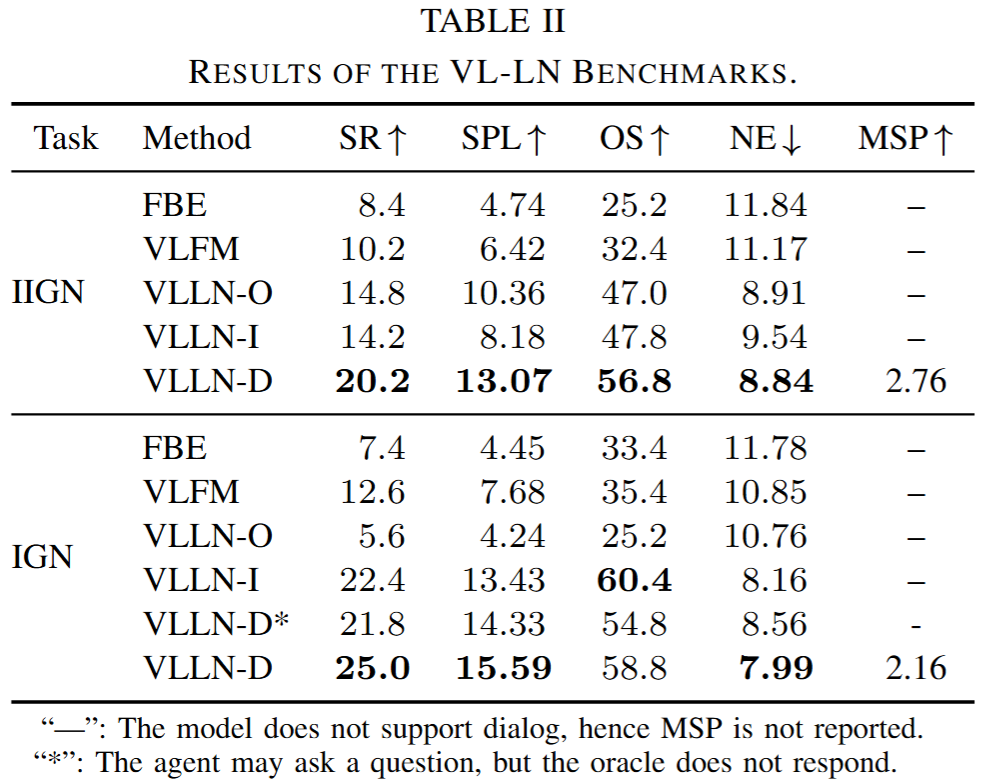
实验结果如下表所示
为了进一步确定模型在交互式实例导航任务上的性能和瓶颈,研究团队对实验结果进行系统性复盘,并将实验结论总结如下:
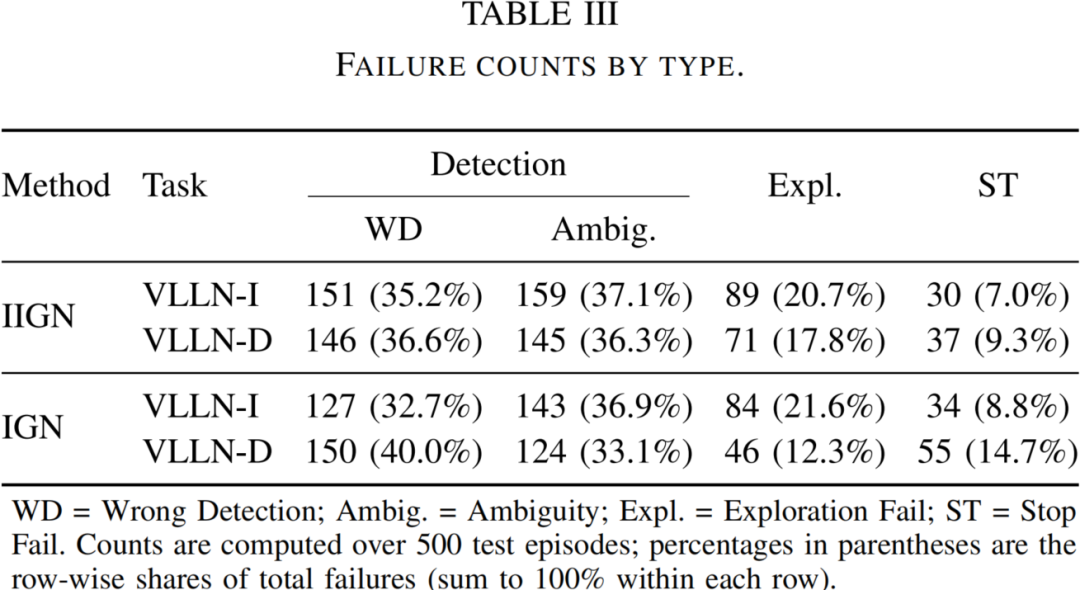
VL-LN Bench 错误类型分布
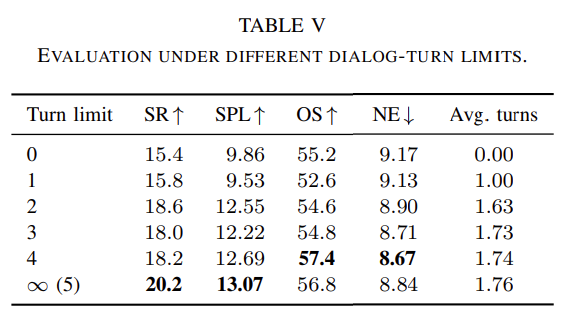
不同对话轮次上限下的 IIGN 性能
对话消歧在任务存在歧义时显著提升成功率:在 IIGN 与 IGN 上,具备提问能力的 VLLN-D 成功率均高于仅会探索的 VLLN-I,成功率分别提升 6.0% 与 2.6%。在对话轮次上限消融中,随着上限由 0 增至 5,VLLN-D 的 SR 由 15.4% 提升至 20.2%。
物体 — 图像对齐是核心瓶颈:无论在 IIGN 还是 IGN 任务中,约 70% 的失败都源于目标未被成功检测,说明性能瓶颈主要不在导航策略,而在于目标实例与图像观测之间的对齐能力。
相较于全量信息设置,问答机制带来的信息增益仍然有限:VLLN-D 在 IIGN 上的成功率为 20.2%,低于其在无法提问、但具备全量信息的 IGN 上的 21.8%,说明对当前模型而言,对话带来的增益仍弱于信息补全带来的增益。
与人类仍有显著差距:论文设置人类 IIGN 测试(一人负责提问与探索,另一人负责回答),结果显示人类平均仅需 2 轮对话即可达到 93% 成功率,表明当前模型与人类水平仍存在巨大差距。
结语
VL-LN Bench 是一个面向长时程交互式实例导航(IIGN)任务的高质量、高挑战且体系完备的评测基准,可系统评估智能体在 3D 环境中的长程探索、实例级目标识别与对话消歧能力。
与此同时,基准配套自动化数据采集管线与 NPC 评测机制,为交互式导航能力的训练与评估提供了一条可规模化、可复现的标准化路径。评测结果清晰表明:引入主动对话能够显著提升智能体在 IIGN 与 IGN 任务中的整体表现,但同时也揭示了当前方法在实例级感知对齐与高信息增益提问策略等关键环节上仍存在明显短板,为未来面向空间智能体的 “会走” 到 “会边走边问” 的技术演进提供了研究方向与启发。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com