AutoLink提出一种新型Schema Linking方法,通过智能体自主探索数据库,突破大规模Text-to-SQL瓶颈,实现高效Schema链接。
原文标题:AutoLink首创自主扩展模式链接,突破大规模Text-to-SQL瓶颈
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、AutoLink中提到的智能体动作空间设计,@retrieve_schema、@explore_schema和@verify_schema这三个动作分别起到了什么作用?如果让你来设计,你会如何改进或增加新的动作?
3、AutoLink在Spider 2.0-Lite数据集上的实验结果显示,其严格召回率(SRR)提升显著,但SQL执行准确率(EX)略低于ReFoRCE。这说明了什么问题?未来AutoLink有哪些改进方向?
原文内容

本文约5300字,建议阅读10分钟本文介绍了 AutoLink 以探索式方法实现大规模数据库高效 Schema 链接。
Text-to-SQL(又称 NL2SQL)是一项将用户的自然语言问题自动转换为 SQL 查询的任务,其目标是让不懂 SQL 的用户,也能直接通过自然语言访问数据库。
例如,用户只需问一句:“近三年每个城市的销售额是多少?”,系统就能自动生成并执行对应的 SQL 查询来获取数据库中对应的数据。
近年来,大语言模型(LLM)在理解自然语言和生成结构化文本方面展现出了惊人的能力,使得 Text-to-SQL 再次成为研究和工业界的热点方向。
当前主流的 LLM-based Text-to-SQL 系统,通常采用如下范式:
将用户问题 + 数据库 Schema(表名、列名、主外键等信息)一起输入给模型,让模型生成 SQL语句。
在中小规模数据库中(如spider),这种方式简单直接、效果也不错。但当我们把目光投向真实的工业数据库时,问题很快就显现出来了。
现实中的工业数据库,往往包含上百张表、上千甚至上万列字段。如果将完整的Database Schema 一股脑地输入给 LLM:
-
输入 token 急剧膨胀,计算成本和延迟不可接受;
-
大量与当前问题无关的表和列构成强噪声,反而干扰模型判断;
-
模型的注意力被稀释,SQL 生成性能甚至会下降。
但另一方面,用户的问题通常只涉及数据库中较小的一部分结构。这就引出了 Text-to-SQL 中一个至关重要、但又极其棘手的子任务:Schema Linking(模式链接)。

论文标题:
AutoLink: Autonomous Schema Exploration and Expansion for Scalable Schema Linking in Text-to-SQL at Scale
论文链接:
https://arxiv.org/abs/2511.17190
代码链接:
https://github.com/wzy416/AutoLink
1、什么是 Schema Linking?
Schema Linking 的目标很明确:
在生成 SQL 之前,先从庞大的数据库 Schema 中,找出与用户问题真正相关的表和列。
通过模式链接,我们可以将完整 Schema ( ) 压缩为一个与问题相关的子集 ( ),再交给 LLM 去生成 SQL,从而实现:
-
减少输入噪声
-
降低 token 成本
从直觉上看,这是一个“显而易见”的步骤。但真正把 Schema Linking 做好,尤其是在大规模数据库场景下,远比想象中困难。
2、现有Schema Linking方法难以扩展
现有的 Schema Linking 方法大致可以分为两类,我们称之为:
数据库级(Database-level)模式链接
这类方法通常一次性输入整个数据库 Schema,让 LLM 在“全局视角”下直接推理哪些表和列是相关的,代表方法包括 MCS-SQL、SQL-to-Schema 等。
它们的问题在于:
-
必须输入完整 Schema,在大数据库中几乎不可扩展;
-
想要提高召回率,往往需要多次采样、多轮解码,成本极高;
-
当 Schema 规模进一步增大时,性能迅速退化。
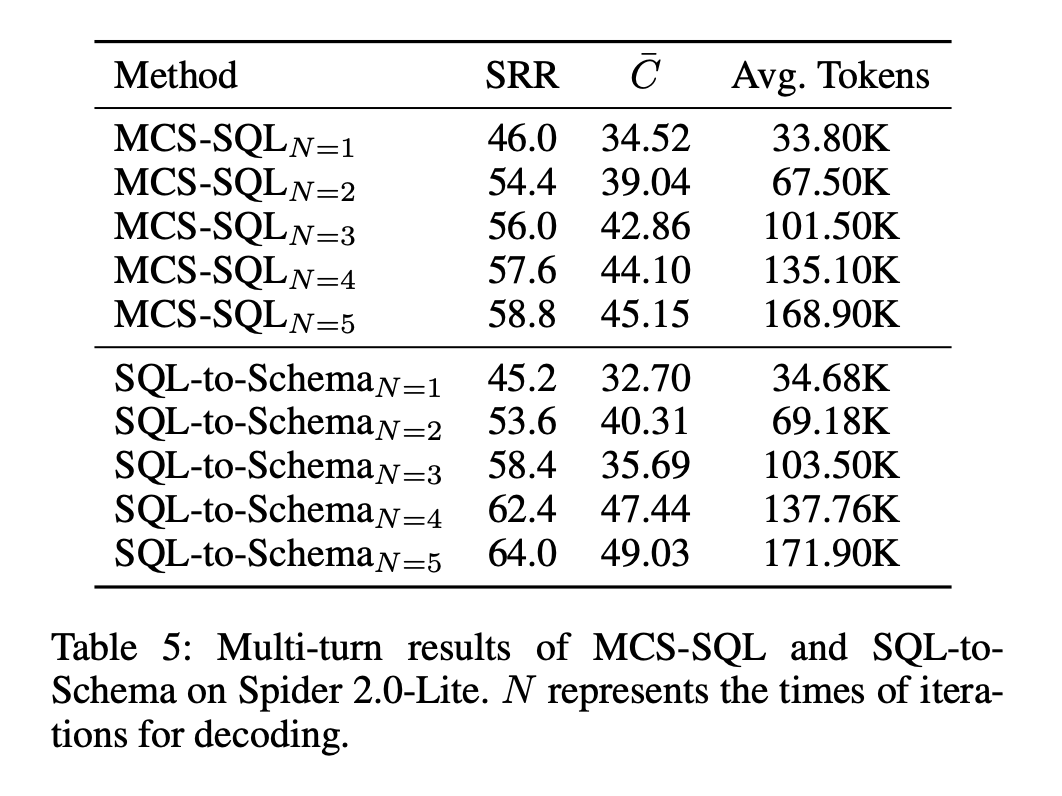
如上表所示,MCS-SQL 和 SQL-to-Schema 方法可以通过多轮 sampling-decoding 来提升 Schema Linking 的召回率。
然而,这种做法存在明显的饱和效应:当解码轮数从 1 增加到 2 或 3 时,严格召回率(SRR)确实有较大提升,但随着轮数继续增加,两者的增益迅速减小,并逐步趋于上限。
换言之,继续增加解码次数,很难再召回新的关键信息。
更关键的是,token 消耗几乎随解码轮数线性增长。
这意味着,即使通过堆叠解码轮数可以获得有限的召回提升,其计算成本却不可避免地持续上升,使得数据库级方法难以在大规模数据库场景下同时兼顾效果与效率,也难以在可控成本内达到较好的 schema 召回率。
数据库元素级(Element-level)模式链接
另一类方法将 Schema 拆解为“表/列级别”的独立元素,对每一个表或列分别判断是否与问题相关,例如基于dual-encoder、cross-encoder 或 LLM 打分的方式(如 CHESS)。
它们的问题同样明显:
-
计算复杂度随 Schema 规模线性增长,在工业场景下难以承受;
-
为了保证高召回,往往需要保留大量候选列,噪声重新回流;
-
在“高召回”和“低噪声”之间存在天然的权衡困境。
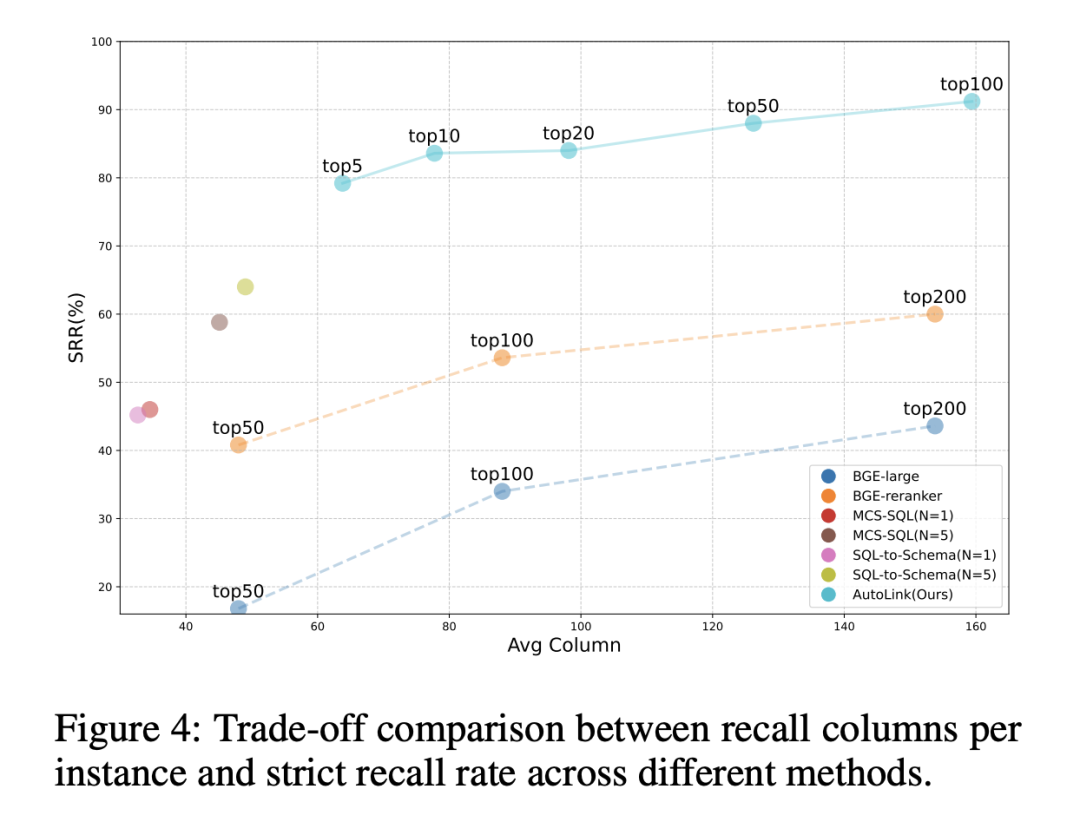
如上图所示,无论是基于双编码器(如 BGE-Large)还是交叉编码器(如 BGE-Reranker)的模式链接方法,要获得较高的 schema 严格召回率,往往需要召回大量列作为候选。
当召回列数较少时,其严格召回率明显受限;只有在将 Top-k 扩展到 100 甚至 200 列后,性能才逐步提升。
回顾现有方法,我们发现它们几乎都隐含着一个假设:
Schema Linking 是一个一次性、静态的筛选问题。
但如果我们换一个视角,去观察一个真正的人类数据库工程师是如何面对一个陌生的大型数据库的,会发现事情并不是这样。
3、人类工程师是如何“链接Schema”的?
当一个工程师面对一个不熟悉的数据库时,他通常不会把整个 Schema 从头到尾读一遍;或者一次性决定“哪些表和列是有用的”。
相反,他更可能采用一种探索式、渐进式的工作方式:
1. 先根据问题的大致语义,猜测一小部分可能相关的表或字段;
2. 通过简单的 SQL 查询或元数据查看,验证这些猜测是否合理;
3. 发现缺失信息后,再有针对性地继续查找、补充Schema;
4. 重复这一过程,直到“刚好足够”回答问题为止。
这是一个交互式、动态扩展、逐步收敛的过程,而不是一次性的筛选。
4、AutoLink的核心动机:把Schema Linking变成“数据库探索”
基于这一观察,我们在 AutoLink 中提出了一个核心思想:
Schema Linking 不应该是一次性的过滤,而应该是一个“自主探索 + 逐步扩展”的过程。
具体来说,AutoLink 不再要求模型一开始就看到完整数据库 Schema,而是:
-
从一个小而不完备的初始 Schema 出发;
-
由 LLM 驱动的智能体(Agent)自主决策:
-
当前 Schema 是否足以回答问题?
-
还缺哪些关键信息?
-
通过语义检索+数据库探索+验证反馈,不断补全 Schema;
-
最终构建一个高召回、低噪声、可扩展的 Schema 子集。
这种方式不仅更符合人类工程师的工作逻辑,也天然具备良好的可扩展性:无论数据库有几百列还是几千列,模型都只看它需要看的那一部分。

5、智能体交互环境构建
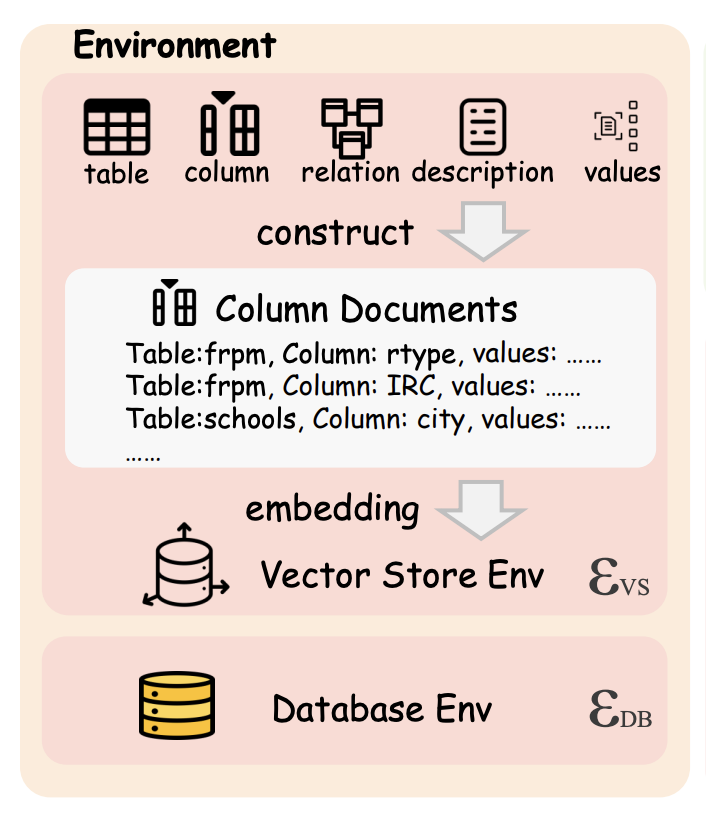
Database Environment
数据库环境( )为智能体提供直接访问数据库的能力,支持执行 SQL 查询以探索表结构、列信息、键关系及数据样本。
执行结果 以结构化文本返回,包括成功查询的前几行数据、空结果提示、执行超时或错误信息:
Schema Vector Store
模式向量存储环境( )构建过程包括:
对数据库中所有列构建文本表示,包括列名、表名、数据类型、描述、主外键信息;使用预训练文本编码器(bge-large-en-v1.5)将列文本编码为向量;
建立向量索引(Faiss),支持近似最近邻搜索,支持语义检索,输入自然语言查询 ,返回最相关的 个列,并组织为结构化模式片段:
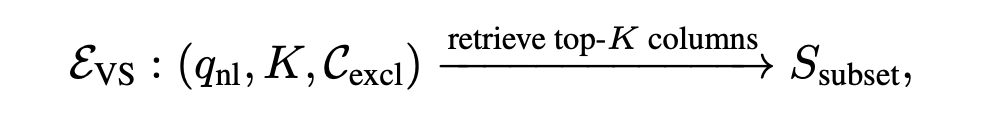
其中 为已经检索到的候选列,对于已经检索的列我们会在向量数据库索引中排除。 为检索到的结构化模式子集。
6、智能体动作空间
我们给智能体设计如下五种动作,智能体在每轮交互中可执行以下动作,分为有反馈和无反馈两类:
有反馈动作:
@explore_schema (SQL 查询):模型可以直接对数据库环境发起探索性 SQL 查询,不仅查看表结构,还能实际“看一眼数据”。
例如,它可以抽样列值、检查字段的取值范围,或验证某些关键词是否存在于某个字段中;同时,也可以通过 INFORMATION_SCHEMA 或 PRAGMA 等元数据接口,搜索潜在相关的表和列。
这一步的作用是建立对数据库的直观认知:哪些列可能和问题有关?字段语义是否与直觉一致?
-- Check sample values containing specific keywords (e.g., "INTOX")
SELECT DISTINCT descript
FROM incidents_2016
WHERE descript LIKE '%INTOX%'
LIMIT 5;
-- Filter columns by dual conditions (table attributes + column semantics) via metadata
SELECT column_name
FROM census.INFORMATION_SCHEMA.COLUMNS
WHERE table_name LIKE '%tract%' AND table_name LIKE '%2018%'
AND LOWER(column_name) LIKE '%income%'
LIMIT 5;
如上所示,智能体可以生成 SQL 查看一个字段中是否存在某些值(例如查看‘incidents_2016’表的‘descript’字段中是否有值包含‘INTOX’),或者查看表列名元数据(例如查看数据库‘census’中是否有表名包含‘tract’和‘2018’且其中是否有列名包含‘income’)。
@retrieve_schema (自然语言查询):当模型意识到当前 Schema 仍然不完整时,它可以向 Schema 向量库发起更“聪明”的检索请求。不同于简单的关键词重写,这里的检索查询可以是模型推断出的“虚拟列名”或抽象语义描述。
例如,对于用户问题 “What’s the score?”,单独看问题本身是高度歧义的;但一旦结合已知表名(如 students),模型就能推断出目标应是 exam score、final grade 等学业成绩相关字段,并据此进行更精准的语义检索。
这一步使模型能够发现问题中未被显式提及、但语义上必需的 Schema 元素。
@verify_schema (SQL查询):在收集到一组候选 Schema 后,模型可以先构造一个最小可执行的验证查询,测试这些 Schema 是否真的能支撑问题的解答。
如果执行失败,数据库返回的错误信息(例如“列不存在”或“表不存在”)会被当作高精度的诊断信号,明确指出当前 Schema 缺失的具体部分。
这使得 Schema Linking 不再是“猜对或猜错”,而是一个有反馈、有方向的修正过程。
无反馈动作:
@add_schema (表名/列名):每当模型通过探索、检索或验证确认了新的有效 Schema 元素,就会通过 @add_schema 将其加入当前候选集合。
随着这一过程不断迭代,Schema 集合会逐步从一个不完整的初始假设,演化为一个完整的最终 Schema。同时该操作必须与有反馈动作配对使用:
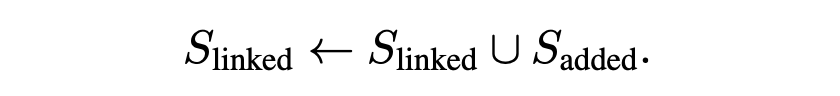
@stop:终止交互过程,当智能体判断模式已完备或达到最大轮数(如 10 轮)时触发。
7、AutoLink算法流程:从初始不完整schema到高recall链接
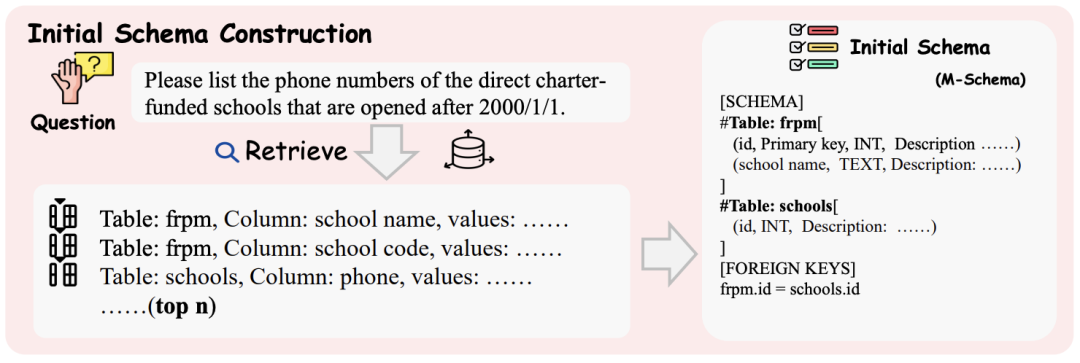
智能体接受的初始输入包括:
指令提示( ):定义智能体目标和可用动作的指令。
用户问题( ):原始用户问题。
完整表名列表( ):数据库中的所有表名(不包括任何列名,表的总数通常是可管理的),这为智能体提供了必要的结构上下文。
-初始模式( )通过 获取:该初始模式是通过对模式向量存储环境 的单个非智能体驱动的检索获得。
我们使用原始用户问题 作为查询来检索一组初始候选列,从而创建初始模式 ,其中 n 是一个相对较大的超参数(例如 50 或 100),以确保与用户问题高度相关但可能不完整的初始模式元素集。
智能体决策:基于当前历史 ,智能体生成推理轨迹 和动作集合 :
其中 为基于提示的 LLM 策略, 封装在<think>标签中(推理过程), 封装在 <action>标签中(动作序列)。
环境执行:环境 接收动作 并返回观察 :
环境包括数据库环境 和模式向量存储环境 ,根据动作类型路由执行。
历史更新:当前轮次的三元组 被追加到历史中,形成新历史:
初始历史 为交互初始状态即智能体的初始输入(包含指令、用户问题、表名和初始模式)。
终止条件:当智能体输出 @stop 或达到最大轮数 (如 )时,迭代过程终止,将初始 schema 与 @add_schema() 操作添加的 schema 作为最终输出 。
AutoLink 将 Schema Linking 建模为一个多轮交互式决策过程,而非一次性的静态预测任务。
智能体从一个不完整、甚至存在明显缺失的初始 schema 出发,在每一轮中结合当前累计的历史信息,先进行内部推理,判断当前schema 是否足以回答用户问题,以及还缺少哪些关键信息。
随后,智能体选择合适的动作,与外部环境进行交互,主动探索数据库结构、检索潜在的 schema 元素,或通过最小可执行 SQL 对当前假设进行验证。
在这一过程中,每一次环境反馈都会被显式地记录并纳入后续决策。无论是数据样本、元数据信息,还是 SQL 执行产生的错误提示,都会成为新的线索,指导下一轮更有针对性的探索或检索。
随着交互轮次的推进,schema 集合通过 @add_schema 动作不断被补全和修正,从最初的粗粒度候选逐步演化为一个完整覆盖的高质量 Schema 子集。
当智能体判断当前 schema 已经能够稳定支撑问题求解,或达到预设的最大交互轮数时,迭代过程终止。
最终输出的 Schema Linking 结果由初始 schema 与交互过程中逐步确认并加入的 schema 元素共同构成。
通过这种“推理—行动—反馈—更新”的机制,AutoLink 实现了从不完整 schema 到高召回、高可靠 Schema Linking 的自适应演进,为后续 SQL 生成提供了更稳健的基础。
8、实验结果
我们在两个 benchmark 上评测 AutoLink:
-
Spider 2.0-Lite:平均 800+ 列,最大超过 3000 列;
-
BIRD:平均 80 列。
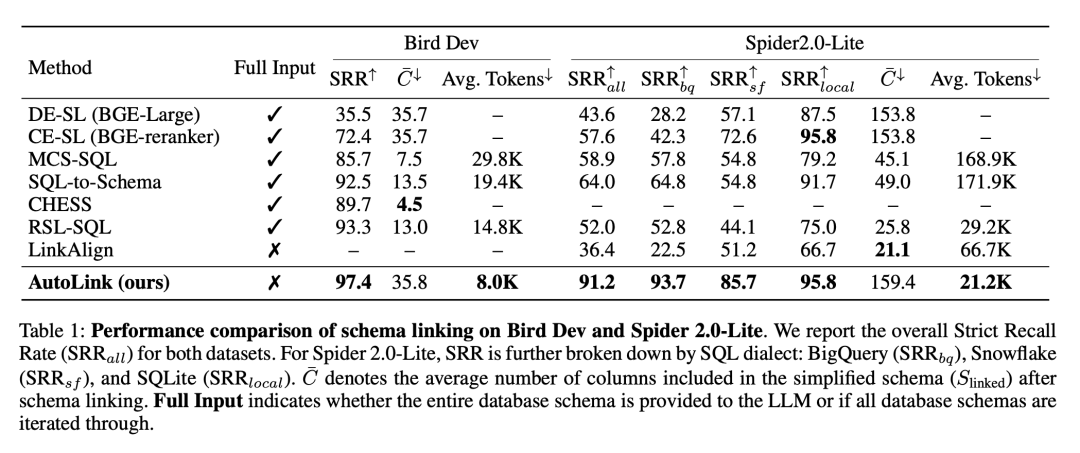
实验结果表明,AutoLink 在 Schema Linking 的召回效果与计算成本之间实现了显著更优的平衡。
在更具挑战性的 Spider 2.0-Lite 数据集上,AutoLink 的严格召回率(SRR)相比次优方法 SQL-to-Schema 提升了 27.2%,同时将最大 token 消耗降低了 87.7%。
即便与双编码器 / 交叉编码器方法(DE-SL、CE-SL)相比,在召回列数相近的条件下,AutoLink 的 SRR 仍平均高出 约 40%。
进一步分析发现,依赖完整 Schema 或多轮 sampling-decoding 的方法(如 MCS-SQL、SQL-to-Schema、RSL-SQL)在大规模数据库上表现明显退化。
虽然这些方法在小规模数据库(如 BIRD)上尚可接受,但在 Spider 2.0-Lite 这类长上下文场景中,token 开销急剧上升,而 SRR 提升却迅速饱和。
实验表明,盲目增加解码轮数只能带来极其有限的收益,且不同轮次之间的结果多样性较低,使得这类方法难以在可控成本下达到与 AutoLink 相当的召回规模与效果。
相比之下,AutoLink 在不同数据规模下均保持稳定优势:即便在仅召回少量列的情况下,仍能取得更高的SRR。同时,与 CHESS、LinkAlign 方法不同,AutoLink 并不追求只保留 gold SQL 所需的最少列。
实验显示,过度压缩 Schema 会显著增加漏召回风险(如 LinkAlign 仅 36.4% SRR),从而削弱后续 SQL 生成的可靠性。
AutoLink 通过可控扩展的 Schema 探索,在召回完整性与噪声控制之间取得了更稳健的平衡。
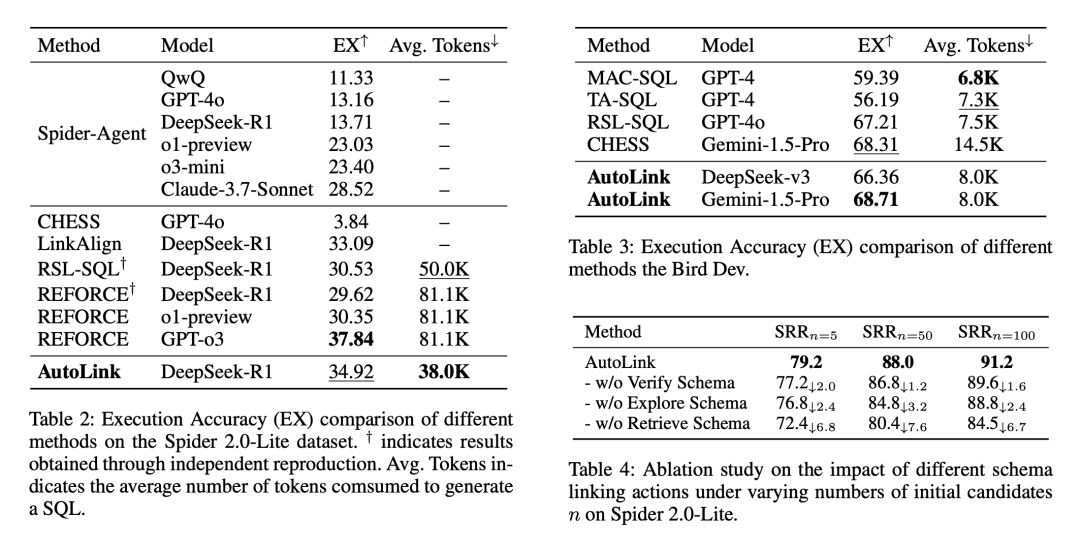
从表 2 和表 3 可以看出,在 SQL 生成方面,AutoLink 在 SQL 的执行准确率(EX)上表现出竞争力。
在 Spider 2.0-Lite 上,AutoLink 使用 DeepSeek-R1 达到了 34.92% 的 EX,虽略低于 ReFoRCE(37.84%),但令牌消耗仅为 38.0K,不到 ReFoRCE 的一半,展现出更高的效率。
在 Bird-Dev 上,AutoLink 使用 Gemini-1.5-pro 取得了 68.71% 的 EX,优于 CHESS(68.31%)和 RSL-SQL(67.21%)。
这些结果表明,AutoLink 通过高质量的模式链接为后续 SQL 生成提供了充分且精准的上下文,从而在不显著增加计算成本的前提下,实现了与当前最优方法相当的生成性能,尤其在大规模复杂数据库中表现出更强的实用性和可扩展性。
同时消融实验进一步证明了@retrieve schema, @explore_schema 和 @verify schema 三个动作对于模式链接过程的增益。其中检索操作发挥了最关键的作用。
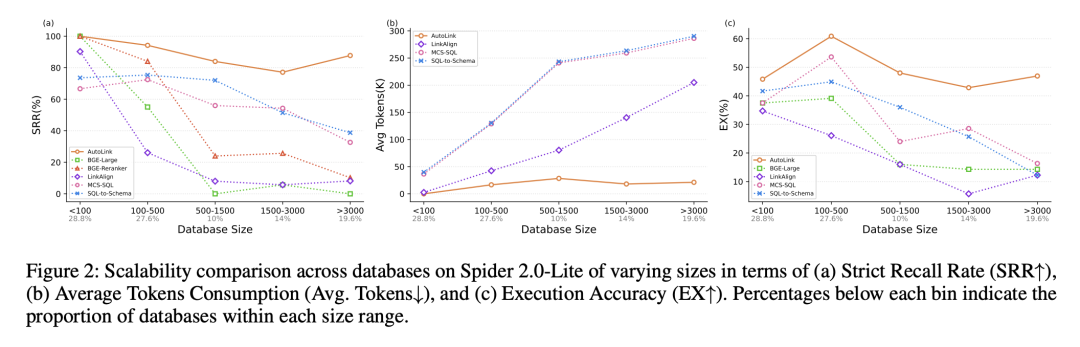
如上图所示,随着数据库规模增大,所有 Schema Linking 方法的严格召回率(SRR)都会明显下降,但 AutoLink 的退化速度显著更慢。
在包含超过 3,000 个列的大型数据库中,所有基线方法的 SRR 均下降到 40% 以下,而 AutoLink 仍能保持接近 90% 的 SRR,展现出极强的数据库规模鲁棒性。
在 token 消耗方面,数据库规模越大,基线方法的开销增长越明显;相比之下,AutoLink 在所有规模下始终保持最低的平均 token 使用量。
这一优势来自其“由小到大”的迭代式 Schema 扩展策略,使得输入规模随数据库增大几乎不发生显著变化。
更重要的是,实验清晰地揭示了一个关键规律:Schema Linking 的 SRR 与最终 SQL 的执行准确率(EX)高度正相关。
当 Schema 不完整时,SQL 生成模型即使不产生幻觉,也无法补全缺失的表和列,从而不可避免地产生错误 SQL 查询。
由于 AutoLink 在各个规模下都保持了最高的 SRR,其在 SQL 执行准确率上也始终领先,尤其在超大规模数据库中,与基线方法对比形成了显著优势。
9、结语
AutoLink 将 Schema Linking 从一次性预测转变为可交互的智能体过程。
通过语义检索与轻量级 SQL 探测的协同,引导大模型按需、渐进式地构建高召回且低噪声的 Schema 子集,在大规模数据库上同时实现了更高的召回率、更低的 token 成本和更强的可扩展性,为工业级 Text-to-SQL 提供了一种更稳健、实用的解决方案。
