斯坦福&英伟达提出TTT-Discover,通过测试时强化学习,让AI在多项任务中超越人类专家,为持续学习带来新思路。
原文标题:比人类专家快2倍,斯坦福联合英伟达发布TTT-Discover:用「测试时强化学习」攻克科学难题
原文作者:数据派THU
冷月清谈:
该方法将单个测试问题定义为一个环境,并在其中执行强化学习,但目标是只为了解决当前问题,并产出一个优秀的解决方案。TTT-Discover通过引入熵目标函数和状态复用策略,优先考虑最有希望的解决方案。实验结果表明,该方法在多个领域都取得了突破性进展,包括在Erdős最小重叠问题上刷新了记录,在GPUMode竞赛中开发出更快的GPU内核,并在AtCoder测试和单细胞分析中超越了现有最佳方案。该研究为持续学习开辟了新的可能性。
怜星夜思:
2、TTT-Discover目前只能应用于具有连续奖励的问题,那么,如何将其扩展到奖励稀疏或者二元奖励的问题上?例如,在数学证明或科学假说验证中,如何设计有效的奖励机制?
3、文章提到TTT-Discover的计算成本较低,每个问题只需花费几百美元。那么,这种方法是否具有大规模推广的潜力?如果大规模应用,可能会对科研模式产生哪些影响?
原文内容

来源:机器之心本文约2500字,建议阅读10分钟
在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?
一个普遍的解法是「测试时搜索」(Test-time search),即提示一个冻结的(不更新参数的)大语言模型(LLM)进行多次尝试,这一点类似人类在做编程作业时的「猜」解法,尤其是进化搜索方法(如 AlphaEvolve),会将以往的尝试存入缓冲区,并通过人工设计、与领域相关的启发式规则生成新的提示。
可是,尽管这些提示能够帮助 LLM 改进以往的解法,但 LLM 本身并不会真正提升,就像一个学生始终无法内化作业背后的新思想一样。
实际上,能够让 LLM 真正进步的最直接方式是学习。
尽管「学习」和「搜索」都能随着算力扩展而良好地增长,但在 AI 的发展历史中,对于围棋、蛋白质折叠等这类困难问题,「学习」往往最终超越了「搜索」。因为,科学发现本质是:超出训练数据与人类现有知识的 out-of-distribution 问题。
为此,斯坦福大学、英伟达等机构联合提出一种新方法:在测试时进行强化学习(RL),即让 LLM 在尝试解决特定测试问题的过程中持续训练自己。

-
论文链接:https://www.alphaxiv.org/abs/2601.16175
-
项目地址:https://github.com/test-time-training/discover
具体来看,团队只是把单个测试问题定义为一个环境,并在其中执行强化学习(RL),因此任何标准 RL 技术原则上都可以应用。然而,需要注意的是,这里的目标与标准 RL 存在关键差异,这里的目标不是让模型在各类问题上平均表现更好,而是只为了解决眼前这一个问题,并且只需要产出一个优秀的解决方案,而不是平均产生多个良好的解决方案。
团队将该方法命名为「Test-Time Training to Discover」(TTT-Discover)。为了适应上述目标,其学习目标函数和搜索子程序都旨在优先考虑最有希望的解决方案 。
结果显示,该方法在多种任务上取得了好成绩,包括击败了 DeepMind 的 AlphaEvolve;数学领域 在 Erdős 最小重叠问题上取得了新突破;在 GPUMode 竞赛中,开发出了比人类最佳内核快两倍的全新 A100 GPU 内核;在 AtCoder 测试中超越了最佳 AI 代码和人类代码;在单细胞分析的去噪任务中取得最好成绩……
值得注意的是,该方法在使用开放模型 OpenAI gpt-oss-120b 基础上,计算成本非常低,通过使用 Thinking Machines 的API Tinker ,每个问题只需花费几百美元。
在业界看来,TTT-Discover 所提出的理念,或为持续学习打开了新的想象空间。

TTT-Discover 方法创新
下图展示了 TTT-Discover 的核心机制,展示 TTT-Discover 在测试阶段针对单个问题持续对大语言模型(LLM)进行训练,记 πθi 为在测试时训练第 i 步更新权重后的策略。该图绘制的是 TTT-Discover 在 GPUMode TriMul 竞赛中测试时,第 0 步、第 9 步、第 24 步以及第 49 步(最终阶段)的奖励分布情况,每一步都会生成 512 个候选解。
可以看到,随着训练过程的推进,LLM 逐渐生成更优的解,并最终超越了以往的最优结果(即人类最佳方案)。

需要注意的是,TTT-Discover 没有直接套用标准的 RL 算法(如 PPO/GRPO)。
因为团队认为,标准 RL 优化的是期望奖励(平均分),而科学探索只在乎最大奖励(最高分),只要能找到一个突破性的解,策略在其他时候表现差也没关系;这样的策略容易让发现探索仅仅止步于「安全但平庸」的高分区域,而不敢去尝试可能带来突破的高风险区域。另外,传统算法每次都是从头开始,无法逐步演化复杂解。
为此,团队引入两个关键组件来解决上述问题。
一是熵目标函数,作用是通过指数加权来极端地偏向高奖励样本。随着 β → ∞,熵目标函数趋近于最大值(max)。然而,团队发现,在训练早期若 β 过大,会导致训练不稳定;在训练后期若 β 过小,则随着改进幅度越来越微小,优势函数会逐渐消失,这说明为不同任务设定一个统一且固定的 β 常数是非常困难的。
为此,团队为每一个初始状态自适应地设置 β(s),通过约束由该目标函数诱导的策略的 KL 散度来实现。
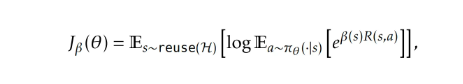
二是受 PUCT 启发的状态复用策略,采用该规则来选择初始状态。每个状态 s 的评分为:
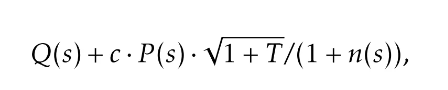
其中,Q (s) 表示当初始状态为 s 时所生成状态中的最大回报(如果 s 尚未被选择过,则取 R (s))。不同于以往研究中采用「平均回报」的做法,团队在 Q (s) 中使用的是子状态的最大回报,这也是关注的核心是从某个状态出发所能达到的最佳结果,而不是平均结果。这种设计确保搜索集中在最有前景的解决路径上,同时保持多样性。
整体来看,熵目标和 PUCT 复用策略的结合使 TTT-Discover 能够优先发现单一的最高奖励解决方案,而不是多个解决方案的平均表现。
结果评估
团队在四个截然不同的领域 —— 数学、GPU 内核工程、算法设计和生物学问题上评估了 TTT-Discover。
除了考虑潜在的影响力外,选择领域的标准还考虑到两个方面,首先,选择能够将自身表现与人类专家进行比较的领域,例如,可以通过与人类工程竞赛中的最佳提交方案或学术论文中报告的最佳结果进行对比来实现,比如数学和算法设计,可以说是近期相关工作取得非常大进展的领域之一。
在每个应用中,团队都报告了已知的人类最佳结果和 AI 最佳结果。
可以看到,在数学领域,关于构造数学对象(如阶跃函数)来证明不等式的更紧致边界 ——Erdős 最小重叠问题任务上,之前人类最佳表现是 0.380927、AI 最佳表现 (AlphaEvolve) 是 0.380924,而 TTT-Discover 刷新记录,拿到了 0.380876 的成绩。
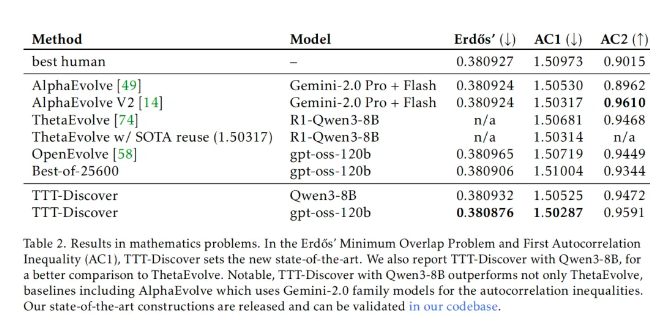
在 GPU 内核优化任务中,首先需要说明的是「新的最优解」(state of the art)意味着实现了比现有方案更快的内核实现。团队选择 GPUMODE 作为评测平台,因为其排行榜经过大量人类竞赛的充分验证,并配备了稳健的评测框架,同时,其基准测试避免了信噪比问题,即避免因操作过于简单或输入规模过小而使系统开销主导运行时间的情况。
结果是,团队的 TriMul 内核在所有 GPU 类型上均达到了当前最优水平。在 A100 上,TTT-Discover 找到的最佳内核比人类专家提交的最优方案快 50%,尽管在训练阶段团队的奖励函数并未在 A100 上直接计时。总体而言,在所有 GPU 类型上,该方法都相对于人类最佳结果实现了超过 15% 的性能提升。
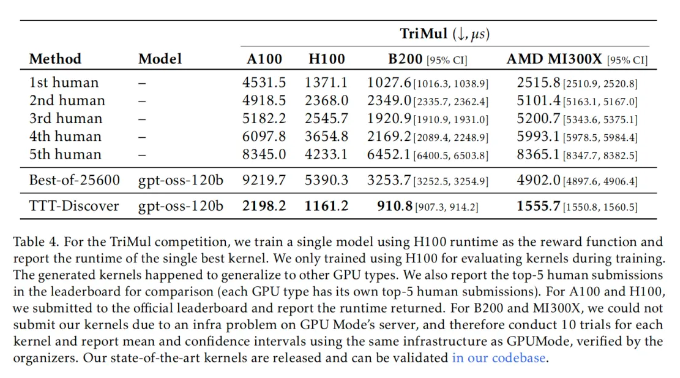
而在另外两项测试中,TTT-Discover 同样取得了非凡的成绩。
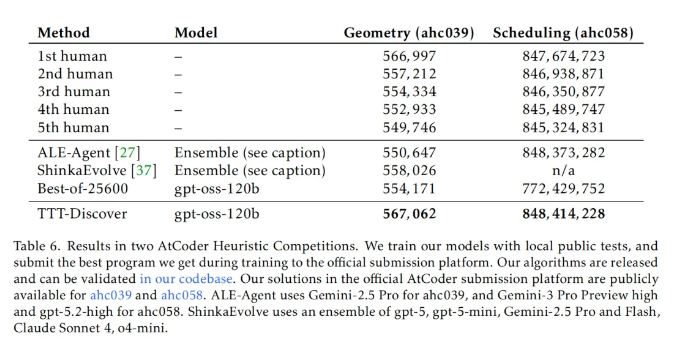
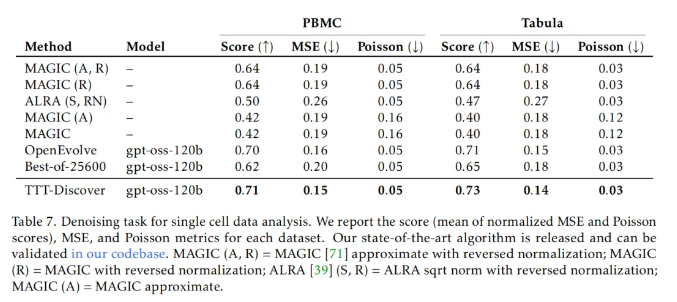
虽然当前 TTT-Discover 方法取得了非常好的成绩,但是团队也承认,该方法目前的形式只能应用于具有连续奖励的问题中,而未来工作最重要的方向是针对具有稀疏奖励或二元奖励的问题,比如数学证明、科学假说,或者不可验证领域的问题(物理、生物推理等)进行测试时训练。
编辑:文婧
