前 OpenAI 研究 VP 创立 Core Automation,挑战 Transformer 架构,探索具备“持续学习”能力的新型 AI 模型。
原文标题:挑战Transformer,前OpenAI研究VP宣布创业,拟融资10亿美元
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 Core Automation 计划使用的数据量比现有模型少 100 倍,你觉得这可能实现吗?如果实现了,对 AI 发展会带来什么影响?
3、文章最后提到 Core Automation 的远景目标包括建造“自我复制工厂”、研制自动生成定制设计的生物机器,甚至改造地外行星的生态。你觉得这些目标靠谱吗?
原文内容
Transformer 是当前 LLM 大发展的核心基础,但也有不少顶尖研究者更愿意探索其它道路。在这其中,甚至包括 Transformer 的创造者之一、Sakana AI 创始人联创兼 CTO Llion Jones。他今天还在 Sakana 的官推上发了一篇博客,题目便赫然是《为什么 Transformer 的这位创造者受够了 Transformer》。
https://x.com/SakanaAILabs/status/2016844349188034922
「我不是说我们应该扔掉 Transformer。但就我个人而言, 我正在大幅减少研究它们的时间。我明确地在寻找下一个目标。」他写道,「让我们一起加大探索力度。别再纠缠于同一个地方,去寻找下一座高峰吧。」
也恰在今天,The Information 报道揭示了前 OpenAI 研究 VP Jerry Tworek 创立的一家正在探索「下一座高峰」的新创业公司 Core Automation。
在效力 OpenAI 期间,Tworek 曾担任研究副总裁,负责强化学习领域的工作。此外,他还是 OpenAI 推理模型、编程工具和 AI 智能体开发的关键贡献者。
据知情人士透露,Core Automation 刚成立几周时间,目前正寻求 5 亿至 10 亿美元的融资。
报道说,根据向潜在投资者展示的材料,Tworek 计划采用一种与 OpenAI、Anthropic 等大厂截然不同的路径来开发 AI 模型。知情人士称,他希望打造具备「持续学习」(Continual Learning)能力的模型,即能够从现实世界的实践中即时获取知识。而现有的 AI 模型尚不具备这种「边练边学」的能力。
目前,这位研究员的创业计划尚处于早期阶段,其融资规模和产品路径仍可能发生变动。如果成功,或许我们可将 Core Automation 与 Safe Superintelligence 和 Thinking Machines Lab 并称为探索非 Transformer 方向的「OpenAI 三子」。
事实上,Core Automation 不是孤例,而是代表了业内一个规模虽小但日益壮大的群体。这些研究人员认为 AI 领域需要一场「彻底的变革」。
在他们看来,当前主流的模型开发技术虽然流行,但很难让 AI 在生物、医学等领域取得重大突破,且无法根除 AI 经常犯低级错误的顽疾。
据了解,Tworek 本月初离开 OpenAI,并在 X 上写道,此举是为了「探索那些在 OpenAI 内部难以推进的研究方向」。
在融资材料中,Core Automation 表示仍会使用大型神经网络 —— 这是当今前沿模型底层的数学基础。但公司将重新审视模型开发的每一个环节,甚至包括训练神经网络的最基本方法「梯度下降」(Gradient Descent)。
知情人士表示,Tworek 计划开发一种对数据量和计算资源需求更低的模型。他们将通过构建全新的架构来取代目前统治市场的 Transformer 架构。此外,Tworek 还希望将原本割裂的模型训练步骤整合为单一的流程。
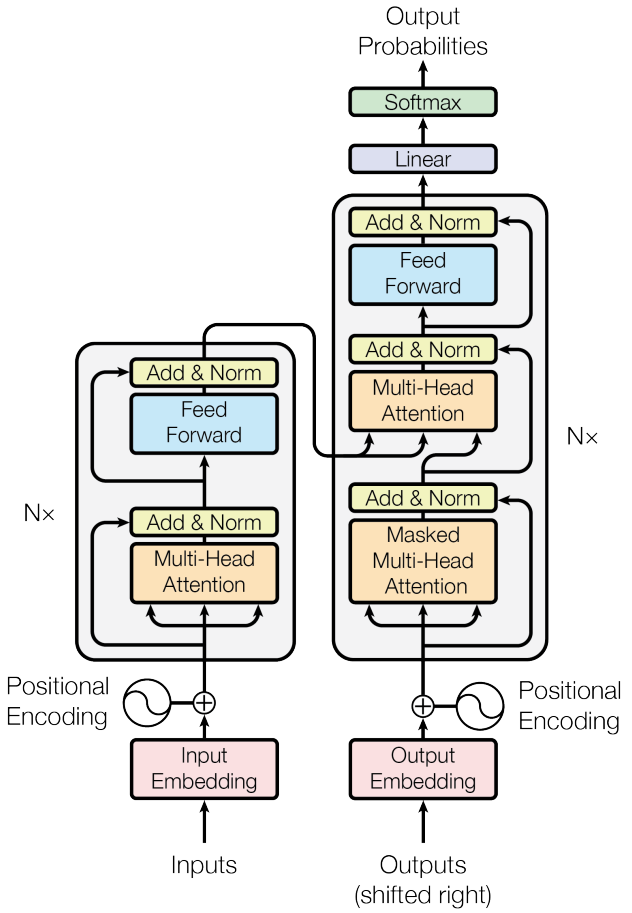
Transformer 架构
在追求「持续学习」这一目标上,Core Automation 与另一家实验室 Safe Superintelligence(由前 OpenAI 首席科学家 Ilya Sutskever 共同创立)不谋而合。Sutskever 此前也表达过类似的愿景,即希望模型能够通过在现实世界中的部署来不断进化。此外,从 Meta 离职的 Yann LeCun 也在探索类似的方向。
当然,OpenAI 和 Anthropic 等巨头也并未忽视「持续学习」。
一些研究者认为,通过对现有基于 Transformer 的模型进行微调,同样可以实现类似的学习特性,而无需彻底推倒重来。
媒体表示,Tworek 宏大的融资目标反映了资本市场对「新实验室」的持续狂热。近几个月来,尽管许多此类公司尚无收入甚至没有产品,但动辄就能拿到数亿美元的投资。
例如:初创公司 Humans& 本月以 44.8 亿美元的估值拿下了 4.8 亿美元种子轮融资,投资者包括英伟达和贝佐斯;Mira Murati 的 Thinking Machines Lab 最近也在洽谈一笔 40 亿至 50 亿美元的融资,投后估值预计超过 500 亿美元。不过相比之下,Thinking Machines 进展更快,去年已推出了模型定制产品并产生了部分收入。
Tworek 早在 2019 年就加入了 OpenAI。在他的构想中,Core Automation 的研究团队将围绕一个名为「Ceres」(取自罗马谷物女神及矮行星之名)的单一算法和模型展开工作。这与主流厂商的做法大相径庭。通常,大型模型的训练会分为预训练(使用海量互联网数据)、中期训练和针对编程、医疗等领域的后期微调。
按照 Tworek 的目标,这款模型所需的数据量将比现有最先进模型少 100 倍。
模型研发成功后,公司将开发 AI 智能体来自动化生产自己的产品。其远景规划首先是工业自动化,最终目标甚至包括建造「自我复制工厂」、研制自动生成定制设计的生物机器,乃至于改造地外行星的生态。
你看好这些新方向的探索吗?
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com