AlphaGo 之父 David Silver 离职创业,目标直指超越人类的超级智能。强化学习 or die?
原文标题:AlphaGo之父David Silver离职创业,目标超级智能
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 Silver 认为 LLM 受限于人类知识,需要 AI 自己探索。那么,你认为完全摆脱人类知识的 AI,会带来哪些伦理问题和社会影响?
3、Silver 坚持强化学习路线,你认为这种路线是否能最终通往 AGI (通用人工智能)?
原文内容
又一位 AI 大佬决定创业,这位更是重量级。
《财富》等媒体本周五报道说,在 Google DeepMind 众多著名突破性研究中发挥关键作用的知名研究员 David Silver 已离开公司,创办了自己的初创公司。

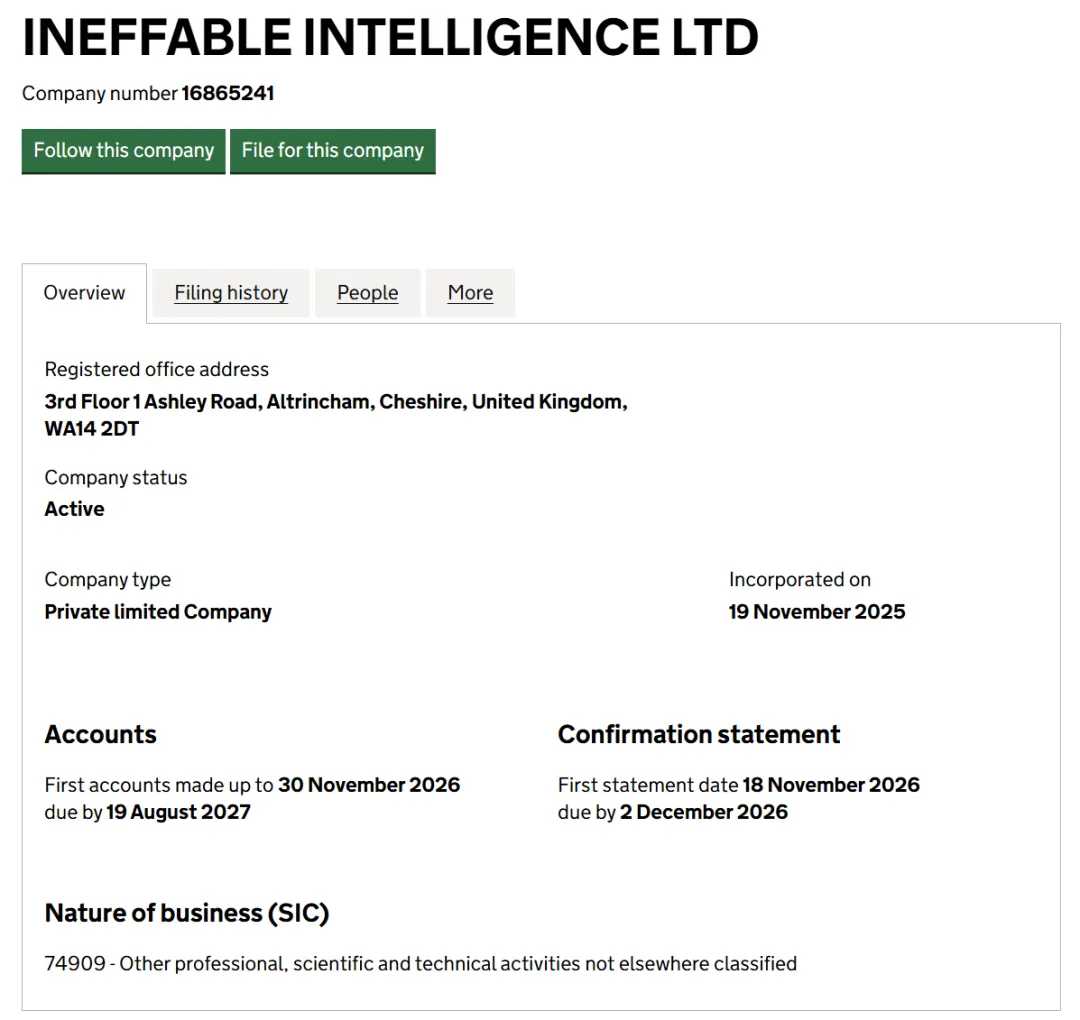
知情人士称,Silver 正在伦敦创办一家名为 Ineffable Intelligence 的新公司。该公司目前正在积极招聘人工智能研究人员,并寻求风险投资。
Google DeepMind 已于本月初向员工宣布了 Silver 的离职消息。Silver 在离职前的几个月里一直处于休假状态,并未正式返回 DeepMind 工作岗位。
Google DeepMind 的一位发言人在电子邮件声明中证实了 Silver 离职的信息,表示:「Dave 的贡献是无价的,我们非常感谢他对 Google DeepMind 工作所做出的贡献。」
根据英国公司注册处 Companies House 的文件显示,Ineffable Intelligence 公司成立于 2025 年 11 月,Silver 于今年 1 月 16 日被任命为该公司董事。
此外,Silver 的个人网页现在将他的联系方式列为 Ineffable Intelligence,并提供了一个 Ineffable Intelligence 的电子邮件地址。

除了在谷歌 DeepMind 的工作之外,Silver 还是伦敦大学学院的教授。他目前仍然保留着这一教职。
在 AI 领域,David Silver 的大名无人不知,他是 DeepMind 众多突破性成就背后的关键人物。
Silver 是 DeepMind 于 2010 年成立时的首批成员之一。他与 DeepMind 联合创始人德米斯・哈萨比斯(Demis Hassabis)在大学时期就已相识。Silver 在公司早期的许多突破性成就中发挥了关键作用,包括 2016 年围棋 AI 系统 AlphaGo 的里程碑式成就,它证明了人工智能可以击败世界上最优秀的围棋棋手。

David Silver、哈萨比斯和李世石。
他也是开发 AlphaStar 团队的关键成员之一。在 2019 年 8 月,AlphaStar 在欧洲星际争霸 II 天梯上达到了大师级水平,跻身人类玩家的前 0.2%。

Silver 还参与开发了 AlphaZero,该程序能够以超人的水平玩国际象棋、日本将棋和围棋;以及 MuZero,该程序即使在没有任何游戏知识(包括游戏规则)的情况下,也能比人类更好地掌握多种不同的游戏。
2024 年 7 月,Silver 与 DeepMind 团队合作开发了 AlphaProof,这是一个实现国际数学奥赛银牌水准的 AI 系统。David Silver 也是 2023 年发表的介绍谷歌首个 Gemini 系列 AI 模型的研究论文的作者之一。Gemini 现在是谷歌领先的商业 AI 产品和品牌。
另有知情人士透露,Silver 告诉朋友们,他渴望重拾「解决 AI 领域最棘手难题的敬畏与奇妙之感」,并将超级智能 —— 即比任何人类都更聪明、甚至可能比全人类都更聪明的人工智能 —— 视为该领域最大的未解之谜。
近年来,多位知名 AI 研究人员离开老牌 AI 实验室,创办了致力于追求超级智能的初创公司。OpenAI 前首席科学家 Ilya Sutskever 于 2024 年创立了一家名为 Safe Superintelligence (SSI) 的公司。该公司迄今已筹集了 30 亿美元的风险投资,据报道估值高达 300 亿美元。
一些 David Silver 的同事,曾参与 AlphaGo、AlphaZero 和 MuZero 项目的科学家们最近也离职创办了 Reflection AI,这家初创公司也声称正在研发超级智能。另一方面,Meta 去年重组了其人工智能部门,成立了新的「超级智能实验室」,该实验室由 Scale AI 前首席执行官兼创始人 Alexandr Wang 领导。
而 Meta 原首席人工智能科学家、图灵奖得主 Yann LeCun 则选择离职,正为其新创立的 AI 公司寻求融资。
David Silver 本科毕业于剑桥大学,2004 年赴加拿大阿尔伯塔大学攻读强化学习博士学位。他曾获得 2019 年 ACM 计算奖、英国皇家工程院银质奖章等多项荣誉。目前 Silver 的论文被引用量已经超过 28 万次。
作为 2024 年图灵奖得主 Richard Sutton 的门生,David Silver 以其在强化学习(Reinforcement learning)方面的研究而闻名,这是一种训练 AI 通过试错和反馈来学习如何做决策的方法。
David Silver 虽然不是强化学习的提出者,但经常被认为是强化学习最坚定的支持者之一,他认为这是创造有一天能够超越人类知识的人工智能的唯一途径。
在谷歌 DeepMind 于去年 4 月份发布的一档播客节目中,David Silver 表示,大型语言模型(LLM)虽然功能强大,但也受到人类知识的限制,他表示,「我们想要超越人类的认知,为此我们需要一种不同的方法,这种方法需要 AI 能够真正地自己去探索,并发现人类尚不知道的新事物。」

他呼吁 AI 进入一个以强化学习为基础的全新「经验时代」。
目前,大语言模型有一个「预训练」开发阶段,该阶段使用无监督学习。它们会吸收大量的文本,并学习预测在给定上下文中哪些词在统计学上最有可能出现在其他词之后。然后,它们还有一个「后训练」开发阶段,该阶段确实会使用一些强化学习,通常由人类评估员查看模型的输出并向模型提供反馈,有时反馈形式只是简单的「好」或者「不好」。通过这种反馈,模型生成有用输出的倾向会得到增强。
但这种训练方式的上限被人类知识锁死 —— 这既是因为它依赖于人类过去学习和记录的知识(在预训练阶段),也是因为大型语言模型后训练阶段的强化学习最终是基于人类的偏好。然而,在某些情况下,人类的直觉可能是错误的或短视的。
例如,在 AlphaGo 2016 年与围棋世界冠军李世石的第二局比赛中,AlphaGo 的第 37 手棋就出乎所有人的预料,以至于所有评论比赛的人类专家都确信这是一个昏招。但事实证明,这最终成为 AlphaGo 赢得那场比赛的关键,体现了 AI 超乎寻常的「大局观」。

同样,人类国际象棋棋手也经常将 AlphaZero 的下棋方式描述为「非人类的」—— 然而,它那些看似违反直觉的走法却常常被证明是绝妙的。
如果在大语言模型的后训练阶段采用强化学习过程,人类评估者可能会对这些走法给出负面评价,因为在人类专家看来,这些走法像是错误的。也许这就是为什么像 Silver 这样的强化学习纯粹主义者认为,要想达到超级智能,AI 不仅要超越人类知识,还需要摒弃人类知识,从零开始,从基本原理出发,学习如何实现目标。
一位熟悉 Silver 想法的人士表示,Silver 创立的 Ineffable Intelligence 公司旨在构建「一种能够不断学习的超级智能,它可以自主发现所有知识的基础」。
人们预计 Ineffable Intelligence 正式宣布融资时,将会出现一个巨大的融资数额。
参考内容:
https://fortune.com/2026/01/30/google-deepmind-ai-researcher-david-silver-leaves-to-found-ai-startup-ineffable-intelligence/
https://www.youtube.com/watch?v=zzXyPGEtseI
https://davidstarsilver.wordpress.com/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com