SplatSSC通过解耦深度引导的高斯泼溅,实现了高效的单目语义场景补全,有效解决了传统方法中存在的问题。
原文标题:AAAI 2026 Oral | SplatSSC:解耦深度引导的高斯泼溅,开启单目语义场景补全高效新范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、DGA通过解耦几何和语义预测来解决“漂浮物”问题,这种解耦思想在其他深度学习任务中是否也有应用前景?
3、文章提到SplatSSC未来将扩展到大规模户外动态场景以及长程具身感知任务,你认为在扩展过程中会遇到哪些挑战?
原文内容

1. 深度学习下的场景理解:从密集网格到对象中心表征
单目 3D 语义场景补全 (Semantic Scene Completion, SSC) 是具身智能与自动驾驶领域的一项核心技术,其目标是仅通过单幅图像预测出场景的密集几何结构与语义标签。
长期以来,该领域受困于传统的密集网格(Grid-based)表征。虽然近期涌现出的 “对象中心” 范式(如 GaussianFormer)利用 3D 高斯基元(Gaussian Primitives)显著提升了效率,但这一路径仍面临两大瓶颈:
1. 基元初始化的盲目性:现有的方法往往通过在 3D 空间内随机分布数万个高斯基元来覆盖场景。实验发现,这种随机初始化的有效利用率极低(仅约 3.9%),造成了巨大的计算冗余。
2. 异常基元引发的 “漂浮物” 伪影:在处理稀疏基元聚合时,现有的方法往往无法有效处理孤立的离群点,导致在空旷区域生成错误的语义碎块,即所谓的 "Floaters" 现象。
针对这些挑战,我们提出了SplatSSC。该框架通过创新的深度引导策略与解耦聚合机制,实现了性能与效率的跨越式提升。
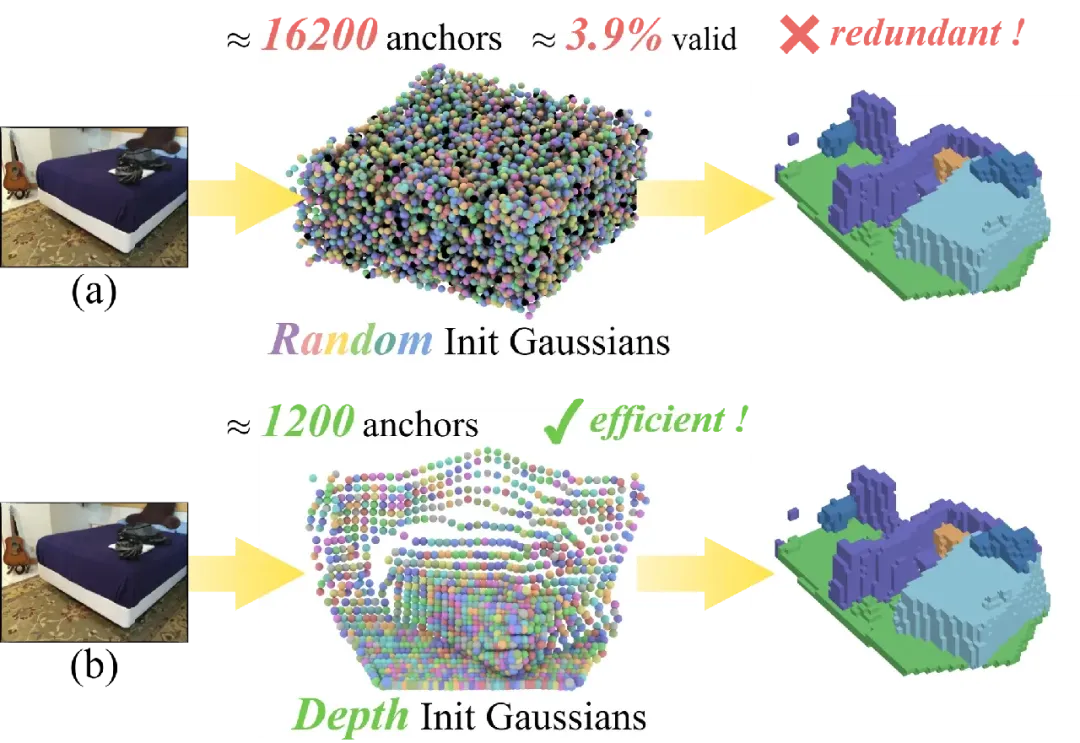
图 1:SplatSSC 与主流框架的初始化策略对比。(a) 现有的 Transformer 框架通常依赖大规模随机分布的高斯基元,这不可避免地引入了空间冗余,导致模型容量的浪费。(b) 相比之下,SplatSSC 利用几何先验进行引导,仅需一组精简且目标明确的高斯基元,即可实现高效的空间覆盖。

-
作者:Rui Qian, Haozhi Cao, Tianchen Deng, Shenhai Yuan, Lihua Xie
-
名称:SplatSSC: Decoupled Depth-Guided Gaussian Splatting for Semantic Scene Completion
-
机构:南洋理工大学 (NTU), 上海交通大学 (SJTU)
-
开源地址: https://github.com/Made-Gpt/SplatSSC
2.核心技术:精准引导与鲁棒聚合
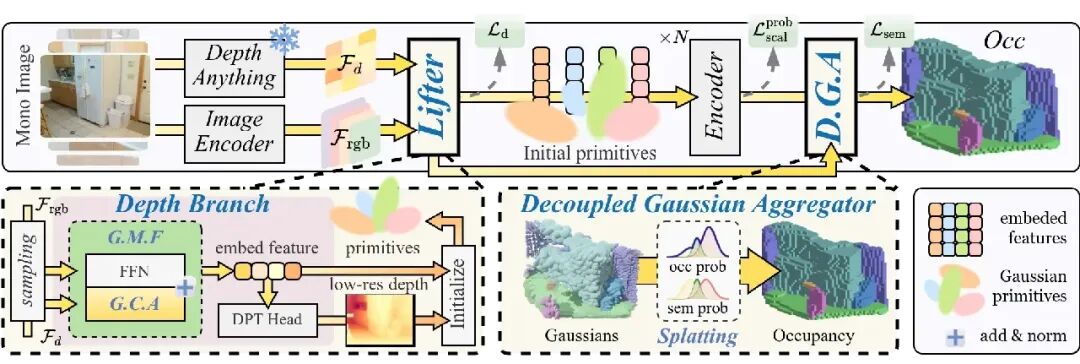
图 2:SplatSSC 架构总览。我们采用并行分支策略:可学习的图像编码器负责多尺度语义提取,而预训练的 Depth-Anything 模型则提供稳定的深度特征。通过组内多尺度融合(GMF)模块,这两类特征在经过采样后被映射到 3D 空间,完成高斯基元的几何初始化,并交由多级编码器进行精炼,最后通过 DGA 模块渲染为语义体素。
2.1 深度引导基元初始化:GMF 模块
SplatSSC 的核心思想是摒弃随机初始化,转而利用几何先验进行精准引导。我们设计了组内多尺度融合模块(Group-wise Multi-scale Fusion, GMF):
-
多模态特征融合:GMF 深度集成了图像的多尺度语义特征与 Depth-Anything-V2 提供的鲁棒深度特征。
-
线性组交叉注意力(GCA):为了在移动端或具身平台上保持高效,我们将特征沿通道轴拆分为多个组,通过组内交叉注意力机制将传统注意力的计算复杂度从平方级降低至线性级。
-
高质高效基元生成:基于生成的几何先验,我们仅需 1200 个高斯基元(约为前作的 7%),即可精准覆盖场景结构的空间分布。
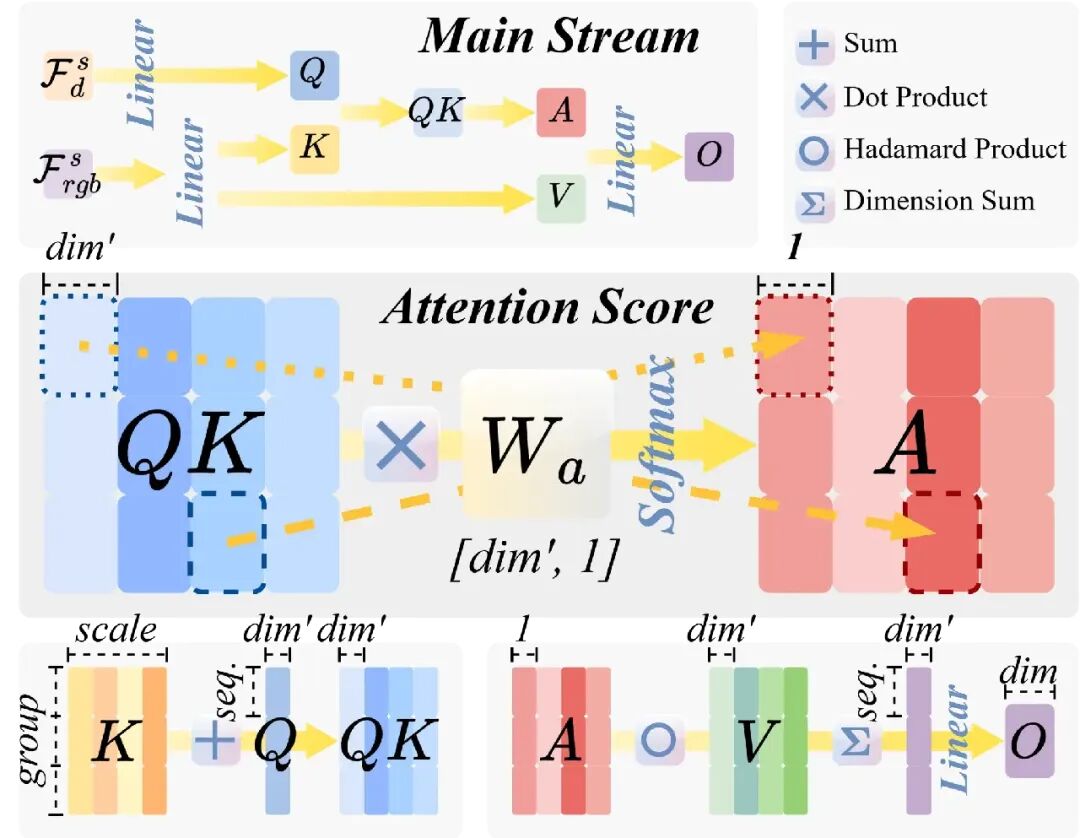
图 3:GCA 层的技术细节。为了降低计算开销,我们设计的![]() 权重矩阵在不同的特征组和尺度间实现了参数共享。这一设计在显著减少显存消耗的同时,保证了注意力分数计算的高效性。
权重矩阵在不同的特征组和尺度间实现了参数共享。这一设计在显著减少显存消耗的同时,保证了注意力分数计算的高效性。
2.2 解耦高斯聚合器 (DGA):向 “漂浮物” 宣战
SplatSSC 引入了解耦高斯聚合器(Decoupled Gaussian Aggregator, DGA),从根本上重新设计了高斯到体素(Gaussian-to-voxel)的喷溅过程。
-
几何与语义的解耦预测:传统方法常将不透明度(Opacity)直接作为概率先验,导致离群点误导语义。DGA 建立了两条独立路径 —— 一条负责预测几何占据(Geometry Occupancy),另一条负责条件语义分布。
-
门控抑制机制:在 DGA 中,基元的不透明度被显式定义为 "存在置信度"。当离群点出现在错误位置时,其低占据概率会直接作为门控信号,屏蔽错误的语义贡献。这种机制无需引入复杂的启发式规则,即可优雅地解决困扰高斯表征的 "漂浮物" 问题。
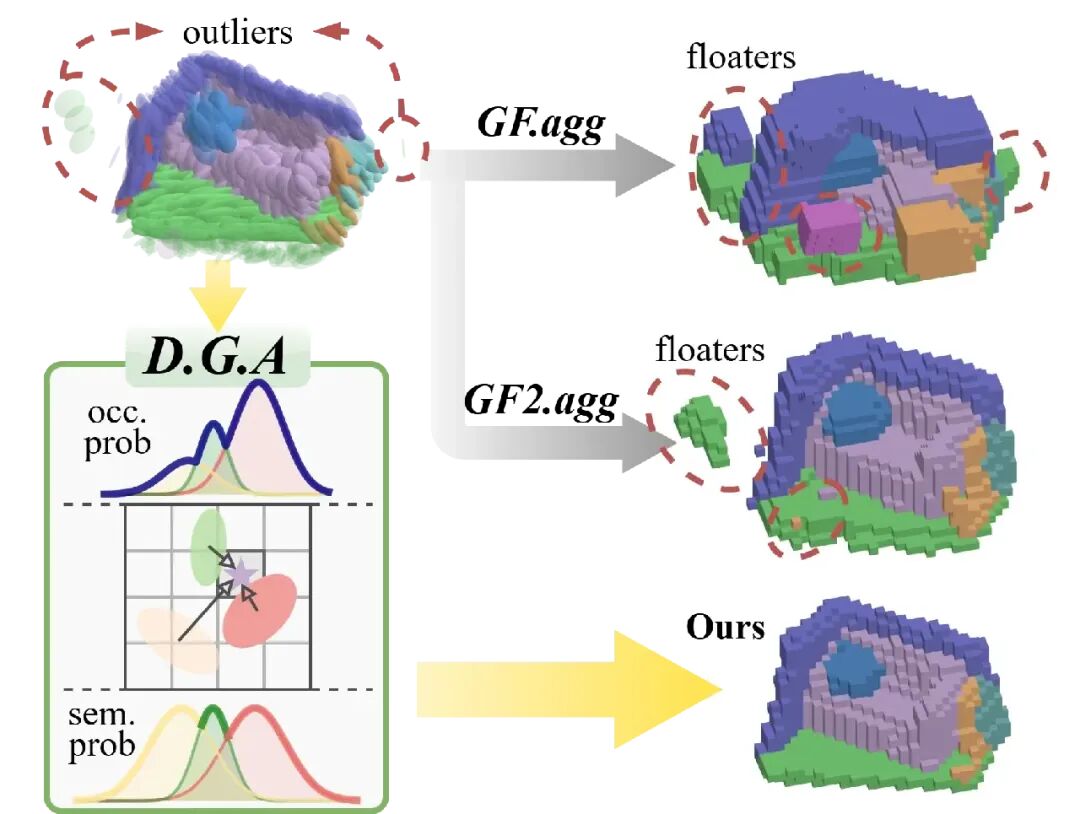
图 4:DGA 鲁棒性演示。传统的聚合方法(如 GF.agg 和 GF2.agg)在面对离群基元时,容易在空旷空间生成错误的 “漂浮物”。DGA 通过解耦占据概率与语义贡献,利用极低的占据概率直接抑制离群点的错误语义映射,从而确保了场景边界的纯净。
3. 实验验证:SOTA 性能与更好的能效比
我们在室内场景补全的主流基准数据集 Occ-ScanNet 上验证了 SplatSSC 的性能。

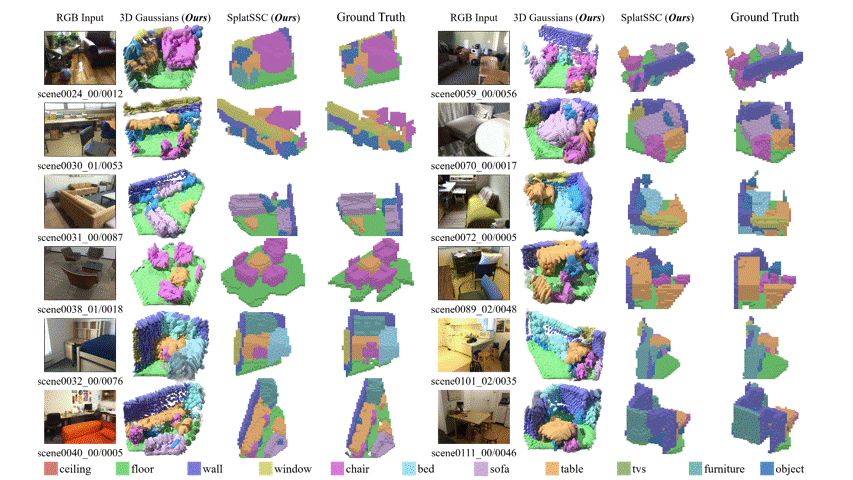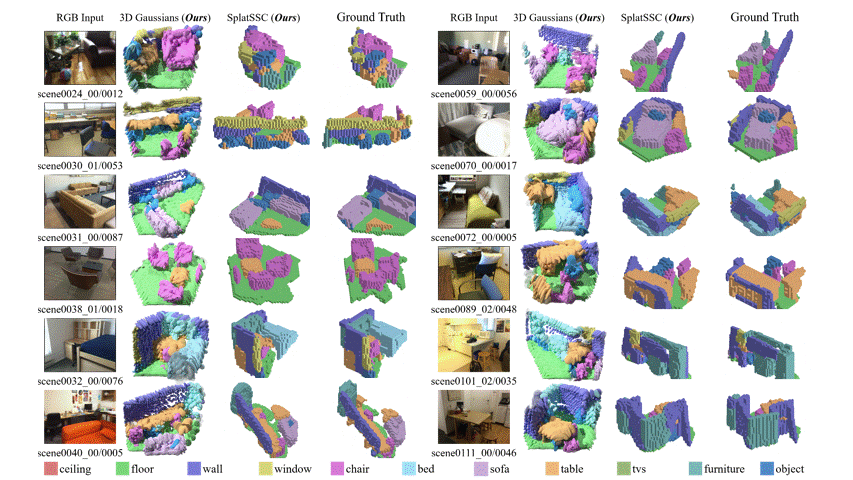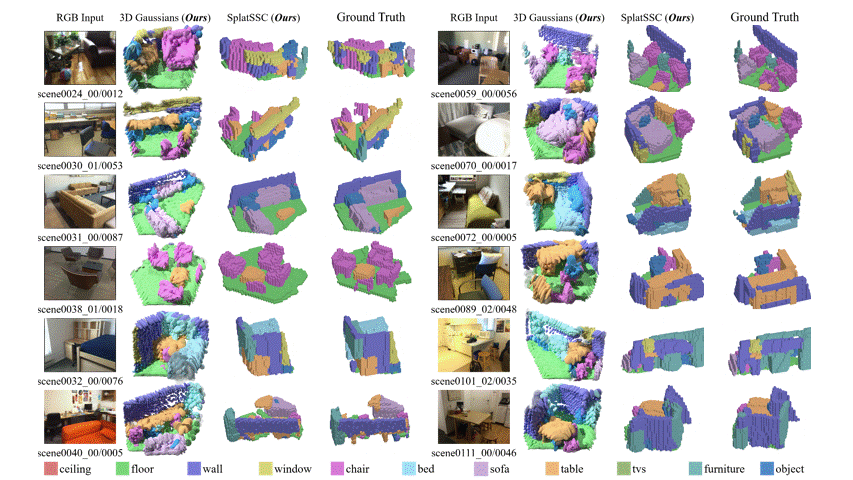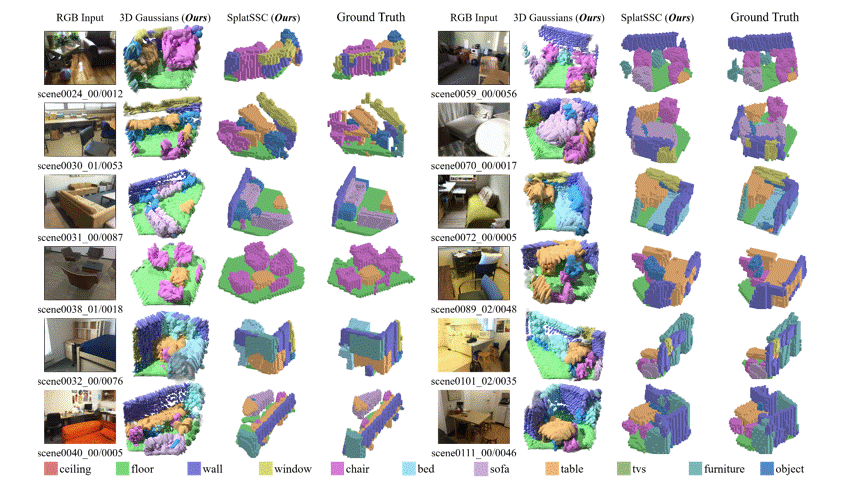
图 5:在 Occ-ScanNet-mini 上的定性实验对比。与其他 baseline 相比,SplatSSC 在场景补全的完整度以及目标物体的召回率上具有明显优势。
3.1 主实验
SplatSSC 在 IoU 指标上达到了62.83%,mIoU 达到51.83%。
-
大幅领先前作:相比此前的 SOTA 方法(如 RoboOcc),我们的模型在 IoU 上大幅提升了6.35%,mIoU 提升了4.16%。
-
更强的细粒度感知:得益于精准的基元引导,模型在处理椅子腿、桌面等精细物体时表现出更强的召回能力和更清晰的边界。
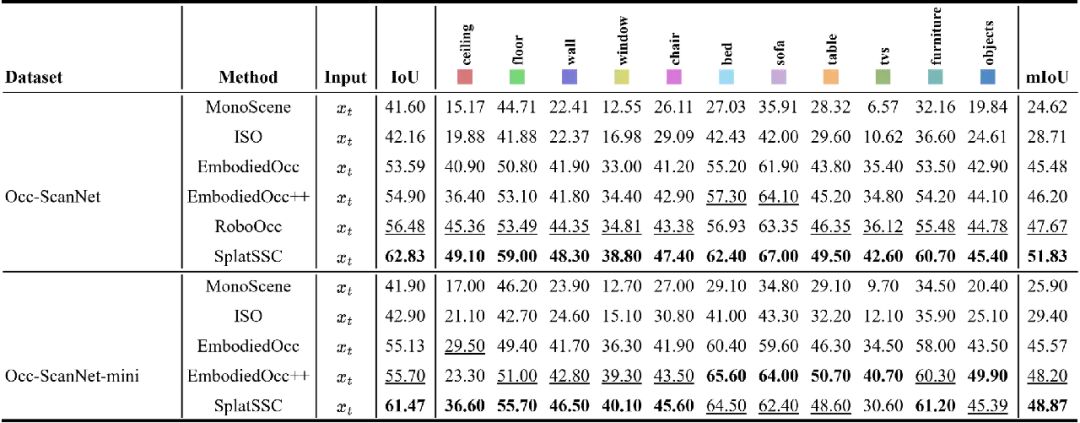
表 1:Occ-ScanNet 数据集上的局部预测性能对比。实验结果显示,SplatSSC 在 IoU 与 mIoU 各项指标上均刷新了记录。表中加粗部分代表最优结果,下划线代表次优结果。
3.2 消融实验
高斯基元参数的消融分析:这组实验揭示了一个关键结论:基元堆砌并不等同于精度提升。
-
寻找 "甜蜜点"(Sweet Spot):实验结果表明,仅使用1200 个高斯基元配合[0.01, 0.16]的尺度范围,即可达到48.87%的最高 mIoU。这比堆砌 19200 个基元的方法更轻量,精度却更高。
-
效率的代差:通过优化基元分布,模型在单张 3090 上实现了约 115ms 的极低延迟,同时彻底规避了大尺度配置下的显存溢出(OOM)问题。
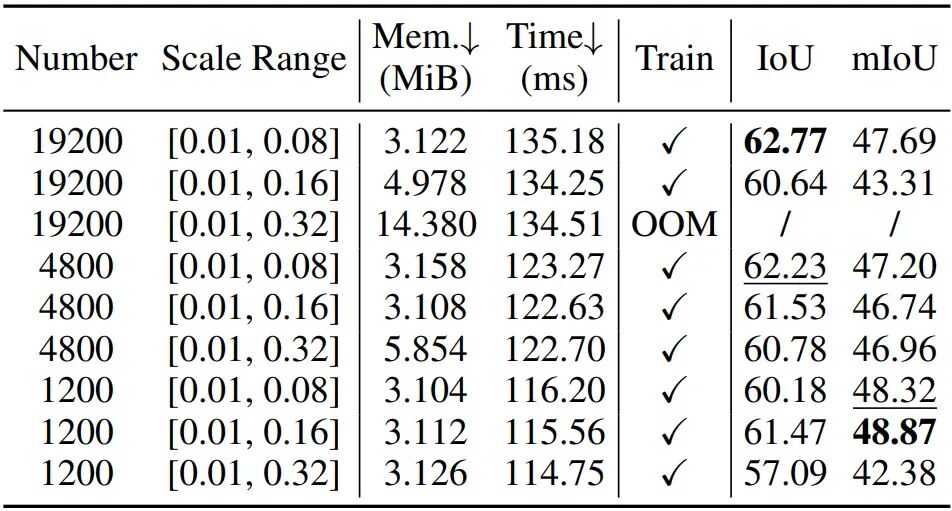
表 2:高斯基元参数消融实验。显存占用与耗时均在单张 RTX 3090 GPU 上测得。
模块贡献与架构拆解:这组实验量化了深度分支(GMF)与解耦聚合器(DGA)的协同效应,证明它们是解决行业痛点的 "组合拳":
-
解决 "浮点伪影"(Floaters):在稀疏设定下,传统的加性聚合(GF.agg)几乎无法工作。对比数据展示了DGA的绝对优势 —— 通过解耦几何与语义预测,它在保持结果 "干净" 的同时,将 mIoU 从崩溃边缘提升至48.01%的顶尖水平。
-
高质量初始化的基石:GMF模块不仅提供深度图,更生成结构化几何先验,这是后续高斯提升(Gaussian Lifting)成功的关键。若缺少 GMF, 即便聚合算法再强,几何 IoU 也会出现剧烈下滑。

表 3:SplatSSC 核心组件消融实验。
3.3 效率突破:少即是多
SplatSSC 展示了稀疏表征的巨大威力:
-
推理延迟缩减:在保持高精度的同时,推理延迟降低了约9.3%(仅为 115.63 ms)。
-
显存占用降低:显存消耗减少了约9.6%。
-
参数规模稳定:在模型轻量化设计下,参数量仅增加 0.19%,几乎可以忽略不计。
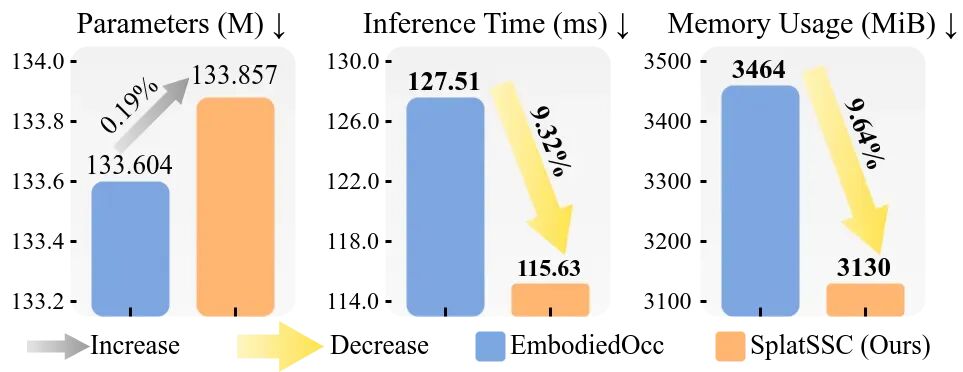
图 6:效率指标对比。实验结果表明,通过引入几何引导的稀疏表征,SplatSSC 仅付出极小的参数成本,即可显著降低推理延迟与显存占用。
4. 总结与展望:迈向具身智能的 persistent world model
SplatSSC 的成功证明了:在 3D 场景表征中,基元的 “质量” 远比 “数量” 更重要。通过几何引导的精准初始化与解耦聚合,我们可以在更低的计算资源下实现更高质量的场景重构。
目前 SplatSSC 在单帧感知上表现优异,未来我们将致力于将其扩展到大规模户外动态场景以及长程具身感知任务中。我们相信,这种基于高斯基元的高效表征将成为构建持久性、交互式世界模型的关键一步。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com