清华大学大数据项目成果:基于 Transformer 的光伏功率预测,为电网安全提供保障。
原文标题:大数据能力提升项目|学生成果展系列之四
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到了不同成本的预测方案(零成本、低成本、高成本),在实际应用中,如何权衡预测精度和成本?有没有可能通过算法优化来降低高成本方案的成本?
3、这项研究的数据来自湖北某光伏电站,那么这个模型是否具有通用性?如果要将该模型应用到其他地区的光伏电站,需要做哪些调整?
原文内容

为了发挥清华大学多学科优势,搭建跨学科交叉融合平台,创新跨学科交叉培养模式,培养具有大数据思维和应用创新的“π”型人才,由清华大学研究生院、清华大学大数据研究中心及相关院系共同设计组织的“清华大学大数据能力提升项目”开始实施并深受校内师生的认可。项目通过整合建设课程模块,形成了大数据思维与技能、跨界学习、实操应用相结合的大数据课程体系和线上线下混合式教学模式,显著提升了学生大数据分析能力和创新应用能力。
回首2025年,清华大学大数据能力提升项目取得了丰硕的成果,同学们将课程中学到的数据思维和技能成功地应用在本专业的学习和科研中,在看到数据科学魅力的同时,也将自己打造成为了交叉复合型的创新型人才。下面让我们通过来自3个院系的4位同学代表一起领略他们的风采吧!
代表性成果
基于 Transformer 系列模型的短期光伏功率预测
能源与动力工程系 吴家豪
本工作在大数据实践课中完成,并发表在 Solar Compass 期刊,目前被引用十余次。
[摘要] 为了解决光伏发电功率波动带来的安全隐患,需要提前对其进行预知,及早采取应对措施。本文基于 Autoformer 、Informer 和 Transformer 三个模型,开发了零成本预测、低成本预测和高成本预测三种预测方法,对湖北某光伏电站的某方阵实现了 4h 和 24h 两种预测时长下的功率预测。结果表明, 部分模型与配置下的结果达到项目指标,且 Informer 和 Transformer 的整体表现优于 Autoformer。经过对三个模型和不同预测间隔的对比,综合指标达成情况和工业实际需求,本文对 4h 和24h预测都给出了相应的建议模型与配置。
[背景] 光伏发电是可再生能源利用方式之一。光伏发电功率具有波动性和间歇性,接入电网后会可能会产生安全稳定问题。为了解决功率波动带来的安全隐患,需要提前预知光伏发电能力,及早采取应对措施。因此开展多种时间尺度的光伏发电功率预测,对电站异常监测和电网功率调控具有十分重要的意义。
[现状] 功率预测方法很多,大体上可以分为物理模型、传统时序与机器学习模型以及深度学习模型。一方面,Transformer 系列模型在时间序列任务上正迅速发展,属于前沿技术。另一方面,光伏功率预测文献中较多的是 RNN 或 Attention-RNN 模型,几乎没有 Transformer 结构模型。因此,将时序 Transformer 应用于光伏的这一研究空缺有待填补。
[目标] 建立光伏功率预测模型,开发不同成本下的预测方案,实现对未来 4 小时和 24 小时的滚动预测。
[技术路线] 使用 Autoformer 、Informer 和 Transformer 三个模型,对方阵级功率进行 4 小时和 24 小时的预测,并开发出三套预测方法,即不使用未来天气的零成本预测,使用不含辐照的未来天气的低成本预测,以及使用含辐照数据的未来天气的高成本预测。
![]()
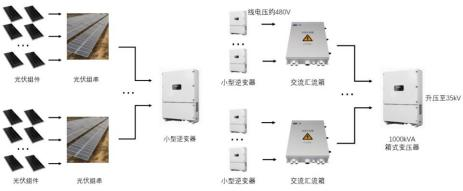
光伏电站空间层次结构
[数据处理] 由于原始数据是以单日进行存储的,且每日只有 4 点到 20 点,因此对其进行了夜间数据填充和连续化处理。由于原始数据是按组串进行存储的,所以为了进行方阵级别的功率预测,对方阵中的所有有效组串数据进行了平均,转换成了方阵级别的功率。
[模型与配置] 使用 Autoformer、Informer 和 Transformer 模型。对方阵级功率进行 4 小时和 24 小时的预测,并开发出三套预测方法,即不使用未来天气的零成本预测,使用不含辐照的未来天气的低成本预测, 以及使用含辐照数据的未来天气的高成本预测。对于零成本预测,decoder 输入为零。对于低成本预测,decoder 输入为未来的温度等免费数据,并且为提升其性能,我们额外设计输入了一维日夜编码以增强其日夜差距信息。对于高成本预测,则使用昂贵的辐照数据。模型的预测序列长度等于预测时长除以预测间隔,其中预测时长有两种,即 4 小时和 24 小时,并分别设置了三种预测间隔。
![]()
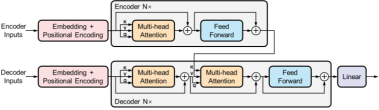
(a) Transformer
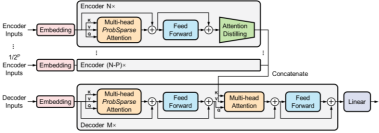
(b) Informer
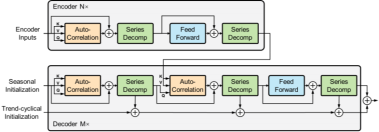
(c) Autoformer
模型示意图
![]()
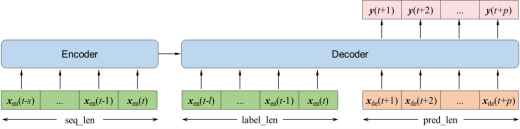
数据流示意图
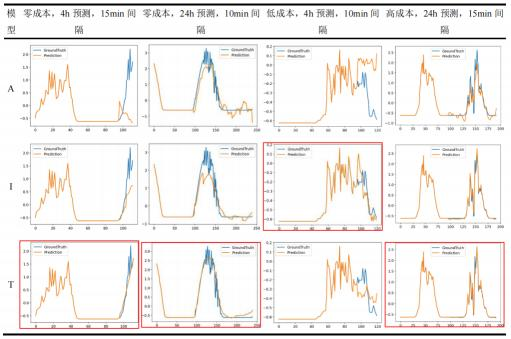
模型性能对比
编辑:文婧
校对:龚力

关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。
新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU