高效智能体落地关键:记忆优化、工具学习与规划提效。
原文标题:高效智能体的「幕后推手」是谁?一篇综述带你从记忆×工具学习×规划看透
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到了智能体的隐式推理,你认为这对于提升智能体效率有哪些潜在的优势? 又会带来哪些新的挑战?
3、在多智能体协作中,如何平衡通信效率和信息完整性是一个关键问题。除了文章中提到的方法,你认为还有哪些创新的思路可以解决这个问题?
原文内容

随着大模型能力的跃迁,业界关注点正在从 “模型能不能做” 快速转向 “智能体能不能落地”。过去一年可以看到大量工作在提升智能体的有效性(effectiveness):如何让它更聪明、更稳、更会用工具、更能完成复杂任务。
但在真实应用里,另一个更 “硬” 的问题常常决定能否上线:高效性(efficiency)。智能体即便表现很好,如果每次都要消耗大量算力、时间与调用成本,也很难在生产环境大规模部署。
基于这一视角,论文整理并撰写了一篇面向 “高效智能体” 的综述,系统梳理当前主要方法,并从三个最关键的机制出发组织全文框架:记忆 — 工具学习 — 规划。论文从设计范式出发对代表性方法进行归纳总结,聚焦那些以效率为目标或能够提升效率的核心设计与实现路径,从而更清晰地呈现智能体在真实落地场景中的成本 — 性能权衡。

-
论文地址:https://arxiv.org/abs/2601.14192
-
GitHub 地址:https://github.com/yxf203/Awesome-Efficient-Agents
一、智能体记忆:
让 “会记” 更省、更准、更可扩展
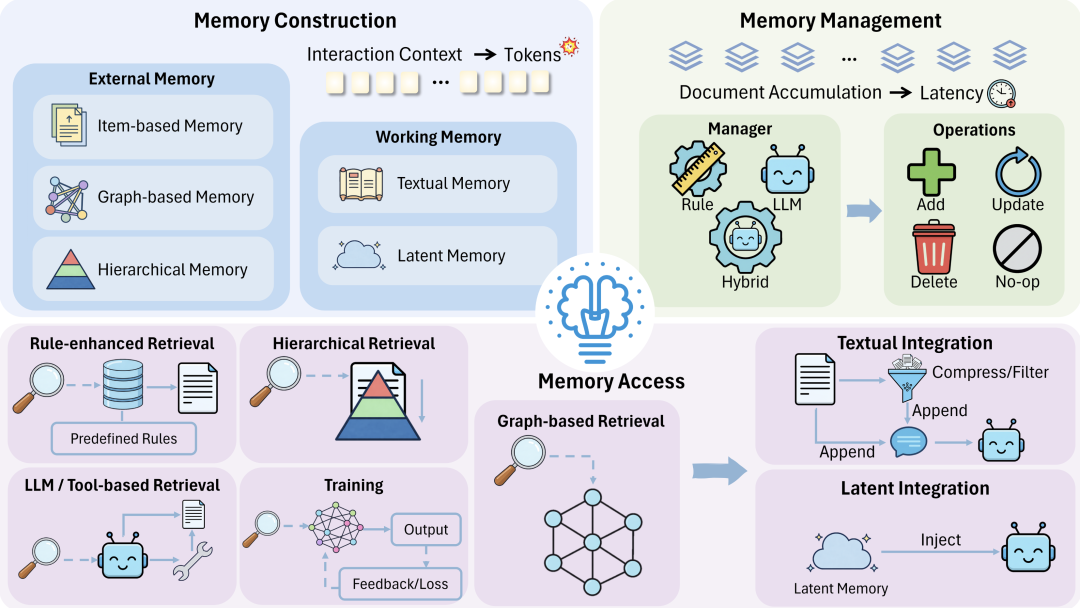
智能体要做长任务,离不开记忆。但把历史一股脑塞进提示词,会带来 token 暴涨和智能体处理长上下文能力下降。因此,高效记忆系统的关键在于把 “长历史” 加工成 “可用、可检索、可复用” 的信息资产。
论文按记忆生命周期梳理三步:构建 — 管理 — 访问。
-
记忆构建:通过概括、压缩与结构化把 “长对话” 转成 “可用记忆”。一类是留在推理链路的工作记忆,文本式直观但吃上下文,隐式式更像缓存,可减少重复编码;另一类是外置为可检索系统的外部记忆,先将信息压成小单元再按需召回,包括条目式、图式与分层式。此外论文也提到要警惕过度压缩带来的信息损失,即需要考虑如何在降成本与保真之间取得平衡。
-
记忆管理:防止 “存爆炸”,也避免 “取太慢”。规则式快但可能误删重要内容,大模型式更聪明但更贵,混合式则按层级或场景组合两者策略,在效果与成本之间取得折中。
-
记忆访问:选什么 + 怎么用。访问分记忆选择与记忆整合,通过检索或训练等方式挑选记忆,再用压缩过滤或隐式注入减少 token 与重复编码。
另外,多智能体记忆也成为新趋势。相较于只靠通信,近年更多工作开始引入 “记忆” 这一概念来支撑规模化协作,论文将其概括为:共享记忆 / 本地记忆 / 混合记忆三类。
二、工具学习:
让 “会用工具” 更少调用、更少等待、更少走弯路
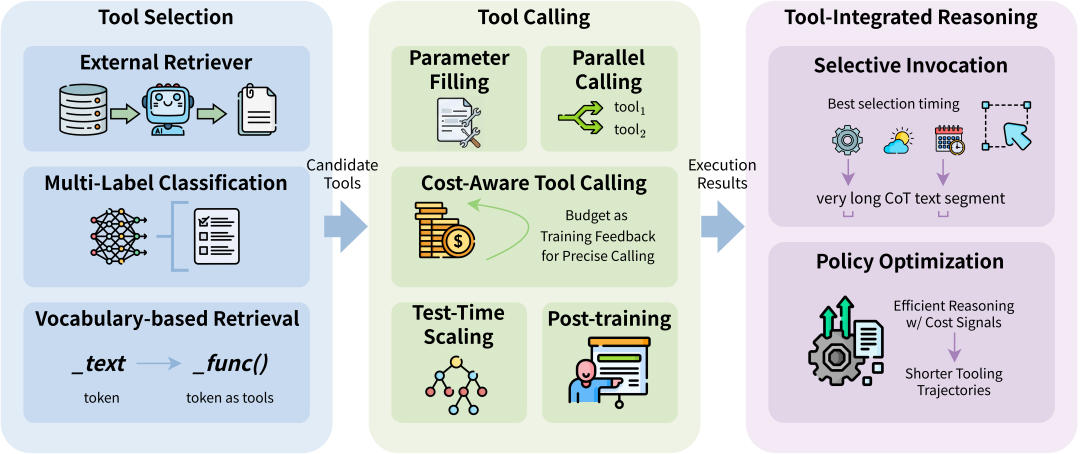
工具让智能体从 “会说” 变成 “能做”,但成本也最容易在工具链路里失控。论文按三条主线梳理提效思路:工具选择 — 工具调用 — 工具融合推理。
-
工具选择:目标是 “更快选对、少塞进 prompt”。相关方法包括外部检索器、多标签分类,以及将工具映射为特殊 token 等思路,核心都是在大量工具中更快、更准地选出最需要的那几个。
-
工具调用:核心是 “少等、少调、少走弯路”。典型路线包括边生成边调用、并行化调用,以及利用成本感知调用与测试时高效扩展来削减冗余调用;进一步还可通过面向效率的后训练把 “短轨迹、少调用” 写进策略本身。
-
工具融合推理:让模型学会 “该不该用、何时用、用几次”。代表性方向包括选择性调用,引导智能体只在必要时才发起工具调用;以及成本约束策略优化,在保证效果的同时对冗余交互与过长轨迹施加惩罚,从而学到更短、更省的工具使用策略。
三、智能体规划:
在 “深度” 与 “宽度” 上同时省下来
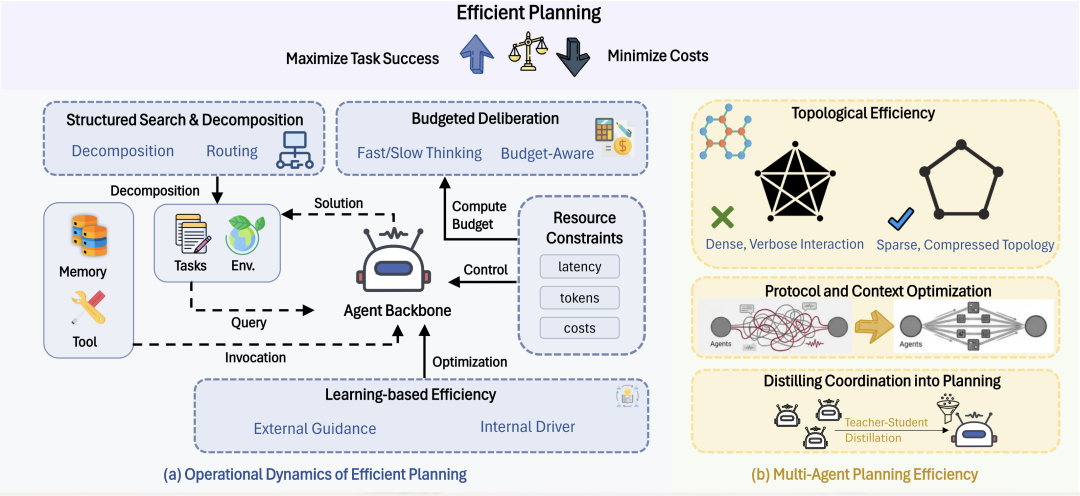
规划决定智能体如何在多步决策空间里行动。效率问题要么来自单体推理 “想太深、搜太贵”,要么来自多体协作 “聊太多、通信太重”。因此论文从两条线展开:单智能体规划与多智能体协作规划。
-
单智能体:少算但不掉效果。主要思路包括自适应预算与控制的 “选择性思考”、结构化搜索的剪枝与代价感知、任务分解的先规划后执行;以及通过策略优化与记忆 / 技能获取把高效规划 “内化或复用”,越用越省。
-
多智能体:少通信但尽可能不丢信息。方向主要有三类:拓扑稀疏化减少全连接带来的
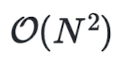 的消息传递开销;协议与上下文优化压缩则关注 “传什么 / 怎么传”;蒸馏方法通过将多智能体协作能力蒸馏回单体,来减少运行时多智能体之间协调的成本。
的消息传递开销;协议与上下文优化压缩则关注 “传什么 / 怎么传”;蒸馏方法通过将多智能体协作能力蒸馏回单体,来减少运行时多智能体之间协调的成本。
四、基准与评测(Benchmark):
没有 “可比的尺”,就谈不上 “可落地的效率”
在谈记忆、工具学习与规划的提效方案之前,先要把 “尺子” 定清楚:高效到底怎么量?
论文强调,效率必须建立在有效性之上。省了资源却显著掉性能,不算高效。因此论文采用的定义是:在给定预算下取得更好的效果,或在相近效果下消耗更少资源。
基于这一视角,论文先梳理了以有效性为主的 benchmark,并进一步汇总了与效率相关的评测内容:一方面,整理了在 benchmark 中显式纳入效率信号(成本、延迟、调用次数等)的评测设置;另一方面,总结了智能体方法中常用的效率指标,用于刻画 “省在哪儿、省多少”。
五、挑战与展望
论文同时也提出了目前的一些挑战与展望:
1)统一评测框架:指标口径统一,模块开销边界清楚,才能真正让各个智能体方法可比可复现。
2)智能体的隐式推理(Latent Reasoning):大模型侧的隐式推理正在升温,但面向智能体的研究仍相对稀缺。由于智能体链路更长、更复杂,还要处理工具调用、规划与记忆等环节,如何把中间推理 “做在隐式空间里”、在不掉效果的前提下降低成本,既是挑战,也是机会。
3)面向部署设计:在多智能体场景下,需要把部署成本纳入考量,核心问题是投入产出比。也就是说,增加智能体带来的收益,是否足以覆盖新增的开销。
4)多模态效率:多模态智能体发展很快,但效率研究仍相对欠缺。文本智能体的一些提效思路可以借鉴,但是直接迁移却并不容易,因为多模态智能体的感知输入、行为空间与任务结构更复杂、交互成本更高。因此,如何在多模态场景下系统地兼顾效果与成本,仍是亟待解决的关键问题。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com