香港大学等机构发布综述,提出“定位-操控-提升”范式,将大模型可解释性研究转化为实际的模型改进。
原文标题:大模型哪里出问题、怎么修,这篇可解释性综述一次讲清
原文作者:机器之心
冷月清谈:
怜星夜思:
2、针对大模型的对齐问题,文章提到了通过定位和有约束的干预来减少有害行为。你认为除了文章中提到的方法,还有哪些更有效的对齐策略?
3、文章提到MI可以赋能大模型的效率提升,探索更灵活的干预和压缩手段。你认为在模型压缩方面,MI有哪些具体的应用前景?
原文内容

过去几年,机制可解释性(Mechanistic Interpretability)让研究者得以在 Transformer 这一 “黑盒” 里追踪信息如何流动、表征如何形成:从单个神经元到注意力头,再到跨层电路。但在很多场景里,研究者真正关心的不只是 “模型为什么这么答”,还包括 “能不能更稳、更准、更省,更安全”。
正是在这一背景下,来自香港大学、复旦大学、慕尼黑大学、曼切斯特大学、腾讯等机构的研究团队联合发布了 “可实践的机制可解释性”(Actionable Mechanistic Interpretability)综述。文章通过 "Locate, Steer, and Improve" 的三阶段范式,系统梳理了如何将 MI 从 “显微镜” 转化为 “手术刀”,为大模型的对齐、能力增强和效率提升提供了一套具体的方法论。

-
论文标题:Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
-
论文链接:https://arxiv.org/abs/2601.14004
-
项目主页:https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey
从 “显微镜” 到 “手术刀” 的范式转移
尽管大语言模型(LLM)近年来在多种任务上展现出了强大的能力,但其内部的运作机制依然在很大程度上不透明,常被视为一个 “黑盒”。围绕如何理解这一黑盒,机制可解释性(Mechanistic Interpretability, MI)逐渐发展为一个重要研究方向。
然而,现有的 MI 研究大多仍停留在 “观察” 层面:例如哪些神经元编码了特定实体、哪些注意力头参与了指代消解、哪些计算电路实现了算术或逻辑功能。但一个更关键的问题仍有待回答 —— 这些机制层面的发现,如何真正转化为模型行为和性能的实际改进?
正是基于这一问题,研究团队撰写了这篇以实践为导向的系统性综述。不同于传统综述侧重于回答 “模型内部有什么”,本文将关注点转向 “可以对模型做什么”,并围绕 "定位->操控->提升" 这一闭环,系统梳理了机制可解释性如何走向可实践的模型改造路径。
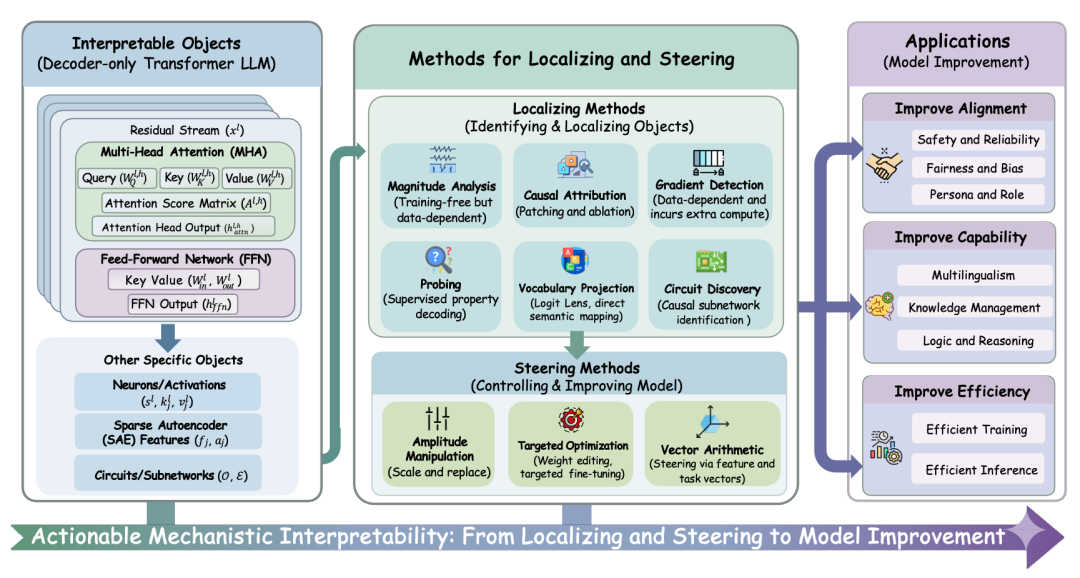
1. Locate:像医生一样精准 “定位” 病灶
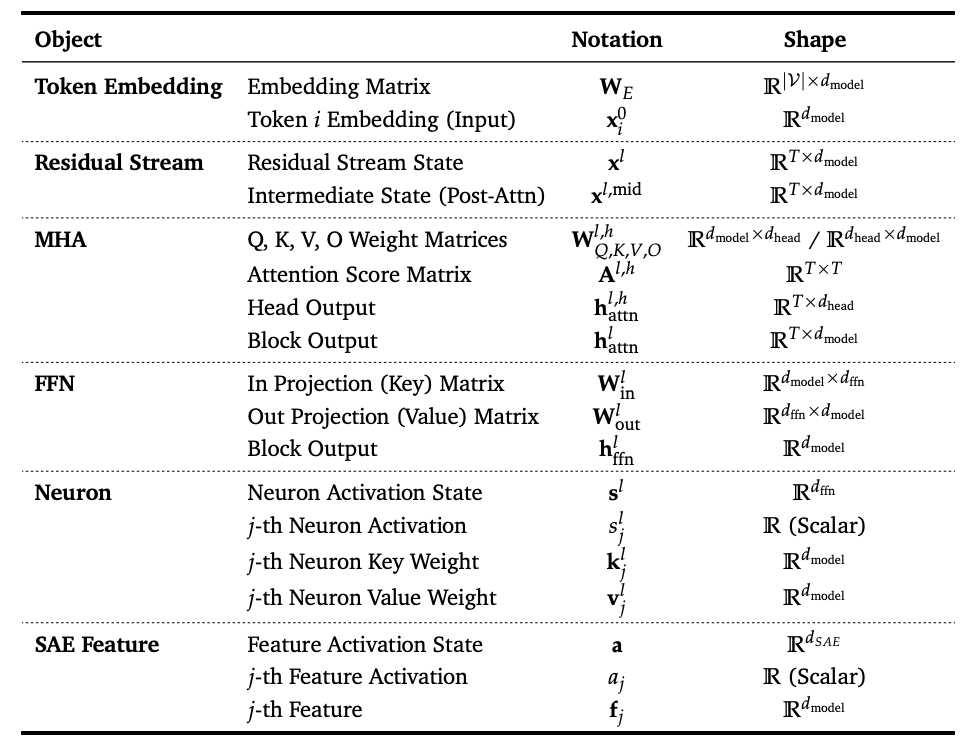
干预的前提是准确的诊断。文章首先构建了一套系统的可解释对象(Interpretable Objects)定义与分类体系,为后续的机制分析奠定了基础。
-
微观层面:从传统的神经元(Neuron) 到近年来广泛使用的稀疏自编码器特征(SAE Feature)。
-
宏观层面:涵盖注意力头(Attention Heads)、残差流 (Residual Stream) 等组件。
-
诊断工具:梳理了包括因果归因(Causal Attribution)、探针(Probing)、梯度检测(Gradient Detection) 等主流定位技术。
2. Steer:面向干预的 “手术” 手段
当关键对象被定位出来之后,对其进行干预便成为可能。这也标志着机制可解释性从 “观察” 迈向 “可实践” 的关键一步。文章将现有的干预手段归纳为三大类:
-
幅度操控(Amplitude Manipulation):对目标对象进行置零/缩放/替换(ablation, scaling, patching)等操作,实现 “开关式” 或 “强度式” 控制。
-
靶向优化(Targeted Optimization):利用定位到的关键组件进行参数级的微调(如仅微调特定的 Attention Heads),比全量微调更高效、副作用更小。
-
向量运算(Vector Arithmetic):在激活空间中加入/移除任务向量或特征向量,实现推理时引导模型行为。
3. Improve:MI 赋能的三大应用场景
Application 章节中将其划分为三大类别,并逐一呈现了 MI 在这三个维度上的实质性提升:
-
对齐(Alignment):通过定位与有约束的干预,减少有害行为、降低幻觉或提升遵循指令的稳定性。
-
能力(Capability):把机理层面的 “功能模块”转化为具体的能力增强路径(例如更稳的推理、记忆或语言生成)。
-
效率(Efficiency):探索更灵活的干预与压缩手段,为高效训练,推理加速与部署成本提供新抓手。

【Paper List 指南】
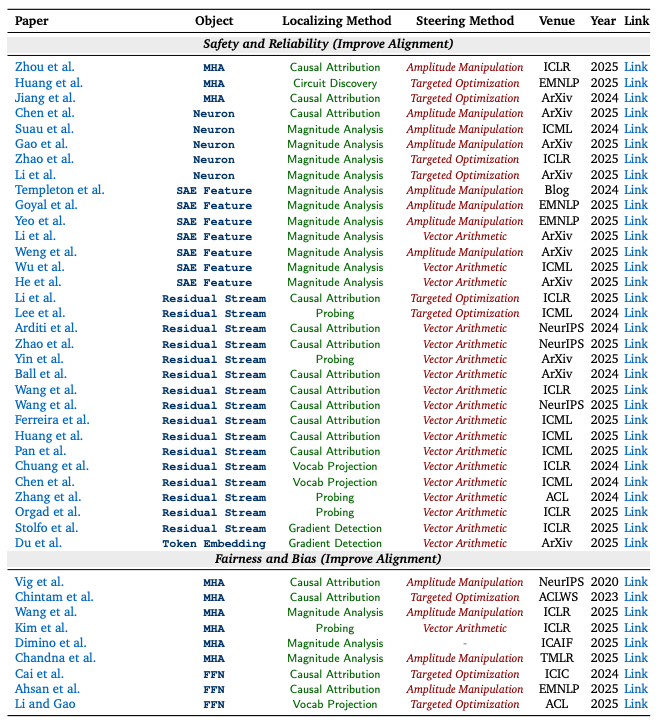
对相似领域的可解释性工作,研究团队将分散的研究成果做成了 “可检索的图表”:每篇论文都用统一标签标出它在研究什么、怎么找到关键位置、以及如何进一步用来引导模型行为,以便将不同研究路线的代表性工作进行直观对照,快速定位与自身需求最契合的的关键论文。
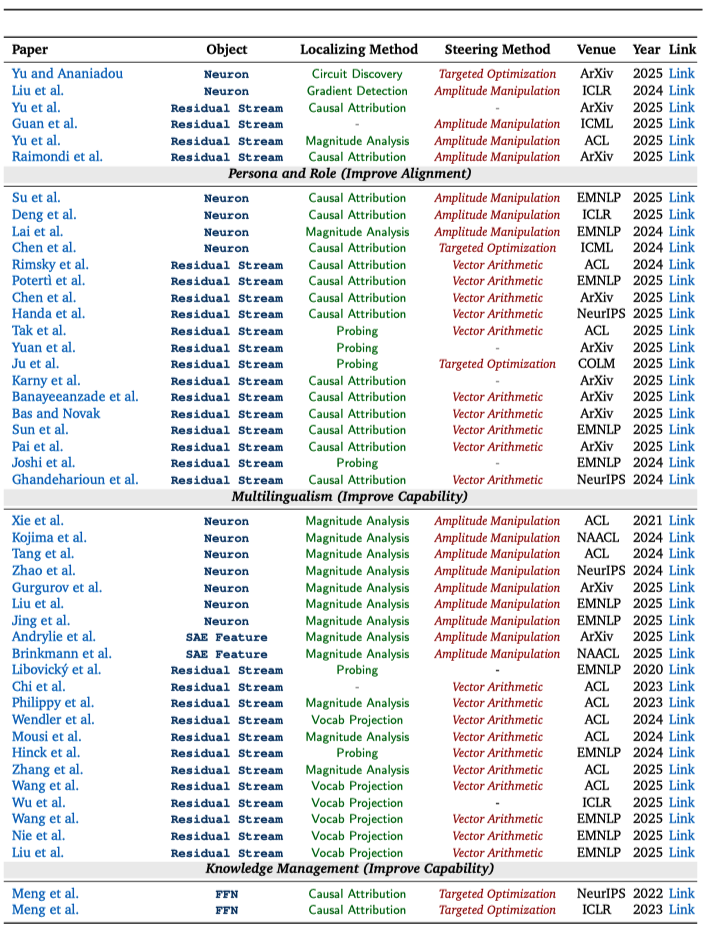
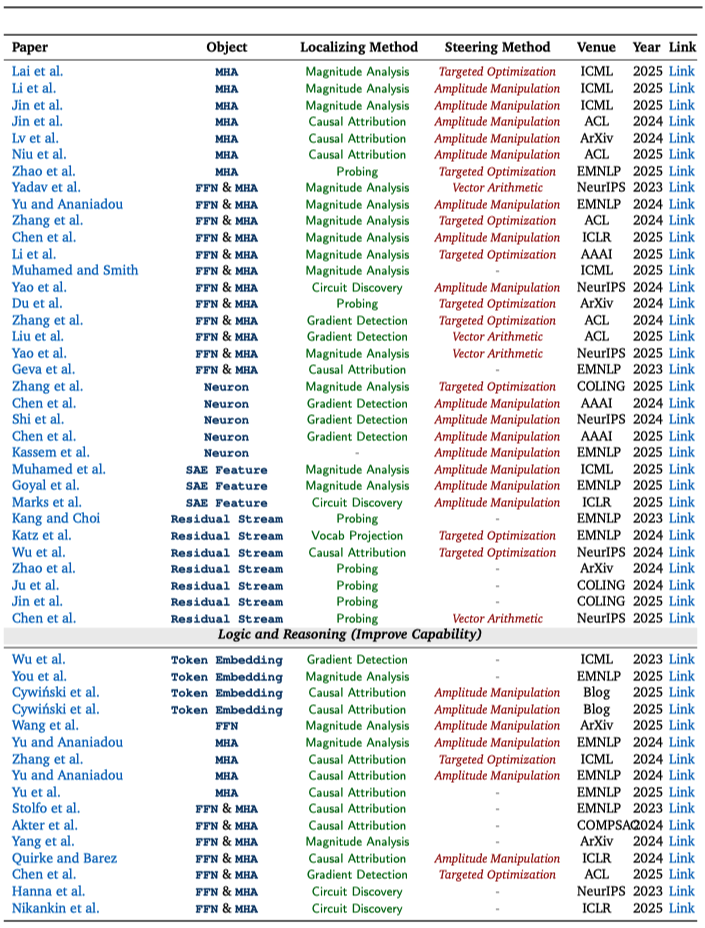
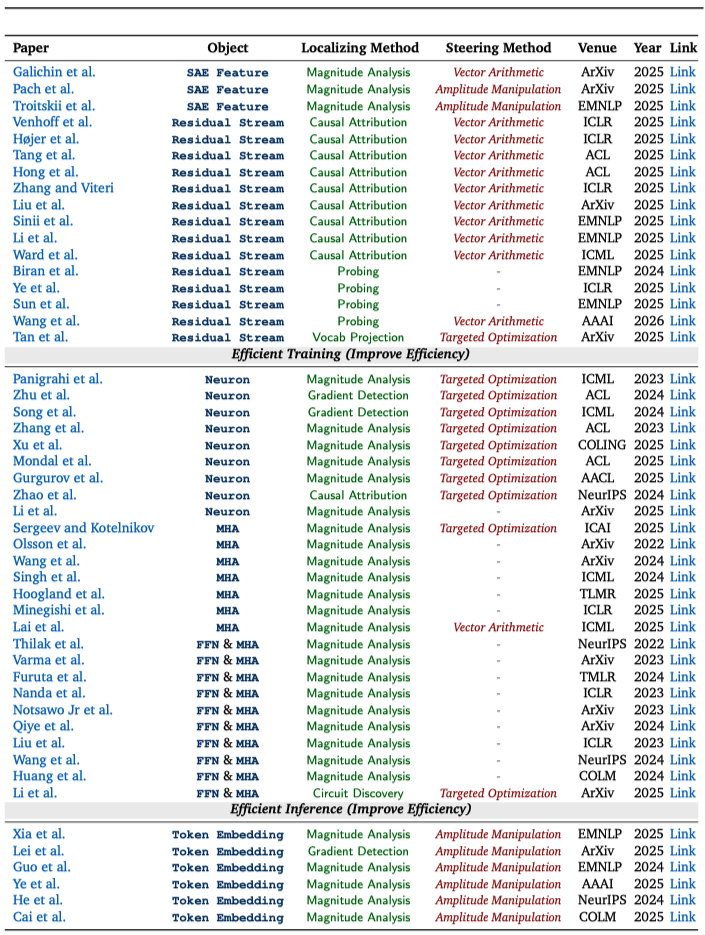
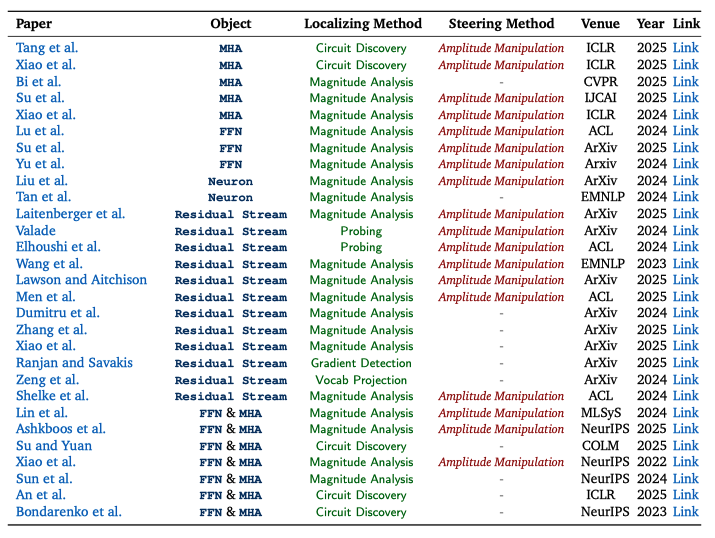
【结语】
本综述通过 "Locate-Steer-Improve" 的框架,首次系统地勾勒出了 MI 从分析走向具体干预的路线图。
展望未来,作者团队认为 MI 的核心挑战与机遇在于打破 “各自为战” 的局面 —— 需要建立标准化的评估基准(Standardized Evaluation),验证干预手段的泛化性;同时推动 MI 向自动化(Automated MI)演进,最终实现让 AI 自主发现并修复内部错误的愿景。
期待这篇综述能为社区提供一份详实的 “指南”,推动大模型从不可解释的黑盒,真正走向透明、可控、可信的未来。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com