微软发布自研AI芯片Maia 200,基于3nm工艺,专为AI推理设计,性能强大且高效。
原文标题:刚刚,微软全新一代自研AI芯片Maia 200问世
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 Maia 200 通过重新设计的内存子系统提升了 Token 吞吐量。那么,这种内存子系统的设计思想是什么?对于其他芯片设计有什么借鉴意义?
3、Maia 200 与 Azure 实现了无缝集成,并提供了 Maia SDK。对于开发者来说,使用 Maia SDK 开发和优化 AI 模型有哪些优势和挑战?
原文内容
一觉醒来,我们看到了微软自研 AI 芯片的最新进展。
微软原定于 2025 年发布的下一代 AI 芯片 Maia 200,终于在今天问世!
微软 CEO Satya Nadella
根据微软官方介绍,Maia 200 作为一款强大的 AI 推理加速器,旨在显著改善 AI token 生成的经济性。
Maia 200 基于台积电的 3 纳米工艺打造,配备原生 FP8/FP4 张量核心、重新设计的内存系统,拥有 216GB HBM3e 内存、7TB/s 带宽以及 272MB 片上 SRAM,并配有数据传输引擎,从而能够保证大规模模型高效、快速地进行数据流动。
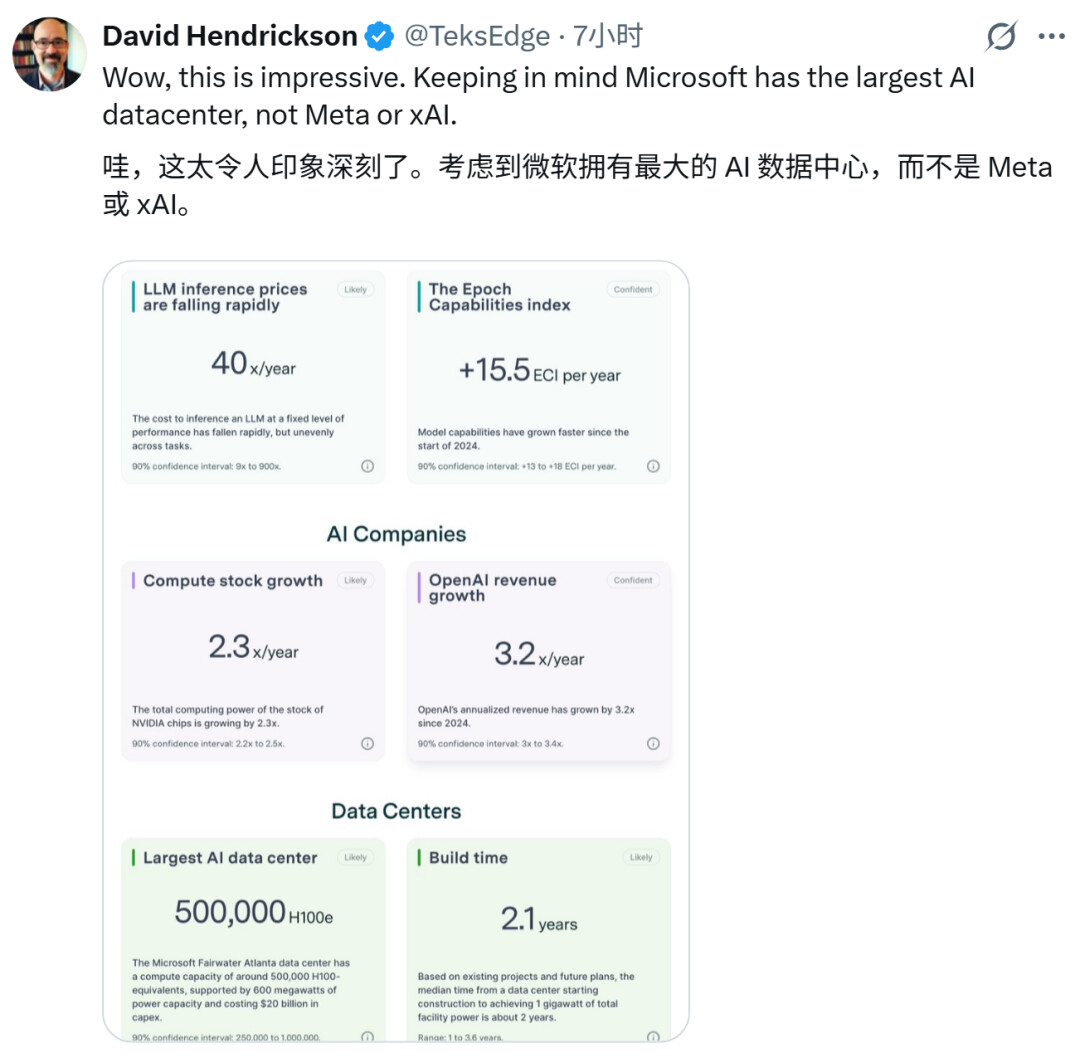
这些使得 Maia 200 成为任何超级计算平台中表现最强的第一方硅片,其 FP4 性能是第三代 Amazon Trainium 的三倍,FP8 性能超越了谷歌第七代 TPU。
与此同时,Maia 200 还是微软迄今为止最高效的推理系统,每美元性能比该公司当前集群中的最新一代硬件提升了 30%。

Maia 200 是微软异构 AI 基础设施的重要组成部分,将为包括 OpenAI 最新 GPT-5.2 在内的多个大模型提供支持,为 Microsoft Foundry 和 Microsoft 365 Copilot 带来更高的性价比优势。
微软超级智能团队将利用 Maia 200 进行合成数据生成和强化学习,以提升下一代自研模型的性能。在合成数据流水线应用场景中,Maia 200 的独特设计有助于加速高质量、特定领域数据的生成与筛选,从而为后续的模型训练提供更及时、更具针对性的信号。
Maia 200 已部署在爱荷华州德梅因附近的美国中部数据中心区域,接下来将部署在亚利桑那州菲尼克斯附近的美国西部 3 区域,未来还将扩展至更多地区。
Maia 200 与 Azure 实现了无缝集成。目前,微软正在开放 Maia SDK 的预览,该 SDK 提供了一整套用于构建和优化 Maia 200 模型的工具,涵盖了 PyTorch 集成、Triton 编译器、优化内核库以及对 Maia 底层编程语言的访问权限。这既能让开发者在需要时进行精细化控制,又能实现模型在不同异构硬件加速器之间的轻松迁移。
对于微软这波突如其来的「秀肌肉」,社区反响热烈。
有网友送出点赞,并强调了微软在基础设施层面的统治力。
也有人关心上面是否能安装最近爆火的 Clawdbot。

也不乏灵魂拷问/调侃。

专为 AI 推理打造
Maia 200 芯片采用台积电最先进的 3 纳米工艺制造,单颗芯片包含超过 1400 亿个晶体管。它专门针对大规模 AI 工作负载进行了定制,同时兼顾了极高的能效比。因此,无论是在性能还是成本效益方面,Maia 200 均表现卓越。
Maia 200 专为使用低精度计算的最新模型设计,在 750W 的 SoC 热设计功耗(TDP)范围内,单颗芯片可以提供超过 10 PetaFLOPS 的 FP4 性能和超过 5 PetaFLOPS 的 FP8 性能。
从实际应用来看,Maia 200 可以轻松运行当今规模最大的模型,并为未来更庞大的模型预留了充足的性能空间。

关键在于,算力(FLOPS)并非提升 AI 速度的唯一因素,数据的传输效率同样至关重要。Maia 200 通过重新设计的内存子系统解决了这一瓶颈。
该子系统以窄精度数据类型为核心,配备了专门的 DMA 引擎、片上 SRAM 和专用的片上网络(NoC)总线,用于实现高带宽数据移动,从而提升了 Token 吞吐量。
优化的 AI 系统
在系统层面,Maia 200 引入了一种基于标准以太网的新型两层 Scale-up 网络设计。通过定制的传输层和紧密集成的网卡(NIC),它在不依赖私有协议矩阵的情况下,实现了高性能、高可靠性和显著的成本优势。
每个加速器可以提供:
-
2.8 TB/s 的双向专用 Scale-up 带宽;
-
在包含多达 6,144 个加速器的集群中,实现可预测的高性能集合通信。
这种架构为密集型推理集群提供了可扩展的性能,同时降低了功耗和 Azure 全球机架的整体拥有成本(TCO)。
在每个托架(tray)内,四个 Maia 加速器通过直接的非交换链路全连接,使高带宽通信保持在本地,实现最佳推理效率。机架内和机架间的联网均采用相同的 Maia AI 传输协议,通过最少的网络跳数实现跨节点、机柜和集群的无缝扩展。
这种统一的架构简化了编程,提高了工作负载的灵活性,减少了闲置容量,并在云端规模下保持了性能与成本效率的一致性。

云原生开发模式
Microsoft 芯片开发计划的一个核心原则,是在最终芯片就绪之前,尽可能地验证整个端到端系统。
针对 Maia 200,一套复杂的预芯片环境从架构设计之初便发挥了引导作用,能够高保真地模拟大语言模型的计算与通信模式。正是通过这种早期的协同开发环境,微软得以在首颗芯片生产出来之前,就将芯片、网络与系统软件视为统一整体进行深度优化。
为了确保 Maia 200 能够在数据中心实现快速且无缝的部署,微软从设计阶段就同步开展了对后端网络及第二代闭环液冷换热单元等复杂系统组件的早期验证。通过与 Azure 控制平面的原生集成,该系统在芯片和机架层面实现了安全性、遥测、诊断及管理能力的全面覆盖,从而显著提升了生产级关键 AI 负载的可靠性与运行时间。
得益于这些投入,在首批封装件送达后的几天内,AI 模型便已在 Maia 200 芯片上成功运行。从首颗芯片到首个数据中心机架部署的时间缩短了一半以上,优于同类 AI 基础设施项目。这种从芯片到软件再到数据中心的端到端方法,直接转化为更高的利用率、更短的投产时间,以及在云规模下每美元性能和每瓦特性能的持续提升。

大规模 AI 时代才刚刚开启,基础设施将决定创新的边界。微软表示,Maia AI 加速器计划是跨代发展的。
在向全球基础设施部署 Maia 200 的同时,微软已经在设计未来几代产品,并期待每一代都能不断树立新标杆,为最重要的 AI 工作负载提供更卓越的性能和效率。
官方博客:
https://blogs.microsoft.com/blog/2026/01/26/maia-200-the-ai-accelerator-built-for-inference/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com