阿里发布千问 Qwen3-Max-Thinking,性能比肩 Gemini 3 Pro,并在多项基准测试中刷新纪录,向国际顶尖水平靠拢!
原文标题:性能比肩Gemini 3 Pro!昨晚,阿里千问最强模型来了
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 Qwen3-Max-Thinking 的自适应工具调用能力,能否具体举例说明,在实际应用中,这种能力会带来哪些便利?
3、Qwen3-Max-Thinking 在哪些方面还有提升空间?未来大模型的发展趋势会是什么样的?
原文内容
1 月 26 日深夜,阿里千问旗舰推理模型 Qwen3-Max-Thinking 正式上线。
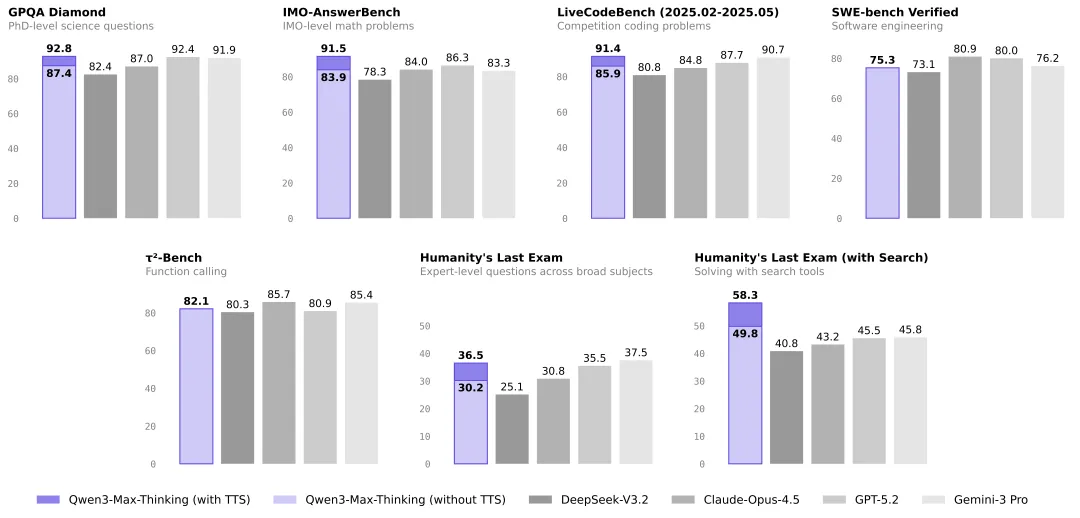
该模型在科学知识(GPQA Diamond)、数学推理(IMO-AnswerBench)、代码编程(LiveCodeBench)等多项权威基准测试中刷新纪录,其综合性能已可对标 GPT-5.2 与 Gemini 3 Pro,成为目前最接近国际顶尖水平的国产大模型之一。
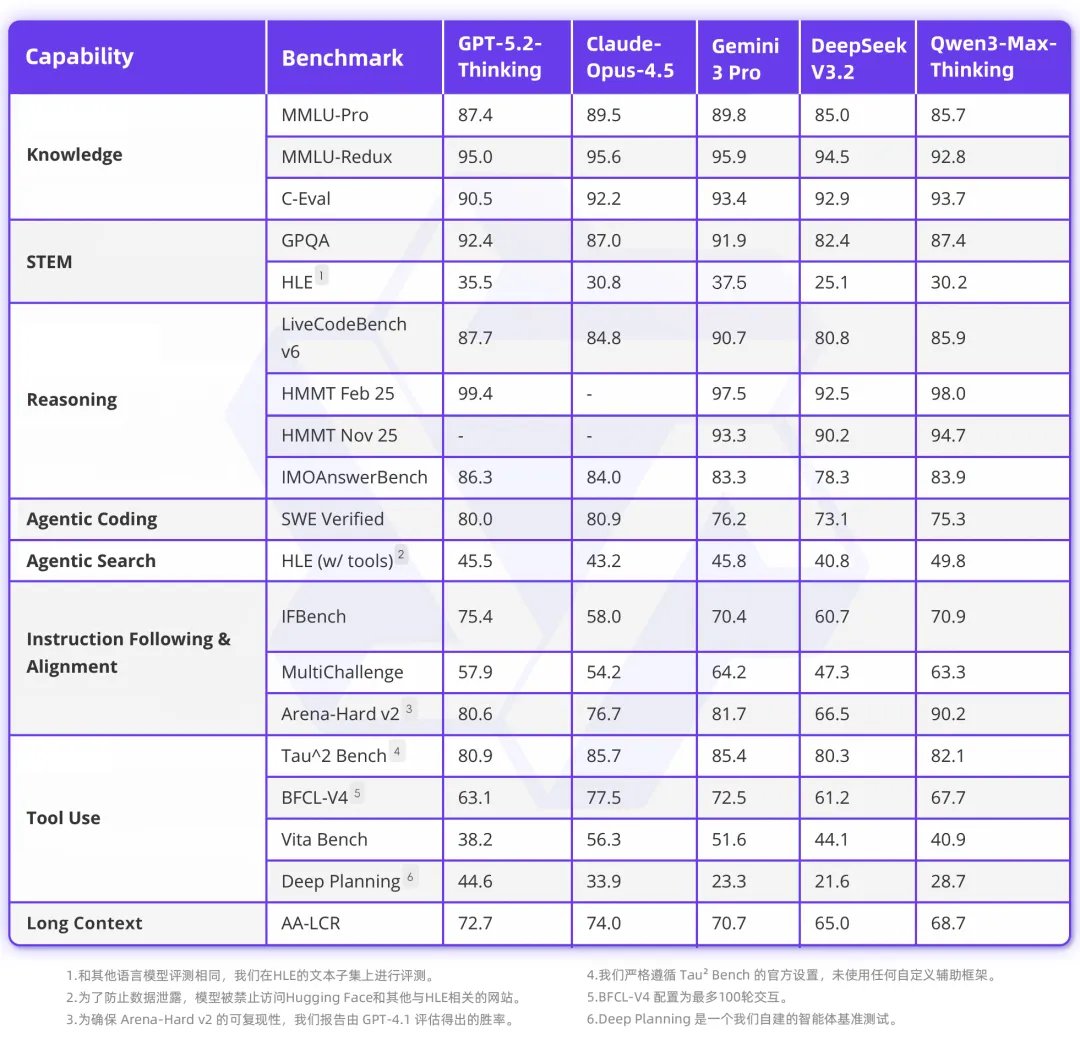
下表为更全面的评估分数:
据了解,Qwen3-Max-Thinking 总参数量超万亿(1T),预训练数据量高达 36T Tokens,是阿里目前规模最大、能力最强的推理模型。
此前,预览版 Qwen3-Max-Thinking 已展现出不俗实力。基于这一基础,通义团队进一步扩大了强化学习后训练规模,对模型进行了系统性优化,使正式版在多项核心能力上实现整体跃升。
在覆盖事实知识、复杂推理、指令遵循、人类偏好对齐以及 Agent 能力等 19 项主流评测基准中,Qwen3-Max-Thinking 取得多项领先成绩,刷新了多项最佳纪录,其综合表现已进入与 GPT-5.2-Thinking-xhigh、Claude Opus 4.5、Gemini 3 Pro 同一竞争梯队。
真实表现如何,我们上手体验了一下。
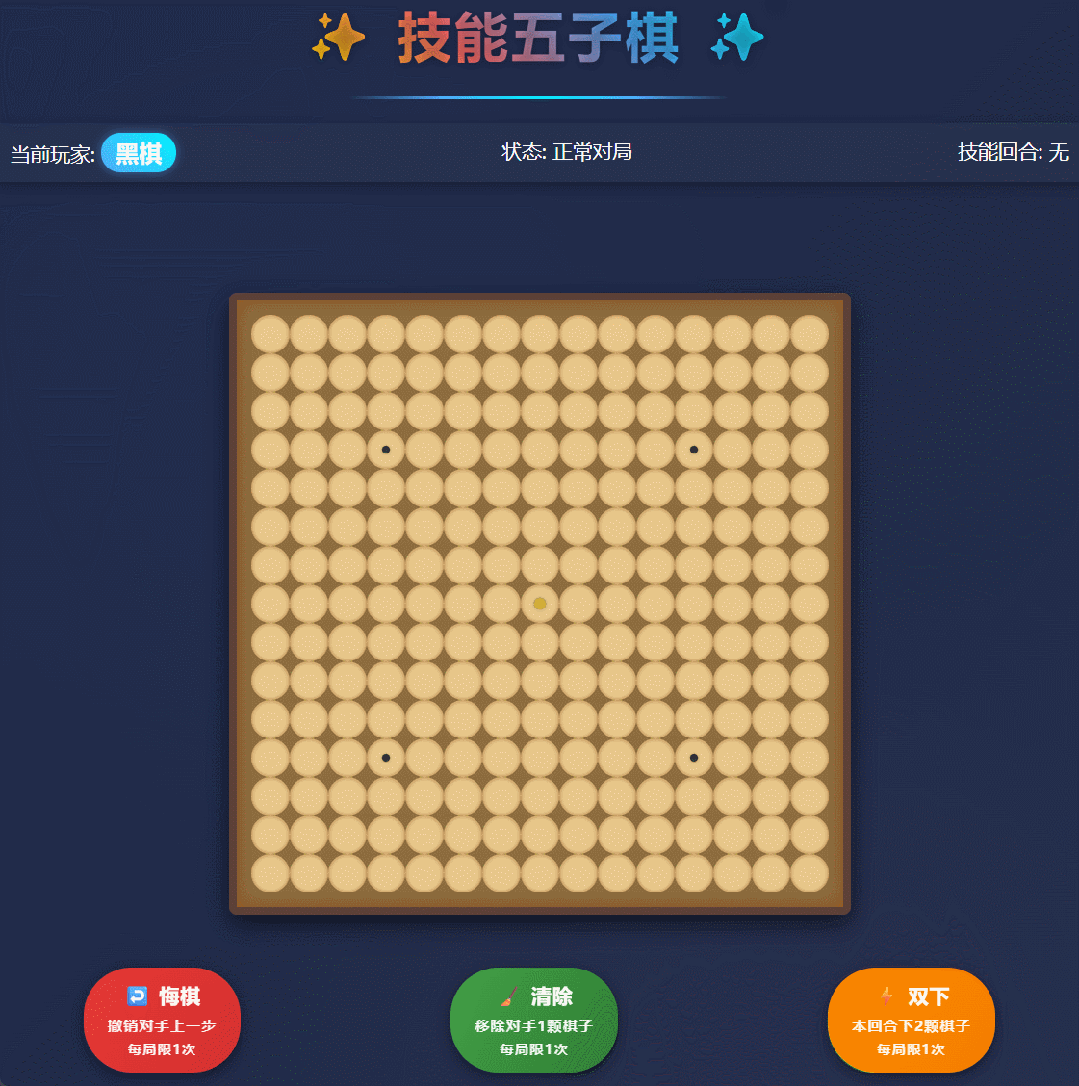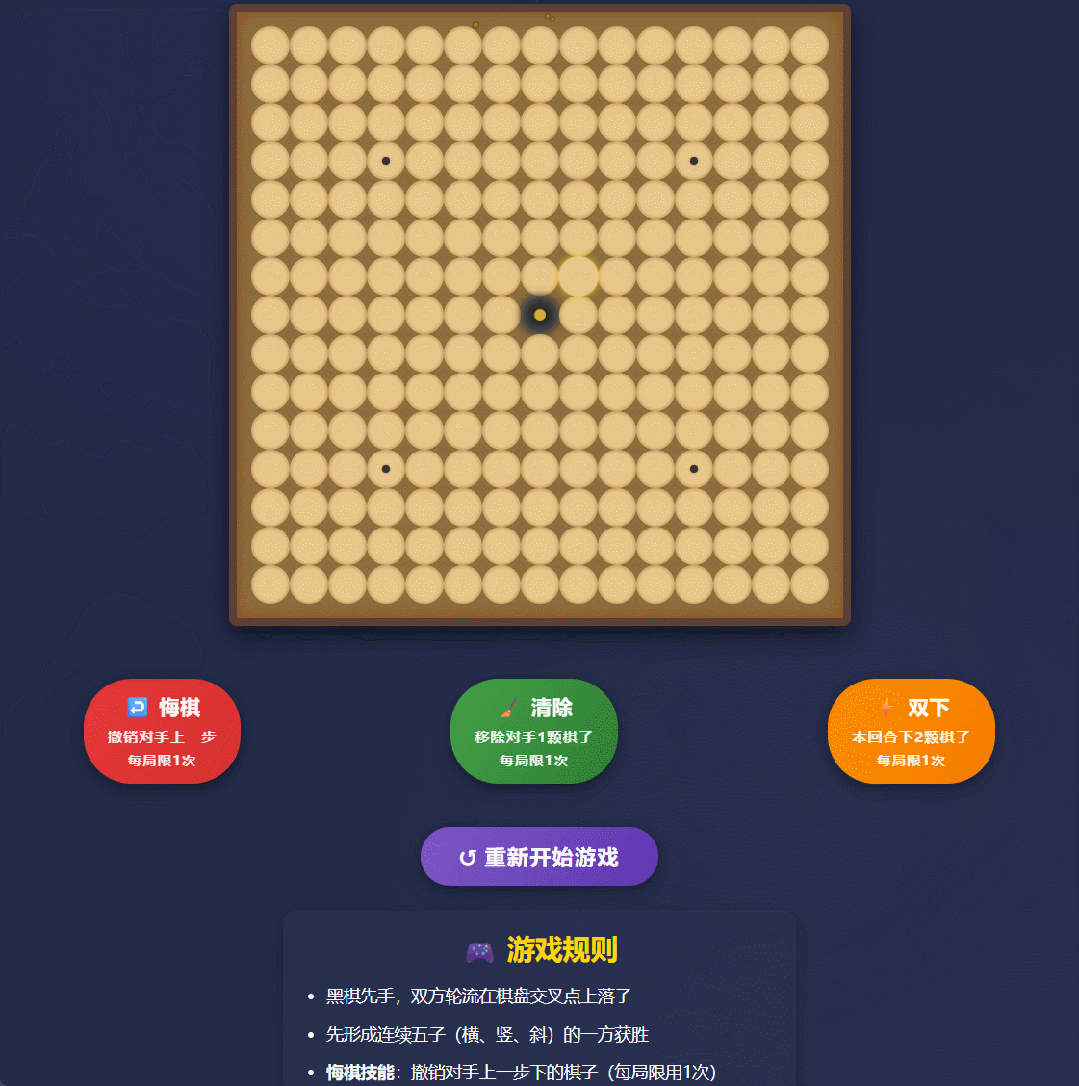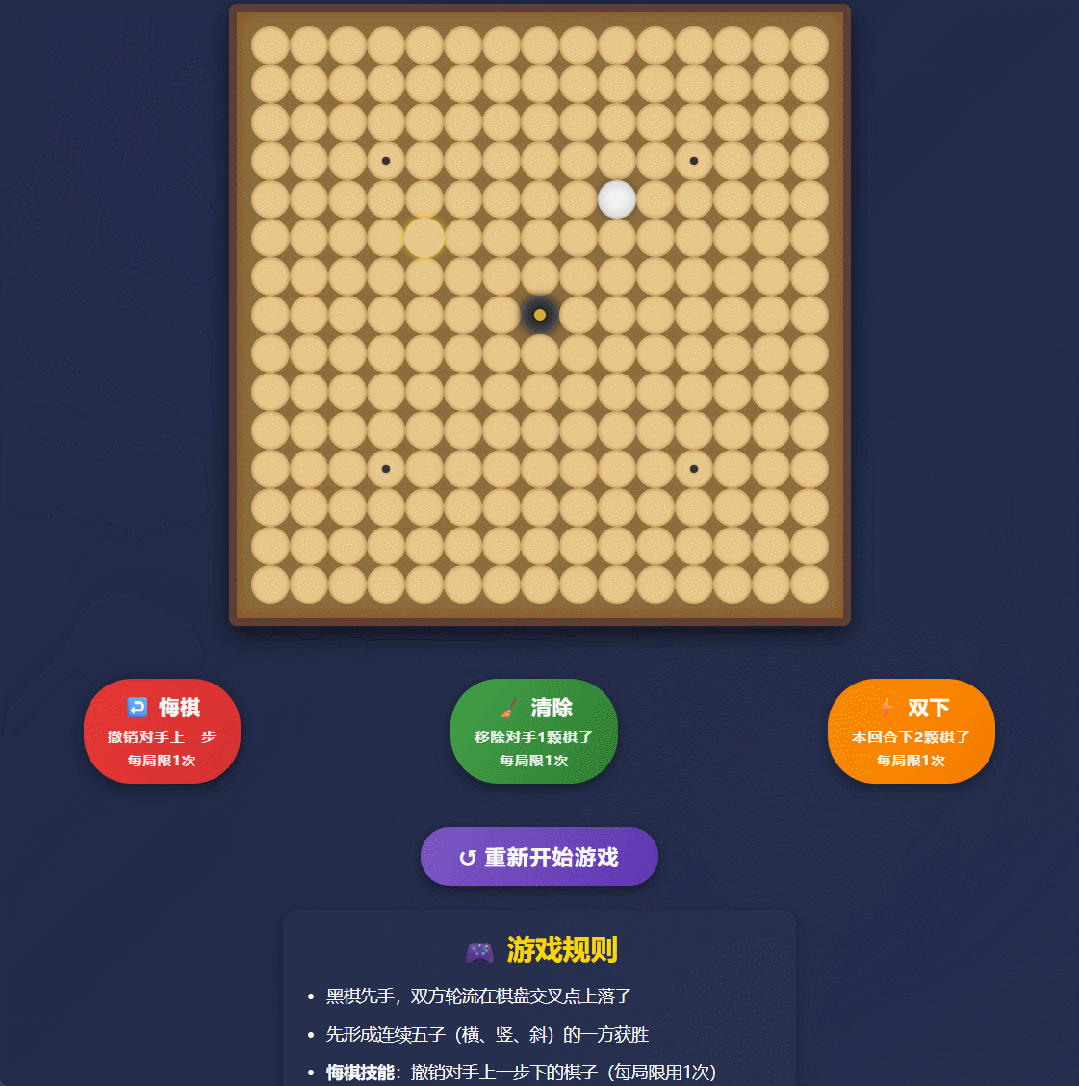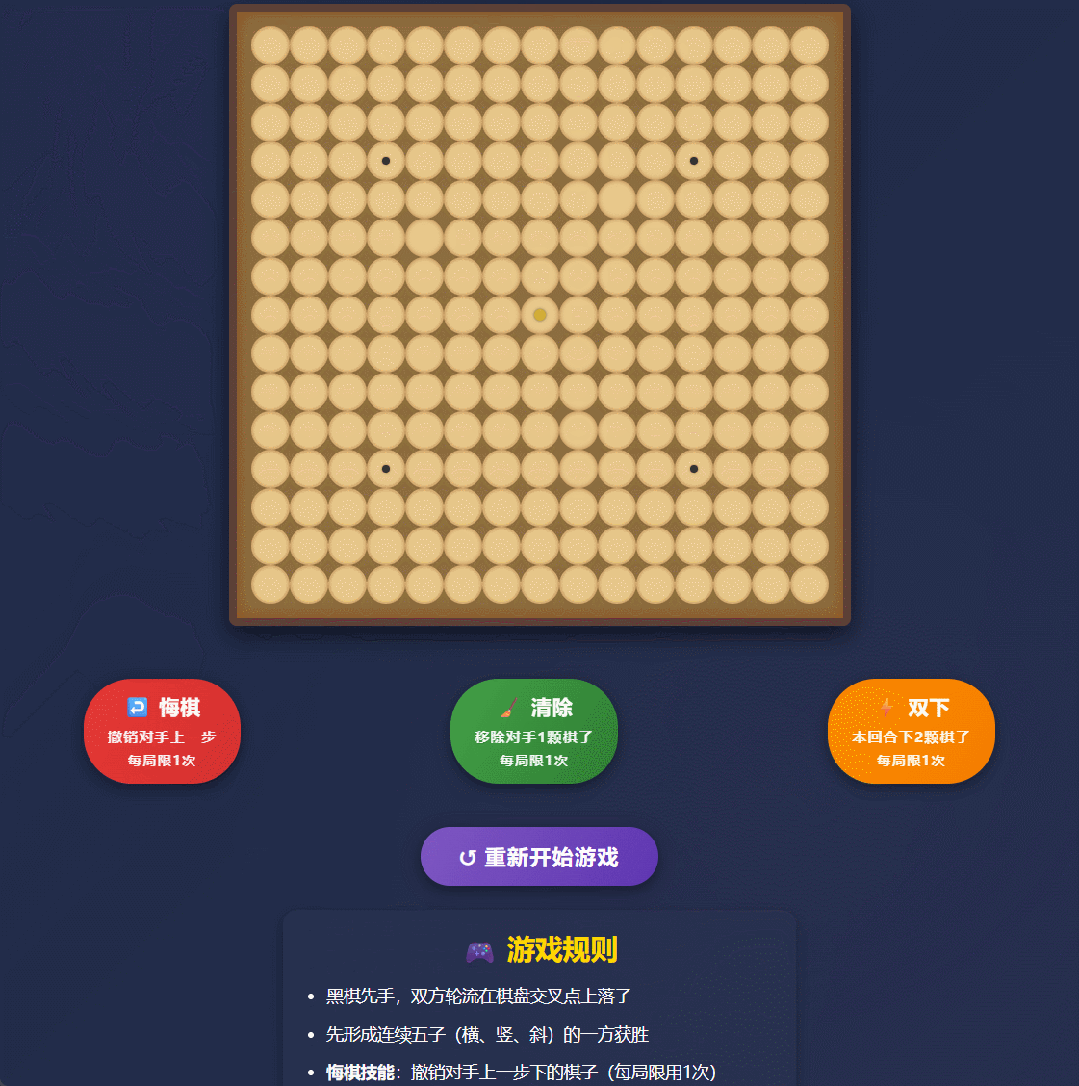
我们输入提示:帮我做一个技能五子棋的游戏网页,要求是在普通的五子棋规则上,玩家可以使用技能。直接给我个 html 文件。
一会儿工夫,Qwen3-Max-Thinking 就嗖嗖甩出 1000 多行代码,把一个可交互、能上手就玩的五子棋直接写完整了。
下一项测试,我们让 Qwen3-Max-Thinking 生成一个跳一跳游戏。
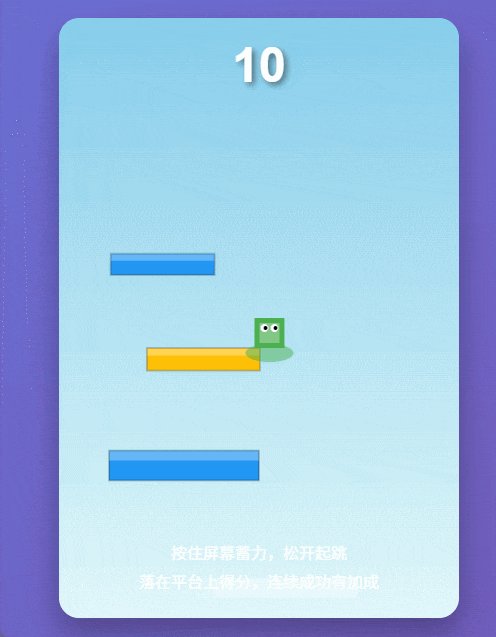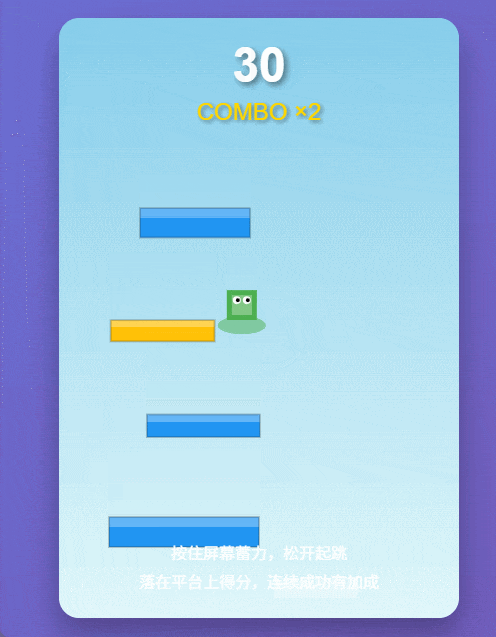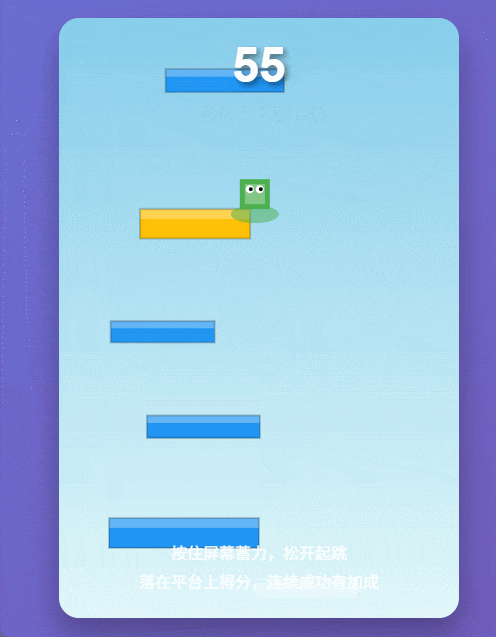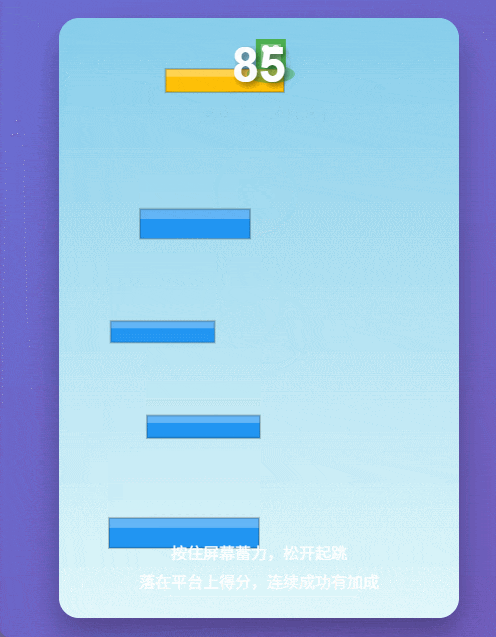
请用纯 HTML + CSS + 原生 JavaScript 写一个可在浏览器直接打开的《跳一跳》小游戏(不要依赖任何外部库)。要求:画面:简洁 2D 即可(canvas 或 DOM 都行);操作:按住蓄力、松开起跳(按住时间决定跳跃距离);规则:从一个平台跳到下一个平台,落空则结束;生成:平台位置随机,但保证可达(不要生成必死局);计分:落在平台上加分,连跳加成可选;体验:有起跳动画、落地判定、失败提示、重新开始按钮;代码:完整可运行,放在一个 HTML 文件里,注释清晰。
这个游戏最难的地方,就在于按住鼠标的时间既是操作,也是赌注:短了跳不过去,长了直接飞过头,容错窗口小到离谱。第一跳很容易失误,然后就 Game Over。
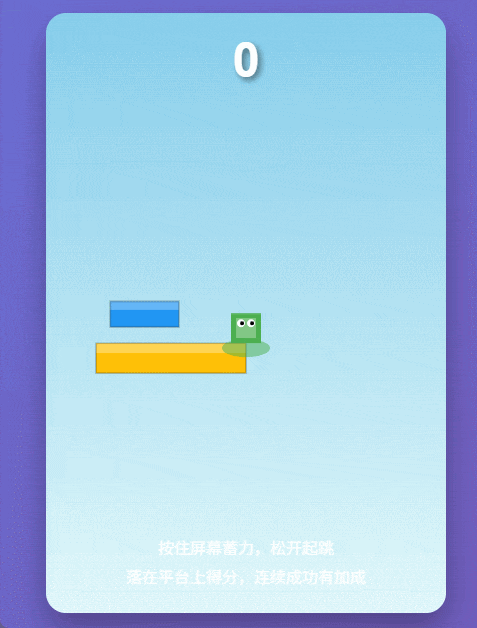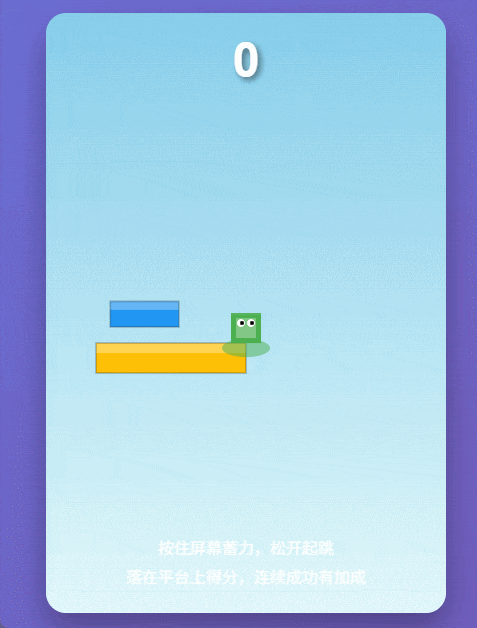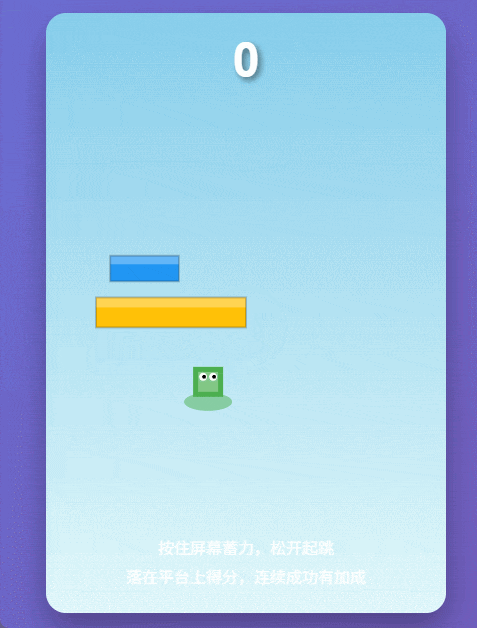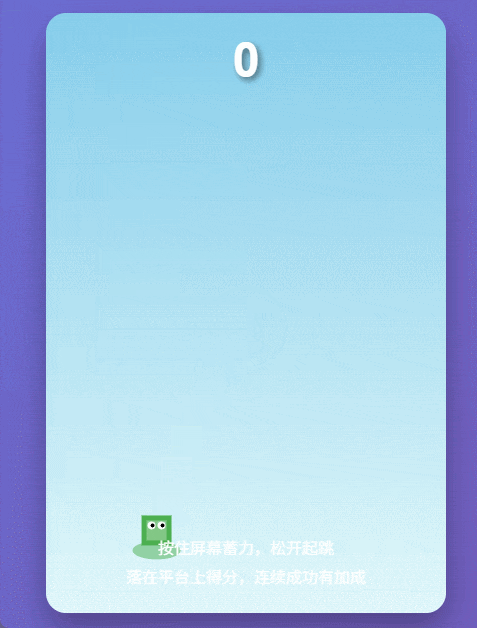
体验地址:https://chat.qwen.ai/
测试时扩展的重新定义
推动 Qwen3-Max-Thinking 的核心创新在于其对传统推理方式的突破。与大多数模型按线性方式逐 token 生成不同,Qwen3 引入了一种由测试时扩展(Test-time scaling)驱动的 Heavy Mode(重推理模式)。
通俗来说,这一技术让模型能够用更多算力换取更高智能水平。但它并非简单的 best-of-N 采样方式,例如一次生成 100 个答案再从中选出最优结果 —— 而是采用了一种经验累积的多轮推理策略。
这种方法更接近人类的解题过程。当模型面对复杂问题时,它不会直接给出一次性猜测,而是进入反复自我反思与迭代推理。通过一种专有的 take-experience 机制,模型能够从此前的推理步骤中提炼有效经验,从而实现:
-
识别死胡同:在无需完整走完错误推理路径的情况下,判断某条推理思路正在失效;
-
聚焦算力:将计算资源重新分配到尚未解决的不确定点,而不是反复推导已经得到的结论。
这种机制带来了实实在在的效率提升。通过避免冗余推理,模型可以在同样的上下文窗口中整合更丰富的历史信息。千问团队表示,该方法在不显著增加 token 成本的前提下,实现了性能的大幅跃升:
-
GPQA(博士级科学问题):得分从 90.3 提升至 92.8;
-
LiveCodeBench v6:成绩从 88.0 提升至 91.4。
自适应工具调用
如果说推理能力决定了模型会不会想,那么工具调用能力决定的,是模型能不能真正把事做成。在 Qwen3-Max-Thinking 中,通义团队不再将推理与工具使用视为两个割裂的阶段,而是将工具能力内生进思考过程本身,构建起一种边思考、边行动的原生 Agent 式模型框架,让大模型从静态的文本推理,迈向可执行、可验证的复杂任务处理。
在完成基础的工具使用微调后,通义团队进一步在大量多样化任务上,引入基于规则奖励与模型奖励的联合强化学习训练,使模型学会何时调用工具、如何结合工具展开推理,而不是机械执行指令。由此,Qwen3-Max-Thinking 获得了更具策略性的工具协同思考能力。
这一自适应工具调用能力已在 QwenChat 中完整落地:模型可自主调度搜索、个性化记忆与代码解释器等核心 Agent 工具,在一次交互中完成信息获取、计算推演与结论生成,回答更贴近专业人士的工作方式,也显著降低了模型幻觉,为解决真实世界中的复杂问题奠定基础。
结语
截至 2026 年 1 月,阿里通义千问(Qwen)系列模型在 Hugging Face 平台上的累计下载量超过了 10 亿次,这一数据使得 Qwen 成为了 Hugging Face 上最受欢迎、下载量最高的开源 AI 模型系列之一。
Qwen3-Max-Thinking 的推出代表着 2026 年人工智能市场的成熟。它将讨论的焦点从谁拥有最智能的聊天机器人转移到谁拥有功能最强大的智能体。通过将高效率推理能力与自适应、自主的工具调用机制相结合,Qwen 已经牢牢确立了自己在企业级 AI 竞争格局中的领先地位。
参考链接:https://venturebeat.com/technology/qwen3-max-thinking-beats-gemini-3-pro-and-gpt-5-2-on-humanitys-last-exam

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com