阿里发布万亿参数 Qwen3-Max-Thinking,多项基准测试媲美甚至超越 GPT-5.2、Claude-Opus 和 Gemini-3 Pro。
原文标题:参数破万亿!阿里Qwen3-Max-Thinking发布,编程能力“踢馆”Gemini与Claude
原文作者:AI前线
冷月清谈:
怜星夜思:
2、文章中提到的“测试时扩展技术”通过“经验提取”避免重复推导,这种机制的具体原理是什么?它与传统的并行采样与聚合方法相比,优势体现在哪些方面?
3、网友评论中提到“产品体验、生态建设是否匹配当前能力”,你认为目前大模型在产品化和生态构建方面面临的最大挑战是什么?
原文内容

就在刚刚,Qwen3-Max-Thinking 正式版突然发布,总参数规模超过 1 万亿(1T),位于目前全球最大规模 AI 模型行列,预训练数据规模高达 36T Tokens,覆盖大量高质量语料。
Qwen3-Max 是阿里通义团队迄今规模最大、能力最强的语言模型,该版本包括 Base、Instruct 和 Thinking 多种形式。
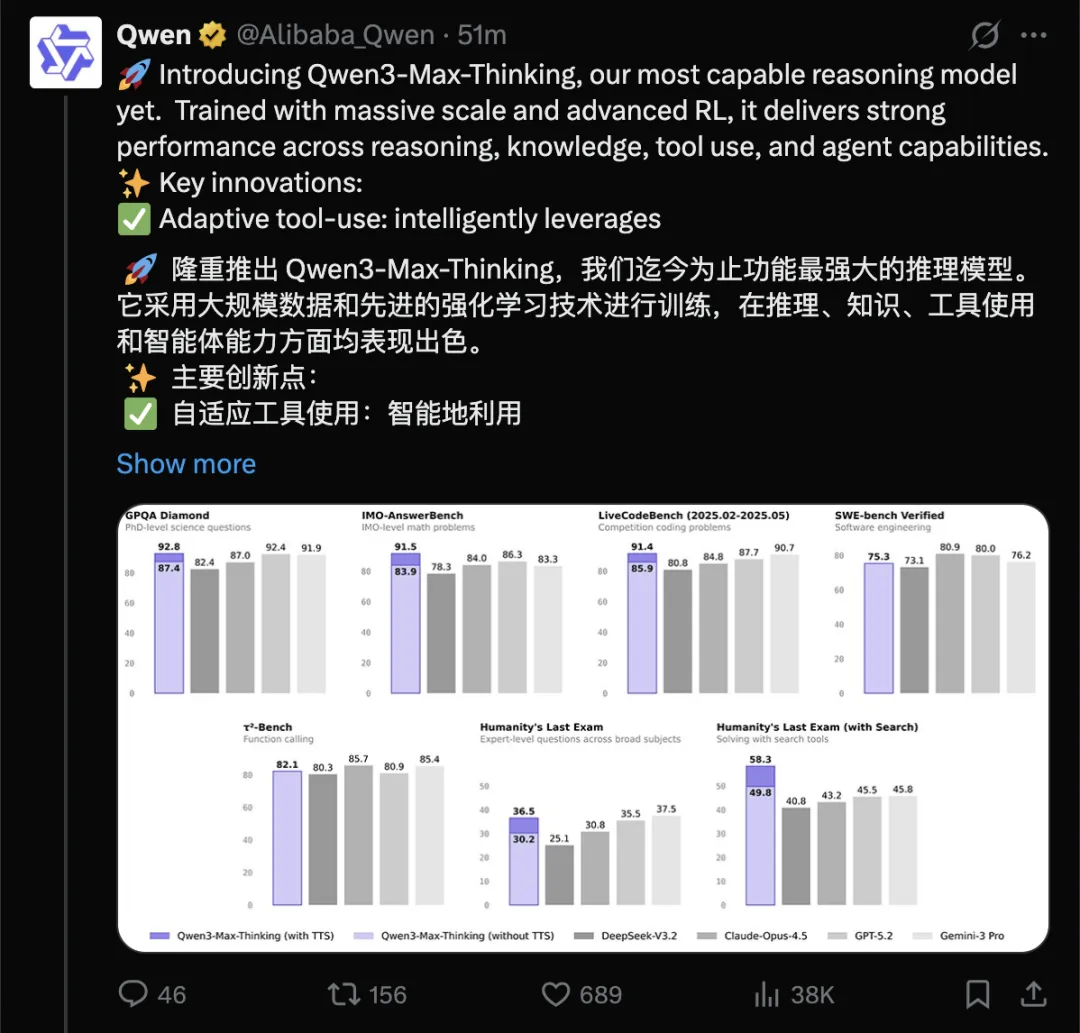
在多项权威基准测试中表现优异,Qwen3-Max-Thinking 性能可与 GPT-5.2-Thinking、Claude-Opus-4.5、Gemini-3 Pro 等闭源顶级模型竞争甚至超越。
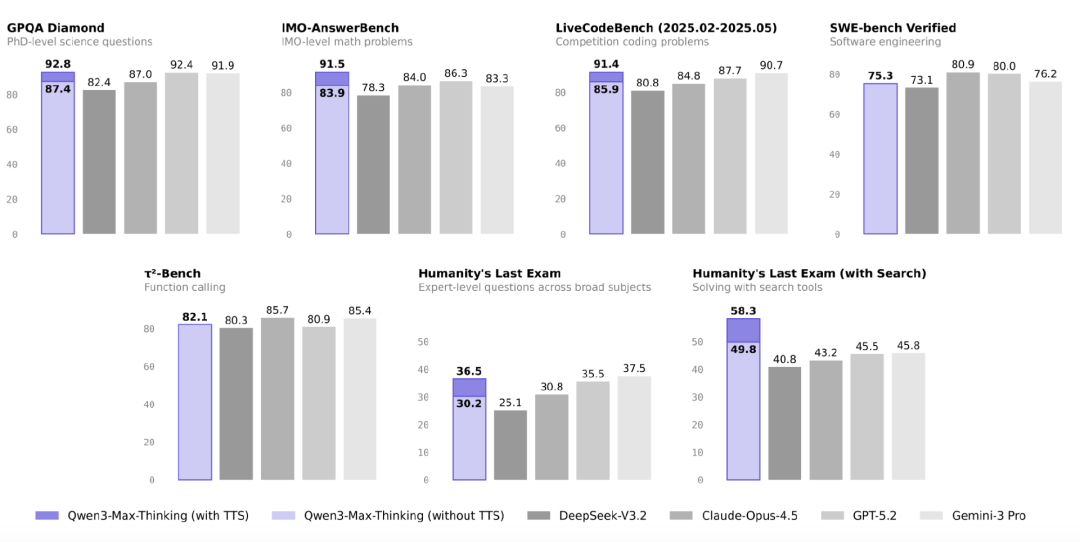
具体而言,Qwen3-Max-Thinking 在多项关键 AI 基准测试中达到了或刷新了全球 SOTA 表现:
-
在包含事实科学知识、复杂推理和编程能力在内的 19 项权威基准测试中取得极高水平,有记录显示其综合表现可媲美 GPT-5.2-Thinking、Claude-Opus-4.5 及 Gemini-3 Pro 等业内领先模型。
-
在数学推理基准测试中,该模型曾在预览阶段实现 AIME 25 和 HMMT 25 满分(即 100% 准确率),这一表现被认为代表了高难度数学推理能力。
-
相较于此前的 Instruct 版本,Thinking 版本在 Agent 工具调用、复杂逻辑和深度推理任务中表现出更优的能力。
这些测试覆盖了科学知识问答(如 GPQA Diamond)、数学推理(如 IMO 等级测试)、代码编程(如 LiveCodeBench)等多个领域,是衡量大型语言模型综合能力的重要指标。
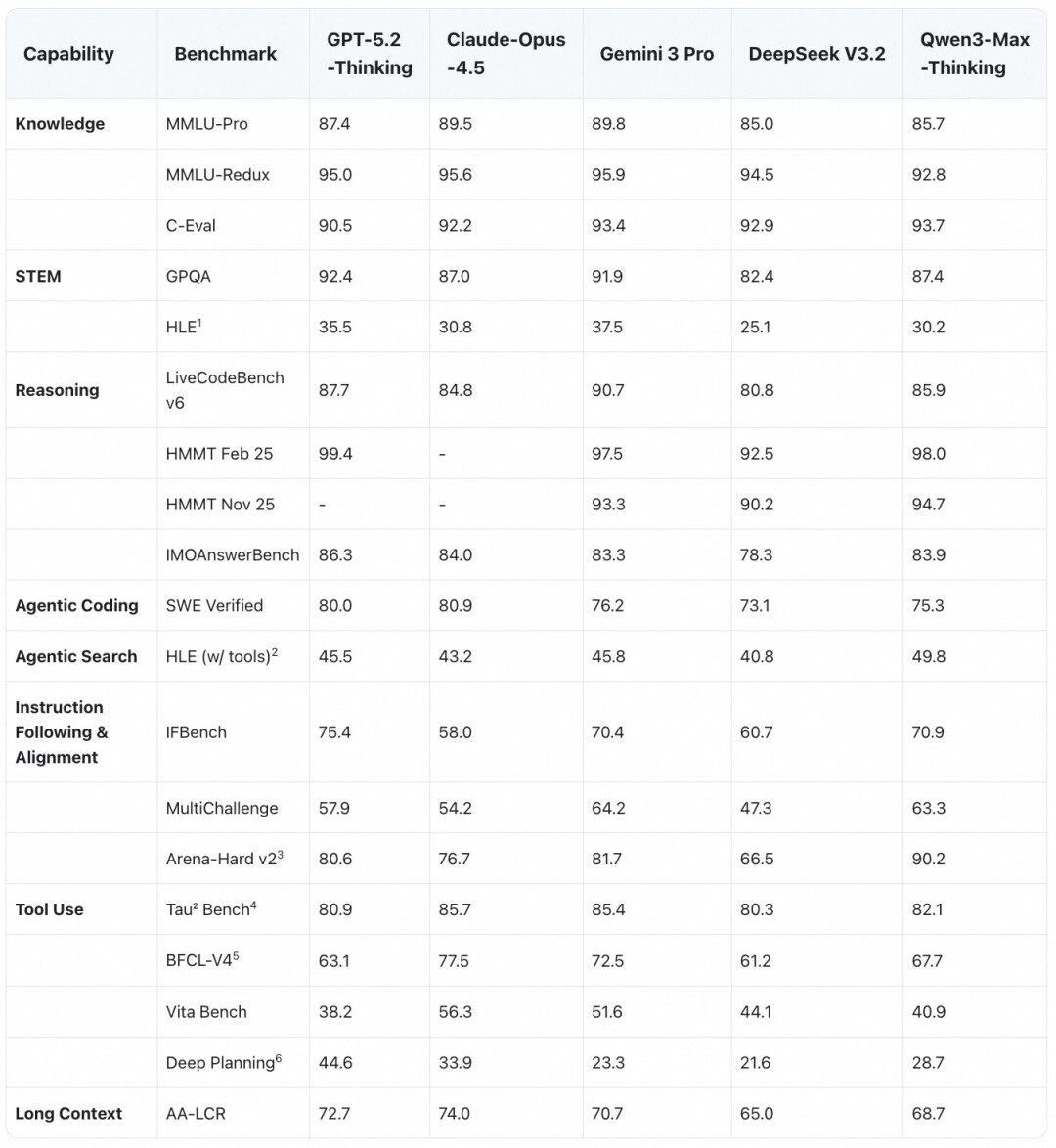
为实现上述性能突破,千问团队在官方博客中称为 Qwen3-Max-Thinking 引入两项核心创新:
-
自适应工具调用能力,可按需调用搜索引擎和代码解释器,现已上线;
-
测试时扩展技术(Test-Time Scaling),显著提升推理性能,在关键推理基准上超越 Gemini 3 Pro。
那么,这两项核心创新到底什么意思?
首先是自适应工具调用能力,据千问团队介绍,与早期需要用户手动选择工具的方法不同,Qwen3-Max-Thinking 能在对话中自主选择并调用其内置的搜索、记忆和代码解释器功能。
该能力源于专门设计的训练流程:在完成初步的工具使用微调后,模型在多样化任务上使用基于规则和模型的反馈进行了进一步训练。实验表明,搜索和记忆工具能有效缓解幻觉、提供实时信息访问并支持更个性化的回复。代码解释器允许用户执行代码片段并应用计算推理来解决复杂问题。这些功能共同提供了流畅且强大的对话体验。
再来说说测试时扩展。该技术是指在推理阶段分配额外计算资源以提升模型性能的技术。研发团队提出了一种经验累积式、多轮迭代的测试时扩展策略。
不同于简单增加并行推理路径数量 N(这往往导致冗余推理),团队对并行轨迹数量进行限制并将节省的计算资源用于由“经验提取”机制引导的迭代式自我反思。
该机制从过往推理轮次中提炼关键洞见,使模型避免重复推导已知结论,转而聚焦于未解决的不确定性。关键在于,相比直接引用原始推理轨迹,该机制实现了更高的上下文利用效率,在相同上下文窗口内能更充分地融合历史信息。在大致相同的 token 消耗下,该方法持续优于标准的并行采样与聚合方法:GPQA (90.3 → 92.8)、HLE (34.1 → 36.5)、LiveCodeBench v6 (88.0 → 91.4)、IMO-AnswerBench (89.5 → 91.5) 和 HLE (w/ tools) (55.8 → 58.3)。
这些技术改善了模型处理复杂任务时的自主规划、推理链构建和决策能力。
千问 App PC 端和网页端已经第一时间上新这一 Qwen 系列最强模型,现在即可免费体验。API(qwen3-max-2026-01-23)也已开放。
体验地址:https://chat.qwen.ai/?spm=a2ty_o06.30285417.0.0.1ef4c921OJuiXU
在模型发布消息传出后,社交平台上也迅速出现了大量讨论。一部分网友的关注点集中在模型能力本身,语气中带着明显的惊讶与认可。
有海外开发者在 X 上表示,自己已经习惯看到 Qwen 在多个榜单上“反超”其他模型。
“Qwen 总是能跑赢其他模型,”一位用户调侃道,同时也提出了更偏产品层面的期待,希望 Qwen 能在 Android 端做出“更简洁、更有辨识度的应用设计”,认为模型能力已经走在前面,产品体验还有进一步打磨空间。
也有不少声音将 Qwen 的发布节奏与国际头部厂商作对比。一位网友直言,通义千问团队在模型更新和能力披露上的频率,甚至“已经超过了 OpenAI”。在他看来,这种持续、高密度的迭代和公开沟通,本身就是一种对开发者更友好的信号,至少让外界清楚知道模型在什么阶段、解决了哪些问题。
还有用户的反馈则更为直接。一位名为 Harriett Solid 的网友在评论中写道:“这正是我一直在等的 Qwen 发布版本。”这类评价并未展开具体技术细节,但从情绪上看,显然将 Qwen3-Max-Thinking 视为一次“到位”的升级,而不是过渡性产品。
整体来看,网友评论呈现出两个明显特点:一方面,对 Qwen 在推理能力和更新速度上的认可度较高;另一方面,讨论已经开始从“模型是否强”延伸到“产品体验、生态建设是否匹配当前能力”。
这也从侧面反映出,随着模型能力逼近甚至进入全球第一梯队,外界对通义千问的期待,正在从单点技术突破,转向更完整的产品与平台层面。
参考链接:
https://chat.qwen.ai/
https://qwen.ai/blog?id=qwen3-max-thinking
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止转载。

