GARDO:通过门控自适应正则化和多样性感知优化,解决扩散模型RL微调中的Reward Hacking难题,实现高效探索和多样性生成。
原文标题:拒绝Reward Hacking!港科联合快手可灵提出高效强化学习后训练扩散模型新范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、GARDO框架中,定期更新Reference Model π_ref 被描述为“动态更新的锚点”,这能保证训练稳定性和探索更广阔空间。但是,如果更新频率不合适,会不会反而导致训练不稳定?有没有什么自适应的更新策略?
3、GARDO通过多样性感知优势重塑来避免模式坍塌,使用DINOv3提取特征并计算样本在特征空间中的稀疏度。但DINOv3毕竟是预训练模型,是否会限制模型的多样性?有没有其他更灵活、更能反映生成模型自身特点的多样性度量方法?
原文内容

在使用强化学习(RL)微调扩散模型(如 Stable Diffusion, Flux)以对齐人类偏好时,我们常面临一个棘手的 “两难困境”:追求高奖励会导致图像质量崩坏(即 Reward Hacking),而为了防止崩坏引入的 KL 正则化又会严重阻碍模型的探索和收敛。
最近,来自于香港科技大学,快手可灵 AI,港中文以及爱丁堡大学的研究团队提出了一种全新的框架 GARDO。它通过门控自适应正则化和多样性感知优化,成功在防止 Reward Hacking 的同时,实现了高效的样本探索和多样性生成。研究工作已经全面开源。
论文第一作者何浩然是香港科技大学博士生,研究方向包括强化学习和多模态基础模型等,研究目标是开发下一代可扩展强化学习后训练算法。通讯作者为香港科技大学电子及计算机工程系、计算机科学与工程系助理教授潘玲。

-
论文标题:GARDO: Reinforcing Diffusion Models without Reward Hacking
-
项目主页:https://tinnerhrhe.github.io/gardo_project
-
论文链接:https://arxiv.org/pdf/2512.24138
背景与动机:RL 后训练中的陷阱
强化学习(RL)在视觉领域的后训练中展现出了不错的效果,逐渐成为当前研究的热点。最近半年,如 flow-grpo,dancegrpo 以及 DiffusionNFT 等工作受到了大家广泛关注。
然而,在视觉任务中,定义一个完美的 “奖励函数(Reward Function)” 极其困难。我们通常使用的是一个代理奖励(Proxy Reward),例如 ImageReward、Aesthetic Score 或者 OCR 识别率。
这就导致了一个典型的问题:Reward Hacking。当模型过度优化这个代理奖励时,它会找到奖励模型的漏洞(Out-of-Distribution, OOD 区域)。结果就是,代理分数(Proxy Score)极高,但生成的图像充满了噪点、伪影,甚至完全失去了真实感。

Reward Hacking 定义
下面展示文生图出现 hacking 的例子:

为了解决这个问题,传统方法(如 DPOK, Flow-GRPO)通常引入 KL 散度正则化,强迫微调后的策略 π_θ 不要偏离原始参考策略 π_ref 太远。但研究团队发现,这种 “一刀切” 的 KL 正则化带来了新的问题:
-
样本效率低:RL 目标函数会被 KL 惩罚项的 π_ref 拖后腿,学习速度变慢。
-
阻碍探索:π_ref 本身通常是次优的,强制 π_θ 贴近它会阻止模型探索那些参考模型 π_ref 未发现的高奖励区域。
核心问题来了,能否在不牺牲样本效率和探索能力的前提下,防止 Reward Hacking?
GARDO:门控、自适应与多样性
为了打破上述困境,作者提出了 GARDO (Gated and Adaptive Regularization with Diversity-aware Optimization) 框架。
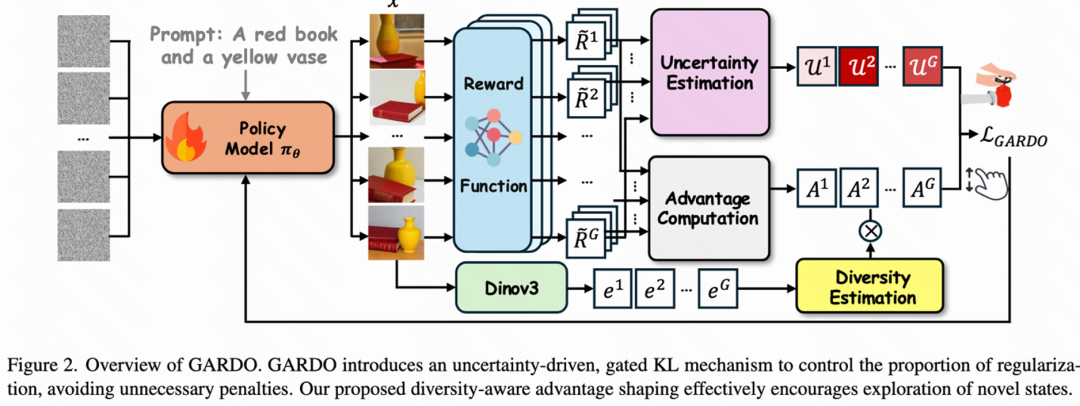
GARDO 方法概览图
KL-regularized RL 的最优解可以写成:
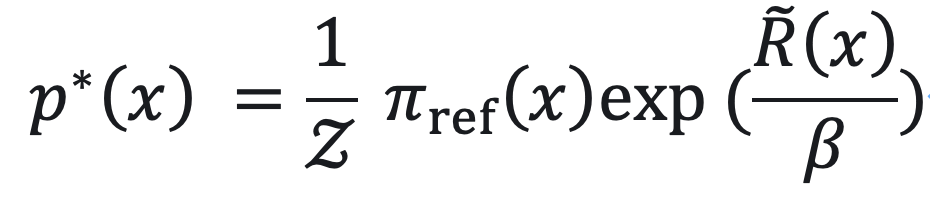
很大程度上由 π_ref (x) 和代理奖励函数 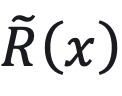 决定。
决定。
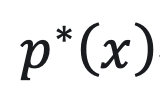

基于上述观察,GARDO 的框架基于三个核心洞察:
洞察一:正则化不需要 “雨露均沾”
方法:门控 KL 机制 (Gated KL Mechanism)
根据定义 1,只有当模型 π_θ 生成的样本落在代理奖励不可靠的区域(即 OOD 区域)时,才真正需要 KL 正则化。对于那些既高质量又在分布内的样本,施加惩罚只会阻碍学习。
GARDO 引入了不确定性估计(通过奖励模型集成 ranking 差异来衡量)。

其中 计算的一个 batch 里的胜率。

-
做法:只对那些具有高不确定性 (Reward Model 拿不准,可能是 Hacking)的样本施加 KL 惩罚。
-
效果:实验发现,仅对约 10% 的高不确定性样本进行惩罚,就足以有效防止 Reward Hacking,让其余 90% 的样本自由探索。从而实现在不牺牲样本效率的情况下,有效抑制 hacking 现象的出现。
洞察二:静态的 π_ref 会限制 RL 优化的上限
方法:自适应正则化目标 (Adaptive Regularization Target)
如果 π_ref 一直不变,随着 π_θ 的变强,KL 惩罚会主导整个 learning Loss,导致优化停滞。
-
做法:定期更新 Reference Model π_ref(将其重置为当前的策略)。
-
效果:这就像给模型设立了动态更新的 “锚点”,既保证了训练的稳定性,又允许模型持续进化,探索更广阔的空间。
洞察三:RL 容易 mode collapse,需要鼓励多样性生成
方法:多样性感知优势重塑 (Diversity-Aware Advantage Shaping)
RL 训练容易导致 Mode Collapse(模式坍塌),即模型发现一种高分画法后就只会画这一种。这不仅降低了生成质量,也加剧了 Reward Hacking。
-
做法:利用 DINOv3 提取特征,计算样本在特征空间中的稀疏度作为 “多样性分数”。将此分数以乘法形式作用于优势函数(Advantage)。
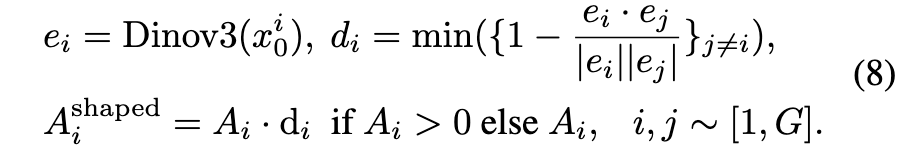
-
注意:只奖励那些既有正向优势(高质量)又具有高多样性的样本,防止模型为了多样性而生成乱七八糟的东西。
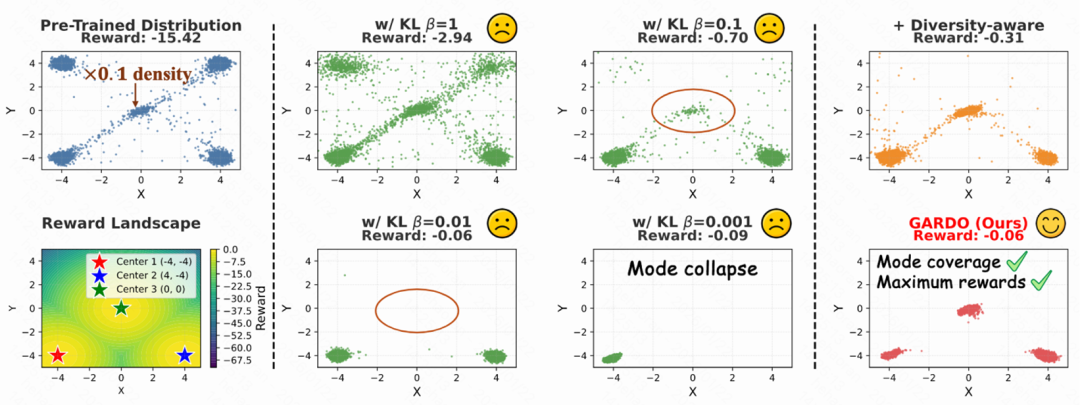
研究团队在高斯混合分布(预训练分布)上训练了一个包含三层 MLP 的扩散模型,目标是捕捉奖励景观中所示的多模态高奖励聚类。使用较大 KL 系数 β 的传统强化学习方法约束过强,无法提升奖励。与之相对,过小的 β 则会导致严重的模式坍缩。团队提出的多样性感知优化方法单独使用时,已成功捕捉到多模态聚类,包括参考策略 π_ref 中概率密度最低的中心聚类。而团队提出的完整的 GARDO 框架则能同时实现奖励最大化并发现所有高奖励聚类。
实验结果:全方位的提升
作者在 SD3.5-Medium 和 Flux.1-dev 等多个基底模型上,针对不同的奖励任务(GenEval, OCR, Aesthetic 等)和不同的 RL 算法(flow-grpo,DiffusioNFT 等)进行了广泛实验。
定量评估
相比于 Flow-GRPO 等基线方法,GARDO 展现了显著的优势:
-
拒绝 Hacking:在 OCR 等易被 Hack 的任务中,GARDO 在保持高识别率的同时,图像质量指标(如 Aesthetic, PickScore)没有下降,甚至有所提升。
-
样本效率:学习曲线显示,GARDO 能够以更少的步数达到更高的奖励水平。
-
泛化性:在未见过的测试指标上(Unseen Metrics),GARDO 表现出极强的鲁棒性。
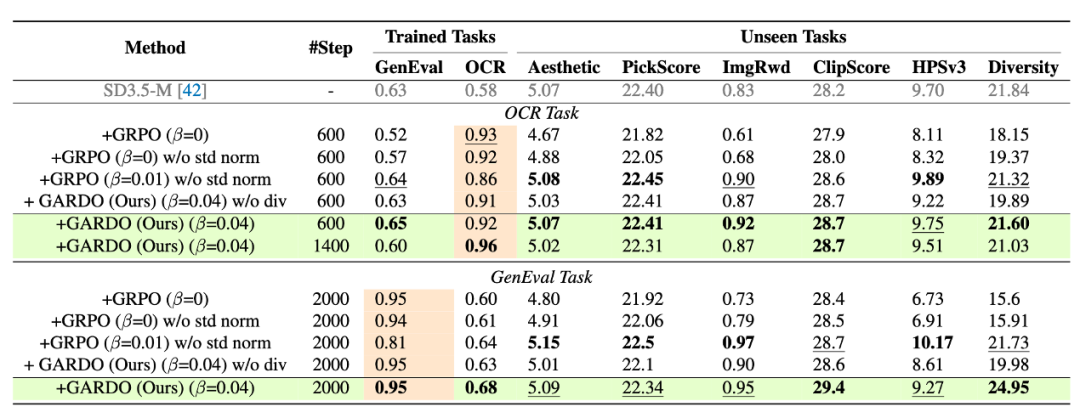
GARDO 和 baseline 在不同 metric 上的表现。训练优化代理任务黄色高亮。
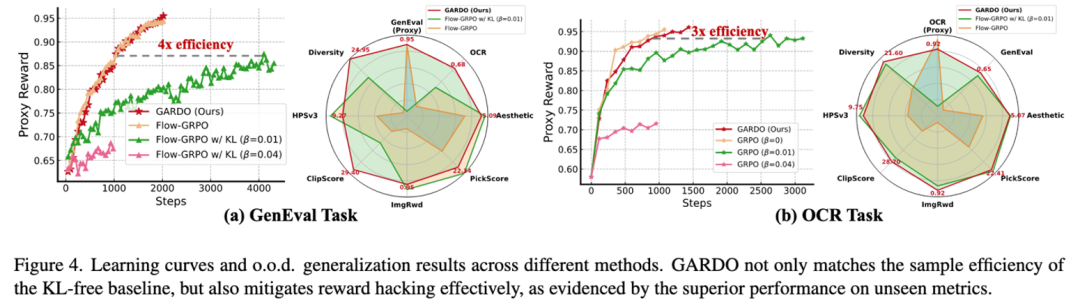
涌现能力
最令人印象深刻的是 GARDO 激发了模型的涌现能力(Emergent Behavior)。
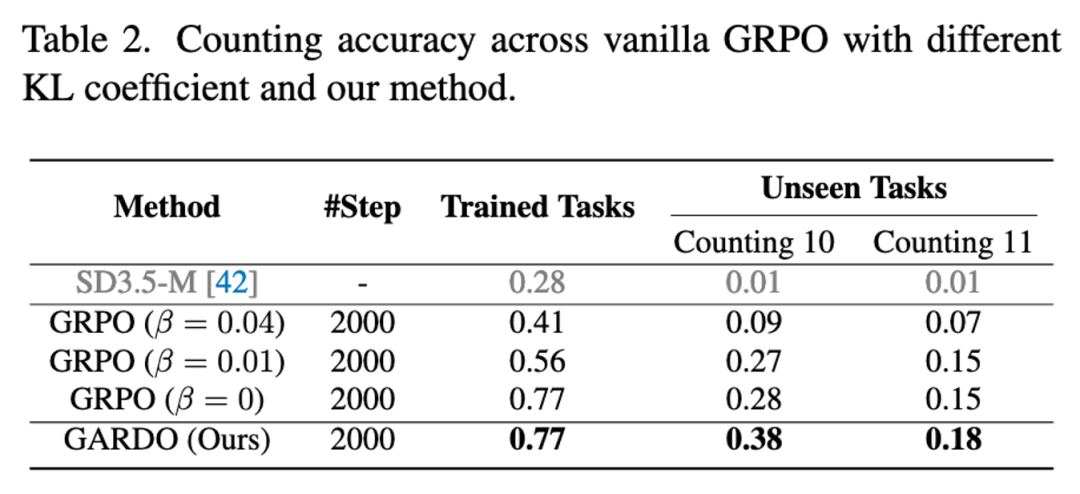
在极具挑战性的 “数数任务”(生成特定数量的物体)中,基底模型和传统 RL 方法很难生成超过 9 个物体。
而 GARDO 成功学会了生成 10 个甚至 11 个物体。
总结
GARDO 针对扩散模型 RL 后训练中的痛点,提出以下解决方案:
-
拒绝盲目正则化 →→ 门控 KL(只惩罚不可靠的)
-
拒绝静态锚点 →→ 自适应更新(不断提升上限)
-
拒绝模式坍塌 →→ 多样性感知(鼓励百花齐放)
这项工作证明了:在视觉生成的强化学习中,精准的控制比强力的约束更重要。对于希望利用 RL 进一步释放扩散模型潜力的研究者和开发者来说,GARDO 提供了一个极具价值的通用框架。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com