神经网络可重编程性:模型适配的范式转变,无需修改参数即可复用预训练模型能力。
原文标题:不止于Prompt:揭秘「神经网络可重编程性」
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中将Prompt Tuning、Model Reprogramming和In-context Learning归为同一框架下,你认为这三种方法在实际应用中,哪种更具有潜力?为什么?
3、文章提到了对抗样本的脆弱性是可重编程性的基础,那么是否存在利用可重编程性来防御对抗攻击的方法?如果存在,其原理是什么?
原文内容

从模型重编程(Model Reprogramming),到参数高效微调(PEFT),再到当下大模型时代的 Prompt Tuning ,Prompt Instruction 和 In-context Learning,研究者和从业人员不断地探索一个核心问题:在尽量不改动模型参数的前提下,如何最大化地复用预训练模型的能力?
过去几年,这类方法在不同社区中以各自独立的形式快速发展 —— 有的来自对抗鲁棒性与迁移学习,有的服务于下游任务适配,有的则成为大模型对齐与应用的基础工具。然而,这些看似分散的技术路线,背后是否存在一个更统一、更本质的理论视角?
近期,来自墨尔本大学可信赖机器学习与推理(TMLR)研究小组和 IBM AI 研究所的研究者系统性地提出了「神经网络可重编程性(Neural Network Reprogrammability)」这一统一主题,在最近的一篇 survey 中,将模型重编程,Prompt Tuning、Prompt Instruction 和 In-context Learning 纳入同一分析框架,从操纵位置、操纵类型、操纵算子和输出对齐四个维度进行了系统梳理与对比。同时,该团队也在 AAAI 2026 上带来同名 Tutorial,帮助研究者与工程实践者全面理解这一正在重塑模型使用范式的关键能力。

-
Tutorial 标题:Neural Network Reprogrammability: A Unified Framework for Parameter-Efficient Foundation Model Adaptation
-
论文标题:Neural Network Reprogrammability: A Unified Theme on Model Reprogramming, Prompt Tuning, and Prompt Instruction
-
Arxiv: https://arxiv.org/pdf/2506.04650
-
GitHub: https://zyecs.github.io/awesome-reprogrammability/tutorial-AAAI26/
1. 模型训练范式的转变
在本文中,我们认为随着预训练模型(pre-trained model)规模的增长,其适配下游任务(downstream tasks)的范式已经发生了根本性转变:从传统的基于模型参数调整的适配(图 1a)转变为了基于模型可重编程性的适配(图 1b)。
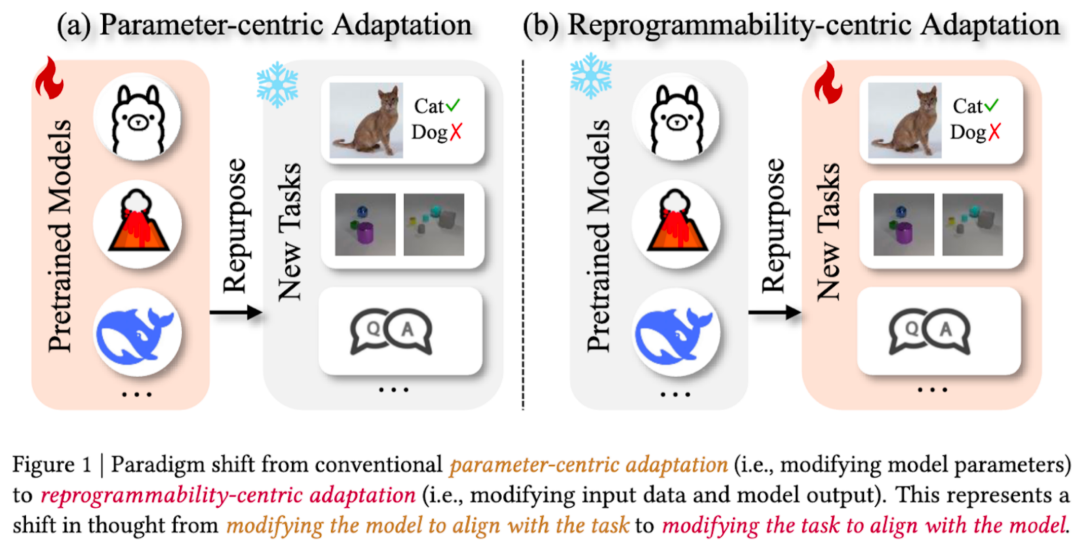
传统适配技术(parameter-centric adaptation, PCA)通过重新训练预训练模型,修改模型内部参数,使其适用于新的下游任务。例如,将 ImageNet 预训练的图像分类器应用于猫狗分类任务时,需要至少改变分类头,甚至重新训练其他层的参数,即我们通常所说的 fine-tuning,本质上改变了模型学习到的内部表征(representation),并需要为每个下游任务维护一份新的参数拷贝。
新兴适配技术(基于模型可重编程性的适配,reprogrammability-centric adaptation, RCA)则采用了一种不同的理念:保持模型参数冻结,转而策略性地修改任务呈现的方式,通过精心设计下游任务的输入变换(包括模型输入(input)、提示(prompt)或上下文信息(context)),以及模型输出对齐方式(output)来使其兼容下游任务,使用极少量可训练参数(甚至完全不引入新参数),在不触及模型权重的情况下「重编程」预训练模型的行为。
核心转变体现在理念上的转换:从「修改模型以适应任务」转向「修改任务以适应模型」,从而使我们能以最小的计算开销在不同任务中重复使用预训练模型,同时保持其原有能力。同一个冻结的模型仅通过改变与其「对话」的方式,就能处理多种不同的任务。
2. 可重编程性范式的效率优势
具体实验数据表明(图 2),相较 PCA,RCA 在参数效率上有明显优势。将 ImageNet 预训练的视觉 Transformer(ViT-B/32)适配到遥感图像分类任务(EuroSAT)。柱状图显示不同 fine-tune 策略的参数需求:从左到右分别对应 fully fine-tune 到逐步减少可训练层数的各种配置,训练参数量随之下降。但即便是最轻量的 PCA 方案仍需要大量参数。
形成对比的是,红色虚线显示 RCA 需要的训练参数始终比任何 PCA 配置少 2-3 个数量级。这些参数用于输入变换和输出对齐,而不是修改预训练模型的内部权重。
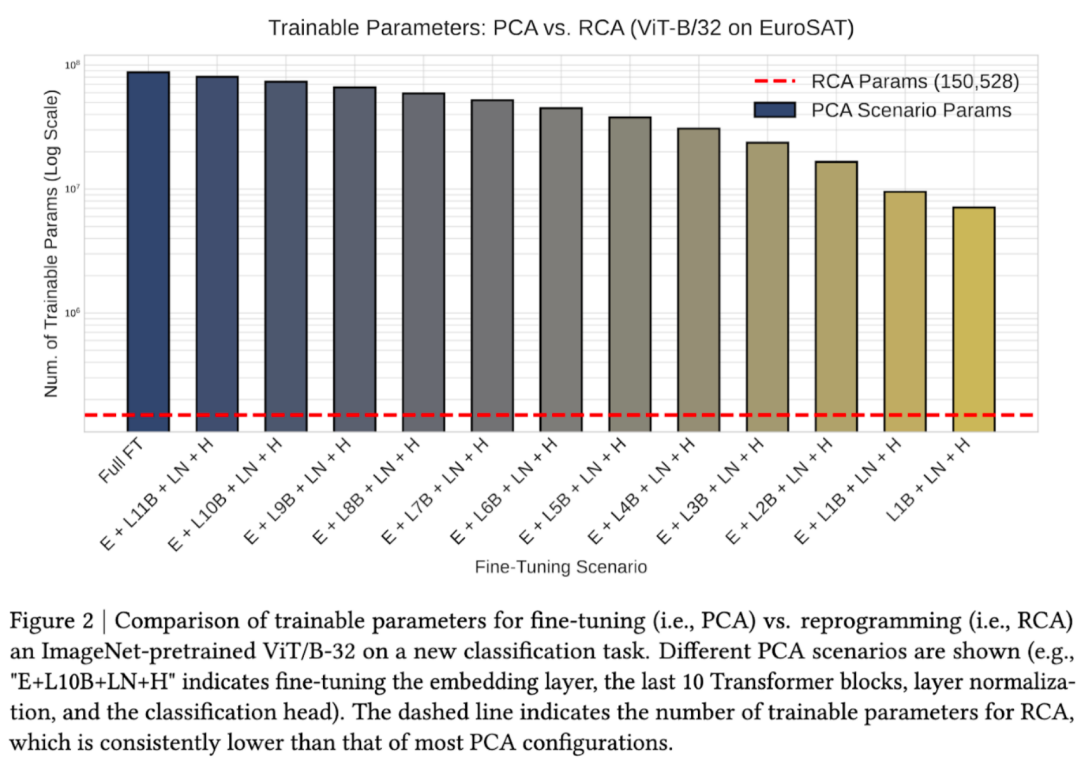
这表明,在可以实现 comparable performance 前提下,RCA 的参数效率更高,使得在资源受限环境中适配大模型成为可能,并支持同时适配多个任务而不会出现灾难性遗忘。在预训练模型规模与能力不断提升、获取方式日趋不透明(如商业模型仅提供 API 接口)的背景下,RCA 的优势愈发突出。
3. 可重编程性范式的「多种称谓」
然而,我们发现相似甚至相同的模型适配方法在不同研究社区却有着截然不同的命名:NLP 社区常称之为「prompt tuning」,而 ML 文献中研究者更倾向于使用 「model reprogramming」指代这类方法。经验上,这种术语混乱也经常引发 「哪种方法更优」、「为何不比较其他方法」等争论。
核心问题在于:prompt tuning,model reprogramming,甚至 in-context learning 真的代表不同的模型适配方法吗?答案是否定的。尽管表现形式各异,这些方法实质上都利用了神经网络的同一固有属性 -- neural network reprogrammability (神经网络可重编程性,图 3)。基于这一认识,我们提出统一框架来连接三个独立发展的研究领域,并系统性地描述和归类这些适配方法。
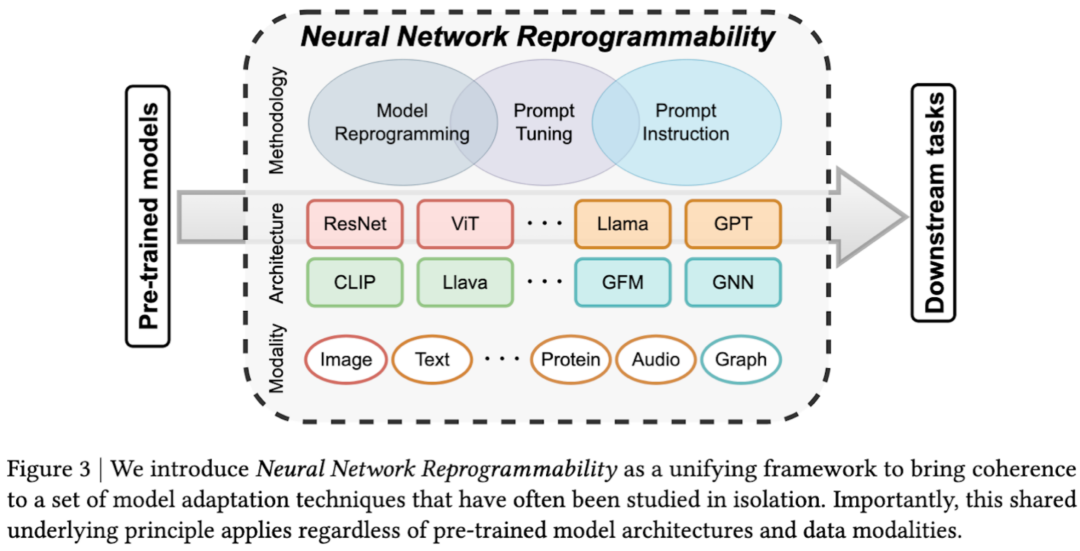
关键点 1. 可重编程性的普适性。
它具备架构无关性和模态无关性,跨越三个核心维度:适配方法,预训练模型架构(单模态类型、多模态模型、专门架构),以及数据类型(图像、文本、音频、图结构等) -- 无论具体实现细节如何,围绕模型接口的信息操作(information manipulation at model’s interfaces)这一共同的底层原理,我们都能将任意预训练模型适配到任意下游任务。
4. 可重编程性范式的首次提出(ICLR 2019)
那么什么是 reprogrammability 呢?下面这张图片展示了从神经网络对于对抗样本的脆弱性(sensitivity to adversarial examples)向可重编程性(reprogrammability)的演进。图片来自文章《Adversarial reprogramming of neural networks》由 G. F. Elsayed, I. Goodfellow, and J. Sohl-Dickstein. 发表于 ICLR 2019.

左侧(传统对抗样本 adversarial example):展示了经典对抗攻击,在熊猫图像上添加不可察觉的噪声,就能使 ImageNet 分类器将其错分为长臂猿,置信度高达 99.3%,尽管图像在人眼看来没有变化。
右侧(对抗重编程 adversarial reprogramming):展示了如何将这种脆弱性转化为建设性用途。我们不仅欺骗模型,同时将其「重编程」以执行完全不同的任务:
-
(a)展示了一个黑白格图像的计数任务,我们可以人为将不同的动物类别映射到方块数量类别(1-10 个方块)
-
(b)展示了「对抗程序」(adversarial program) -- 精心设计的噪声,充当指导模型行为的指令(可以理解为 prompt)
-
(c)将(a)和(b)结合后,仅在 object recognition 任务上预训练的 ImageNet 分类器被「重编程」以执行方格计数任务,可以输出「4 个方格」的预测结果(从源域的「虎鲨」类映射得到)
关键点 2. 巧妙利用神经网络的敏感性。
由对抗样本发现的神经网络敏感性(理论背景包括决策边界的不连续性等),正是可重编程性的基础。我们不再将这种敏感性仅视为安全缺陷,而是建设性地利用它,在不重新训练的情况下将预训练模型重定向到新的任务。精心设计的 program/prompt 可以将神经网络感知的弱点转化为高效的适配机制。

5. 可重编程性范式的数学表达
如上,我们给出 neural network reprogrammability 统一框架的定义,涵盖了文章中讨论的各类模型适配方法。定义如下:
给定源域(source domain)上预训练的模型,该模型从源域输入空间映射到源域输出空间。神经网络可重编程性使这个固定模型(参数不再改变)能够通过两个可配置的变换在完全不同的目标域(target domain)实现由该域输入 / 输出空间定义的目标任务:
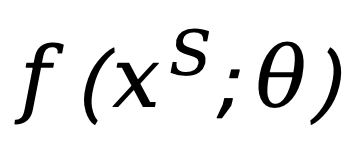
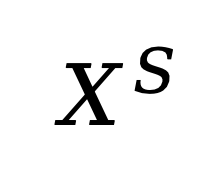
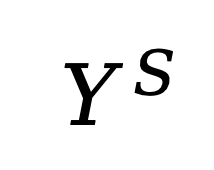
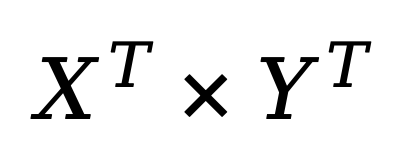
-
输入操作(input manipulation)该变换将目标任务的输入转换为预训练模型可处理的格式,这可能是通过添加可学习的 prompt、拼接 demonstration examples 或应用 adversarial perturbation 到目标样本上。
-
输出对齐(output alignment)该变换将预训练模型的源域预测映射到目标任务的输出格式。这可能涉及到 label mapping, structured parsing 或 linear projection 等。
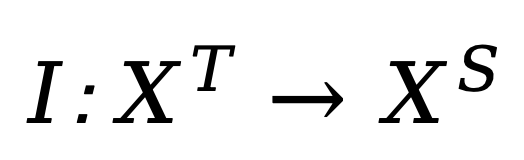
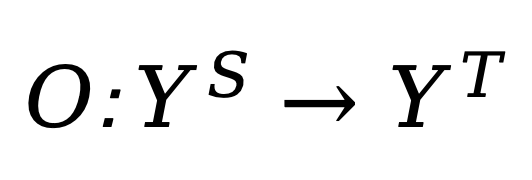
将这两个变换与预训练模型结合,我们得到重编程后的预训练模型。这个看似简单的复合函数可以描述上述模型适配技术的本质,这些看似不同的方法实际上只是同一基本原理的不同实例。
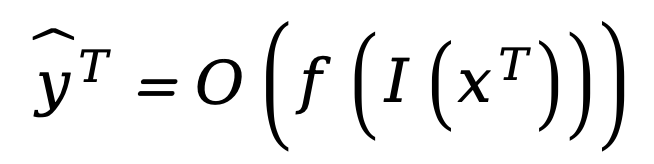
6. 可重编程性范式的具体案例
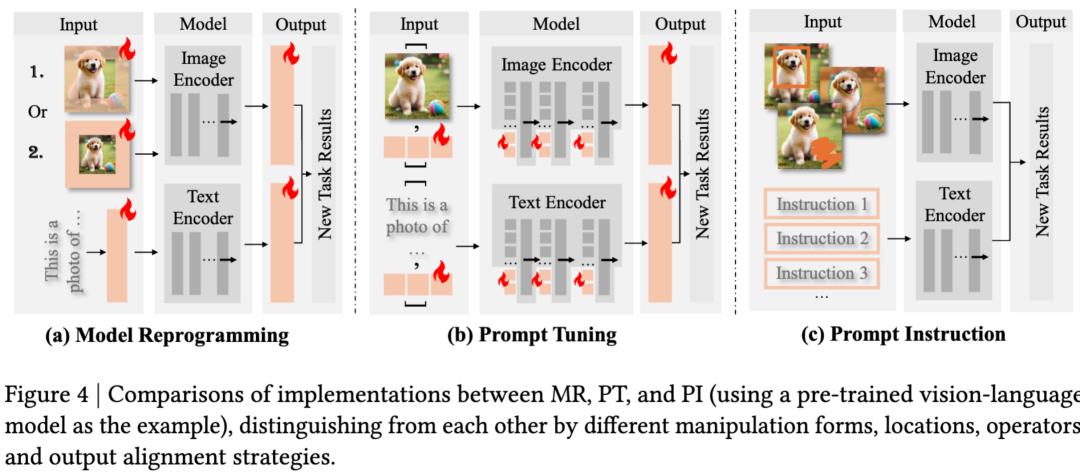
以视觉 - 语言模型(Vision-Language Model)为例,说明三种可重编程方法在实现上的差异(如图 4 所示)。
-
(4a) model reprogramming (MR):主要在模型原始输入层操作。可学习的扰动直接添加到输入图像上。模型通过图像和文本编码器处理这些修改后的输入,需要输出对齐将模型的原始预测映射到新的目标任务。这种方法适用于可访问模型的输入和输出,但对内部模型组件控制有限的情况。
-
(4b) prompt tuning (PT):主要在中间表示层操作。可学习的 tokens 或嵌入(embedding)被插入到模型的内部层(包括图像编码器和文本编码器)。这些「软提示」可以在嵌入层(embedding layer)或隐藏层(hidden layers)进行前置或插值,在保持核心参数冻结的同时允许对模型内部处理进行更直接的控制。
-
(4c) prompt instruction (PI):通过上下文演示(contextual demonstration)操作。该方法不使用可学习参数,而是提供多个示例图像和明确的文本指令来引导模型行为。模型从提供的演示中「上下文」学习任务,无需任何参数更新。该方法的有效性主要在 LLMs 和 large vision-language model/multi-modal LLMs 上可观察到。
-
操作位置:输入空间 (MR) → 嵌入 / 隐藏空间 (PT) → 输入空间 (PI)
-
参数需求:可学习扰动 (MR) → 可学习 tokens(PT) → 无新参数 (PI)
-
访问要求:输入访问 (MR) → 白盒访问 (PT) → API 级访问 (PI)
本质上,三种方法都实现了相同目标 -- 将冻结模型重新用于新任务 -- 通过计算图中的不同路径实现。
Neural network reprogrammability 如何在不同模态和任务中具体实现呢?
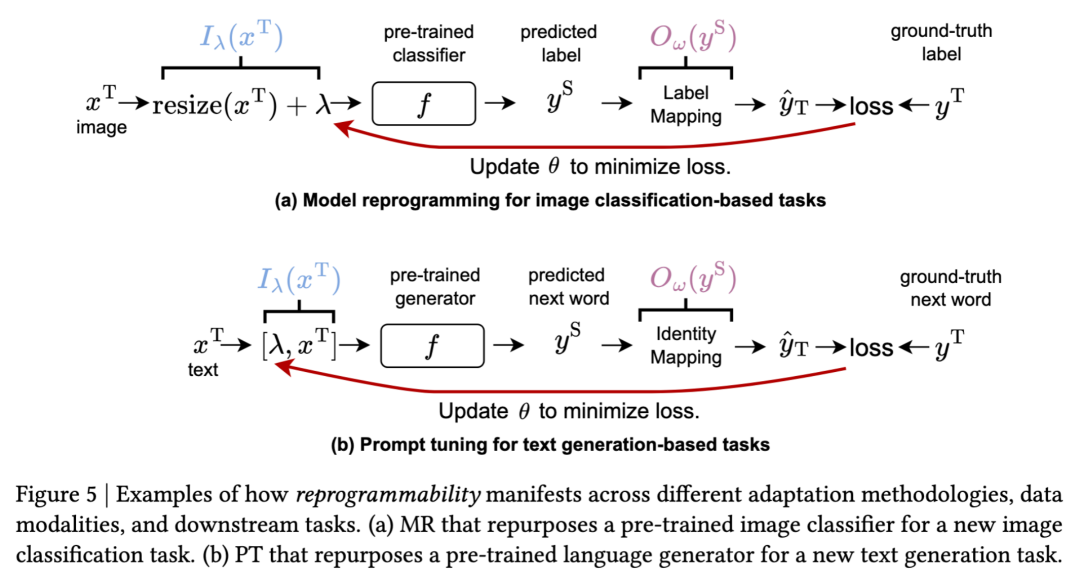
(a) model reprogramming for 图像分类任务(图 5a):
-
输入操纵:目标图像经过调整大小并与可学习扰动模式 λ 结合。这将目标任务输入转换为预训练分类器可处理的格式。
-
预训练模型:冻结的图像分类器 (如 ResNet, ViT) 处理操纵后的输入。
-
输出对齐:将分类器的原始类别预测转换到目标任务的标签空间(不同类别,可能不同数量的类别)。即实现了 Label Mapping 步骤,不需要额外的训练参数。
-
训练:仅通过反向传播优化扰动参数 λ,模型权重保持冻结。
(b) prompt tuning for 文本生成任务(图 5b):
-
输入操纵:可学习的 prompt tokens λ 通过拼接操作前置到目标文本输入。
-
预训练模型:冻结的 language generator(如 GPT)处理提示增强的输入。
-
输出对齐:因为模型已经在目标文本空间输出,无需额外转换。
-
训练:仅优化提示参数 λ,保持生成器完全冻结。
关键点 3. 数学框架下的一致性。
尽管操纵不同模态(视觉 vs 语言)、任务类型(分类 vs 生成)并使用不同的输入操纵策略(加性扰动 vs 连接提示),两种方法都遵循完全相同的数学框架。
7. 基于可重编程性范式,归纳现有方法
基于这个特性,我们进一步提出了一个分类法(taxonomy),将过往的研究工作组织为跨四个维度的连贯结构,并展示了 neural network reprogrammability 这一框架的泛用性。
-
操纵位置:定义输入操纵发生在预训练模型的哪个接口,包括原始输入空间(input space),嵌入空间(embedding space),以及隐藏空间(hidden space)
-
操纵类型:定义输入操纵的类型,分为可优化(learnable)和固定(fixed)
-
操纵算子:定义输入操纵如何被应用到目标数据(target input)上,包括加性(additive)、拼接(concatenative)、参数化(parametric)算子
-
输出对齐:定义是否模型输出需要进行额外操作以对齐目标任务(target output),包括恒等映射 (identity mapping)、结构变换(structural alignment)、统计变换(statistical alignment)、线性变换(linear alignment)
对应地,MR,PT 和 PI 对应的研究方法可以被系统归类,如表格 2 所示。
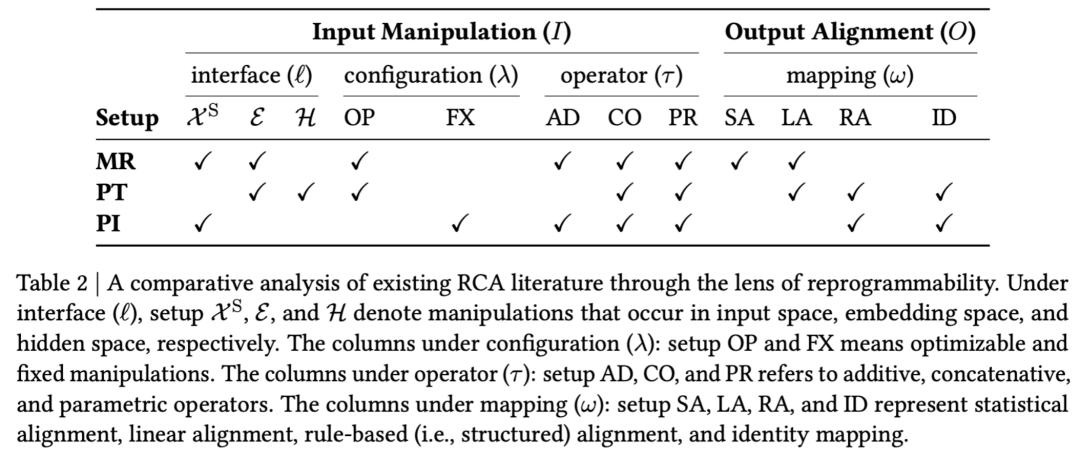
8. 如何用可重编程性范式来理解 In-context learning 和 Chain-of-Thought Reasoning
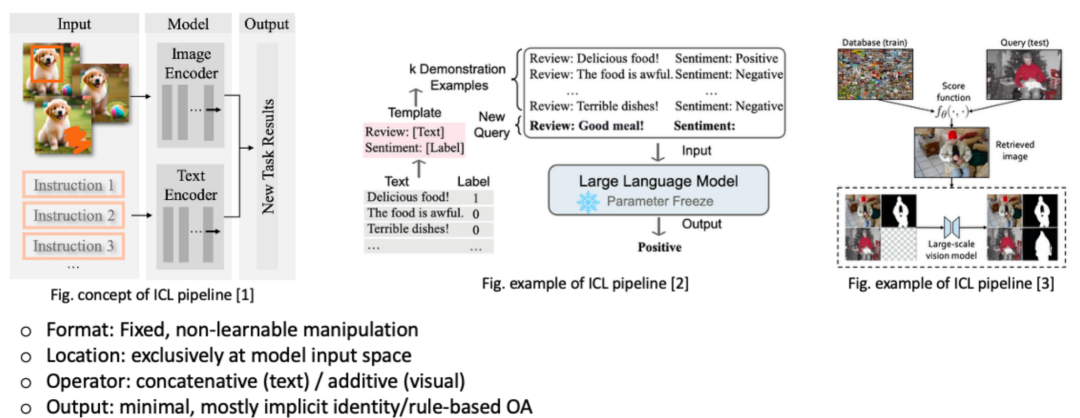
特别地,LLM 的上下文学习 in-context learning (ICL) 在该框架下可以描述为
-
固定输入操纵:无训练参数,依赖人为设计的 demonstration examples
-
原始输入空间操纵:demonstration example 直接与模型的 text query 拼接
-
拼接操纵算子:demonstration example 通过拼接操作
-
隐式输出对齐:无需额外显式映射,预训练模型直接生成目标输出或依靠模型自身能力对输出进行基于规则的格式、结构调整(见下图示例,ChatGPT 可以直接对模型输出的 natural language 进行格式限制,e.g., bullet list, LaTeX)

因此,模型通过这些示例在「上下文」中学习目标任务的模式,且无需任何参数更新。Demonstration examples 本质上是一种输入操纵,通过策略性构造输入,从而重编程模型行为。
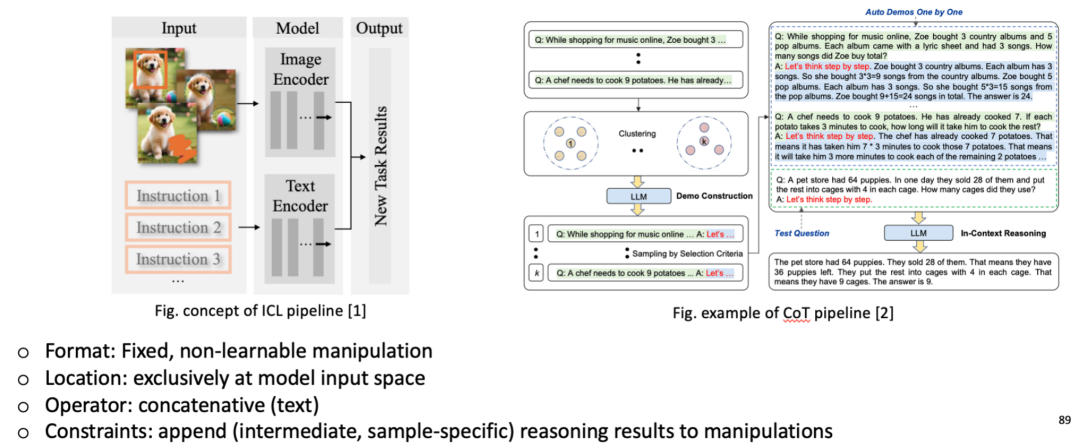
对应地,思维链推理(Chain-of-Thought Reasoning)可被认为是一种通过融入结构化、与输入样本特定相关的(sample-specific)「推理形式」的输入操纵。
-
输入操纵:具备增强的上下文信息,不仅包含输入 - 输出对,还包含明确的中间推理步骤。例如,解决数学问题时,CoT 会包含「问题 -> 第一步计算 -> 第二步计算 ->…-> 最终步骤」的完整推理过程。另外,每个目标输入 query 都会触发模型生成与该具体 query 匹配的推理链。比如解决「23×47=?」时,模型会生成针对这两个具体数字的逐步计算过程,而不仅是通用的乘法公式。
-
输出对齐:由于模型输出完整的推理序列(「首先计算 23×40=920,然后计算 23×7=161,最后 920+161=1081」),因此需要结构化、基于规则的解析机制(structural alignment)从这个推理文本中提取最终数值答案。
9. 资源分享:Awesome Neural Network Reprogrammability 资源库
为了方便社区追踪这一飞速发展的领域的最新进展,我们维护了一个 Awesome 风格的资源库,收录并持续更新 Neural Network Reprogrammability 领域的最新论文和代码实现。希望这个资源库能让你少走弯路!
-
GitHub: https://zyecs.github.io/awesome-reprogrammability/
如果你正在做相关方向,欢迎在 GitHub 上 star 支持,或者来仓库一起补全与更新!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com