避免Agent Skills“裸奔”,构建确定性与灵活性共存的企业级混合架构,保障系统稳定与安全。
原文标题:Agent Skills 落地实战:拒绝“裸奔”,构建确定性与灵活性共存的混合架构
原文作者:AI前线
冷月清谈:
怜星夜思:
2、文章强调 Java 在数据流转和安全检查中的作用,那么在 Serverless 架构下,如何发挥 Java 的这些优势?
3、文章中提到对LLM输出做二次安检,感觉很有必要,但是这会不会影响Agent的效率和灵活性?有什么好的优化方案吗?
原文内容

在我们的“文档处理 Agent”项目中,基础的问答功能(RAG)已经解决得很好。但随着用户需求升级,我们面临了新的挑战:
用户场景:
“这是 2024 和 2025 年的两份经营数据报表,请对比 DAU 和营收的同比增长率,并生成一个 Excel 表格给我。另外,把总结报告导出为 PDF。”
这类需求包含两个特征:
-
逻辑计算:需要精确算术(LLM 弱项)。
-
文件 IO:需要生成物理文件(LLM 无法直接做到)。
引入 Skills(让 LLM 调用 Python 代码)似乎是唯一解。但在具体落地时,我们走了一段弯路。
起初,我们参考了开源社区做法,采用了 完全的 Code Interpreter 模式。我们将 requests、pandas、reportlab 等库的权限全部开放给 LLM,并在 Prompt 中告诉它:“你是一个 Python 专家,请自己写代码解决所有问题。”
这种“裸奔”模式在生产环境中遭遇了三次暴击:
-
输入端不可控:LLM 对非结构化数据(如无后缀 URL、加密 PDF)的处理极其脆弱,经常陷入报错死循环。
-
输出端崩坏:让 LLM 从零绘制 PDF/Word 是灾难。经常出现中文乱码、表格对不齐、使用了过期的库 API 等问题。
-
安全黑洞:数据流完全在沙箱内闭环,Java 主程序失去了对内容的控制权,无法拦截敏感词或违规数据。
变革:Java 主控 +
DSL Skills 的混合架构
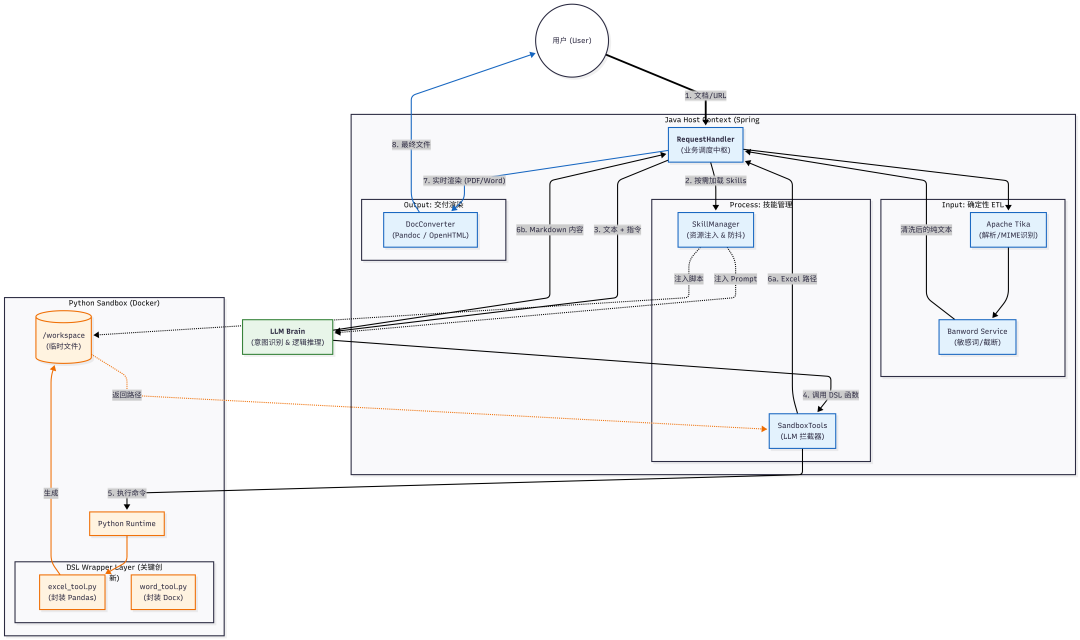
为了解决上述问题,我们重构了架构。核心思想是:收回 LLM 的“底层操作权”,只保留其“逻辑调度权”。
我们制定了新的架构分工:Java 负责确定性的数据流转与安检,LLM 负责意图理解与代码组装,Python 沙箱 负责在受控环境下执行具体计算。
我们将系统重新划分为四个逻辑层级:
-
ETL 层 (Java):负责下载、MIME 识别、OCR、敏感词检测。这是“确定性管道”。
-
Brain 层 (LLM):负责阅读纯文本,进行逻辑推理,并生成调用代码。
-
Skills 层 (Python Sandbox):提供高度封装的 SDK(DSL),而非裸库。
-
Delivery 层 (Java):负责将 Markdown/HTML 实时渲染为 PDF/Word。
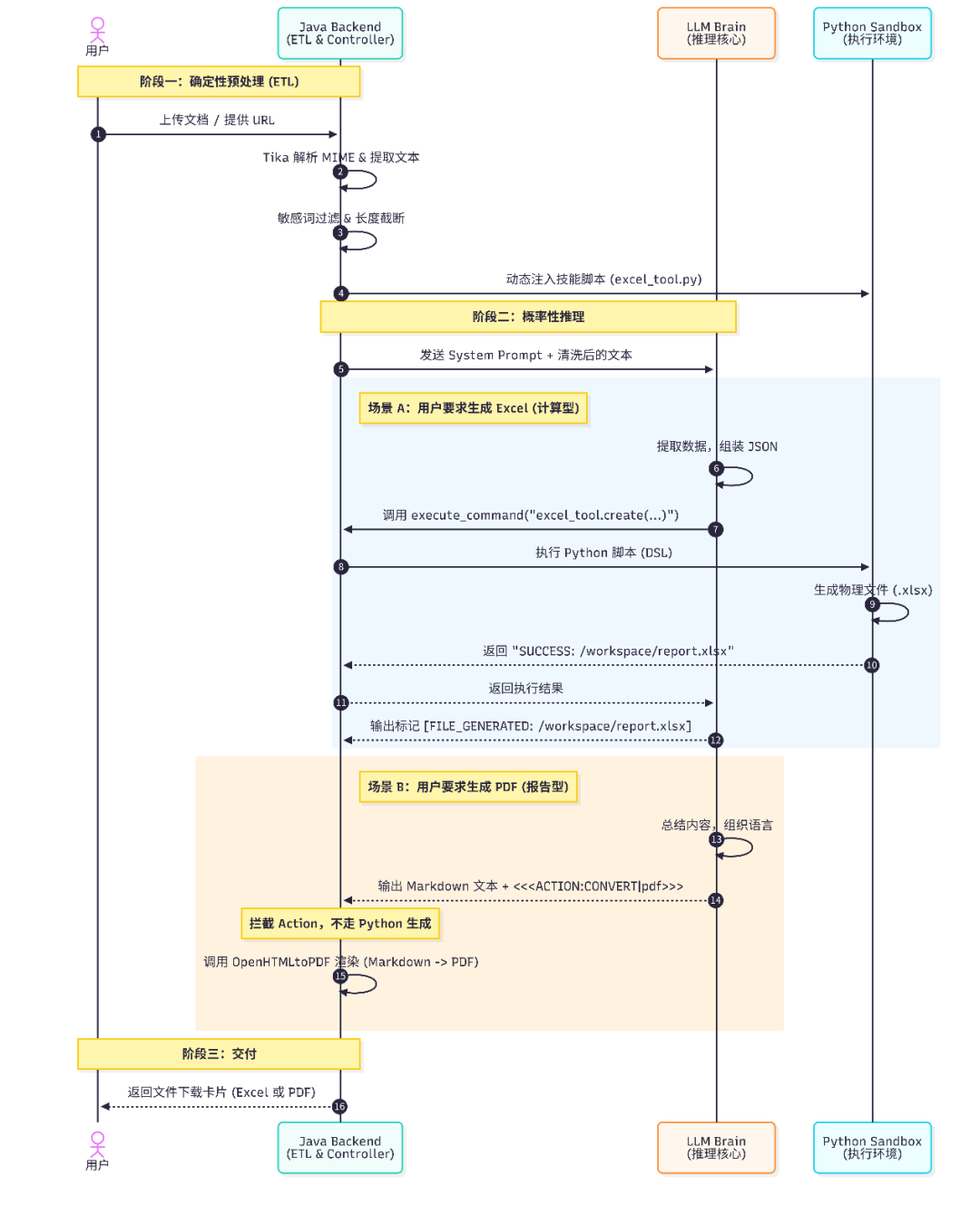
我们不再让 LLM 去下载和解析文件。所有输入文件,先经过 Java 的 DocPipeline。利用 Apache Tika 进行精准解析,并立即进行 敏感词检测 和 文本截断。这一步保证了 喂给 LLM 的数据是干净、安全、标准化的纯文本。
这是我们对 Skills 实践最大的改进。我们 禁止 LLM 直接写 import pandas 进行底层操作,而是预置了一套高度封装的 DSL。
Python 端封装 (excel_tool.py):
import pandas as pd
import os
def create_excel(data_list, filename="report.xlsx", output_dir="/workspace"):
try:
df = pd.DataFrame(data_list)
save_path = os.path.join(output_dir, filename)
# <span class="specialTitle">【封装价值体现】</span>自动处理格式、列宽、引擎兼容性,屏蔽 LLM 的幻觉风险
with pd.ExcelWriter(save_path, engine='openpyxl') as writer:
df.to_excel(writer, index=False, sheet_name='Sheet1')
# 自动调整列宽 (LLM 很难写对的工程细节)
worksheet = writer.sheets['Sheet1']
for idx, col in enumerate(df.columns):
max_len = max(df[col].astype(str).map(len).max(), len(str(col))) + 2
worksheet.column_dimensions[chr(65 + idx)].width = min(max_len, 50)
return save_path
except Exception as e:
return f"Error: {str(e)}"
Skill 说明书 (SKILL.md):
我们在 Prompt 中通过“接口契约”强行约束 LLM 的行为,明确了何时该写代码,何时该纯输出文本。
# File Generation Skill (Standardized)
你拥有生成专业格式文件(Excel, Word, PDF)的能力。
沙箱中已预装了封装好的 `excel_tool` 库。
**核心决策树**:
1. 如果是 **统计数据/表格** -> 必须生成 **Excel** -> **写 Python 代码**。
2. 如果是 **分析报告/文档** -> 必须生成 **Word/PDF** -> **禁止写代码**,走渲染路径。
---
### 场景 1:生成 Excel (.xlsx)
**规则**:禁止使用 `pandas` 底层 API,必须调用封装函数。
**数据结构**:必须是【字典列表】,每个字典代表一行。
**Python 调用示例**:
```python
import excel_tool
# 1. 准备数据 (从文档中提取)
data = [
{'年份': '2024', 'DAU': 1000, '营收': '500万'},
{'年份': '2025', 'DAU': 1500, '营收': '800万'}
]
# 2. 调用封装函数 (自动处理样式、列宽)
excel_tool.create_excel(data, filename='analysis.xlsx')
```
---
### 场景 2:生成 Word / PDF (.docx / .pdf)
**规则**:**严禁编写 Python 代码**(如 `reportlab` 或 `python-docx`)。
**执行动作**:
1. 请直接输出内容丰富、排版精美的 **Markdown** 文本。
2. 在 Markdown 的**最后一行**,务必添加对应的动作标签,系统会自动将其渲染为文件。
**输出示例**:
# 2024 年度经营分析报告
## 一、 数据概览
本季度营收同比增长 20%...
| 指标 | Q1 | Q2 |
| :--- | :--- | :--- |
| DAU | 100w | 120w |
... (此处省略 2000 字内容) ...
<<<ACTION:CONVERT|pdf>>>
# File Generation Skill (Standardized)
你拥有生成专业格式文件(Excel, Word, PDF)的能力。
沙箱中已预装了封装好的 `excel_tool` 库。
** 核心决策树 **:
1. 如果是 ** 统计数据 / 表格 ** -> 必须生成 **Excel** -> ** 写 Python 代码 **。
2. 如果是 ** 分析报告 / 文档 ** -> 必须生成 **Word/PDF** -> ** 禁止写代码 **,走渲染路径。
#### 场景 1:生成 Excel (.xlsx)
** 规则 **:禁止使用 `pandas` 底层 API,必须调用封装函数。
** 数据结构 **:必须是<span class="specialTitle">【字典列表】</span>,每个字典代表一行。
**Python 调用示例 **:
```python
import excel_tool
# 1. 准备数据 (从文档中提取)
data = [
{'年份': '2024', 'DAU': 1000, '营收': '500 万'},
{'年份': '2025', 'DAU': 1500, '营收': '800 万'}
]
# 2. 调用封装函数 (自动处理样式、列宽)
excel_tool.create_excel(data, filename='analysis.xlsx')
对于不同类型的文件,我们采取了截然不同的交付策略:
-
Excel(强结构化):走 Skills 路线。LLM 组装数据 -> 调用
excel_tool-> 沙箱生成物理文件。 -
Word/PDF(富文本):走 渲染路线。严禁 LLM 写代码生成。
-
LLM 只输出高质量的 Markdown 并在末尾打上
<<<ACTION:CONVERT|pdf>>>标签。 -
Java 后端拦截该标签,利用
OpenHTMLtoPDF或Pandoc将 Markdown 实时转换 为精美的 PDF/Word。
以下是我们在 Spring AI 体系下实现这套混合架构的关键逻辑。
我们实现了一个 SkillManager,支持按需加载技能。为了提升性能,我们设计了 Session 级的“防抖机制”,确保同一个会话中只需上传一次 Python 脚本,避免重复 IO。
@Service public class SkillManager { // 缓存技能脚本: 技能名 -> { 文件路径 -> 内容 } private final Map<String, Map<String, String>> skillScripts = new ConcurrentHashMap<>(); // 防止重复注入的防抖 Set private final Set<String> injectedSessions = ConcurrentHashMap.newKeySet(); /** * 核心逻辑:根据需要的技能列表,动态注入脚本到沙箱 */ public void injectToSandbox(String sessionId, List<String> neededSkills) { // 1. 防抖检查:如果该 Session 已注入,直接跳过,避免重复 IO if (injectedSessions.contains(sessionId)) return; // 2. 注入 Python 包结构 (__init__.py) sandboxService.uploadFile(sessionId, "/workspace/skills/__init__.py", ""); // 3. 批量上传该技能所需的 DSL 脚本 for (String skillName : neededSkills) { Map<String, String> scripts = skillScripts.get(skillName); if (scripts != null) { scripts.forEach((path, content) -> sandboxService.uploadFile(sessionId, path, content) ); } } injectedSessions.add(sessionId); }
// … 省略加载 Resource 的代码 …
}
串联 Java ETL、LLM 推理和最终的交付分流。
@Service public class DocumentAnalysisRequestHandler { public Flowable<Response> processStreamingRequest(Request req) { // 1. 【Java ETL】确定性解析与安检 // 无论 URL 还是文件,先转为纯文本,并做敏感词过滤 List<ParseResult> parsedDocs = etlPipeline.process(req.getUrls());// 2. 【技能注入】
List<String> neededSkills = List.of(“file_generation”);
skillManager.injectToSandbox(req.getSessionId(), neededSkills);
// 3. 【LLM 执行】Context Stuffing
String prompt = buildPrompt(parsedDocs, skillManager.getPrompts(neededSkills));
// 调用 LLM,挂载 ToolContext 以实现多租户隔离
Flowable<AgentOutput> agentFlow = chatClient.prompt()
.system(prompt)
.user(req.getUserInstruction())
.toolContext(Map.of(“projectId”, req.getSessionId()))
.stream()
.content();
// 4. 【结果分流】
return agentFlow
.toList() // 收集完整回复
.flatMap(this::handlePostGenerationAction);
}
/**
* 核心分流逻辑:决定是返回沙箱文件(Excel) 还是 调用Java渲染(PDF)
*/
private Single<AgentOutput> handlePostGenerationAction(List<String> rawChunks) {
String text = String.join(“”, rawChunks);
// 分支 A:检测到 Python 生成了 Excel (Skills 产物)
// 格式:[FILE_GENERATED: /workspace/report.xlsx]
if (FILE_GENERATED_PATTERN.matcher(text).find()) {
String path = extractPath(text);
return Single.just(new AgentOutput(path, OutputType.FILE));
}
// 分支 B:检测到转换指令 (渲染产物)
// 格式:<<<ACTION:CONVERT|pdf>>>
if (text.contains(“<<<ACTION:CONVERT|pdf>>>”)) {
// Java 侧实时渲染:Markdown -> PDF
// 优势:完美控制字体和样式,避免 Python 生成乱码
String pdfPath = docConverterService.convertAndSave(text, “pdf”);
return Single.just(new AgentOutput(pdfPath, OutputType.FILE));
}
// 分支 C:普通文本
return Single.just(new AgentOutput(text, OutputType.TEXT));
}
}
在 Tool 执行层做最后一道防线:输出内容的二次安检。
@Component
public class SandboxTools {
@Tool(name = "execute_command", description = "在沙箱中执行 Shell 命令")
public String executeCommand(ExecuteCommandRequest req, ToolContext context) {
String projectId = (String) context.getContext().get("projectId");
try {
// 1. 执行 Python 脚本
Map<String, Object> result = sandboxMcpService.executeCommand(projectId, req.command());
String stdout = (String) result.get("stdout");
// 2. <span class="specialTitle">【关键】</span>输出侧安检
// 防止 LLM 通过代码计算出违规内容,绕过输入侧检查
if (banwordService.hasBanWords(stdout)) {
log.warn("Banword detected in sandbox output!");
throw new BanwordException("敏感内容阻断");
}
// 3. 超长截断 (防止 LLM 上下文爆炸)
if (stdout.length() > MAX_TEXT_LENGTH) {
return stdout.substring(0, MAX_TEXT_LENGTH) + "\n[SYSTEM: TRUNCATED]";
}
return stdout;
} catch (Exception e) {
return "Execution Error: " + e.getMessage();
}
}
}
Skills 技术让 LLM 拥有了“手”,但这双手必须戴上“手套”。
通过这次架构演进,我们得出的核心经验是:
-
不要高估 LLM 的 Coding 能力:它是一个优秀的逻辑推理引擎,但在工程细节(排版、库依赖、环境配置)上非常糟糕。DSL 封装是必须的。
-
不要丢掉 Java 的确定性:解析、下载、格式转换、安全检查,这些传统代码擅长的领域,不要交给概率性的 LLM 去做。
-
架构分层:
-
Input: Java (Standardization & Security)
-
Thinking: LLM (Reasoning)
-
Action: Python (Calculation via DSL)
-
Output: Java (Rendering & Delivery)
这种混合架构,既保留了 Agent 处理复杂动态需求的能力(如自定义计算涨跌幅),又守住了企业级应用对稳定性与合规性的底线。
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!

