RoT框架将文本推理“渲染”为图像,压缩推理过程,加速推理,并使隐式推理过程可分析。
原文标题:思维链太长拖慢推理?把它「画」进隐空间!新框架RoT探索大模型隐空间推理新范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到,RoT在推理过程中探索了两种终止策略:基于Special Token的动态终止策略和固定Token预算的静态终止策略。为什么动态终止策略的性能低于静态终止策略?
3、RoT框架利用视觉信息的高密度特性来压缩推理过程,这是否意味着它更适合处理那些本身就包含丰富视觉信息的任务?对于纯文本推理任务,RoT还有优势吗?
原文内容

在 LLM 时代,思维链( CoT)已成为解锁模型复杂推理能力的关键钥匙。然而,CoT 的冗长问题一直困扰着研究者——中间推理步骤和解码操作带来了巨大的计算开销和显存占用,严重制约了模型的推理效率。
为了解决这个问题,研究界近期尝试了「隐式 CoT」(Implicit CoT),即让模型在内部隐状态中完成推理,而不输出具体的文本。这种方法虽然快,但却是个「黑盒」:我们无法知道模型到底想了什么,也难以进行监督。
有什么方案既保证推理速度快,又使得过程可分析,还无需昂贵的预训练?
针对这一挑战,腾讯内容服务部 BAC 联合清华大学与北京大学,提出了一种名为 Render-of-Thought (RoT) 的新框架。RoT 的核心思想非常巧妙:利用多模态模型(VLM)已有的视觉编码器作为「语义锚点」,将文本推理步骤「渲染」为图像的视觉嵌入(Visual Embeddings)。
这种方法不仅将推理过程压缩到了致密的视觉潜空间中,还通过视觉渲染让隐式推理过程变得可分析且可追踪。

-
论文标题:Render-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning
-
论文地址:https://arxiv.org/abs/2601.14750
-
Github 地址: https://github.com/TencentBAC/RoT
-
Huggingface地址:https://huggingface.co/collections/TencentBAC/rot
显式太慢,隐式太黑盒?
RoT 走出第三条路
显式 CoT (Explicit CoT): 让模型把每一步推理都写出来,就像学生做数学题写步骤一样。生成几百个 Token 的中间步骤不仅费时,还极其消耗显存。
隐式 CoT (Implicit CoT): 模型直接在内部隐状态中进行推理,不输出具体文本。这种方式就像把思考过程扔进了一个「黑箱」,缺乏中间过程的监督。
Render-of-Thought (RoT): 另辟蹊径,把「思考」变成了「作画」。利用视觉信息的高密度特性,将冗长的文本压缩成紧凑的视觉向量。这不仅有迹可循,还大幅提升了推理速度。

拒绝「黑盒」:
让隐式推理「看得见、摸得着」
RoT 是一种将文本思维链通过光学渲染(Optical Rendering)和视觉知识蒸馏转化为紧凑视觉表征的新范式。
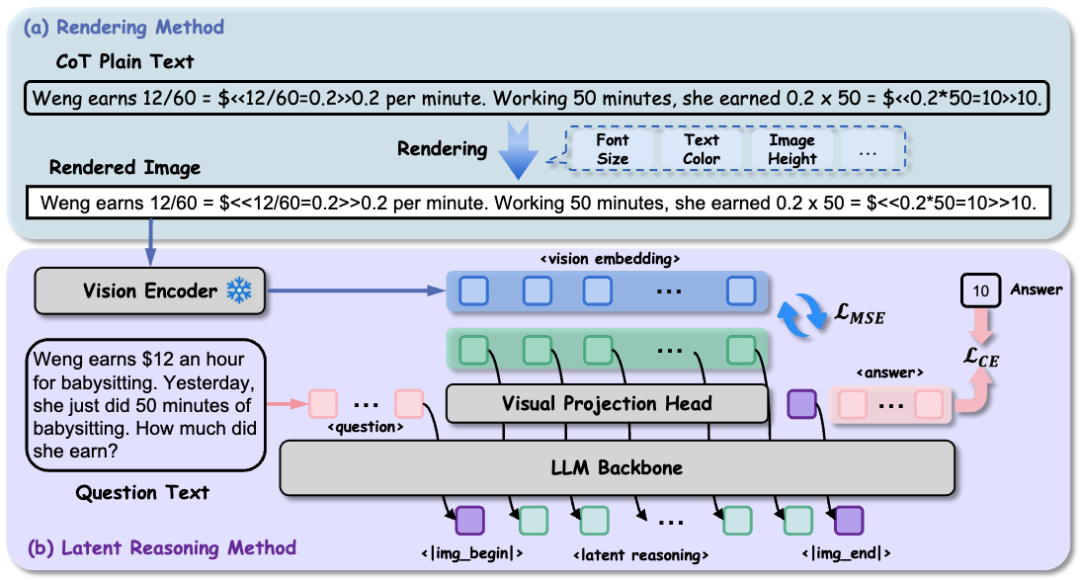
与以往需要从头学习「推理 Token」的隐式方法不同,RoT 直接利用了现有 VLM(如 Qwen-VL, LLaVA)中冻结的视觉编码器。通过将 LLM 的隐状态与渲染文本的视觉嵌入对齐,RoT 实现了即插即用(Plug-and-Play),无需额外的预训练开销。渲染方案将文本推理步骤转化为单行图像,隐空间推理方法通过投影头将 LLM 生成的隐状态与视觉特征对齐。
为了适应自回归思维链的序列化建模,研究团队摒弃了固定尺寸的图像渲染方案,采用了单行图像渲染。该策略可以根据文本长度动态修改所需的图像宽度。此外,单行的渲染方式确保图像的 Patch 严格按照从左到右的方式提取,自然地将视觉序列与文本顺序对齐。
移花接木的艺术:
两步训练实现「降维打击」
RoT 的实现过程主要分为两个阶段,旨在逐步将 LLM 的离散推理能力转化为连续的视觉隐空间推理能力。
阶段一:视觉对齐 (Visual Alignment)
这一阶段冻结了 LLM 和视觉编码器,仅训练一个轻量级的「视觉投影头」(Visual Projection Head)。目标是将 LLM 的文本隐状态映射到由视觉编码器提取的「渲染 CoT 图像」的特征空间上。
在推理步骤 t 时,生成的 latent embedding 可以记为,target vision embedding 记为 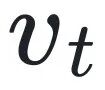 。此时 vision embedding 的对齐损失可以记为:
。此时 vision embedding 的对齐损失可以记为:
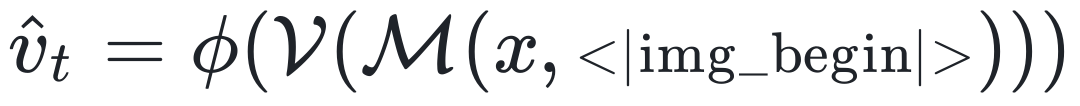
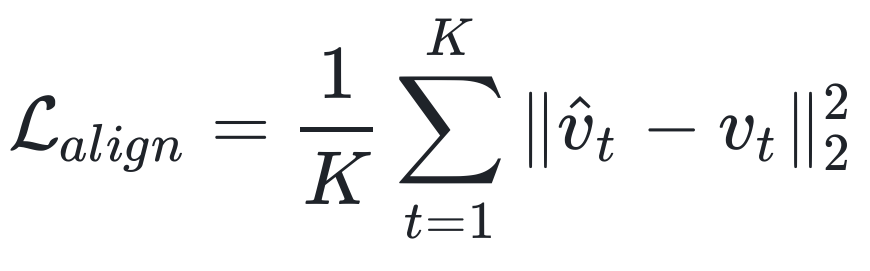
此外,在第一阶段中,为了使模型与所提出的推理模式保持一致,同时对 <|img_end|> 这一 special token 和答案的交叉熵损失进行了建模:
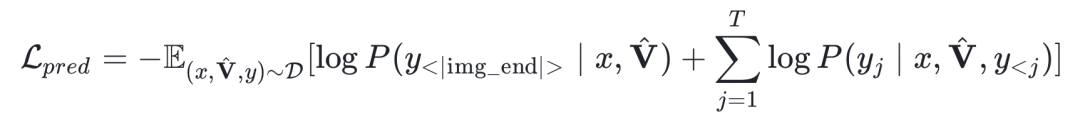
其中是生成的 latent visual tokens,y 为问题 x 的 ground truth 答案。阶段一的整体损失函数为上述两者加权:

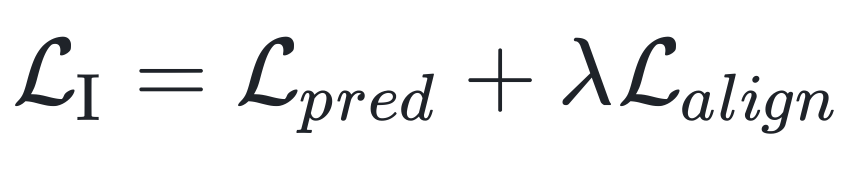
阶段二:潜在监督微调 (Latent Supervised Fine-Tuning)
在对齐之后,第二阶段通过 LoRA 微调 LLM,并且冻结已经训练对齐的投影头。此时,模型不再生成文本 Token,而是自回归地生成一串连续的「潜在视觉 Token」(Latent Visual Tokens)。这些 Token 在隐空间中模拟了视觉编码器的输出,最终引导模型解码出正确的文本答案。

推理与解码策略
推理过程要求模型自主地从连续的潜在推理空间导航到离散的文本解空间。研究团队探索了两种方案:基于 Special Token 的动态终止策略以及固定 Token 预算的静态终止策略。
-
基于 Special Token 的动态终止策略
推理阶段在第一个时间步长 结束,此时终止标记的概率达到最大值:

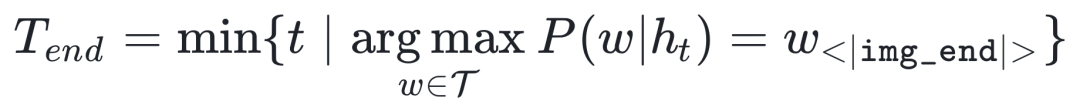
其中 表示 Token 集, 表示在时间步长 t 时的隐藏状态。模型从后续状态开始对文本答案进行解码。

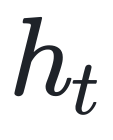
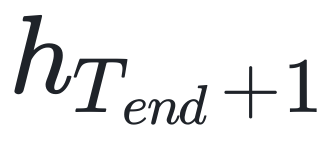
-
固定 Token 预算的静态终止策略
该策略将潜在思维链的长度限制为一个固定的超参数。达到这个阈值时,会手动添加 <|img_end|> 这一 special token,以触发从潜在推理到文本生成的转换。
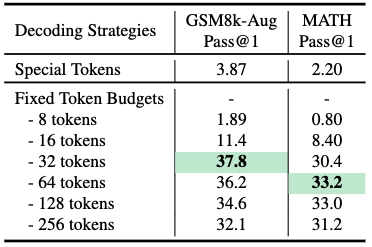
研究团队在实验中发现,动态终止策略的性能明显低于固定 Token 预算策略。这种性能差距可能源于连续潜空间中自我调节停止机制的内在不稳定性。在生成潜空间推理嵌入时,隐藏状态可能无法始终如一地为终止标记生成高置信度的预测,从而导致过早或延迟的转换,破坏推理流程。
此外,采用固定 Token 预算策略时,每个数据集的最优 Token 预算各不相同。在 GSM8k-Aug 数据集上,32 个 Token 能实现最佳性能,而 MATH 数据集则需要 64 个 Token 才能达到峰值准确率。研究者推测这种差异的出现是因为 MATH 数据集更具挑战性,需要更长的推理链。
实测数据说话:
推理速度「狂飙」
研究团队在 GSM8k、MATH、SVAMP 等多个数学和逻辑推理基准上对 RoT 进行了广泛测试。实验基于 Qwen3-VL 和 LLaVA-V1.6 等主流架构。
-
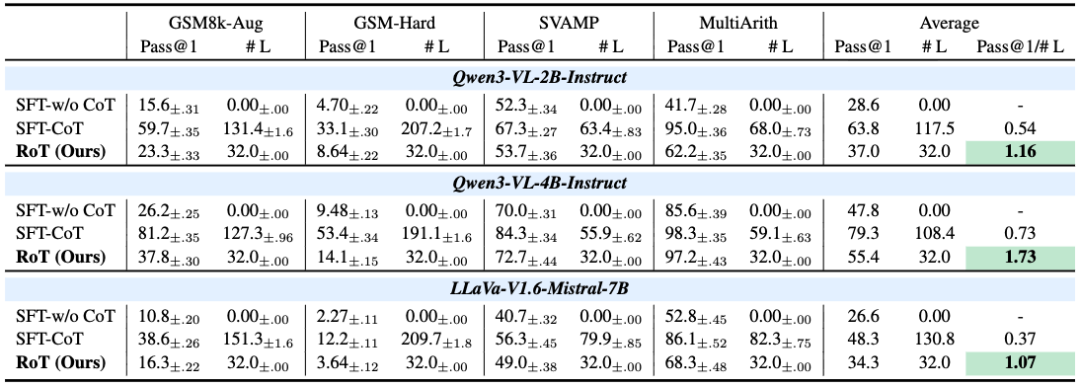
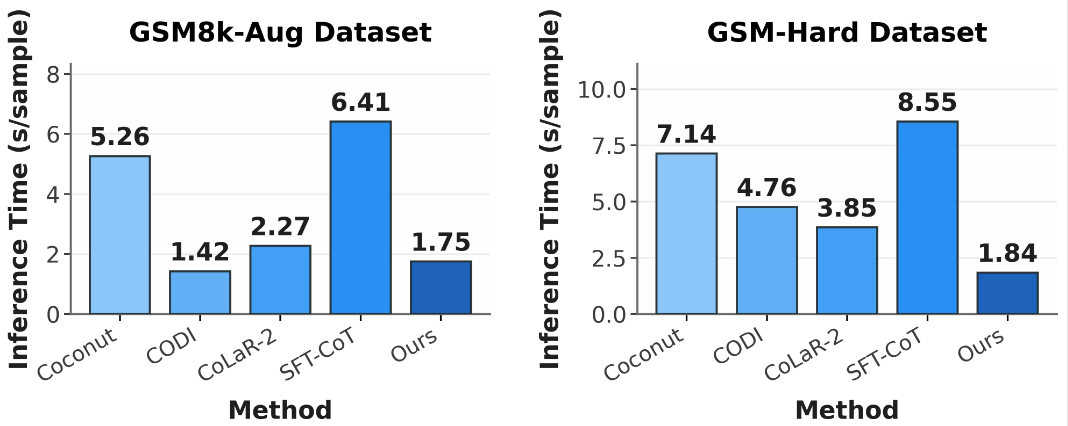
显著的压缩与加速: 相比于显式 CoT,RoT 实现了 3-4 倍的 Token 压缩率。在推理速度上,RoT 展现出了巨大的优势。例如在 Qwen3-VL-4B 模型上,Pass@1/(准确率与长度比)指标显著优于基线。
-
优于现有的隐式推理方法: 与 Coconut、CoLaR 等最新的隐式推理方法相比,RoT 在准确率上表现出色。特别是在 MultiArith 数据集上,RoT (Qwen3-VL-4B) 达到了 97.2% 的准确率,显著优于同等规模下其他隐空间推理方案。
-
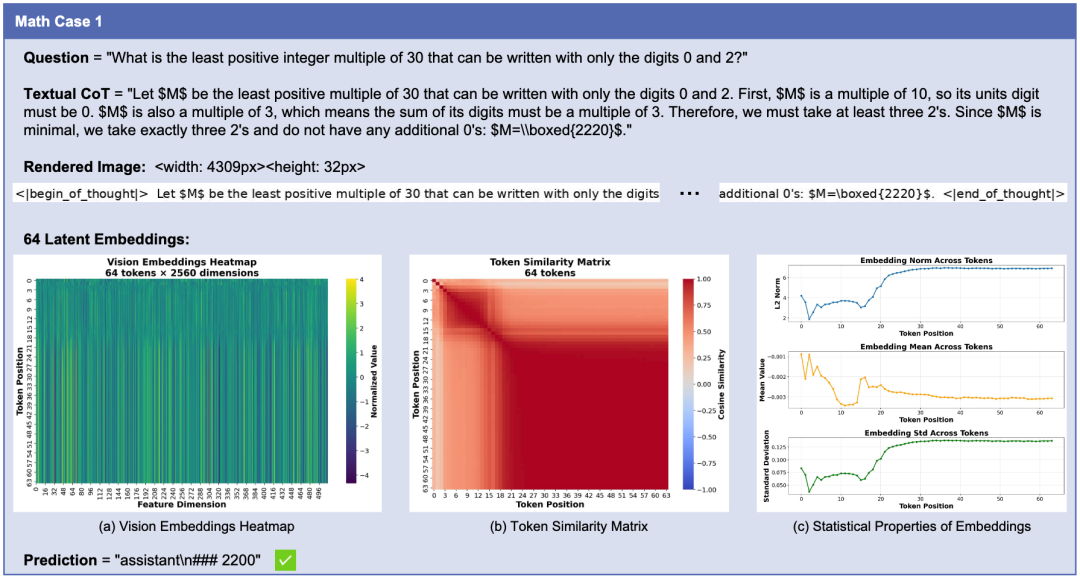
隐空间推理的可分析性: RoT 的一大亮点在于其可分析性。由于隐状态被对齐到了视觉空间,可以通过热力图(Heatmap)等来观察模型的「思考过程」。研究团队展示了 MATH 数据集的一个案例。可以看到,生成的潜在 Token 呈现出明显的结构化模式,Token 相似度矩阵显示了推理的阶段性。这证明模型并非在随机生成向量,而是在进行有逻辑的隐式推理。
单行渲染 vs. 多行渲染
在 RoT 中,传统的固定尺寸的多行渲染会导致文本在图像中频繁换行。对于模型来说,这种换行在视觉空间中引入了不必要的「空间跳跃」,打断了语义的连续性。
为了验证这一点,研究团队对比了「固定尺寸的多行渲染图像」与 RoT 文中使用的「单行动态宽度图像」。
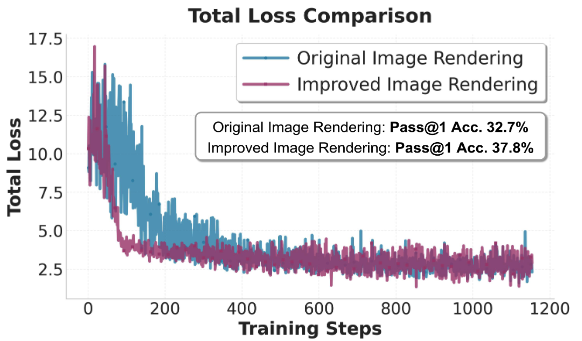
如上图所示,单行渲染相比多行渲染收敛更快,同时能够更好地契合语言模型从左到右的序列生成特性。
两阶段训练缺一不可
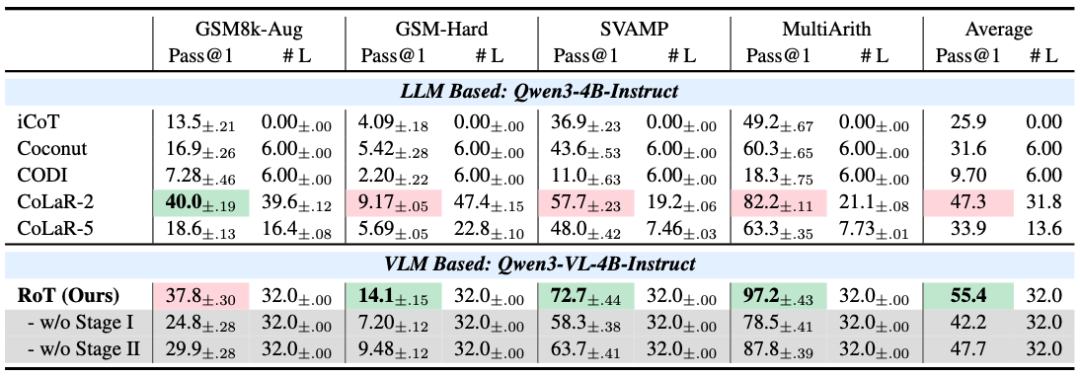
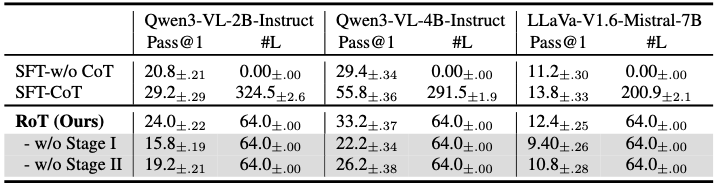
为了评估渐进式训练策略的效果,研究团队分别对每个阶段进行独立消融实验。
去除第一阶段会导致 MATH 的准确率从 33.2% 降至 22.2%,表明视觉对齐对于构建潜在空间结构以及在复杂任务中防止表示坍缩至关重要。同样,排除第二阶段也会导致性能显著下降,这会导致模型难以从连续的潜在空间中推导出最终答案。
展望
Render-of-Thought 提出了一种极具前景的「视觉化思维」范式。它打破了文本模态的限制,利用视觉信息的高密度特性来压缩推理过程。
这项工作不仅大幅提升了推理效率,更重要的是,它通过「将思维渲染为图像」这一直观的想法,为理解大模型神秘的内部隐空间提供了一扇新的窗口。对于未来在端侧设备等资源受限场景下部署强推理模型,RoT 提供了一条切实可行的技术路径。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com