英伟达开源VibeTensor,AI全栈深度学习系统无需人工干预!或开启生成式软件工程新纪元!
原文标题:陈天奇、贾扬清点赞:Vibe Coding版PyTorch,连论文都是AI写的
原文作者:机器之心
冷月清谈:
怜星夜思:
2、VibeTensor 构建的 “AI 辅助的开发方法”中,人类从“程序员”转变为“监工”与“策略制定者”。这种转变会对未来的软件开发团队带来哪些影响?
3、VibeTensor 在算子内核的性能上已经可以超越 PyTorch,但整体性能仍有差距。你认为未来 AI 在哪些方面还有提升空间,才能真正实现“AI 编程”?
原文内容
前两天,Node.js 之父 Ryan Dahl 在 X 上断言:「人类编写代码的时代已经结束了。」该帖引发广泛讨论,浏览量更是已经超过了 700 万。而现在,我们迎来了一个对这一判断的有力证明。
刚刚,英伟达杰出工程师许冰(Bing Xu)在 GitHub 上开源了一个新项目 VibeTensor,让我们看到了 AI 在编程方面的强大实力。
从名字也能看出来,这是 Vibe Coding 的成果。事实也确实如此,这位谷歌学术引用量超 20 万的工程师在 X 上表示:「这是第一个完全由 AI 智能体生成的深度学习系统,没有一行人类编写的代码。」

更具体来说,VibeTensor 是一个可运行的深度学习系统,配备了 RCU 风格的调度器、缓存分配器和反向模式自动微分器。该智能体还发明了一种 Fabric 张量系统 —— 这是目前任何框架中都不存在的新东西。
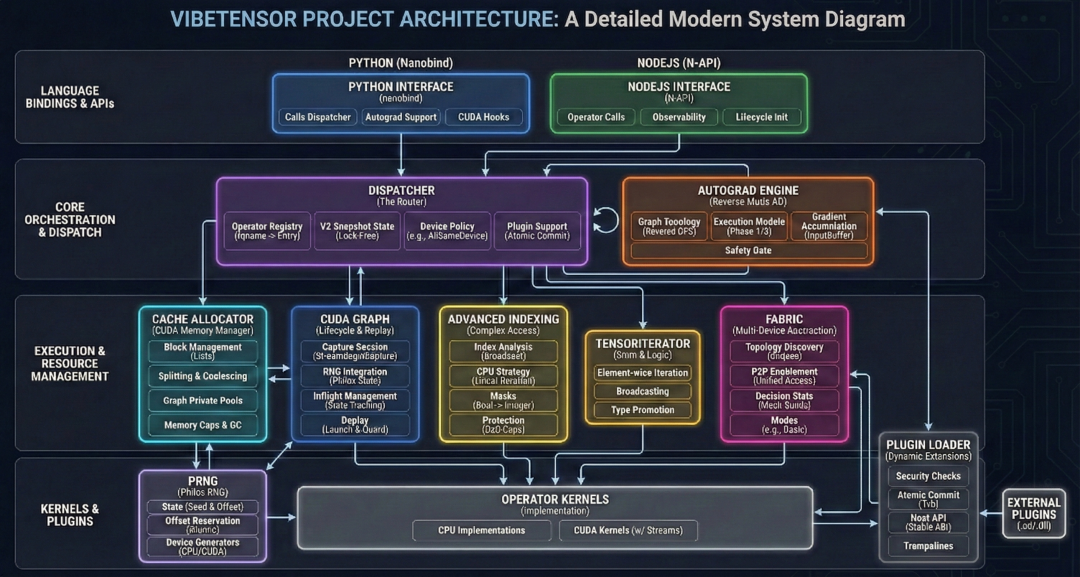
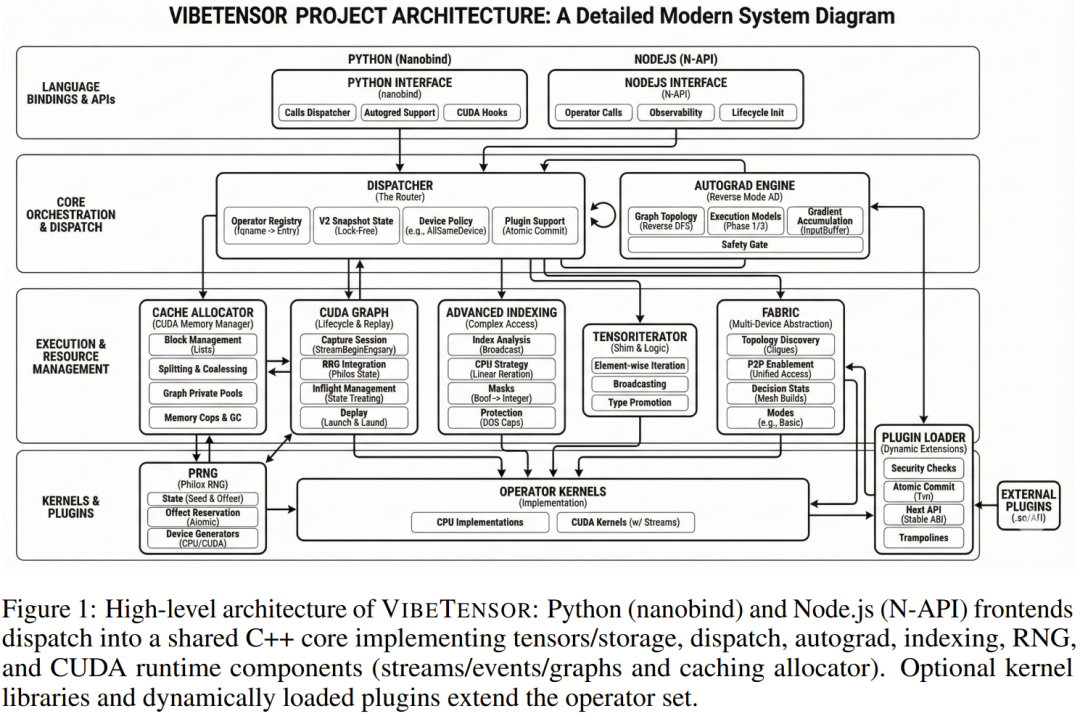
很明显,许冰分享的这张项目架构图也是 AI 生成的
其 Vibe Kernel 包含 13 种不同类型、总计约 4.7 万行代码的自动生成内核,这些内核使用 Triton 和 CuteDSL 编写,并且具有很强的性能表现。
许冰表示,VibeTensor 由英伟达的第四代智能体生成。但它也呈现出了一种「弗兰肯斯坦效应(Frankenstein Effect)」:系统本身是正确的,但某些关键路径的设计效率低下。因此,其性能无法与 PyTorch 相媲美。
更重要的是,许冰强调:「自 2025 年夏天以来,我一行代码都没写过。」他说这项工作是他看过 Andrej Kaparthy 的播客之后开始的。「我当时并不认同他的观点,所以我和 Terry Chen(英伟达首席工程师)开始用它来测试我们的智能体的能力。弗兰肯斯坦效应最终暴露了我们智能体的一些局限性 —— 但方向很明确。」
该项目在 X 上引起了不少关注,许冰的几位著名英伟达同事(也被列为参与者)也有分享点评。
比如陈天奇表示:VibeTensor 很有意思,它表明 AI 智能体能够构建深度学习框架这样复杂的东西。「生成的代码还有一些需要改进的地方,但它能够做到这一点本身就非常有趣。」

贾扬清的评价则更高,他表示该项目的出现罕见地验证了一个根本性问题:AI 能否编写复杂的系统代码?而该项目给出的答案是「能,但是……(仍有问题)」。他说 AI 正以惊人的速度前进,「如果我们能掌握更多正确的原则,AI 终将完全超越人类程序员。这就像 2015 年 1 月的 AlphaGo。」

目前,许冰已经在 GitHub 上 NVlabs 帐号下发布了 VibeTensor 的相关内容,其中也包含一篇论文。

-
论文标题:VibeTensor: System Software for Deep Learning, Fully Generated by AI Agents
-
论文地址:https://github.com/NVlabs/vibetensor/blob/main/docs/vibetensor-paper.pdf
-
项目链接:https://github.com/NVlabs/vibetensor
有意思的是,当我们初看这篇论文时,我们发现论文中有一些 AI 生成的内容。于是我们询问了许冰本人,而他给出的答案让我们非常震惊:这篇论文竟也是 100% 由 AI 撰写的!

许冰的回复
下面我们就来详细看看这个 AI 编写的项目究竟是什么。
VibeTensor:全球首个完全由 AI 智能体生成的全栈系统
VibeTensor 可不仅仅是又一个深度学习库。它是全球首个完全由 AI 智能体生成的全栈系统。从 Python/Node.js 的上层绑定,到 C++ 核心调度器,再到最底层的 CUDA 内存管理,每一行代码的增删改查、每一次 Bug 的修复、每一轮构建验证,全部由英伟达第四代智能体(Agent)独立完成。
而人类的作用是提供了高层级的需求指导,然后像监工一样看着 AI 智能体在两个月内疯狂输出。下面就来拆解一下这个氛围编程版的 PyTorch:VibeTensor。
首先,性能上虽然 VibeTensor 目前还无法与 PyTorch 这种经过多年磨砺的框架抗衡(根据论文测试,部分场景慢了约 1.7 到 6.2 倍),但作为一个功能完整的技术原型,其设计的完整度令人吃惊。
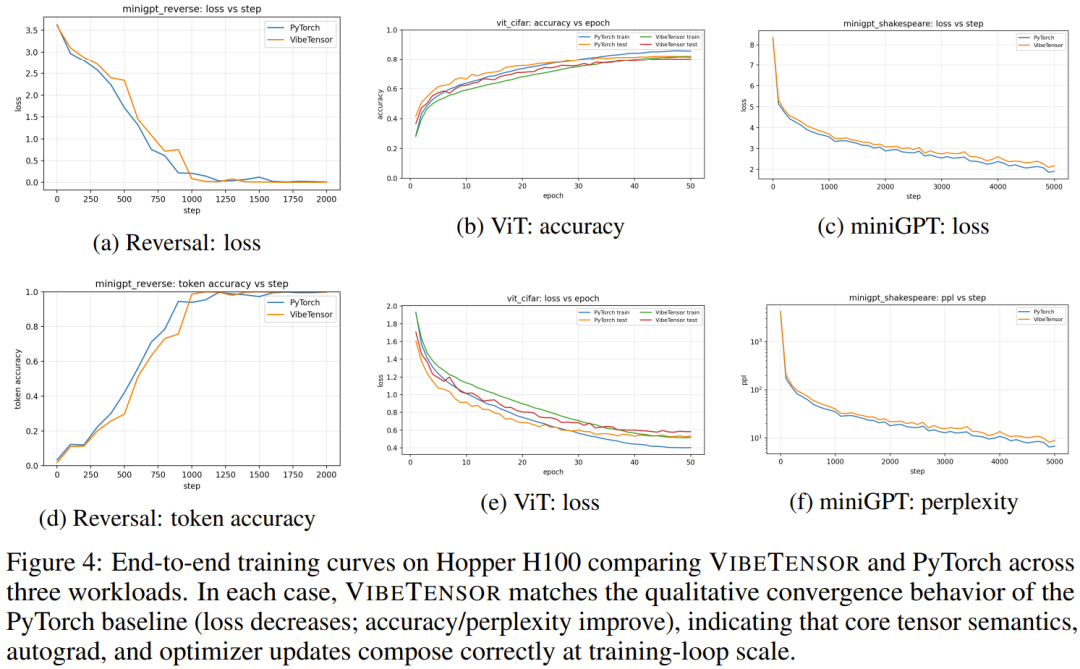
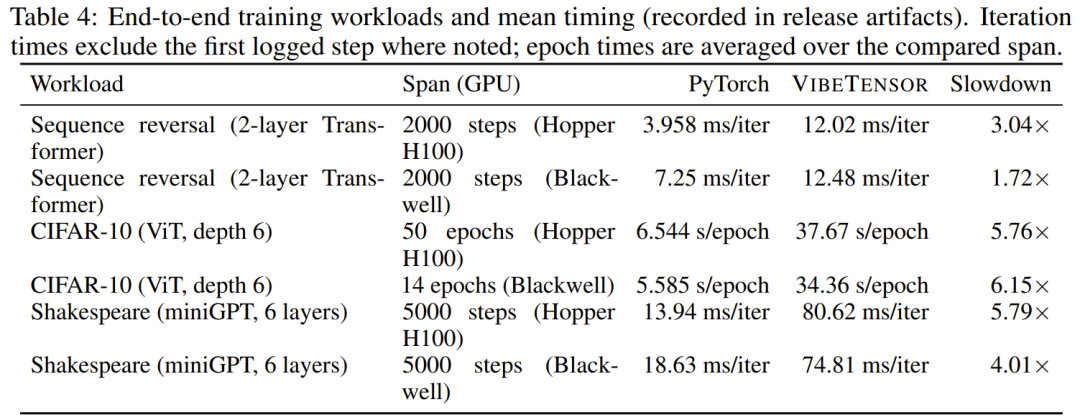
根据论文描述,VibeTensor 并不是一个简单的包装库,它拥有极其硬核的底层架构。
核心运行时的「暴力美学」
VibeTensor 的 C++20 核心并非简单的库调用。它实现了一个完整的 TensorImpl 架构,作为参考计数的 Storage 之上的视图。令人惊讶的是,AI 赋予了它支持非连续视图(Non-contiguous views)和 as_strided 语义的能力,并引入了原子版本计数器来确保原地(In-place)操作的安全性。
在算子调度层面,AI 构建了一个 schema-lite 调度器,能够将 vt::add 这样的操作名精准映射到 CPU 或 CUDA 的内核实现上。这种设计支持锁定(Boxed)和非锁定(Unboxed)调用路径,并通过不可变的快照状态(Snapshot states)实现了稳态下的无锁调用,极大地压低了调度开销。
独创的 Fabric 张量系统:不属于任何现有框架
在 VibeTensor 的所有组件中,最令人振奋的莫过于名为 Fabric 的实验性子系统。这是目前市面上任何主流深度学习框架(如 PyTorch 或 TensorFlow)中都不曾以这种形式存在的概念。
Fabric 本质上是一个显式的多设备抽象层。它的核心使命是打破单卡运行时的限制,直接接管硬件拓扑的自动发现过程。根据论文描述,Fabric 能够主动识别 CUDA P2P(点对点)和 UVA(统一虚拟地址)支持情况。
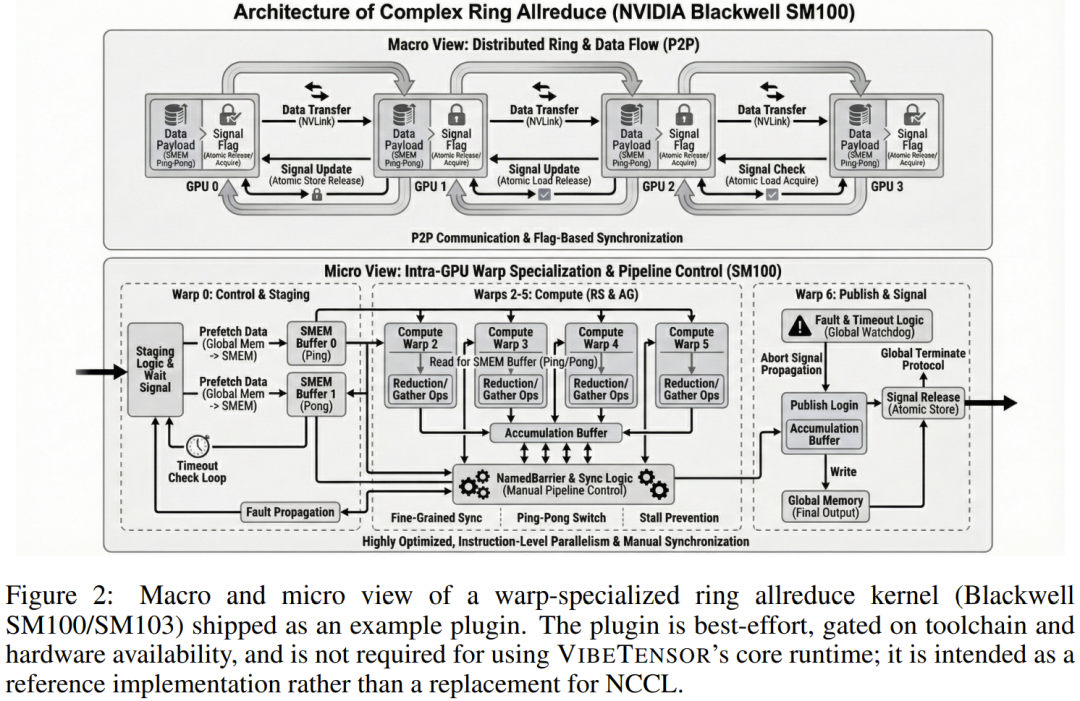
不同于传统框架将多卡通信隐藏在复杂的分布式 API 后,Fabric 提供了一套透明的可观测原语,允许研究者直接控制内存的放置与同步策略。
在 VibeTensor 的 Blackwell 评估中,AI 甚至基于 Fabric 构建了一个可选的环形全归约(Ring-allreduce)插件。这种插件直接绑定了 CUTLASS 的实验性内核,完全绕过了 NCCL。这意味着 AI 已经开始尝试从底层通信协议层面,去重构大规模分布式训练的逻辑。
异步优先的「Node.js + Python」双前端
在用户界面上,AI 并没有止步于复刻一个 PyTorch。它不仅利用 nanobind 打造了一个高度兼容的 Python 覆盖层(vibetensor.torch),还开创性地引入了一个基于 Node-API 的 Node.js 插件。
这个 JavaScript/TypeScript 界面采用了纯粹的「异步优先」设计。所有的重负载任务都被调度至 napi_async_work 以避免阻塞 Node 事件循环,并通过一个全局在途任务上限(VBT_NODE_MAX_INFLIGHT_OPS)来精细控制排队压力。这种横跨数据科学(Python)与后端工程(Node.js)的选型,体现了 AI 智能体在处理异构开发环境时的灵活性。
AI 内核套件:从算子到显存的全自动进化
在最底层的算子实现上,VibeTensor 附带了一个由 AI 生成的庞大内核套件。这里包含了 200 多个源文件,涵盖了从基础的 LayerNorm 到复杂的 Fused Attention 等各类算子。
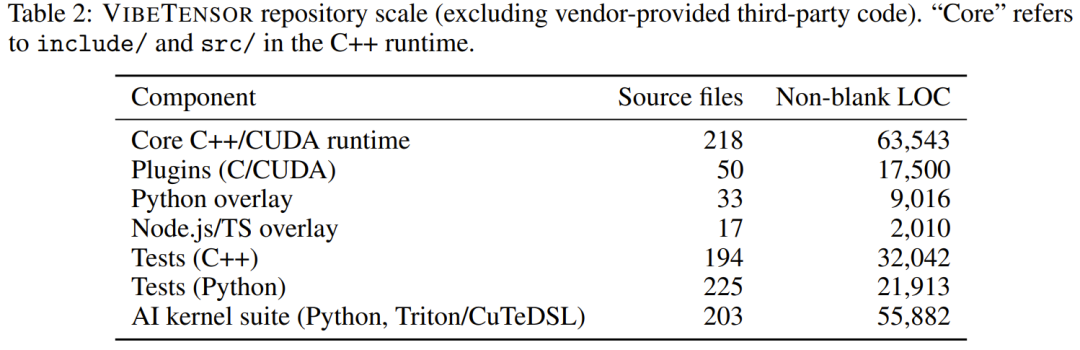
这些内核利用了 Triton 和英伟达自家的 CuTeDSL 编写。
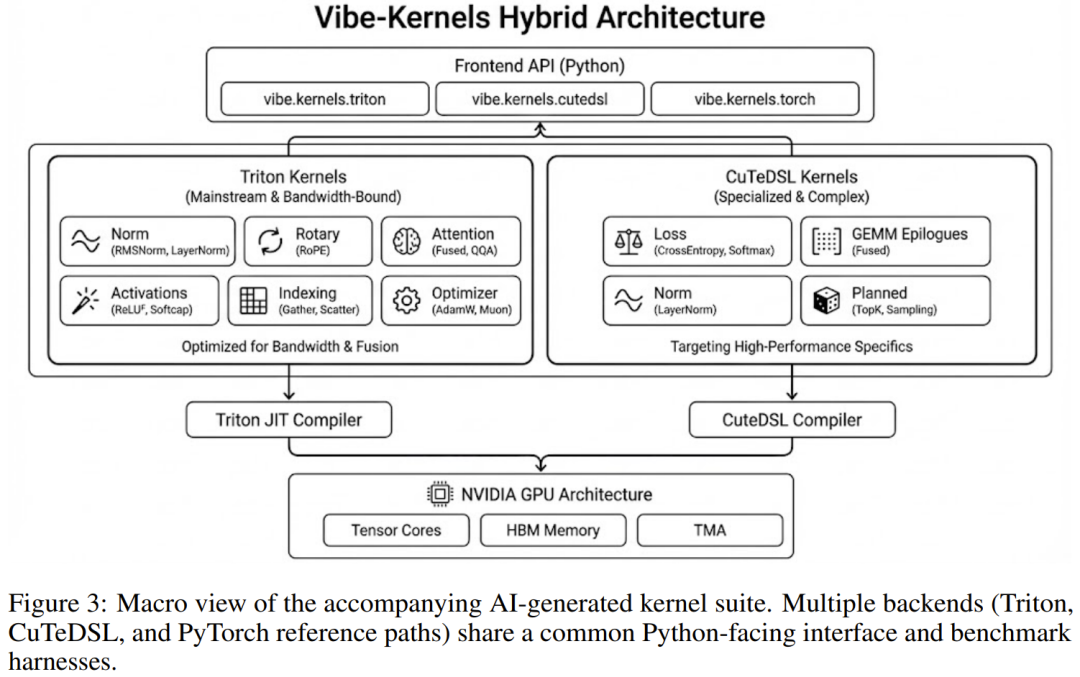
值得注意的是,AI 生成的内核并非只是「能用」,在 H100 的实测中,其生成的 Fused Attention 内核在特定形状下,前向计算比 PyTorch 的原生 FlashAttention 快了 1.54 倍,后向计算快了 1.26 倍。尽管这只是孤立算子的表现,但它证明了 AI 在掌握硬件特性(如 Hopper 架构的 TMA 或 Tensor Cores)方面的巨大潜力。

弗兰肯斯坦效应:AI 编程的隐形墙
尽管 VibeTensor 能够跑通复杂的神经网络模型,但许冰和团队在论文中诚实地提出了一个引人深思的概念:「弗兰肯斯坦效应(Frankenstein Effect)」。
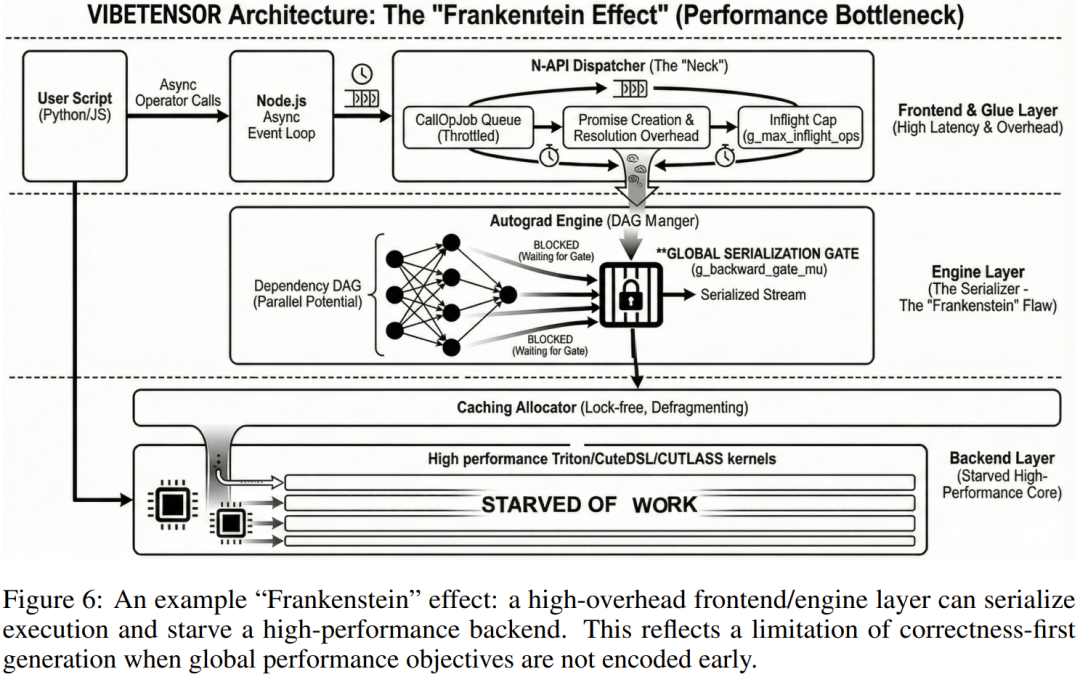
这是 AI 智能体在构建复杂系统时暴露出的核心局限性。简单来说,AI 能够确保每一个局部子系统(如调度器、分配器、算子)在逻辑上是正确的,且能通过单元测试。但当这些局部组件拼凑成一个庞大的全局系统时,它们之间会产生意想不到的「摩擦」,形成性能瓶颈。
例如,AI 为了确保多线程环境下的安全性,在 Autograd 引擎中设计了一个非重入的全局互斥锁。这个设计从局部看非常稳健、安全,但在全局运行时却成了「扼杀」并行性能的元凶,导致原本高效的显卡内核因数据等待而频繁空转。这种「正确但低效」的代码,正是目前智能体在系统级架构设计上的天花板。
AI 辅助的开发方法
VibeTensor 的诞生并非源于一次简单的提示词工程,而是一场长达两个月的、由高层级人类指令驱动的 Agent 自主演化过程。许冰也让 AI 在论文中用一个章节专门总结了「AI 辅助的开发方法」。
1. 彻底的「黑盒」工作流
在这场实验中,人类的角色从「程序员」彻底转变为「监工」与「策略制定者」。许冰及其团队并没有进行任何代码层面的 Diff Review(差异审查),也没有手动运行过任何验证命令。
相反,开发流程被简化为一个持续循环的闭环:
-
目标设定: 人类指定一个作用域明确的目标和必须遵守的约束条件。
-
代码生成: AI 智能体自主提议代码更改,并以 Diff 的形式应用到仓库中。
-
工具校验: Agent 会自动调用编译器、测试框架和差异检查工具。
-
多智能体评审: 为了弥补单体 AI 可能存在的盲点,团队引入了多 Agent 协作评审机制,用于捕捉缺失的边界情况、冗余的抽象或是潜在的安全隐患。
2. 测试驱动的「硬核」规范
在 Agent 驱动的开发中,测试不再是锦上添花,而是唯一的「真理来源」。VibeTensor 的每一行代码都必须经过 C++(CTest)和 Python(pytest)双重测试套件的洗礼。
更具创新性的是,AI 智能体还利用 PyTorch 作为一个「参考原件」,建立了一套自动化的 API 对齐检查器。当 AI 编写的算子出现数值偏差或内存泄漏时,Agent 会自主分析报错日志,添加一个最小化的回归测试用例,并重新进入修复循环。这种「测试即规格说明」的模式,确保了即使在缺乏人工干预的情况下,生成的 16 万行代码依然保持了极高的逻辑一致性。
3. 跨层级调试的挑战
论文揭示了一个有趣的现象:AI 在处理「单次正确」的任务时表现卓越,但在处理系统的「组合稳定性」时却面临巨大挑战。例如,在 Fused Attention 算子的移植过程中,Agent 经历了多次挫败:从最初的参数超限、显存对齐错误,到运行数千次后才暴露出的缓冲区初始化隐患。
这种跨越 C++ 运行时、CUDA 驱动程序和 Python 封装层的多级调试能力,正是此次英伟达第四代智能体展示出的最核心竞争力。它证明了 Agent 已经能够理解复杂的内存语义和硬件约束,而不仅仅是模仿代码片段。
AI 工程师的「AlphaGo 时刻」?
VibeTensor 的出现并非为了取代 PyTorch,而是一场关于「生成式软件工程」的宏大实验。
正如前文所述,许冰提到这项工作的灵感源于 Andrej Karpathy 的播客。当时他并不完全认同 Karpathy 关于「AI 编程」的某些激进观点,于是决定和首席工程师 Terry Chen 一起,用最硬核的系统开发来测试智能体的极限。
现在,方向已经明确。虽然「弗兰肯斯坦效应」依然存在,但 VibeTensor 的诞生标志着一个新时代的开启:未来的系统软件可能不再是工程师逐行敲出来的,而是由人类定义需求、由 AI 在「氛围」中生成出来的。
参考链接
https://x.com/bingxu_/status/2014354974986408138
https://x.com/tqchenml/status/2014360719534227561
https://x.com/jiayq/status/2014373196934590593
https://x.com/rough__sea/status/2013280952370573666
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com