OpenAI考虑收益分成模式,AI制药成功后也要“抽成”?或颠覆现有AI商业模式。
原文标题:OpenAI:以后大家用AI赚的钱,我可能要抽成
原文作者:机器之心
冷月清谈:
怜星夜思:
2、OpenAI从“卖工具”转向“分利润”,这是否意味着AI公司需要重新思考其商业模式?除了利润分成,AI公司还有哪些可能的盈利方式?
3、OpenAI的训练数据来源一直备受争议,如果他们抽取用户使用其AI开发的知识产权分成,这是否会让争议更加激烈?你认为OpenAI应该如何解决数据来源问题?
原文内容
今天一早,OpenAI CEO 奥特曼就发推晒收入,「仅我们的 API 业务而言,上个月就增加了超过 10 亿美元的 ARR(年度经常性收入)。」
他继续说到,大多数人只看到了 ChatGPT 的成绩,但 API 团队的工作表现同样令人惊叹。
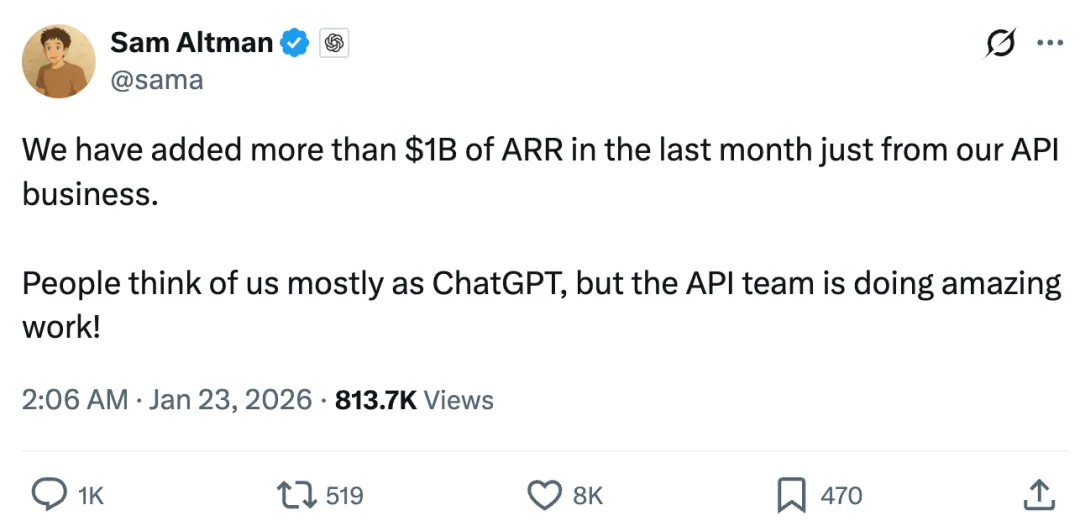
奥特曼此举或许是为了提振投资者的信心。这几天,OpenAI 被曝正计划寻求融资 500 亿美元,新的估值预计在 7500 亿美元到 8300 亿美元之间。
与此同时,在外媒 The Information CEO Jessica Lessin 主持的一场达沃斯论坛上,OpenAI CFO Sarah Friar 讨论了另一种商业机会 ——「价值共享」(value sharing)。
她提出,在药物研发领域,其他公司可以使用 OpenAI 的技术来发现药物。但一旦新药研发成功,OpenAI 将从自己的 AI 技术为客户创造的收益中分取一部分利润。
这意味着,OpenAI 可能正在考虑从「卖工具」转向「分利润」的商业模式。OpenAI 似乎不满足于只收「软件使用费」,而是想在客户发财时「抽成」。

OpenAI CFO Sarah Friar 在达沃斯论坛上。
最近大家都在讨论 OpenAI 的收入压力,预测他们今年会改变策略想办法盈利。没想到改变商业模式,是这么个改变法?
此番报道一出,真可谓一石激起千层浪,OpenAI 又被推上了风口浪尖。
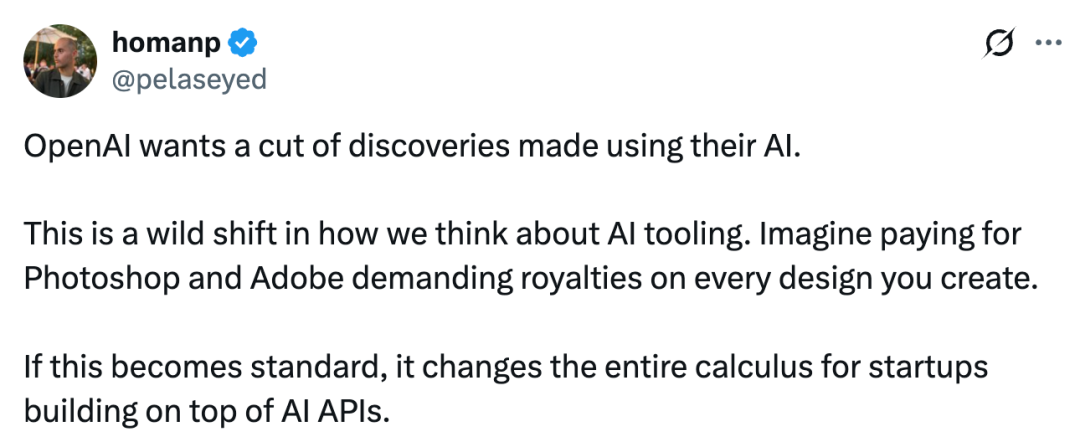
有人认为,这可能是对 AI 工具化认知的一次巨大颠覆。想象一下,如果你在使用 Photoshop,而 Adobe 却要求对你创作的每一件设计作品抽成。
如果这种做法成为行业标准,对于那些基于 AI API 构建业务的初创公司来说,整个商业模式的成本计算逻辑都将被彻底改变。
也有人分析道,「这听起来可能像是异想天开,但科学家们确实已经对大语言模型作为「想法合成器」和「研究助手」的潜力感到痴迷,并且 OpenAI 也确实在积极寻求获取生物、制药等领域的私有数据授权,用于模型训练。」

不过,更有业内人士感叹道,「一家以非营利性质起家的公司竟然走到了这一步,真是令人尴尬,简直是一种耻辱。」
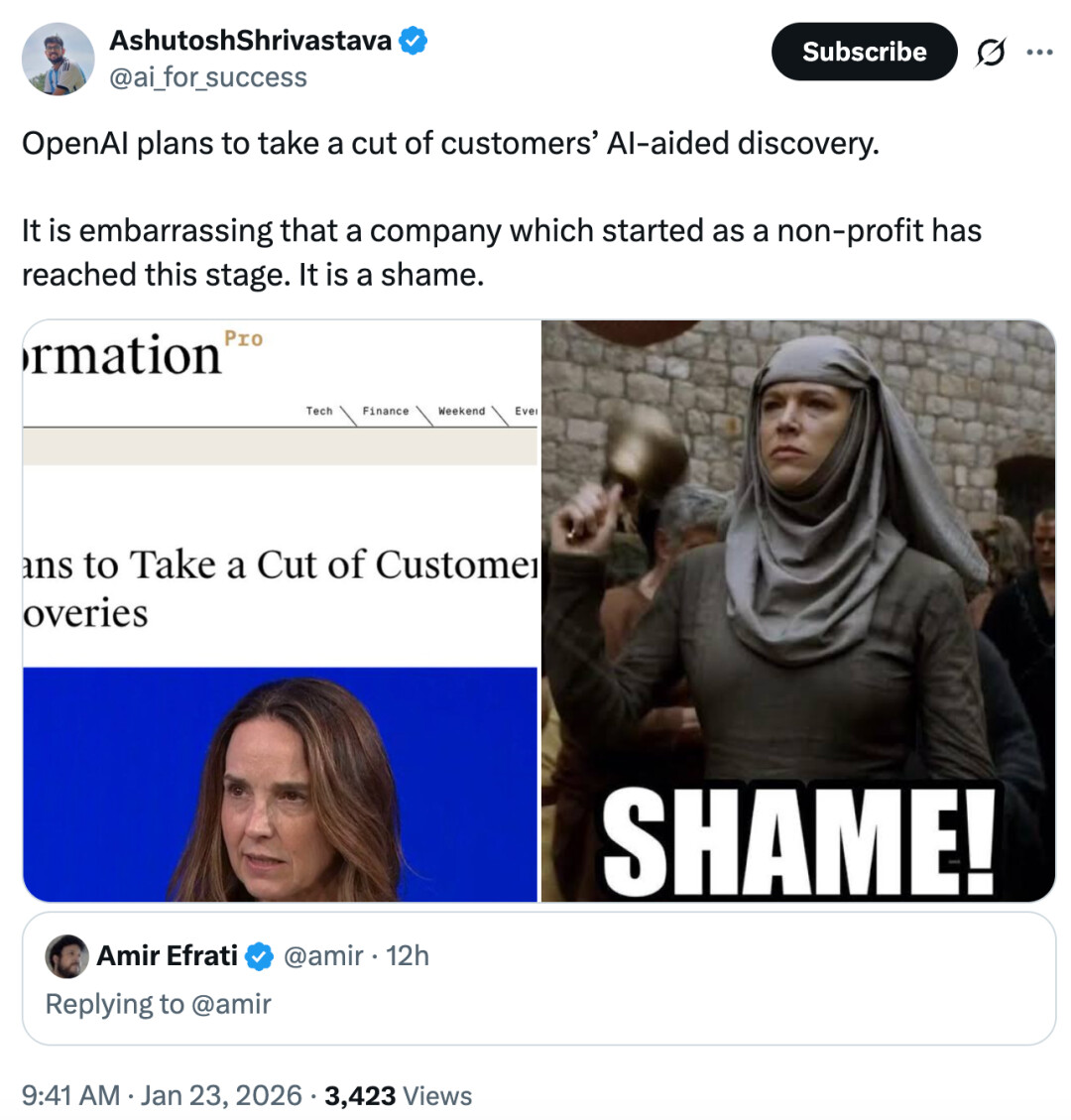
「所以,OpenAI 打算从用户使用其软件开发的知识产权(IP)中抽取分成,而他们自己的软件,却又是通过侵犯他人的知识产权构建出来的。」
一直以来,OpenAI 面临着 AI 训练数据的来源争议,其模型使用的训练数据中包括受版权保护的文章、书籍、代码和艺术作品。此前,《纽约时报》以及包括多位作家在内的个人就曾对 OpenAI 未经授权使用其数据来训练模型提起过诉讼。

对于企业来说,OpenAI 的这种模式是可接受的吗?答案或许是肯定的。并且,这可能会令 OpenAI 损失更多商业客户。
OpenAI 转变思路的背后,AI 正在加速药物研发
OpenAI 抛出收入分成论的原因,一部分看到是如今 AI 作为科研工具已经已经开始起效了。
最近,制药和生物技术公司纷纷开始使用各种形式的 AI 进行药物研发。已有多家大型医药公司宣布了与 OpenAI 的深度合作,尝试使用 OpenAI 的模型来分析大量数据并提出假设或测试方法。去年 10 月,为制药公司提供服务和设备的企业 Thermo Fisher Scientific 表示,它将使用 OpenAI 模型来加速药物开发,并识别哪些疗法不太可能成功。
OpenAI 似乎也在开发越来越复杂、专门用于生物学和药物方向的 AI 模型,以推动 AI 在药物发现过程中更直接地协助制药公司。
例如,OpenAI 最近与生命科学诊断供应商 Revvity、Xero 以及其他生物技术公司进行了洽谈,想要获得授权以使用它们更专业的数据来训练自家 AI 模型。
在 AI + 医药研发方向,OpenAI 并不是唯一的一家,Anthropic 以及谷歌 DeepMind 等也与一些早期生物技术初创公司就数据许可或合作事宜展开了讨论。
Sarah Friar 无疑熟悉像 Recursion 这样较早期的 AI 药物研发公司,这些公司曾与制药企业达成交易,若其技术成功识别出药物,将获得巨额奖金。不过,目前这样的成功案例即使有,也寥寥无几。
竞争虽然才起步,但已非常激烈:OpenAI 的对手 Anthropic、Google DeepMind 以及 Alphabet 旗下专注于利用 AI 进行药物研发的子公司 Isomorphic Labs,也都已与早期生物技术初创公司就数据许可或合作关系进行了讨论。
上周末,Sarah Friar 在一篇博客文章中做了某些暗示,OpenAI 也可以在能源和金融领域达成这种价值共享类型的安排。「基于知识产权(IP)的许可协议和基于结果的定价,将分享所创造的价值,」Sarah Friar 这样写道。

博客地址:https://openai.com/index/a-business-that-scales-with-the-value-of-intelligence/
大语言模型已经很擅长发现人类可能错过的架构和形态。OpenAI 的模型有时可以将不同领域的概念联系起来,提出新型实验建议,涉及从核聚变到病原体检测的各个方面。尽管这些模型存在许多局限和错误,但科学家们似乎仍对它们充满热情。
虽然这听起来可能有些天马行空,想象 OpenAI 通过 IP 许可或版税获得的收入比广告还多,但 Sarah Friar 的言论极其清晰地释放了他们想要做什么的信号。
问题在于,在 OpenAI 完成目前正向投资者寻求的数百亿美元融资之后,她是否还会继续谈论这一点。
参考链接:
https://www.theinformation.com/newsletters/applied-ai/openai-plans-take-cut-customers-ai-aided-discoveries?rc=jn0pp4
https://www.tipranks.com/news/the-fly/openai-spoke-to-revvity-about-licensing-data-the-information-reports-thefly
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com