Meta发布Llama 4技术报告,1300+作者署名,疑似回应Llama 4性能质疑,强调部署限制与营销宣传的差异。
原文标题:Meta新模型要来了,但Llama 4的锅谁来接?1300多位作者的联合报告来了
原文作者:机器之心
冷月清谈:
怜星夜思:
2、报告中提到 Llama 4 在实际部署中由于硬件成本限制,上下文长度受到限制,这对于 AI 模型的应用会产生什么影响?你认为未来可以通过哪些技术手段来解决这个问题?
3、Llama 4 团队发布这份报告,你觉得更像是技术澄清还是危机公关?你觉得他们成功解释了 Llama 4 的争议吗?
原文内容
路透社最新消息,Meta 新成立的 AI 团队本月已在内部交付了首批关键模型。据悉,该消息来自 Meta 公司的 CTO Andrew Bosworth,他表示该团队的 AI 模型「非常好」(very good)。
媒体在去年 12 月报道称,Meta 公司正在开发一款代号为 Avocado 的文本 AI 模型,计划于第一季度发布;同时还在开发一款代号为 Mango 的图像和视频 AI 模型。Bosworth 并未透露哪些模型已交付内部使用。
有意思的是,就在这篇报道的前些天,一篇技术报告《Llama 4 家族:架构、训练、评估和部署说明》在 arXiv 悄然上线,其中全面回顾了 Meta Llama 4 系列模型宣称的数据和技术成就。

-
报告标题:The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
-
报告地址:https://arxiv.org/abs/2601.11659v1
需要说明,上传这篇报告的作者是 Meta 一位机器学习工程师 Arthur Hinsvark,但这篇报告却并未明确标识来自 Meta。
尽管如此,这篇报告还是将 Llama 4 项目的所有参与者都加入到了作者名单中 —— 超过 1300 名,足足 5 页!因此,我们可以大体上认为这份报告就是来自 Llama 4 团队,尽管其中不少人现在已经从 Meta 离职,比如前 Meta FAIR 团队研究总监。
值得注意的是,这篇报告的引言有一段明确说明:「本文档是对公开材料的独立调查。报告的基准数值归因于模型卡,除非另有说明;应将它们视为开发者报告的结果,并对评估工具、提示工程和后处理持通常的保留态度。」
也就是说,这篇报告整体回顾了 Meta 公布的各种 Llama 4 相关材料,尤其是其宣称的一些数据。但没有明确解释其在实际应用中表现明显不及预期的原因。想要了解相关背景的读者可参阅:
不过,该报告也不是完全没有提到相关原因,仔细阅读的话,我们能在行文中看到一些端倪,其中主要的讨论点集中在部署限制和榜单争议上:
-
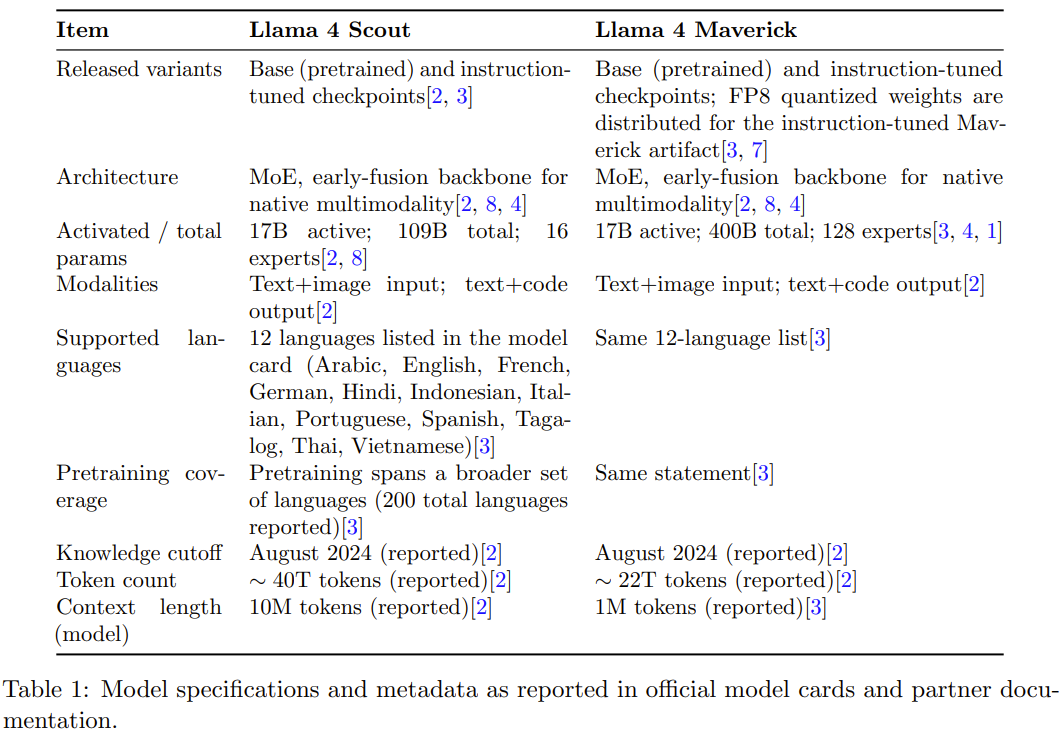
架构能力与实际部署的差距(尤其是上下文长度):论文反复强调了一个「经常出现的操作主题」:模型的架构支持能力与实际服务中提供的能力之间存在差距。虽然 Scout 在架构上设计为支持 10M 上下文长度,但在实际部署中(如 Cloudflare 或 AWS),由于显存和 KV 缓存的硬件成本限制,服务商往往将可用上下文限制在 128K 或 1M。这意味着用户在实际使用托管服务时,可能无法体验到模型宣称的全部长上下文能力。
-
榜单成绩与发布版本的差异:论文提到了关于 LMArena 排行榜的争议。Meta 在榜单上提交的 Maverick「实验性聊天」变体与公开发布的版本不完全相同。这导致了外界批评其「操纵基准测试」(gaming AI benchmarks)。这也解释了为什么用户使用公开发布版本时的体验可能与某些榜单上的高分表现不一致。
-
营销话术与技术指标的区别:论文明确指出,发布公告中的某些声称(例如 Scout 是「同类最佳」或强调性价比)属于「面向营销的主张」(marketing-facing claims),应当与严谨的模型卡基准测试结果分开解读。
这些细节似乎暗示了这份报告是 Meta Llama 团队对于 Llama 4 系列模型备受社区广泛批评(数据亮眼但能力很差)的最终回应。
对于这些说明,不知道你怎么看?
具体到内容上,这篇技术报告的内容仅有 15 页,其中 1300 多位作者的名单就足足占了 5 页,再去掉一页参考文献,实际内容仅有 9 页。其中,Meta Llama 团队总结了:
-
已发布的模型变体(Scout 和 Maverick)以及更广泛的系列模型背景,包括预览版的 Behemoth 教师模型;
-
超越高级 MoE 描述的架构特征,涵盖路由 / 共享专家结构、早期融合多模态,以及针对 Scout 报告的长上下文设计元素(iROPE 和长度泛化策略);
-
训练披露,跨越预训练、用于长上下文扩展的中期训练(mid-training),以及发布材料中描述的后训练方法(轻量级 SFT、在线 RL 和轻量级 DPO);
-
开发者报告的基础和指令微调检查点的基准测试结果;
-
在主要服务环境中观察到的实际部署限制,包括特定于提供商的上下文限制和量化打包。
此外,这份报告还总结了「与再分发和衍生命名相关的许可义务,并回顾了公开描述的安全措施和评估实践。其目的是为需要关于 Llama 4 精确、有来源依据事实的研究人员和从业者提供一份紧凑的技术参考。」
更多详情请参阅原报告。
参考链接:
https://www.reuters.com/technology/metas-new-ai-team-has-delivered-first-key-models-internally-this-month-cto-says-2026-01-21/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com