北大清华提出WaveFormer,用波动方程建模视觉,兼顾全局交互和高频细节,告别注意力机制的算力瓶颈。
原文标题:AAAI 2026 Oral | 告别注意力与热传导!北大清华提出WaveFormer,首创波动方程建模视觉
原文作者:机器之心
冷月清谈:
怜星夜思:
2、WaveFormer里提到用欠阻尼波动方程来建模,这个“阻尼”参数感觉挺关键的,它会如何影响最终的视觉效果?大家觉得这个阻尼系数α,在实际应用中应该如何调整?
3、WaveFormer在多个任务上都取得了不错的效果,大家觉得它最有潜力在哪个领域发挥更大的作用?或者说,它有哪些局限性?
原文内容

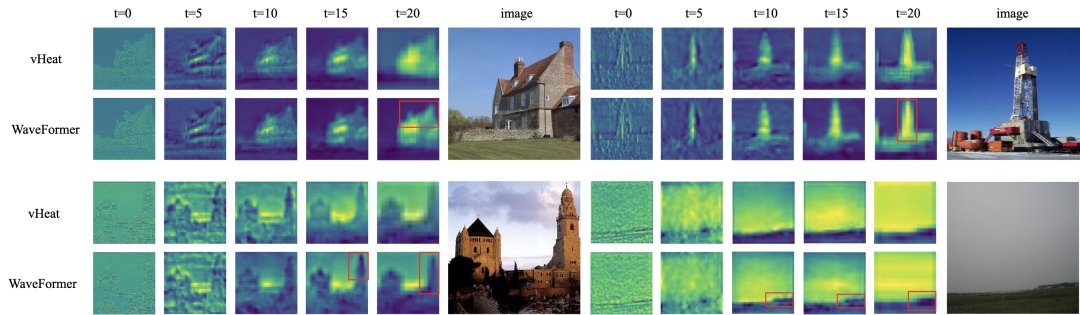
“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。
我们是否能找到一种既能实现全局交互,又能精准保留高频细节的物理建模方式?
来自北京大学和清华大学的研究团队给出了答案:波动方程(Wave Equation):把特征图当作空间信号,让语义在网络深度对应的 “传播时间” 里,遵循欠阻尼波动方程演化。这样一来,低频的全局结构与高频的边缘纹理不再是 “此消彼长” 的牺牲关系,而可以在可控的波动传播中共同存在。在 AAAI 2026 Oral 论文《WaveFormer: Frequency-Time Decoupled Vision Modeling with Wave Equation》中,研究者首次将视觉特征图视为在波动传播时间下演化的空间信号,受欠阻尼波动方程支配。

-
论文链接:https://arxiv.org/abs/2601.08602
-
代码仓库:https://github.com/ZishanShu/WaveFormer
WaveFormer 首次将波动方程作为视觉主干网络的核心全局建模机制。
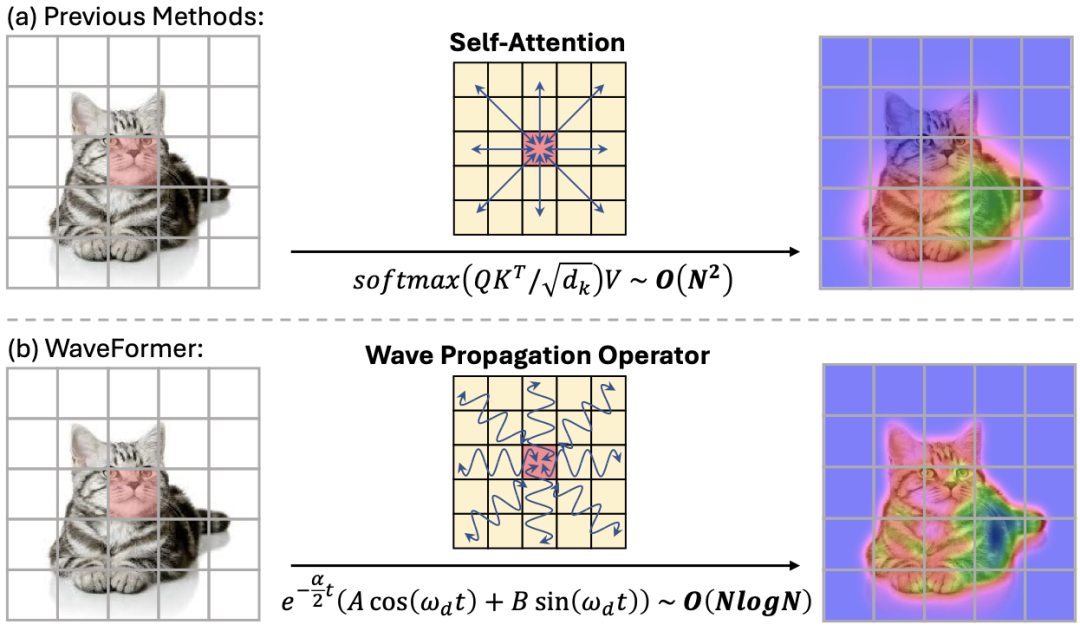
方法拆解:把图片当作 “波场”,特征当作 “波”,让语义振荡传播
WaveFormer 的关键思想可以用一句话概括:
全局交互不一定要靠 “相似度匹配”(attention),也可以靠 “波传播动力学”。
WaveFormer 将特征传播写成一个欠阻尼波动方程:
-
u (x, y, t):语义场(可以理解为特征图随 “传播时间” 演化)
-
v:传播速度(控制传播范围)
-
α:阻尼系数(控制衰减强弱)
它还引入了一个很有意思的设定:除了初始语义场 u0,还允许一个 “初始速度场” v0,表示不同区域语义被激活 / 抑制的变化趋势。
这个设定带来的最大变化是:空间频率被显式建模了。
论文里明确把 “频率” 对应到 2D 特征图的空间频率:低频是全局布局,高频是边缘与纹理。
WaveFormer 不再把不同频率的信息一股脑丢给网络自己 “学着处理”,而是把它们写进了传播方程的解里:不同频率以不同方式振荡、衰减,但都参与全局语义的长程运输。
关键在于,团队推导了波动方程在频域下的闭式解:
-
热方程常见形式会出现类似的项,高频随时间急速衰减
-
WaveFormer 的衰减项更像 ,对不同频率更 “公平”,而频率差异主要体现在 cos/sin 的振荡项上,从而实现频率–时间解耦。
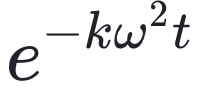
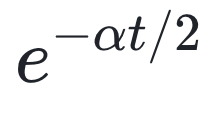
热传导方程和扩散方程的闭式解的对比:

WPO:把闭式解变成一个 O (N log N) 的全局模块
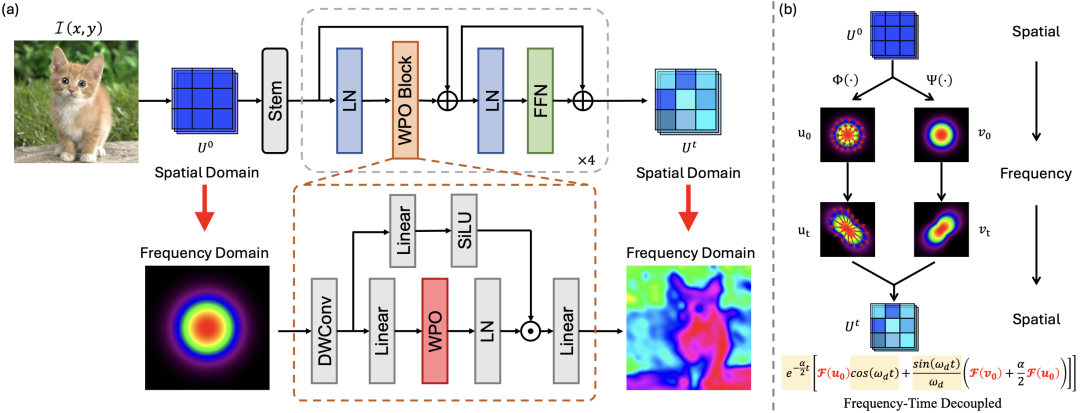
更 “工程友好” 的部分在这里:作者把欠阻尼波动方程的频域解,做成了一个可以直接替换 attention 的算子 WPO。
WPO 的实现流程非常清晰:
1. 把输入特征图变换到频域;
2. 用欠阻尼波动方程的频率–时间解耦的闭式解,对每个频率分量做 “振荡式调制”;
3. 再逆变换回空间域,从而完成一次 “全局语义传播”。
因为核心计算发生在频域(FFT /iFFT),WPO 的全局建模复杂度是 O (N log N),论文在摘要里明确对比 “远低于 attention”。
在网络结构上,WaveFormer 走的是层级式骨干:stem + 四个阶段,每个阶段由 WPO Block 组成(WPO + FFN + 下采样),整体可以作为 ViT 或 CNN 的 drop-in backbone。
为什么 “波传播” 适合视觉?一个更直观的理解
如果把一张图像看成 “由低频骨架 + 高频细节叠加” 的信号,那么视觉建模很多时候在做两件事:
-
低频:抓住整体结构、主体布局、长程一致性;
-
高频:保住边缘、纹理、细粒度辨别线索。
WaveFormer 的 “波动方程建模” 给了一个很直接的机制:
在频域里,每个频率分量按 “阻尼振荡” 传播:低频衰减慢、负责全局结构;高频振荡快、在阻尼控制下仍能保留边缘纹理。
论文把这种机制称为一种新的、物理一致的建模偏置(physics-inspired inductive bias),用于同时捕捉全局一致性与高频细节。
实验结果:速度、效率与精度的全面超越
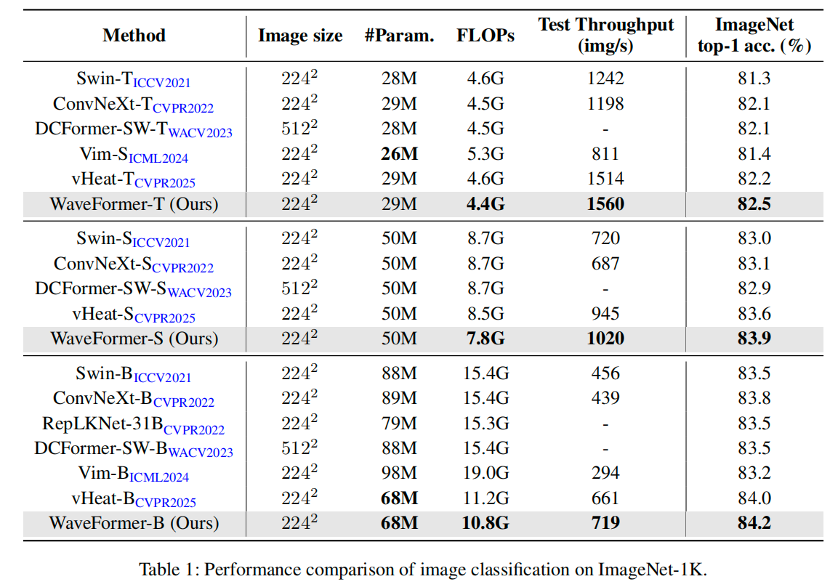
WaveFormer 在三类核心任务上验证:ImageNet 分类、COCO 检测 / 实例分割、ADE20K 语义分割。
ImageNet-1K 分类:
WaveFormer-B 在 10.8G FLOPs / 68M 参数下达到 84.2% Top-1。
论文同时给出整体结论:在保持竞争精度的同时,最高可带来 1.6× 吞吐提升、30% FLOPs 降低。
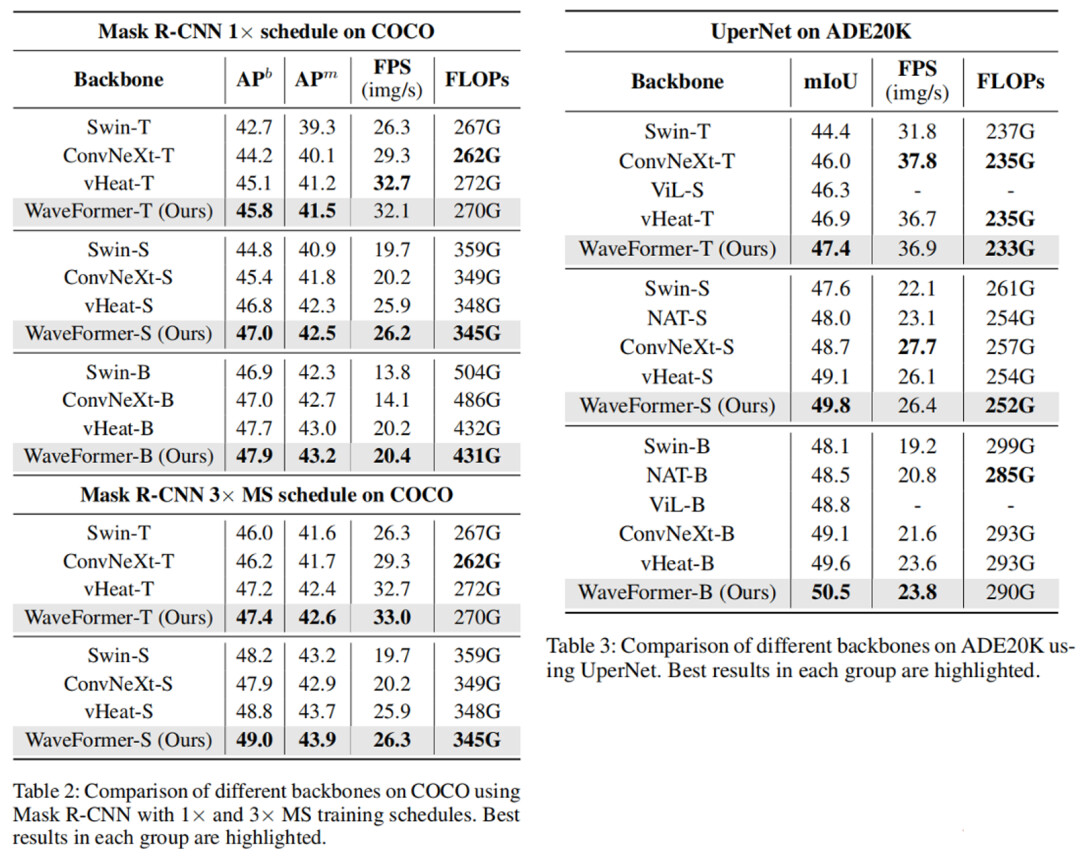
COCO 检测与实例分割(Mask R-CNN):
WaveFormer 在 box AP 与 mask AP 上整体优于 Swin/ConvNeXt,并且推理 FPS 更高。例如 WaveFormer-B 达到 47.9% APb、43.2% APm,推理速度 20.4 img/s,比 Swin-B/ConvNeXt-B 分别快 48%/45%。
ADE20K 语义分割(UperNet):
WaveFormer-B 达到 50.5% mIoU,同时 FLOPs 与 FPS 也具备优势;论文把这种提升与 “频率意识的波传播能同时保全局结构与细节边界” 直接关联起来。
总结与展望
WaveFormer 证明了经典的物理波动规律能够为现代人工智能提供强大的归纳偏置 。这种基于波动方程建模的新范式,不仅为视觉基础模型开辟了频域处理的新路径,也为未来多模态语义传播的研究提供了深刻的启示。
WaveFormer 最值得被记住的,可能不是某个单点指标,而是它把 “视觉全局建模” 换了一种语言来描述:
-
从 “token 相似度交互” 转向 “语义场的动力学传播”;
-
从 “隐式处理频率” 转向 “显式建模低频 / 高频及其随深度演化”;
-
从 “黑盒的全局模块” 转向 “可解释、可控(v 与 α 可调)的传播过程”。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com