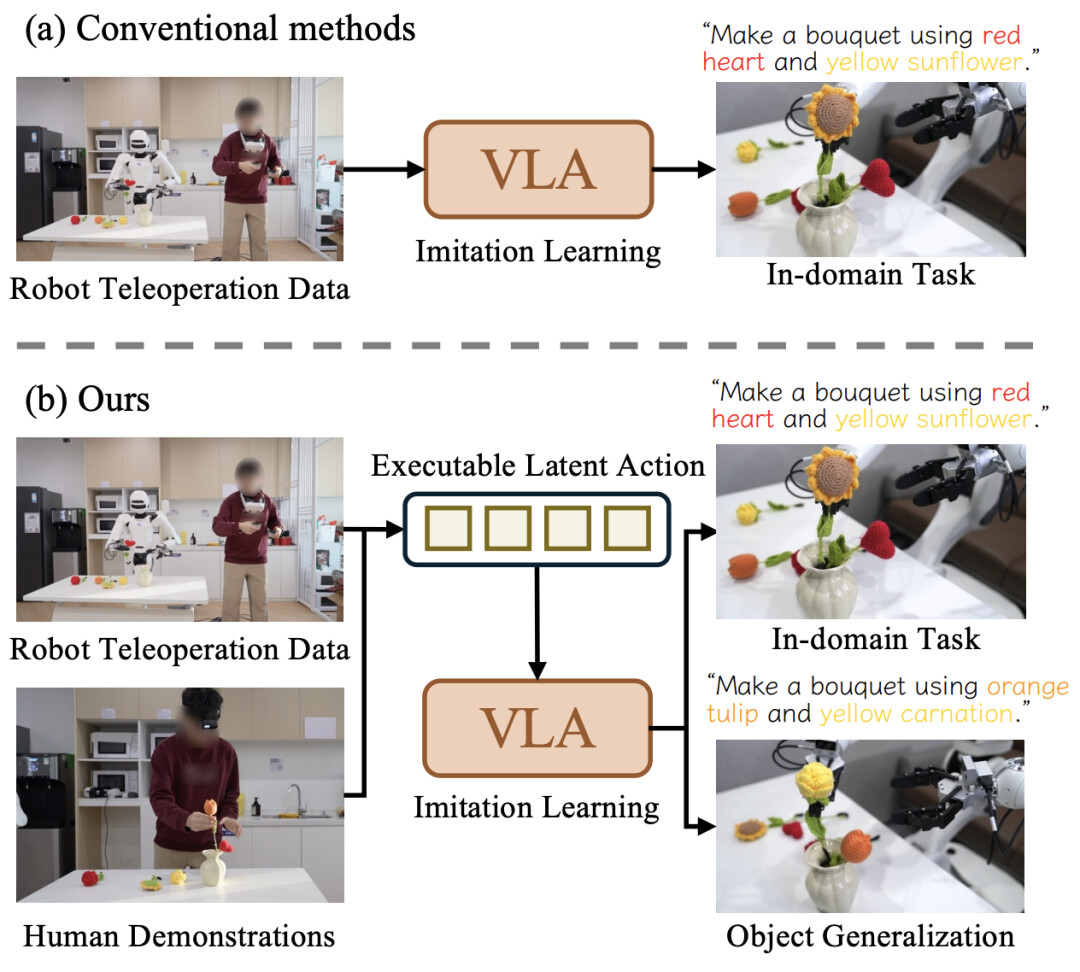
清华等提出CLAP框架,让机器人从视频学习技能,解决数据饥荒,加速产业化。
原文标题:让机器人看视频学操作技能,清华等全新发布的CLAP框架做到了
原文作者:机器之心
冷月清谈:
怜星夜思:
2、CLAP框架中提到的知识匹配(KM)正则化策略,对于防止灾难性遗忘至关重要。那么,在实际应用中,如何选择合适的KM正则化强度?过强和过弱分别可能带来什么问题?
3、CLAP框架目前主要关注的是机器人操作技能的学习,未来是否可以扩展到其他领域,例如,让AI通过观看教学视频学习绘画、音乐等艺术技能?
原文内容

近日,清华大学与星尘智能、港大、MIT 联合提出基于对比学习的隐空间动作预训练(Contrastive Latent Action Pretraining, CLAP)框架。这个框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,也就是说,机器人能够直接从视频中学习技能!
-
论文标题:CLAP: Contrastive Latent Action Pretraining for Learning Vision-Language-Action Models from Human Videos
-
论文地址:https://arxiv.org/abs/2601.04061
-
项目地址:https://lin-shan.com/CLAP/
引言
长期以来,机器人学习面临着一个令人头疼的「数据饥荒」难题:互联网上有着数以亿计的人类行为视频,但专门用于训练机器人的数据却寥寥无几。
这种数据不对称现象的根源在于,收集机器人操作数据需要昂贵的硬件设备、专业的操作环境,以及大量的人工标注工作,成本高昂且效率低下。相比之下,人类行为视频数据虽然丰富,但由于视觉表征与机器人动作空间之间存在巨大的语义鸿沟,传统方法难以有效利用这些资源。
现有的潜在动作模型(Latent Action Models)试图利用视频数据,但往往会遭遇「视觉纠缠」(visual entanglement)问题 —— 模型学到的更多是与实际操控无关的视觉噪声,而非真实的操控技能。
CLAP 框架的核心创新正是解决了这一长期困扰业界的技术瓶颈。该框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,有效避免了以往潜在动作模型中普遍存在的「视觉纠缠」问题。通过对比学习,CLAP 将视频中的状态转移映射到一个量化的、物理上可执行的动作码本上。
研究团队基于两种 VLA 建模范式进行训练:其一是 CLAP-NTP,一种自回归模型,在指令跟随与对象泛化方面表现突出;其二是 CLAP-RF,一种基于 Rectified Flow 的策略,面向高频率、精细化的操控。
这一技术突破的实际意义体现在多个层面。首先,从数据利用效率来看,CLAP 框架使得机器人能够从 YouTube、抖音等平台上的海量视频中学习技能,极大扩展了可用训练数据的规模。其次,从成本效益角度分析,这种「看视频学技能」的方式显著降低了机器人技能获取的门槛。
此外,该框架还解决了机器人学习中的一个关键技术挑战 —— 知识迁移问题。通过知识匹配(Knowledge Matching, KM)正则化策略,CLAP 有效缓解了模型微调过程中的灾难性遗忘现象,确保机器人在学习新技能的同时不会丢失已掌握的能力。
从产业应用前景来看,CLAP 框架的长期价值不仅在于技术创新,更在于其对机器人产业化进程的推动作用。当机器人能够通过观看视频快速掌握新技能时,企业部署机器人的成本和周期将大幅降低,这有望加速机器人在服务业、制造业等领域的规模化应用。
详解 CLAP 框架
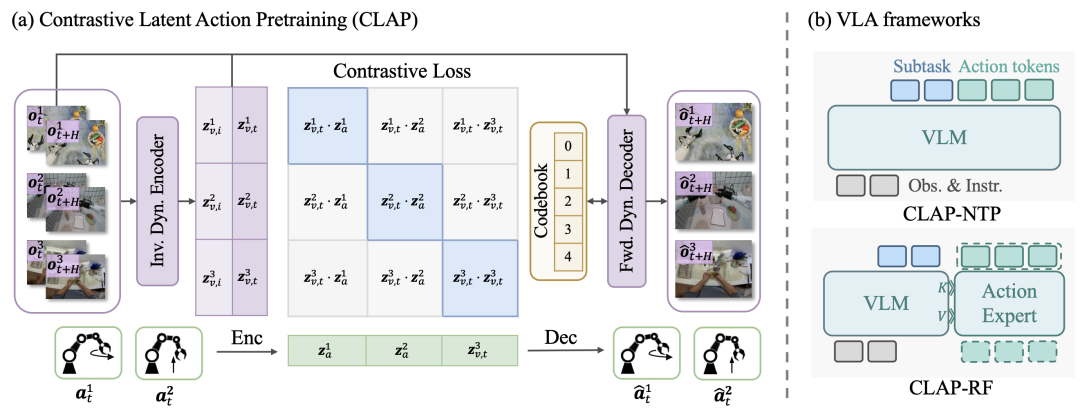
研究团队构建了一个统一的视觉 - 语言 - 动作(VLA)框架,使其能够同时利用机器数据的动作精确性与大规模无标注人类视频演示的语义多样性。框架分为两个相互衔接的阶段:
-
通过 CLAP 进行跨模态对齐:建立共享的潜在动作空间,弥合无标注人类视频与有标注机器人轨迹之间的监督缺口。该过程基于对比学习进行隐空间动作预训练(CLAP):它将人类视频中的视觉状态转移「锚定」到一个量化的、物理上可执行的动作空间中。
-
分层策略训练:研究团队通过连续训练两个 VLA 模型,将语义理解与控制动力学有效解耦:
-
CLAP-NTP:采用「下一词元预测」(Next-Token-Prediction)训练的 VLA,擅长指令跟随与任务规划;
-
CLAP-RF:包含一个 VLM 模型与一个采用 Rectified Flow 训练的动作专家,以实现高频、精确控制。
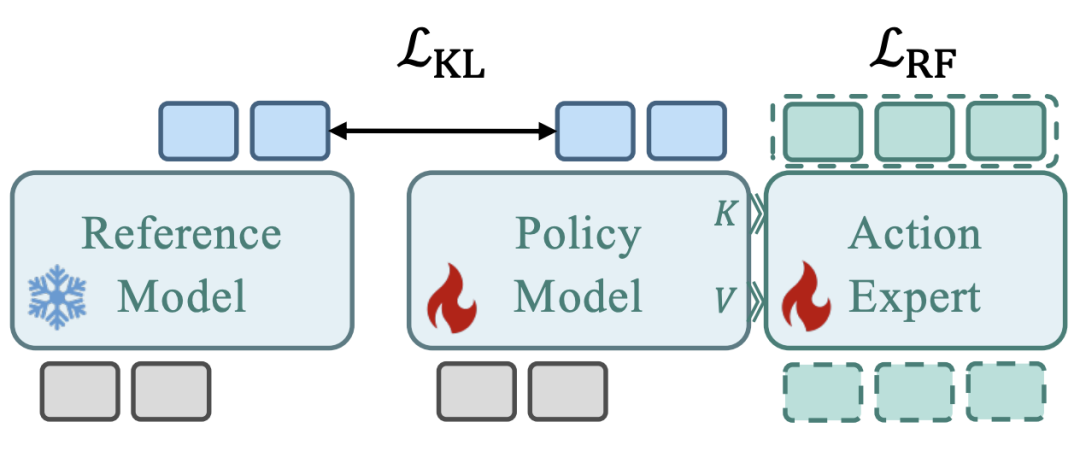
为高效适配新的本体形态并防止预训练先验在微调中发生灾难性遗忘,研究团队进一步提出知识匹配(Knowledge Matching, KM)微调策略:一种正则化方法,在微调过程中将策略更新锚定在可信区域内。
实验结果
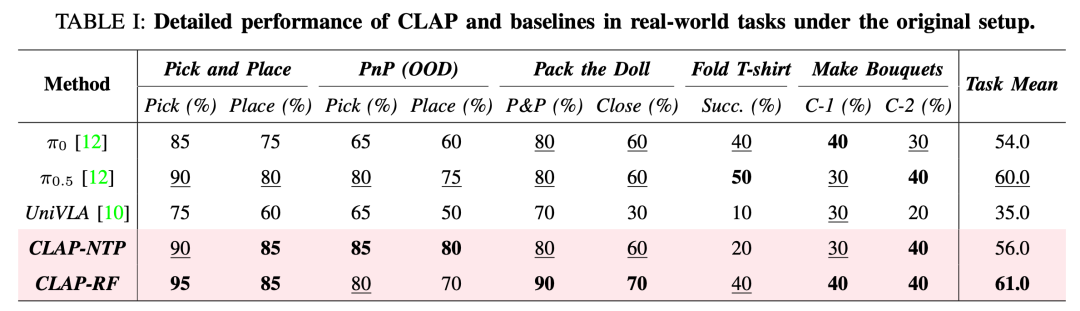
大量实验表明,CLAP 显著优于强基线方法,使得从人类视频中学习到的技能能够有效迁移到机器人执行中。
下表 1 为初始设置下,CLAP 与基线方法在真实世界任务中的性能比较。
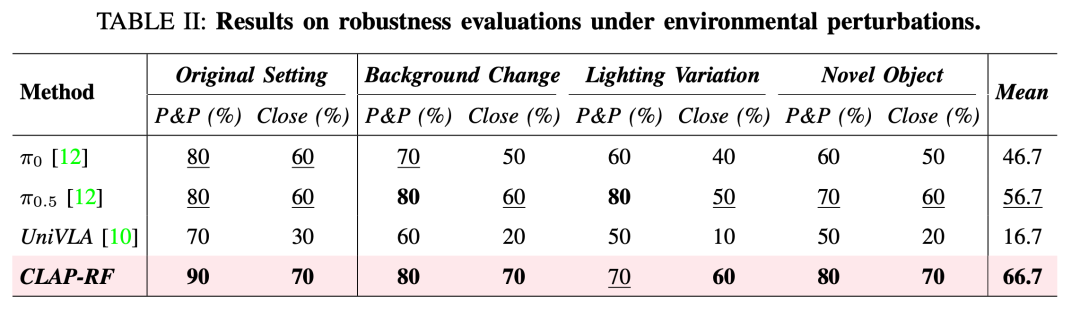
更多实验结果请参阅原论文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com