复旦大学推出OpenNovelty,一个基于LLM的可验证顶会论文查新系统,辅助审稿人评估论文创新性,提供可追溯的证据。
原文标题:你的论文有novelty吗?复旦搞了个顶会论文查新系统
原文作者:机器之心
冷月清谈:
怜星夜思:
2、OpenNovelty 强调可验证性,但如果系统判断错误的证据来源于一篇本身就存在问题的已发表论文,该如何处理?会否造成错误的“创新性不足”判断?
3、OpenNovelty目前主要应用于ICLR等AI顶会,未来是否有可能推广到其他学科领域?不同学科的知识结构和创新评价标准差异很大,OpenNovelty需要做哪些调整?
原文内容

ICLR 2026 的 Rebuttal 结束了。当 OpenReview 上的喧嚣散去,我们发现,作者与审稿人之间漫长的拉锯战,最终往往只剩下一个核心分歧:「这个想法,以前真的没人做过吗?」
Novelty(创新性)是学术评审中被高度关注的指标之一, 但其评估在实践中仍高度依赖评审者的经验判断与检索覆盖。随 arXiv 文献数量的快速增长,仅靠人工检索与记忆来追溯相关研究工作,已难以满足高效的评审需求。

针对这一挑战,复旦大学 NLP 研究团队与其此前孵化的学术搜索平台 WisPaper 展开合作,共同研发了 OpenNovelty——一个基于大语言模型、强调证据与可验证性的自动化新颖性分析系统。

-
论文标题:OpenNovelty: An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment
-
论文链接: https://arxiv.org/abs/2601.01576
-
Github 链接: https://github.com/january-blue/OpenNovelty
-
HuggingFace: https://huggingface.co/papers/2601.01576
-
官方网站: https://www.opennovelty.org
核心设计
OpenNovelty 的根本原则很简单:任何关于「该论文创新性不足」的判断,都必须附带可追溯的真实证据,这些证据必须来自于已发表的文献,并且能精确定位到原文具体段落。若系统未能找到相关证据,则如实说明「未发现支持该判断的证据」。
与传统查重仅关注文字表层重叠不同,OpenNovelty 试图解决语义层面的重复。 系统会对投稿进行结构化抽取,将作者表述转写为更便于检索与对比的学术概念短句,自动提取出论文的一个核心任务(Core Task)和若干具体贡献(Contributions)。
此外,系统还采用了「查询扩展(Query Expansion)」机制,针对提取出的每条信息,生成多个语义等价的变体,在 WisPaper 的索引库中进行地毯式检索,防止单一表述带来的检索遗漏。
四步分析流程:
从论文提交到生成
可验证的新颖性评估报告
第一步:核心信息提取
系统从论文的标题、摘要和引言,精准地提取出两类信息:
-
核心任务:论文拟解决的核心学术问题(例如:「基于多轮强化学习的 LLM 智能体长周期决策训练」);
-
贡献声明:作者明确宣称的创新点,如新方法、框架、算法或理论形式化(例如:「一个支持多种强化学习算法的统一训练框架」)。

第二步:相关文献检索与筛选
基于提取的信息,系统自动生成一组学术搜索语句(包括同义词及变体表达,避免因措辞差异而遗漏相关文献),然后利用 WisPaper 学术引擎展开地毯式搜索。
初步检索可能召回数百至上千篇潜在相关论文,随后通过去重、时间过滤与筛除弱相关性文献等步骤,最终形成约 60–80 篇用于后续分析的候选论文集合。
第三步:层次化分析与证据比对
这是系统的核心分析环节。系统会基于核心任务召回的候选论文构建层次化 taxonomy(树状分类体系),以呈现目标论文在相关研究脉络中的位置。提供目标论文在候选研究脉络中的相对定位,供评审者快速浏览。
针对每条贡献声明,系统会在贡献召回的候选论文集合中进行逐篇对比,并尝试给出可核验的对应证据片段。比对的结果有如下三种:
-
能反驳(can_refute):找到已发表的论文具有相似贡献,必须附带双方论文的原文摘录作为证据。
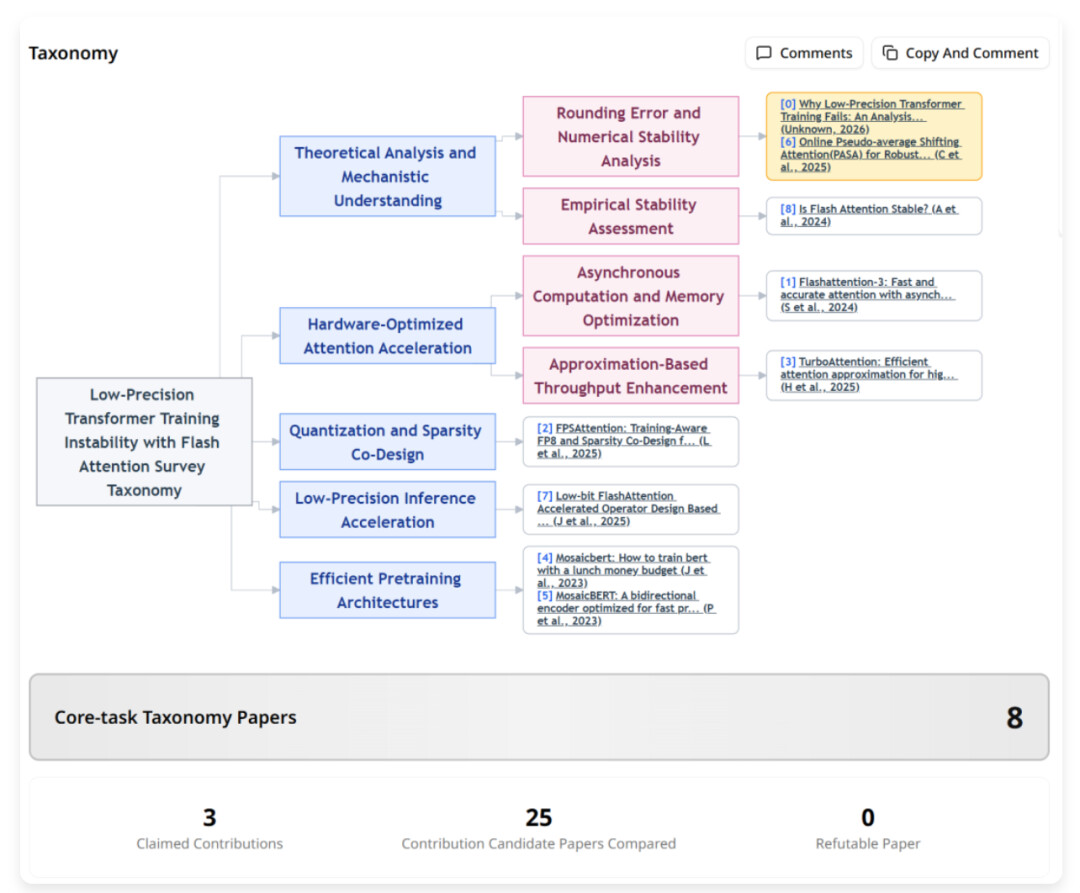
-
无法反驳(cannot_refute):在当前检索范围内,未发现可质疑该创新贡献的文献。
-
存疑(unclear):信息不足,无法判断。
关键在于:如果系统做出「能反驳」的判断,但其提供的证据(即摘录段落)无法在原论文中找到或匹配度过低,该判断会自动降级为「无法反驳」。
第四步:「新颖性调查报告」生成
系统整合前三阶段结果,生成包含以下模块的评估报告:
-
论文的核心任务
-
研究领域的分类体系
-
每条创新声明的比对结果和证据
-
综合的「新颖性评估」叙述
对于系统给出的关键判断,报告会尽量提供可追溯的候选文献与可核验的原文证据位置,便于评审者快速定位与人工复查。

系统部署与公开验证
截止到 1 月 16 日,团队已经在系统上分析了 1360 篇投稿,并且把所有生成的新颖性报告公开发布在其官方网站。任何人都可以查阅系统对某篇投稿的分析结果、检索到的相关文献以及判断依据。
团队计划进一步将分析规模扩展至 2000+ 篇投稿,此外,还将持续优化系统,计划将其应用于其他 AI 顶级会议,并对所收集的报告和评审证据进行深入分析。
OpenNovelty 的影响
对审稿人而言:它是一个辅助工具而非替代。系统可以帮助评审者梳理文献脉络,快速掌握一篇论文在领域中的位置,从而将更多精力集中于更需要人类专业判断的关键环节,如研究意义、方法严谨性等问题。
对论文作者而言:它可作为投稿前的自查工具。如果研究具备实质创新性,系统可以提供相关证据;如果漏引了重要文献,系统亦能指出问题。
对学术界而言: 该系统提供了一种“可验证的新颖性评估”工程路径——用检索到的真实文献与贡献级证据对比来约束结论输出,让判断能够被追溯与复核,而不是停留在模型的无证据生成。推动 AI 成为负责人的知识引证者,而非不可靠的内容生成器。
仍需人类判断
团队在论文里也明确指出了系统的局限性:
-
难以理解复杂的数学公式和图表——如果一篇论文的核心创新藏在一个复杂的方程式里,系统可能会错过;
-
只能搜到被索引过的论文,可能错过未被收录的小众期刊或非英语出版物;
-
「无法反驳」仅表示在「检索范围内未找到」,并不等于「确实不存在」。
因此,团队一再强调:这是辅助工具,而非决策主体。最终的学术判断,仍然要由人类审稿人完成。
结语
OpenNovelty 的出现带有某种实验性的克制。它并非试图取代现有的同行评审体系,而是作为一套第三方审计系统介入。在 Rebuttal 结束后的最终决策阶段,它负责清洗迷雾,向 AC 展示那些被淹没的证据,而将最终的价值判断权留给人类。
目前,ICLR 2026 的部分论文查新报告已在 OpenNovelty 官网开放查阅。对于即将在明年继续冲击顶会的科研人员来说,这或许是一个审视自己工作的新鲜视角。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com