华东师大提出APN框架,通过自适应Patch聚合实现IMTS预测精度与效率双优,超越现有SOTA模型。
原文标题:极简却超强:华东师大 APN 打破 IMTS 预测的 SOTA 垄断
原文作者:数据派THU
冷月清谈:
APN的核心优势在于其简洁的设计和高效的性能。它避免了插值操作,直接基于原始观测进行聚合,减少了噪声引入。同时,自适应的Patching策略使模型能够根据数据的疏密程度调整“视野”,更好地适应不规则数据的特点。此外,APN的后端采用简单的Query机制和MLP进行预测,进一步提高了计算效率。消融实验也验证了TAPA模块中自适应Patching和加权聚合的重要性,二者共同保证了APN在不规则时间序列预测中的有效性。
该研究表明,在处理不规则时间序列时,高质量的特征工程比复杂的模型结构更为重要。APN为相关领域的研究者提供了一个强大而易于实现的Baseline。
怜星夜思:
2、APN模型强调避免插值,直接在原始观测上进行聚合。那么,这种做法在哪些场景下会失效?例如,如果数据缺失过于严重,或者数据噪声非常大,APN模型还能保持其优势吗?
3、APN模型在效率方面表现出色,这是否意味着它更适合部署在边缘设备或资源受限的环境中?在这些场景下,如何进一步优化APN模型,以满足更苛刻的性能要求?
原文内容

本文约2000字,建议阅读5分钟本文介绍了 APN 框架,以自适应 Patch 聚合实现 IMTS 预测精度与效率双优。
在多变量时间序列预测领域,不规则采样(Irregular Multivariate Time Series, IMTS) 一直是一个棘手的难题。由于医疗、气象等数据的采集往往伴随着非均匀的时间间隔和缺失值,传统的固定 Patch 策略往往难以奏效。
本文介绍一篇来自华东师范大学团队的最新工作 APN,目前已被AAAI 2026 Oral接收。作者重新审视了不规则时间序列预测,提出了一种基于自适应 Patch 聚合(Adaptive Patching) 的通用框架。该模型不依赖复杂的 ODE 求解器或繁重的图神经网络,而是通过学习动态的 Patch 边界和“软聚合”策略,直接从原始观测中提取特征。仅需简单的 MLP 解码器,APN 就在多个真实数据集上超越了 GraFITi、tPatchGNN 等SOTA模型,实现了精度与效率的双重提升。

【论文标题】
Rethinking Irregular Time Series Forecasting: A Simple yet Effective Baseline
【论文地址】
https://arxiv.org/abs/2505.11250
【论文源码】
https://github.com/decisionintelligence/APN
核心痛点:固定Patch的局限性
随着 Transformer 在时序领域的爆发,Patching(分块)技术几乎成为了标配。然而,将 Patching 直接应用到不规则时间序列(IMTS) 上,面临着两大挑战:
-
信息密度不均(Uneven Information Density):如图1(a) 所示,采用固定长度划分 Patch 时,有的Patch可能包含大量冗余数据,而有的 Patch 可能几乎没有观测值。这导致特征提取极不稳定。
-
语义截断(Inappropriate Segmentation):硬性的切分可能会将连续的重要动态变化切断,破坏了语义的完整性。
此外,现有的 IMTS 模型(如Neural ODEs、GNNs)往往计算开销巨大,难以满足即时预测的需求。
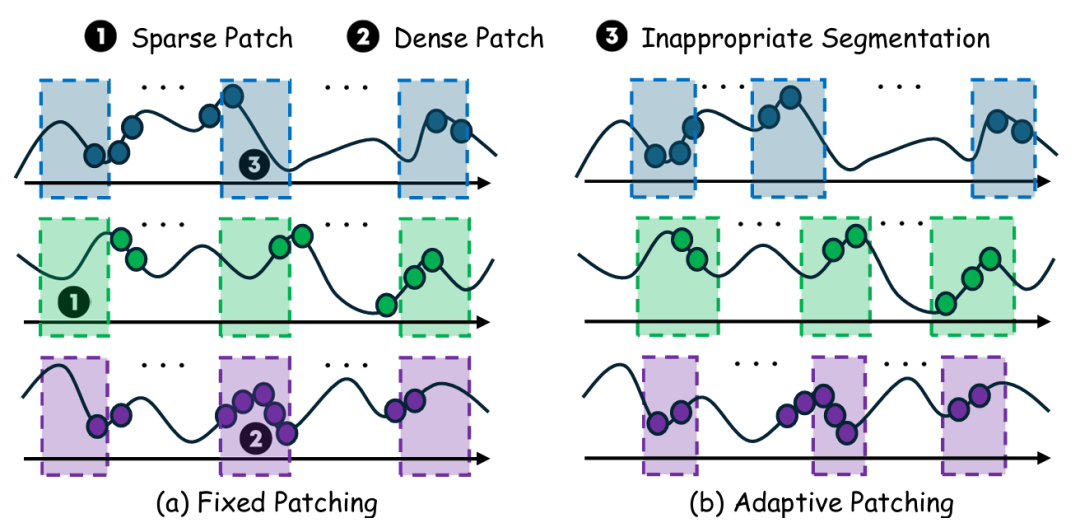
图1:固定Patch vs 自适应Patch
APN框架:大道至简
为了解决上述问题,作者提出了 APN (Adaptive Patch Network)。其核心设计理念是:将处理不规则性的复杂工作前置,生成高质量的规则化Patch表示,从而允许后端使用极简的网络结构。
APN 的整体架构如图2所示,主要包含两个阶段:
-
时间感知 Patch 聚合(TAPA):负责将不规则序列转换为规则的 Patch 序列。
-
上下文聚合与预测:利用简单的 Query 机制和 MLP 进行预测。
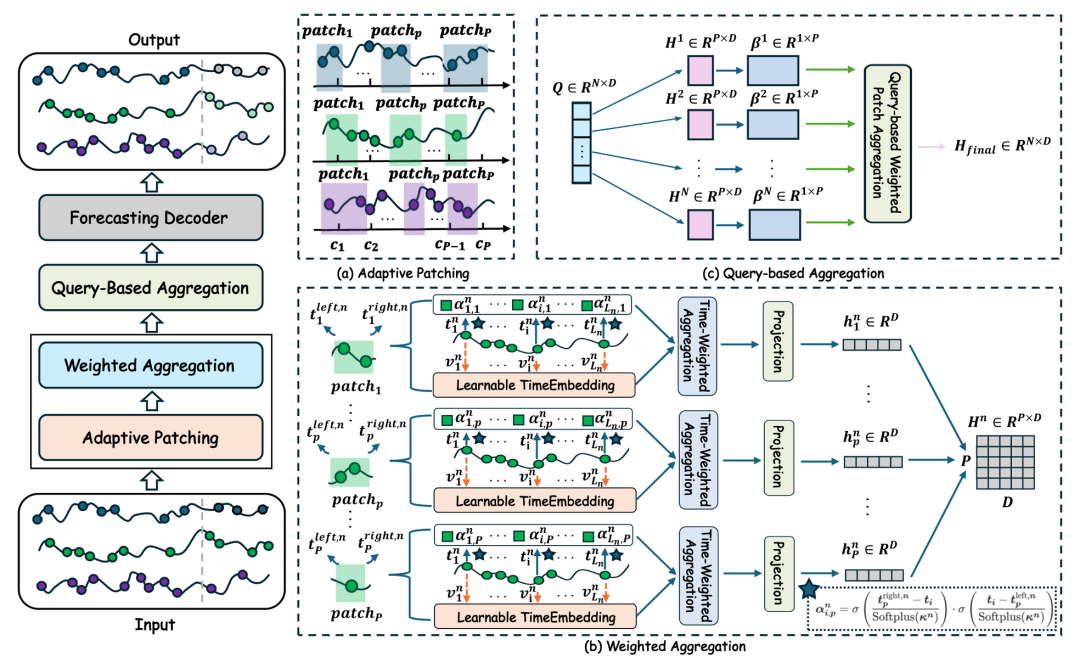
图2:APN整体框架图
01、核心创新:TAPA模块
TAPA(Time-Aware Patch Aggregation)是 APN 的灵魂,它包含两个关键步骤:
1. 自适应Patching
APN不再使用固定的时间窗口,而是为每个Patch 学习一个动态的时间窗口 。
-
模型学习两个参数:位置调整量 和宽度参数 。
-
通过这种方式,模型可以自动调整窗口大小:在数据稀疏区域“扩大视野”以捕获足够信息,在数据密集区域“聚焦细节”以减少噪声。
2. 加权聚合
这是 APN 与基于插值方法最大的不同。APN 不进行插值,不生成虚假数据点,而是采用软窗口机制。
-
利用 Sigmoid 函数生成平滑的权重曲线。
-
每个原始观测点 根据其与 Patch 中心的时间距离,被分配一个权重 。
-
通过加权平均,直接聚合原始观测值生成 Patch 表示。
这种设计保证了全数据覆盖。即使某个观测点位于两个 Patch 的边界之间,由于是软权重,它依然能对周围的 Patch 产生贡献,避免了硬切分带来的信息丢失。
02、极简后端:Query & MLP
经过 TAPA 处理后,不规则序列变成了一组规则的向量 。后续处理非常高效:
-
Query-based Aggregation:引入一个可学习的 Query 向量,计算所有 Patch 的加权和,提取全局上下文。
-
Forecasting Decoder:一个简单的双层 MLP,直接输出预测结果。
实验结果
作者在四个主流IMTS数据集(PhysioNet, MIMIC, HumanActivity, USHCN)上进行了广泛实验。
01、预测精度
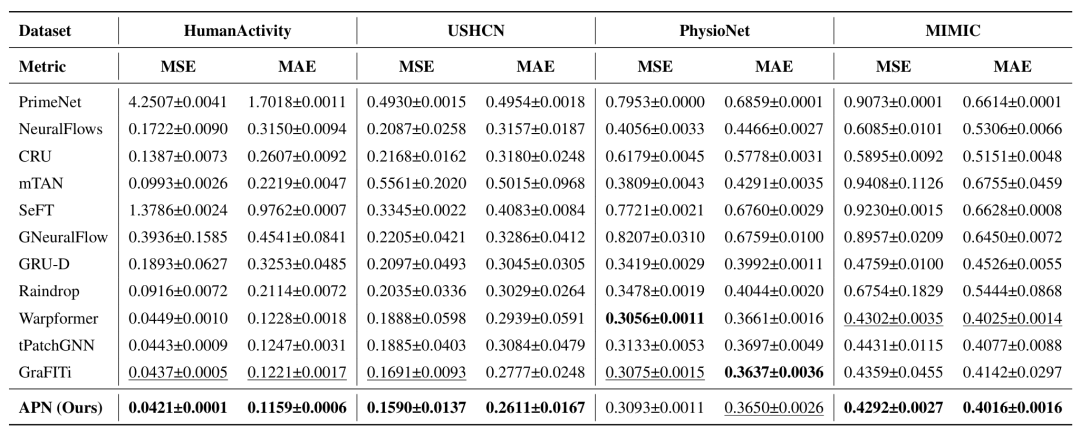
表1:四个数据集上的MSE/MAE对比
如上表所示,与包括 NeuralFlows, GraFITi, tPatchGNN 在内的11个基线模型相比:
-
APN 在所有数据集上均取得了最佳性能。
-
相比第二名(通常是 GraFITi),MSE 和 MAE 分别降低了约 2.64% 和 3.61%。
-
这证明了自适应 Patch 比复杂的图网络或 ODE 更能有效捕获不规则时序的特征。
02、效率分析
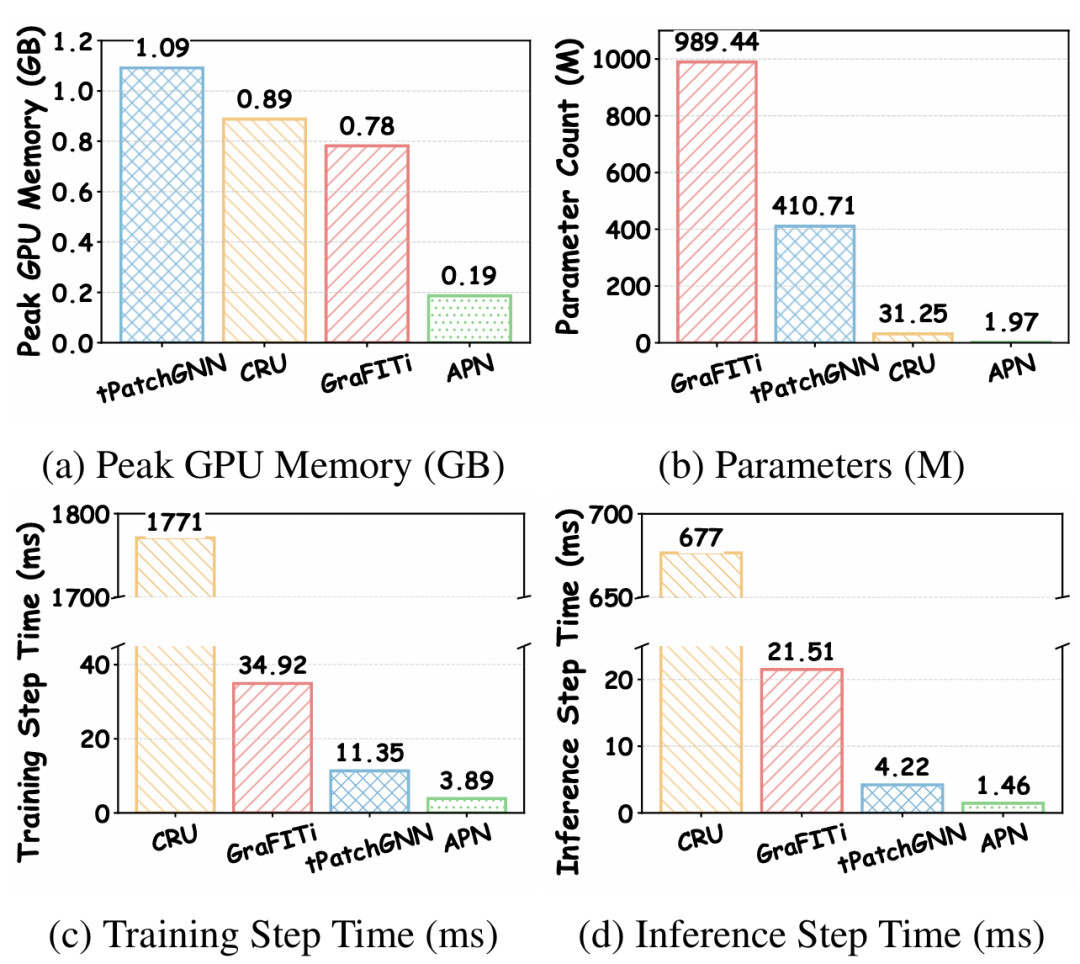
图4:计算效率对比(显存、参数量、训练时间、推理时间)
上图展示了在 USHCN 数据集上的效率对比。结果非常惊人:
-
训练速度:APN 比 GraFITi 快数倍,比基于 ODE 的方法快更多。
-
显存占用:极低,适合资源受限环境。
-
参数量:保持在极低水平(M级甚至更小)。
03、消融实验
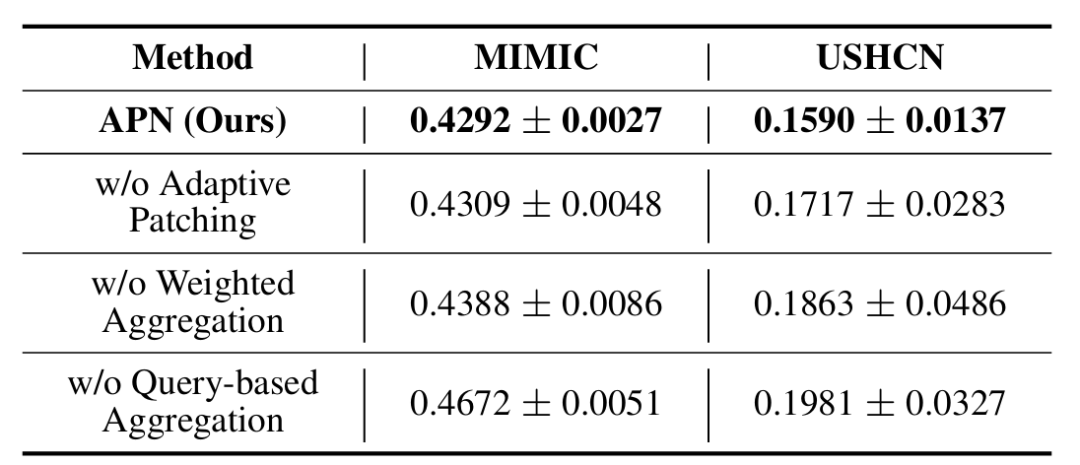
表2:APN(MSE)的消融研究
消融实验证实了 TAPA 模块的重要性:
-
去掉 Adaptive Patching(退化为固定窗口),性能显著下降。
-
去掉 Weighted Aggregation(退化为硬切分平均),性能同样受损。
-
这说明动态调整窗口和软聚合是 APN 成功的关键双因子。
总结
APN 可以说是一篇“奥卡姆剃刀”式的论文。在大家都倾向于堆叠复杂模块(ODE、GNN、Transformer)来处理不规则时间序列时,APN 指出了问题的本质:不是模型不够深,而是数据切分方式不对。
APN的核心贡献在于:
-
拒绝插值:直接基于原始观测进行聚合,避免了插值带来的噪声。
-
动态视野:让模型自己学习“看哪里”和“看多宽”,完美适配不规则数据的密度变化。
-
极致高效:证明了简单 MLP 配合良好的特征工程(TAPA),完全可以打败复杂的 SOTA 模型。
对于正在处理医疗数据、稀疏传感器数据的研究者来说,APN 提供了一个非常强力且易于实现的 Baseline,值得一试。
编辑:于腾凯
校对:刘茹宁
