阿里云发布 UModel,为可观测性打造认知操作系统,弥合数据、模型和工程鸿沟,助力 AIOps 落地。
原文标题:阿里云全新发布的 UModel 是什么
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章中提到了 UModel 的三种图查询能力:graph-match、graph-call 和 Cypher。你认为这三种查询方式分别适用于哪些场景?你更倾向于使用哪一种?为什么?
3、UModel 被称为可观测性的'认知操作系统',你如何理解这个概念?你认为 UModel 的发展,未来会对 AIOps 产生哪些影响?
原文内容

要回答这个问题,我们先简单回溯下:IT 系统的可观测体系是如何走到今天的?
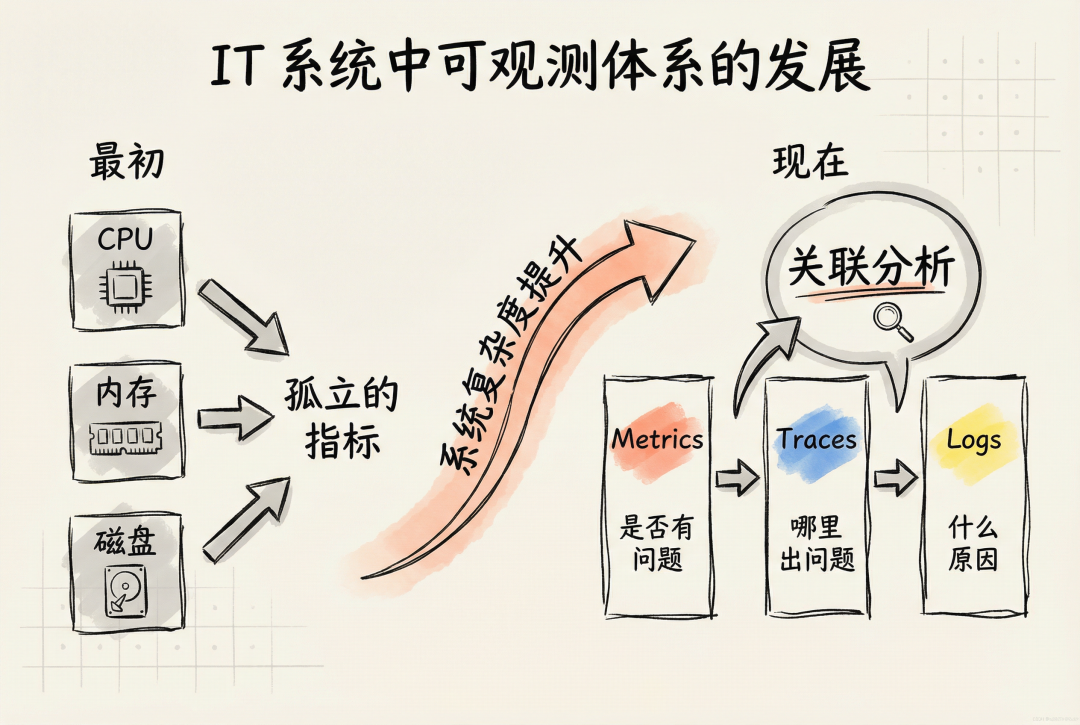
一、IT 系统中可观测体系的发展
最初,企业面向单一数据类型构建监控体系,CPU 使用率、内存占用、磁盘 I/O……一个个孤立的指标就像烽火台,只能通过局部视角告诉我们“什么地方出了问题”。
但随着微服务、容器技术的普及,系统复杂度呈指数级增长。企业开始意识到:单点指标无法解释全局。于是开始对孤立的数据进行抽象,抽象出 Metrics(指标)、Traces(链路追踪)和 Logs(日志),并进行关联分析:
-
Metrics:IT 系统是否有问题;
-
Traces:哪里出了问题;
-
Logs:问题是由什么原因导致的。
发展至今,成为观测体系的三大数据支柱。
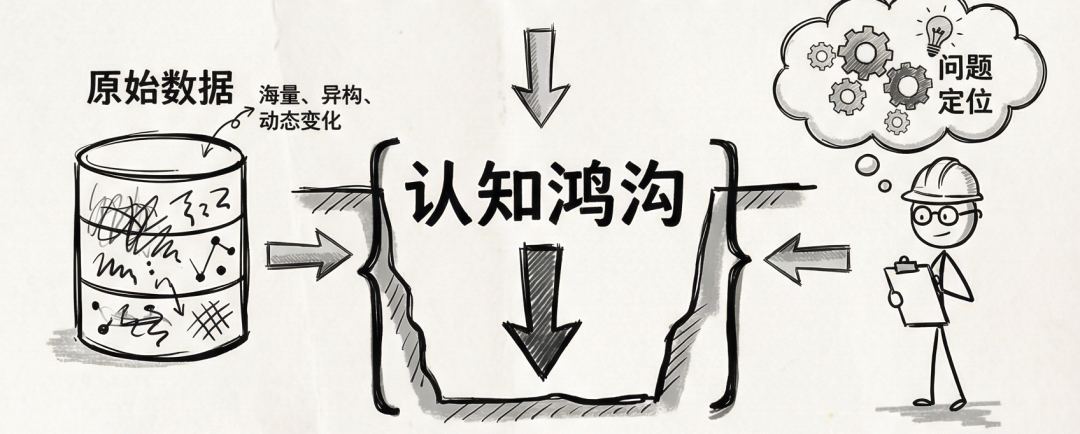
但从海量、异构、动态变化的数据中准确推理并定位问题,本质上是一个极其困难的逆向工程。数据只是现象,而现象与本质之间往往存在巨大的认知鸿沟。
Metrics、Traces 和 Logs 这看似完整的三角,实则仍停留在现象观测层面,是 L1 级智能体的典型工作流,人工设计流程节点、人工配置触发、人工调用 API,再把指标、链路、日志喂给 AI,期望它自己找出因果,结果往往是幻觉式归因:把时间上的巧合当作逻辑上的因果。为什么?因为在 AI 面前,缺少对系统本质的建模。
在 AI 时代,加剧了这种模式的挑战。一是 LLM 驱动的应用带来了上下文的碎片化。运维工程师每天要在不同的控制台之间切换,手动拼凑“发生了什么”。这就像在信息高速公路上骑自行车,工具很先进,但认知方式仍是人力驱动。二是相比由工程师写的代码定义的传统 IT 系统,AI 带来了更多的不确定性,指数级提升了原始数据自动化关联的难度,给准确推理并定位问题的挑战添了堵。
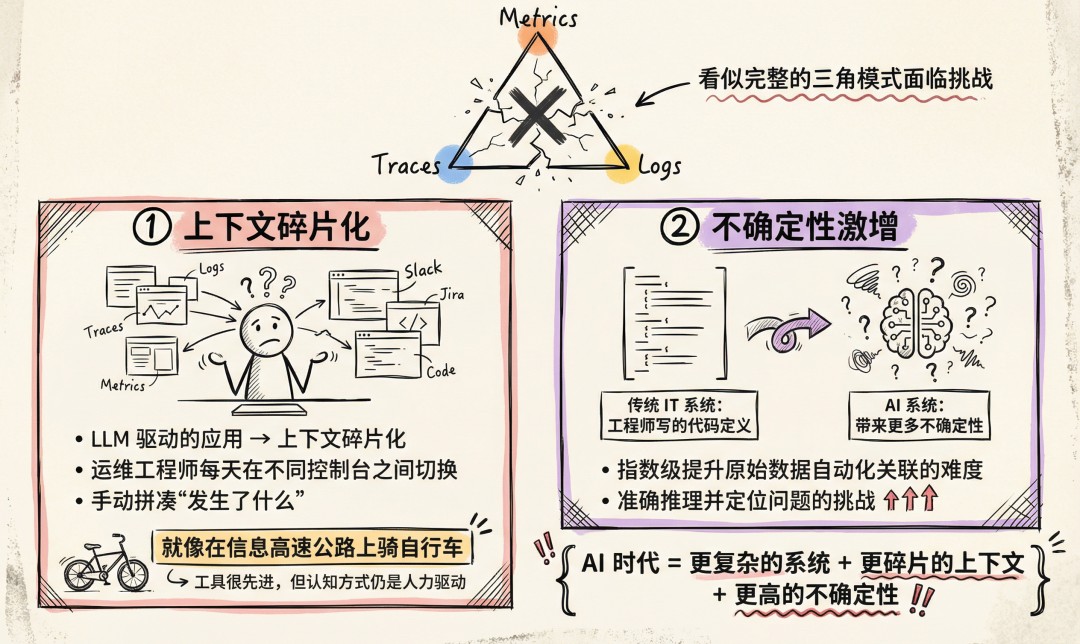
总结起来,原本的认知鸿沟,被进一步分化成三层新的鸿沟:
-
数据鸿沟:原始数据混杂、碎片化、噪声多,99% 以上可能是无效信息,难以从中有效提取信号。
-
模型鸿沟:AI 模型存在“黑盒”特性,推理过程难以解释;还可能出现“幻觉”,生成看似合理但不符合事实的结果。
-
工程鸿沟:每天数 PB 级的数据采集、清洗、存储、计算,对性能、成本、安全性提出极高要求。
二、数据到建模
让一个没见过电路图的人,从一堆电压表读数中定位并恢复故障服务器,是不现实的。
当前市面上大多数的 AI 运维助手,本质上仍是 L1 级智能体:它们被封装在一个封闭的对话框里,被动响应用户提问,背后是一连串预设的 if-else 规则或简单 RAG 检索。它们没有对系统结构的内生理解,无法主动推理依赖路径,更谈不上安全执行修复操作。
而要迈向 L2 甚至 L3 级智能体,即能自主感知、规划、行动并持续学习的数字员工,就必须为其构建一个结构化的运行时上下文,不然只能靠人的经验来排查、定位和解决问题。这个上下文是经过建模、带有语义、支持查询与推理的图谱。有了这张图,智能体就能避免在数据海洋中盲目打捞,而是在一个有路标、有规则、有边界的城市中穿行。
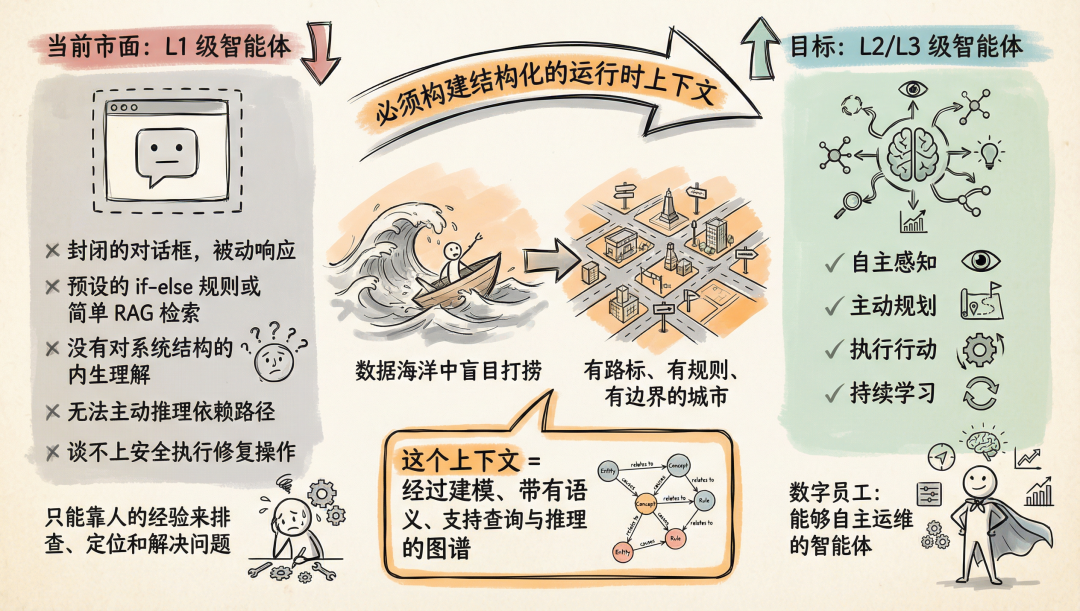
因此,出路不在更多的数据,而在更好的建模。先为 IT 系统建立一张认知地图。这张图要包含实体(主机、服务、数据库)、关系(调用、依赖、部署)、行为(日志事件、性能指标)以及它们之间的语义约束。只有在这张图上,智能体才能像经验丰富的老运维一样,快速定位故障并恢复生产。
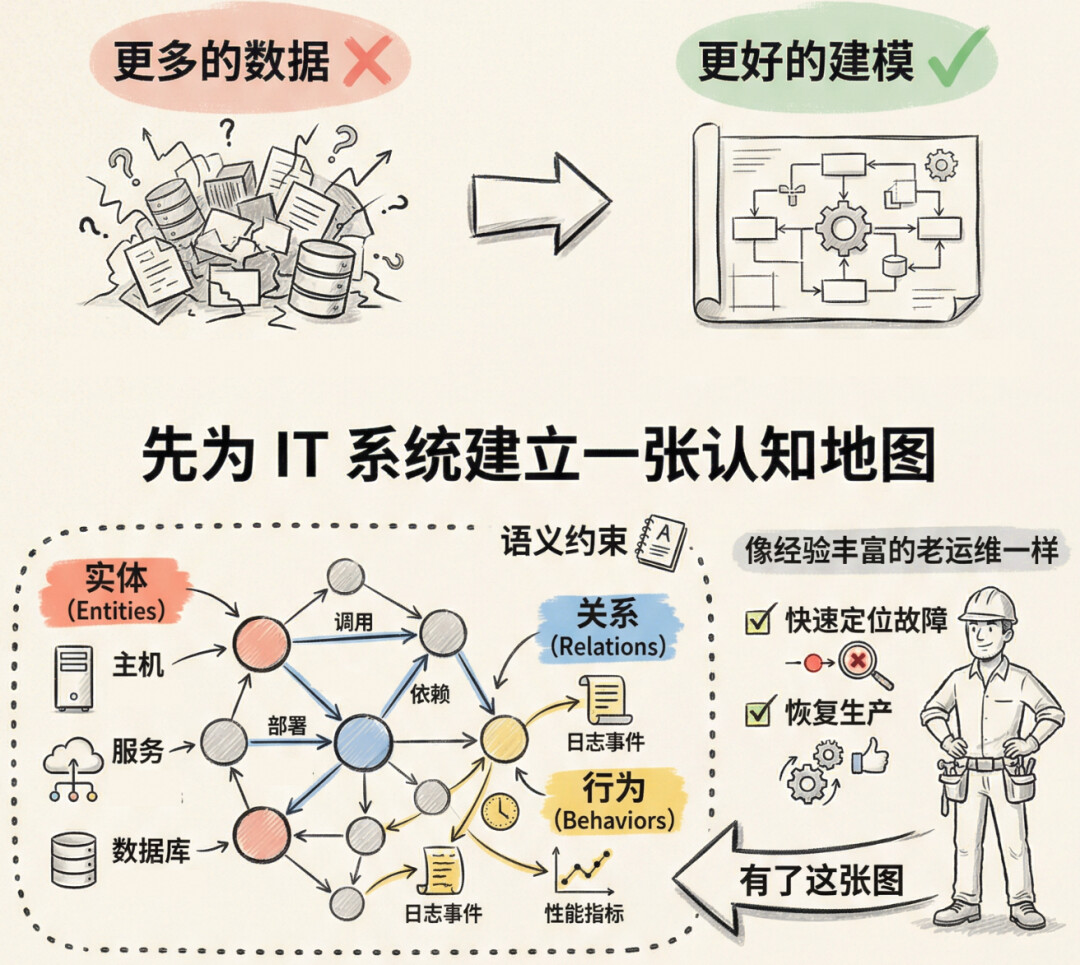
UModel 正是这张图的建模语言。我们需要从“数据驱动”转向“建模驱动”,从面向现象的观测,转向面向本质的建模,构建一个统一的上下文图谱,这正是 UModel 的使命。
三、什么是 UModel
UModel(Universal Observability Model)是基于图模型的可观测数据建模方法。
又是图模型,又是建模,一听就很学术。通俗易懂的讲,就是用“画图”的方式,把一堆随机事件之间的概率关系理清楚,让复杂变简单,让模糊变清晰。因此,UModel 旨在通过标准化的数据建模方式,实现可观测数据的统一表示、数据建模与具体存储的解耦,从而实现智能分析。有了 UModel,智能体才能像经验丰富的老运维那样快速定位故障并恢复生产,成为可能。UModel 可以看成是阿里云可观测体系的数据建模基础。
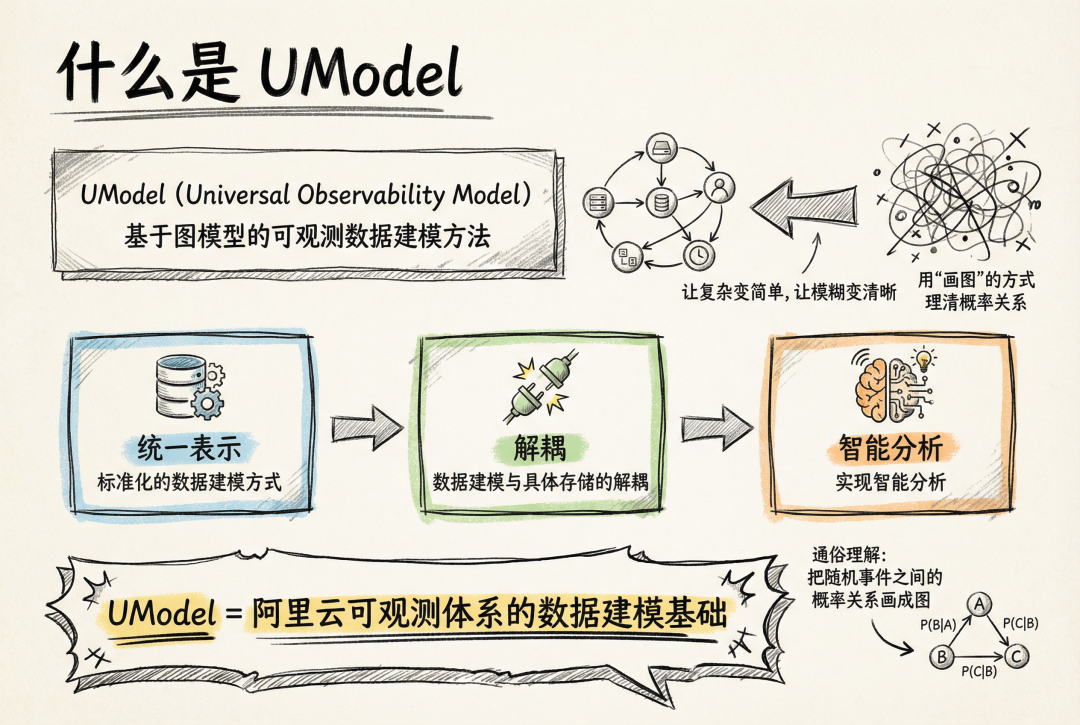
总的来讲,UModel 的核心思想,是为可观测领域打造一个认知操作系统,是一套标准化的数据建模方法,旨在弥合前文所述的三重鸿沟,为 AIOps 提供可解释、可扩展、可自动化的基础。
接下来,我们从 UModel 的构成和使用方式来看看它是如何把零散、杂乱的可观测数据,画成一张结构清晰、智能体能理解的图。
四、UModel 的构成和使用方式
企业习惯于将系统中的每个组件,例如应用、容器、中间件、网关、数据库,视为独立的实体进行监控和管理,并为它们配置仪表盘,设置告警,追踪性能表现。传统的监控和查询工具,无论是基于 SQL 还是 SPL,其核心都是处理二维的、表格化的数据。它们擅长回答关于个体的问题(这个 Pod 的 CPU 使用率是多少?),但在回答关于关系的问题时却显得力不从心。
当面对“这个服务的故障会影响哪些下游业务?”或“要访问到核心数据库,需要经过哪些中间服务?”这类问题时,传统工具往往需要复杂的 JOIN 操作、多步查询,甚至需要工程师结合线下架构图进行人脑拼凑。这种方式不仅效率低下,而且在关系复杂、层级深的情况下几乎无法完成。我们拥有了所有“点”的数据,却失去了一张看清“线”的地图。
因此,UModel 将要解决以下四个关键问题:
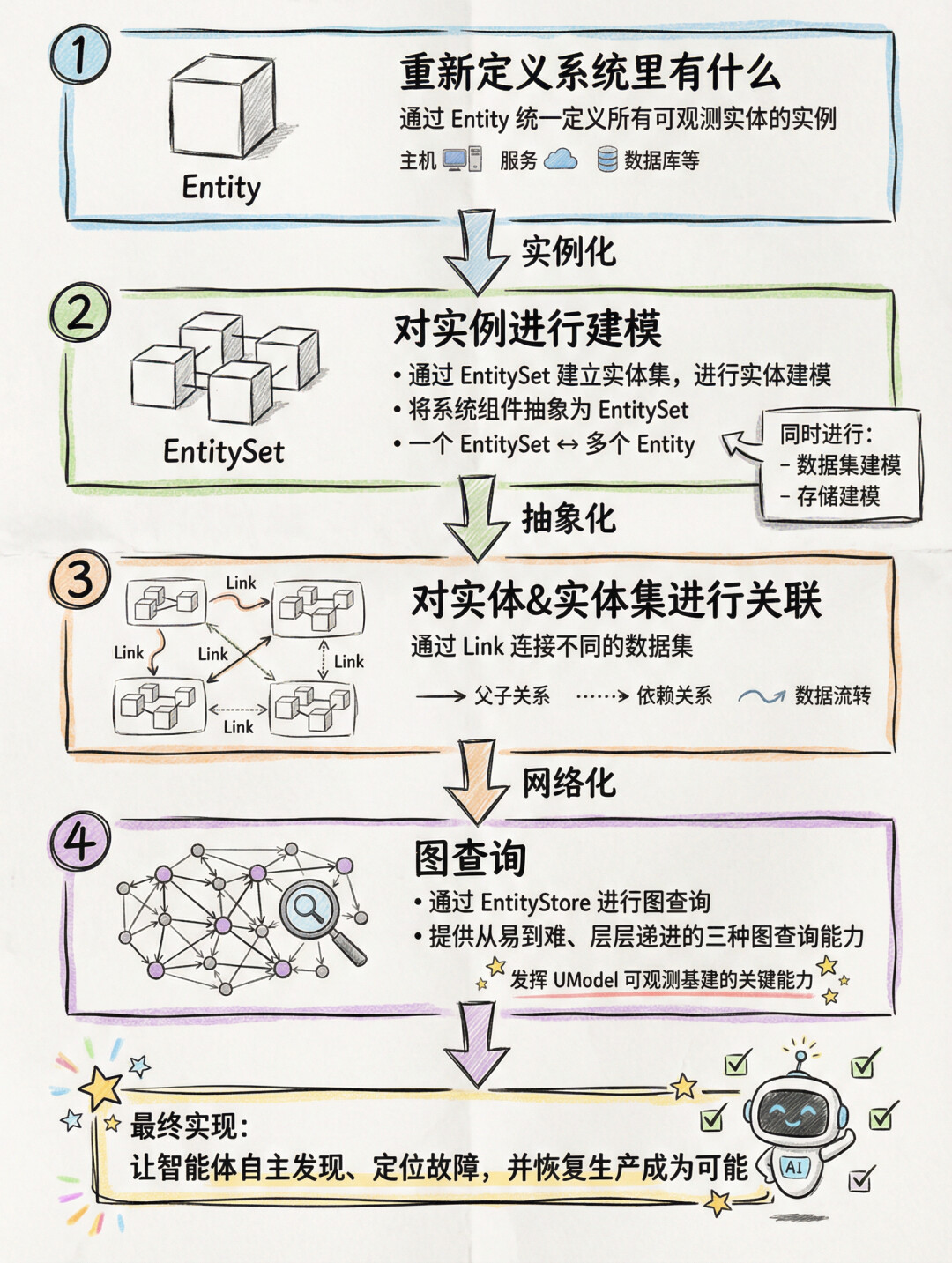
1. 重新定义系统里有什么
通过 Entity 来统一定义所有可观测实体的实例,包括容器实例、服务实例等,例如服务实例 "order-service"、Pod 实例 "web-pod-001"。
2. 对实例进行建模
通过 EntitySet 建立实体集,并进行实体建模。将系统组件抽象为 EntitySet,一个 EntitySet 可对应多个 Entity:
-
基础设施实体:主机、容器、网络设备、存储系统;
-
应用层实体:微服务、API 接口、数据库实例、消息队列;
-
业务实体:用户会话、业务流程、交易订单;
-
运维实体:部署环境、代码仓库、运维人员。
除了进行实体建模,还需要进行:
-
数据集建模:将日志、指标、链路追踪、事件和性能剖析等多种可观测数据类型抽象为 TelemetryDataSet,由此衍生出 LogSet、TraceSet、EventSet、ProfileSet、MetricSet 等更具体的观测数据集。
-
存储建模:Storage 是 UModel 中数据集底层存储的抽象,定义了数据的实际存储位置和访问方式。通过存储建模,UModel 能够统一对接多种存储后端,为用户提供一致的数据访问体验。
3. 对这些实体&实体集进行建联
通过 Link,连接不同的数据集:
-
EntitySetLink 定义 EntitySet 实体间的关系(如服务 A 调用服务 B);
-
DataLink 定义 EntitySet 与 DataSet 之间的关联(如某 Pod 产生哪些日志);
-
StorageLink 定义 DataSet 与 Storage 之间的关联。
在此基础之上,自动生成实体拓扑图和数据关系图。
4. 图查询
图查询可以认为是发挥 UModel 这一可观测基建的关键能力。因为系统的真实形态本就是一张图,那么对它的查询和分析,也应该使用最符合其本质的方式——图查询。
为了实现这一点,我们在 UModel 体系的核心构建了 EntityStore。它采用了创新的双存储架构,同时维护了 __entity__ 日志库(存储实体的详细属性)和 __topo__ 日志库(存储实体间的拓扑关系)。这相当于我们为整个可观测系统建立了一个实时更新的、可查询的数字孪生图谱。
基于这个图谱,我们提供了从易到难、层层递进的三种图查询能力,以满足不同用户的需求:
-
graph-match:为最常见的路径查询场景设计,语法直观,让用户能像描述一句话一样(“A 经过 B 调用了 C”)来快速查找特定链路。
-
graph-call:封装了最高频的图算法(如邻居查找、直接关系查询),通过函数式接口提供,用户只需关心意图(“找 A 的 3 跳邻居”)而无需关心实现细节。
-
Cypher:引入业界标准的图查询语言,提供最完整、最强大的图查询能力,支持任意复杂的模式匹配、多级跳跃、聚合分析,是处理复杂图问题的终极武器。
这一整套解决方案,旨在将强大的图分析能力,以一种低门槛、产品化的方式,让智能体实现自主发现、定位故障,并恢复生产成为可能。
过去,运维靠人脑串联孤立的数据和几十个工具;未来,UModel 希望能作为可观测的基础设施,支撑智能体在统一上下文图谱中工作。当可观测数据被建模为可理解、可行动的上下文图谱,AIOps 才真正拥有了落地的土壤。