DeepSeek 发布 Engram,为大模型引入条件记忆,显著提升知识和推理能力,并有效降低计算成本。
原文标题:DeepSeek 发布全新论文,一文读懂 Engram!
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、论文中提到,Engram 承担了早期层对静态模式的重建工作,从而提升了模型的"有效深度"。你如何理解"有效深度"这个概念?它对大模型的性能有何影响?
3、DeepSeek 计划在 V4 模型中使用 Engram 技术,你认为这项技术会对 V4 模型的哪些方面带来提升?你对 DeepSeek V4 有哪些期待?
原文内容
在大模型的发展历程中,一个长期困扰研究者效率的难题是:模型往往需要消耗昂贵的计算资源去重建那些本可以通过简单查询获得的静态知识。
近日,DeepSeek 团队发布重磅论文 Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models,由梁文锋等研究者署名,宣布为大模型架构开辟了一个全新的稀疏性维度:条件记忆(Conditional Memory)。

为什么 MOE 还不够
长期以来,MoE(专家混合模型) 是大模型稀疏性的事实标准。它通过条件计算平衡了模型容量与计算成本。但 DeepSeek 指出,语言信号具有高度的异质性:
-
动态推理:需要深度的神经计算。
-
静态知识:如命名实体、公式,本应通过查找直接获取。
目前的 Transformer 缺乏原生的查找原语,被迫用昂贵的算力去运行时重建静态表,这极大地浪费了序列深度。
为此,DeepSeek 推出了 Engram 模块——一个将经典 N-gram 嵌入现代化,实现 O(1) 常数级快速查找的高效知识外挂。
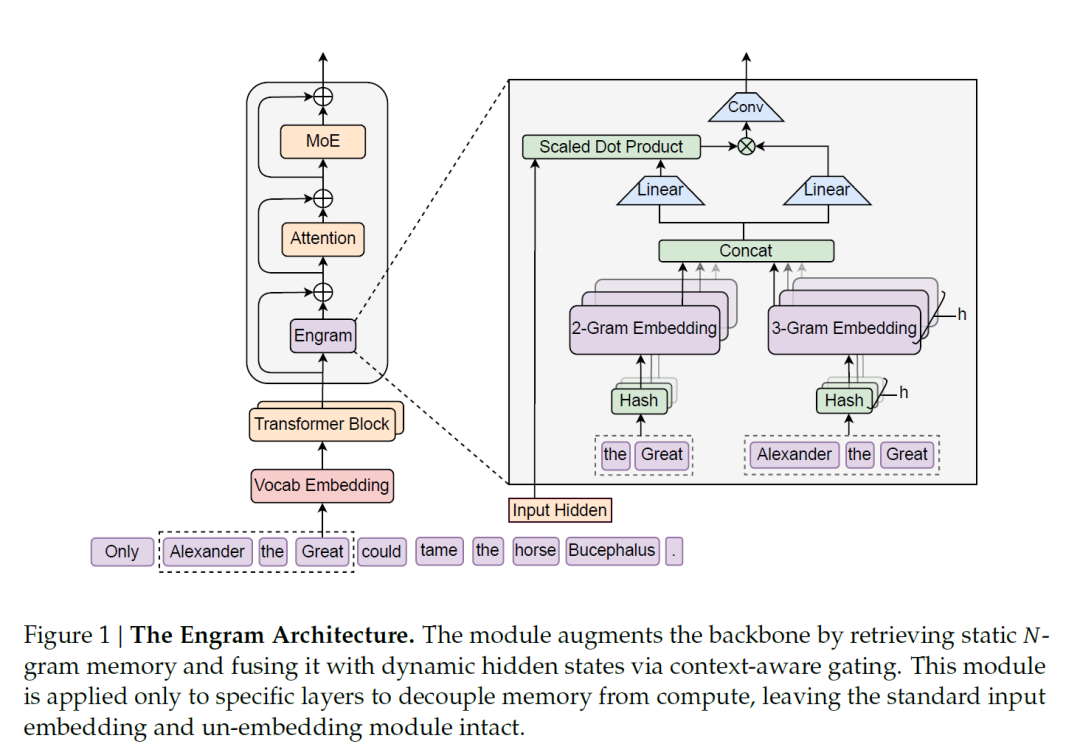
论文四个重点划线:
稀疏分配:发现 U 形扩展规律
研究团队为量化 Engram 与 MoE 之间的协同,论文提出稀疏性的分配问题。这也是该论文的核心。并通过大量实验发现了一个显著的 U 形扩展规律(U-shaped scaling law)
-
权衡关系:纯 MoE 架构缺乏专用内存,迫使模型通过计算低效重构静态模式;而过度分配给记忆则会损害模型的动态推理能力 。
-
最佳平衡点:当大约 20%-25% 的稀疏参数预算分配给 Engram 时,模型性能达到峰值。例如在 10B 参数规模下,验证损失从 1.7248 降至 1.7109。
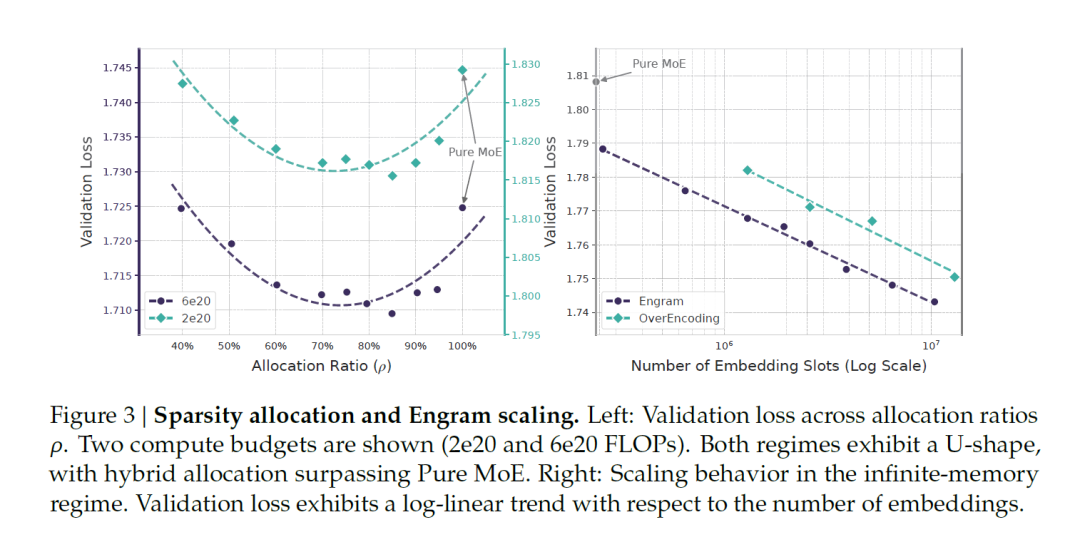
基于前述容量分配规律,研究团队训练了 Engram-27B 模型(总参数量 26.7B,激活参数 3.8B)。在该模型中,原 MoE-27B 的专家数量从 72 个减少到 55 个,同时将释放出的参数重新分配到 5.7B 参数的 Engram 内存中,使容量分配比例达到 ρ = 74.3 % \rho = 74.3\%ρ=74.3%。
经过预训练后,Engram-27B 在保持与 MoE-27B 相同参数规模和 FLOPs 的前提下,在知识与推理、通用推理、代码以及数学等多个任务上均表现出明显提升。
实证验证:全维度性能飞跃
在严格的等参数(iso-parameter)和等浮点运算量(iso-FLOPs)约束下,Engram-27B 模型在知识、推理、代码和数学等领域均表现出相较 MoE 基线的一致性提升。
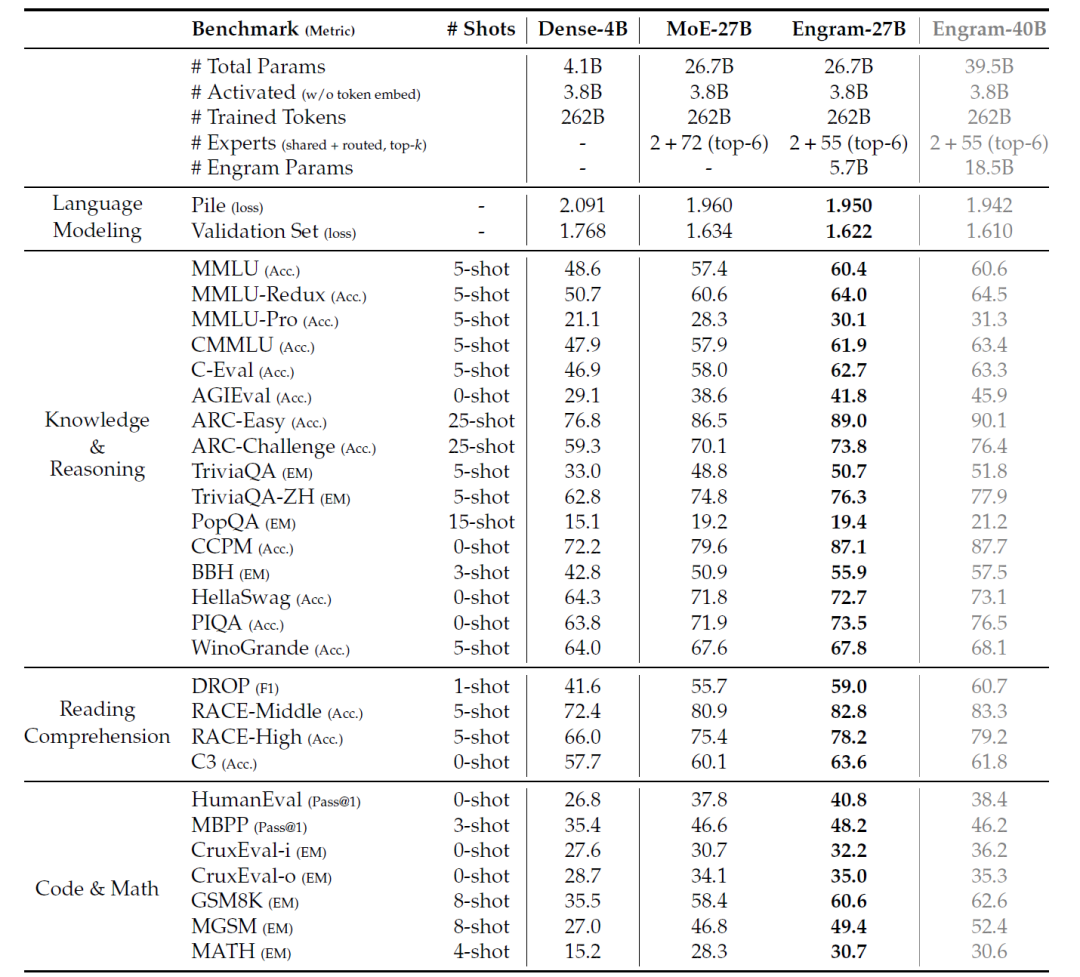
预训练性能比较:Dense 模型、MoE 模型与 Engram 模型(来源:论文)
-
知识储备:MMLU 提升 3.4 分,CMMLU 提升 4.0 分 。
-
通用推理:最令人惊喜的是,复杂推理(BBH)提升了 5.0 分,科学推理(ARC-C)提升 3.7 分。
-
代码与数学:HumanEval (+3.0) 和 MATH (+2.4) 同样显著提升。
-
长文本能力:在“大海捞针”(Multi-Query NIAH)测试中,准确率从 84.2% 飙升至 97.0%。
机制分析:释放有效深度
为什么记性好能让逻辑更强?通过 LogitLens 和 CKA 分析发现 Engram 接管了早期层对静态模式的重建工作。 当底层不再需要浪费算力去死记硬背时,模型保留了更多的 Effective Depth(有效深度) 来处理深层语义,让大脑全身心投入高阶推导。
-
底层减负:Engram 承担了早期层对静态模式(如固定搭配、实体名)的重建工作 。
-
提升有效深度(Effective Depth):当底层不再浪费算力去死记硬背时,模型实际上获得了更深的表示能力来处理深层语义。
-
解放注意力:通过将局部依赖交给 Engram 处理,模型释放了宝贵的注意力容量来聚焦全局上下文。
系统效率:突破显存天花板
在工程落地层面,Engram 展现了极致的基础设施感知特性 :
-
确定性寻址:由于检索索引仅取决于输入序列,系统可以在计算当前层时,异步预取下一层所需的记忆向量 。
-
打破显存瓶颈:DeepSeek 演示了将高达 100B 参数的嵌入表卸载到廉价的 CPU 内存中。
-
极低开销:这种跨硬件搬运带来的额外推理延迟低于 3%。这为未来挂载 TB 级别的海量记忆库铺平了道路。
值得关注的是,论文最后明确指出,条件记忆将成为下一代稀疏模型中不可或缺的核心建模组件。
据外媒报道,DeepSeek 计划于 2 月发布其新一代旗舰 AI 模型 DeepSeek V4。并且 V4 在多个关键指标上表现优异,与现有主流模型相比展现出一定优势,因此让人不禁拭目以待这款新旗舰的正式亮相。
参考论文:
https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf

