中科院和CreateAI推出NeoVerse,用百万单目视频训练4D世界模型。采用前馈式4DGS,双向运动建模,单目退化模拟等技术,效果超越现有方法,并在多个领域有应用前景。
原文标题:李飞飞又被超越了?百万「普通视频」打造通用4D世界模型!
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、NeoVerse的“稀疏帧重建,密集帧渲染”策略是如何提高训练效率的?这种策略在其他视频处理任务中有没有应用潜力?
3、NeoVerse论文中提到,它构建了一套能够无缝适配互联网单目视频的训练管线。你认为要将这项技术真正落地应用,还需要解决哪些实际问题?
原文内容

来源:新智元本文约2700字,建议阅读5分钟当全行业还在为昂贵的多视角数据焦头烂额时,中科院和CreateAI重磅推出NeoVerse,直接用百万单目视频砸开了4D世界模型的大门,让AI真正学会了理解开放世界。
项目主页:https://neoverse-4d.github.io/
论文链接:https://arxiv.org/abs/2601.00393


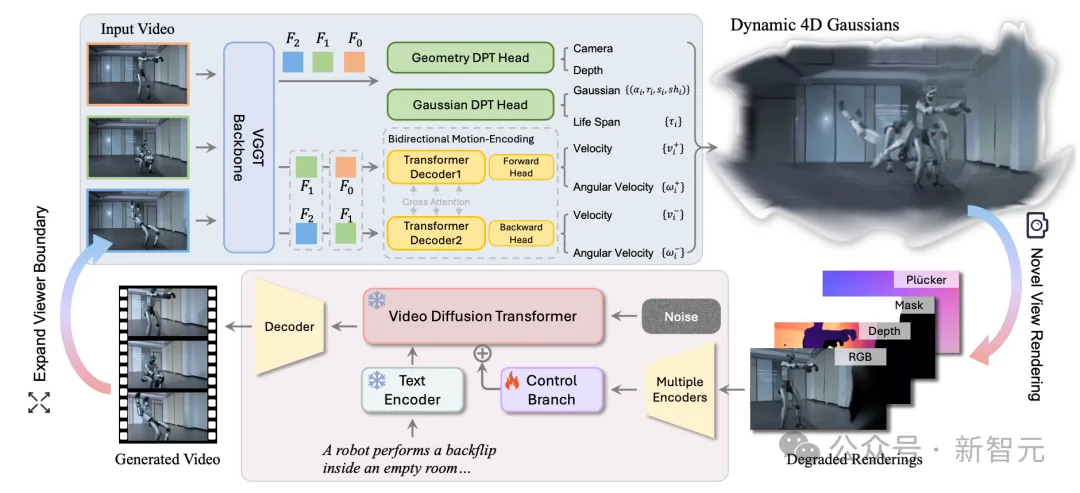
NeoVerse 是一种重建-生成混合式的架构,其首先重建出 4D 表示,然后将其用于生成模型的作为新视角的几何引导。要实现训练管线的 scaling up,第一步必须解决「重建速度」问题。NeoVerse 提出了一种免姿态输入(Pose-free)的前馈式 4DGS 模型。
与传统针对专一场景迭代优化的重建方法不同,NeoVerse 基于视觉几何基础变换器(VGGT)进行动态化和高斯化改进。这种前馈式重建无需复杂离线预处理,一次预测即可在几秒内完成动态场景 4D 建模。
NeoVerse 引入双向运动编码分支,通过交叉注意力机制分别提取前向 ( )和后向( )的运动特征,这种有利于精准预测高斯基元的双向线速度和角速度,实现相邻时间戳的中间时刻高斯插值渲染。
具体来说,对于帧特征 ,NeoVerse 沿时间维度将其复制并切分成两部分: 和 。其中前者作为查询特征,后者作为键和值来获取前向运动特征,反之则得到后向运动特征。
其中 和 分别是 的前向运动特征和 的后向运动特征,这些特征将用于预测高斯基元双向运动的线速度和角速度。
NeoVerse 定义的 4D 高斯基元如下
包括传统 3D 高斯属性:3D 位置 、不透明度 、朝向 、大小 和球谐系数 。双向建模预测的前后向线速度 和角速度 。以及 4DGS 常用的生命周期 。
其中 3D 位置 是通过预测深度和相机参数将像素深度反向投影到 3D 空间获得的,动态属性 由双向运动特征预测,其他属性则由帧特征预测。
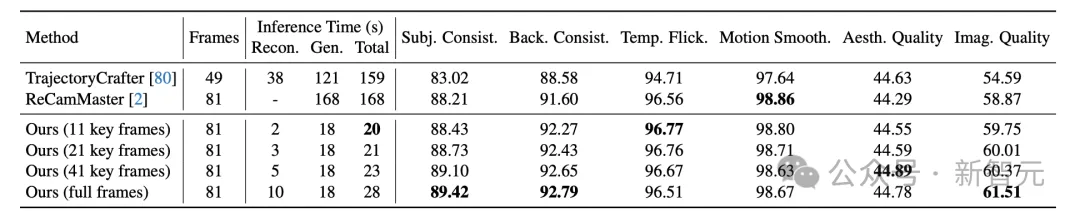
为了进一步加快重建速度从而提升训练效率,NeoVerse 提出「稀疏帧重建,密集帧渲染」策略,在少量稀疏关键帧输入的条件下通过高斯场插值渲染出连续密集的视频画面。对于一个非关键帧时间戳 ,NeoVerse 将其最近的关键帧时间戳 下的高斯基元 转移到 :
其中为了处理非均匀的关键帧间隔,NeoVerse 归一化时间距离 来对不透明度的衰减进行建模, 是 的左右两个关键帧时间戳。生命周期 约束在 范围内,当 接近于1时, 趋于1,表明 ,否则不透明度会快速衰减。

在单目视频训练中,最大的挑战是缺乏「新视角」的监督信号。NeoVerse 并没有尝试寻找完美的数据,而是反其道而行之,引入了单目退化模拟机制,在训练的每一次迭代中,NeoVerse 并不是简单地从输入视角渲染,而是刻意「模拟」了单目重建在不同视角下的退化规律,从而建立起一套自监督训练范式:
-
高斯剔除(Gaussian Culling): 模拟相机移动时可能出现的遮挡与视场丢失(图(a))。通过剔除部分 4D 高斯基元,模型被迫在「信息不全」的情况下学习维持物体的几何完整性。
-
平均几何滤波(Average Geometry Filter): 除了遮挡之外,另一种典型的退化模式是深度不连续的飞行边缘像素。NeoVerse 通过在采样的新视角上渲染深度图并作平均滤波,再根据滤波后的深度值调整每个高斯基元的位置。当调整位置后的高斯重新渲染回原视角,则能模拟出现飞边现象(图(b))。当增大平均滤波核半径时,则能模拟出更大范围的空间畸变(图(c))。
NeoVerse 通过控制分支将模拟的渲染结果(包含渲染图像、深度、不透明度图以及相机位姿的 Plüker 嵌入)注入视频生成模型。在训练过程中,NeoVerse 仅训练控制分支,同时冻结视频生成主干模型,这不仅可以提升训练效率,更重要的是,使其能够支持步数蒸馏 LoRAs,以加速生成过程。


较大的相机运动下的渲染图像容易产生包括飞边像素和扭曲等现象。上图展示了 NeoVerse 单目退化模拟的必要性。如果没有在模拟出的退化样本上进行训练,生成模型往往会过于信任重建渲染中的几何伪影,导致出现「鬼影」效果或模糊输出。通过结合退化模拟,生成模型能够学会抑制这些伪影,并在遮挡或扭曲区域生成逼真的细节。
在大规模视频训练的支持下,NeoVerse 不仅能实现高精度的 4D 重建与精准漫游,更能跨越影视制作、具身智能与自动驾驶等多个领域,支持多视角生成、视频编辑等丰富下游应用。
子弹时间
从图像到世界:重建 + 生成的迭代闭环
多样化相机控制
视频编辑
具身场景应用
驾驶场景应用
驾驶场景前视相机到多视角相机扩展
NeoVerse 的出现,标志着 4D 空间智能从「实验室精雕细琢」向「大规模数据驱动」的范式转移。它通过攻克核心的扩展性(Scalability)瓶颈,构建了一套能够无缝适配互联网单目视频的训练管线。这种对海量开放场景数据的深度挖掘,不仅让 NeoVerse 在泛化能力上实现了质的飞跃,更使其成为了支撑自动驾驶、具身智能及内容创作等多元领域的通用 4D 世界模型底座。
