研究揭示 Transformer 通过梯度下降演化为贝叶斯推理机,并阐释了其内部几何和动力学机制,为理解 LLM 智能提供新视角。
原文标题:从优化到推理:Transformer 贝叶斯本质的几何 + 动力学全景解析
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到了“熵有序流形”的概念,并将其与 Chain-of-Thought 联系起来。那么,是否可以通过设计特定的训练方法,强制模型学习更清晰、更鲁棒的熵有序流形,从而提升 CoT 的效果?
3、文章中提到 Attention 机制充当 E 步的“软责任”,Value 向量充当 M 步的“原型”,这是否意味着我们可以将 Transformer 的训练过程视为一种特殊的 EM 算法?这种视角对我们理解和改进 Transformer 有什么启示?
原文内容

本文约2200字,建议阅读5分钟
本文通过三部曲论文,揭示 Transformer 是梯度诱导的贝叶斯推理机,破解黑盒本质。
不是设计,而是进化。当交叉熵遇见 SGD,贝叶斯推理成了唯一的数学必然。
长期以来,LLM 的推理能力被视为一种难以解释的“涌现”。我们目睹了 Loss 的下降,却难以透视参数空间内部发生了什么。
近日,来自哥伦比亚大学和 Dream Sports 的研究团队发布了一组三部曲论文。
这项工作并未止步于实验观察,而是建立了一个连接优化目标 (Loss)、内部几何 (Geometry) 与推理功能 (Inference) 的完整物理图景。
它讲述了一个关于 LLM 如何运作的完整故事。其核心野心正如标题所言——试图用数学终结 Transformer 的黑盒时代。
他们证明了:Attention 机制并非某种近似的特征提取器,而是在梯度下降的驱动下,自发演化出的一套精确的贝叶斯推理机。
1、理论锚点:交叉熵的贝叶斯终局
Transformer 的训练通常基于最小化交叉熵损失。Paper I 首先澄清了这一优化过程的数学终局。

论文标题:
The Bayesian Geometry of Transformer Attention
论文链接:
https://arxiv.org/abs/2512.22471
在无限数据与容量的极限下,最小化交叉熵 :
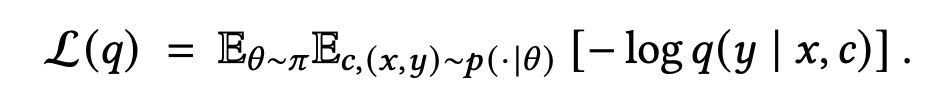
其最优解 在数学上严格等价于解析贝叶斯后验预测分布 (Bayesian Posterior Predictive Distribution):
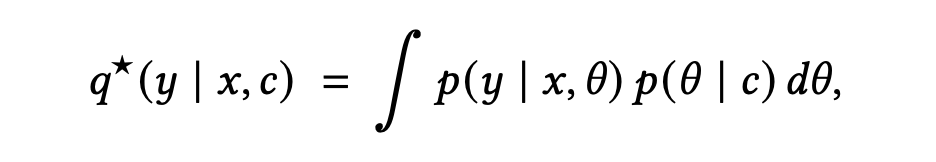
为了验证有限容量的 Transformer 是否真正逼近了这一极限,作者构建了贝叶斯风洞 (Bayesian Wind Tunnels) 。
这是一个完全受控的数学环境,其中每一步的解析后验都是精确已知的。

〓 图1. “贝叶斯风洞”概念图。在缺乏 Ground Truth 的自然语言之外,作者构建了一个可精确测量的受控环境。
实验结果表明,在双射学习与 HMM 状态追踪任务中,Transformer 展现了极高的精度。
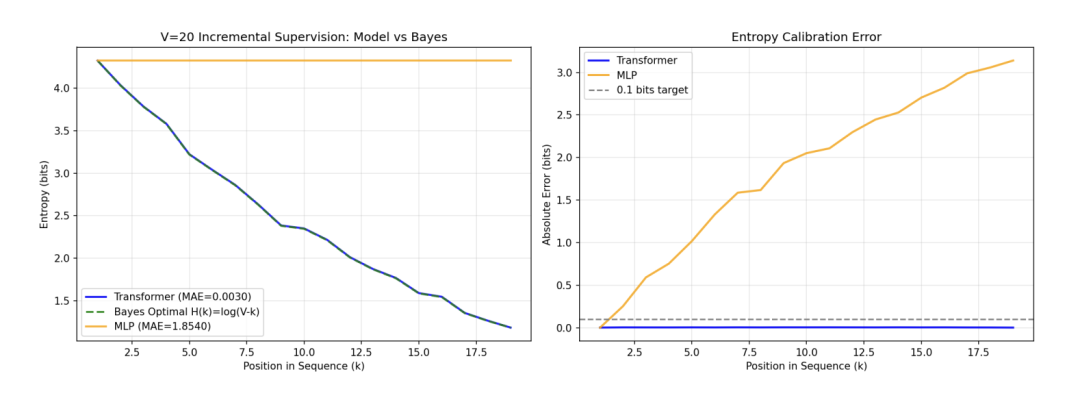
〓 图2. Transformer 的预测熵精确贴合理论贝叶斯后验,平均绝对误差(MAE)低至 10^{-3} 比特;相比之下,MLP 无法有效利用上下文进行假设消除。
更微观的证据来自单序列分析,这是证明模型真理解而非平均记忆的铁证:
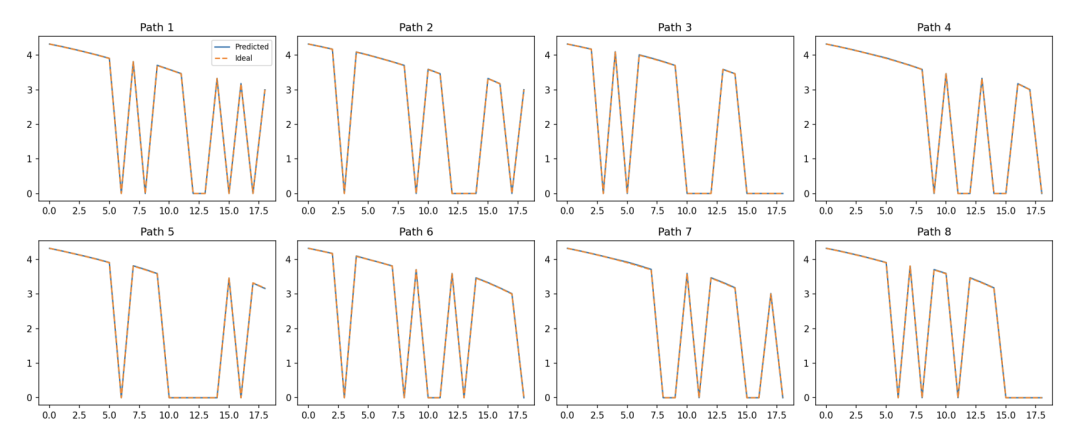
〓 图3. 针对每一个具体序列,Transformer 的熵值(实线)能够精确追踪理论后验(虚线)的锯齿状变化,证明模型在进行逐 Token 的实时推理。
而在 HMM 任务中,模型甚至展现出了完美的长度外推 (Length Generalization) 能力,证明其学会了通用的递归算法:
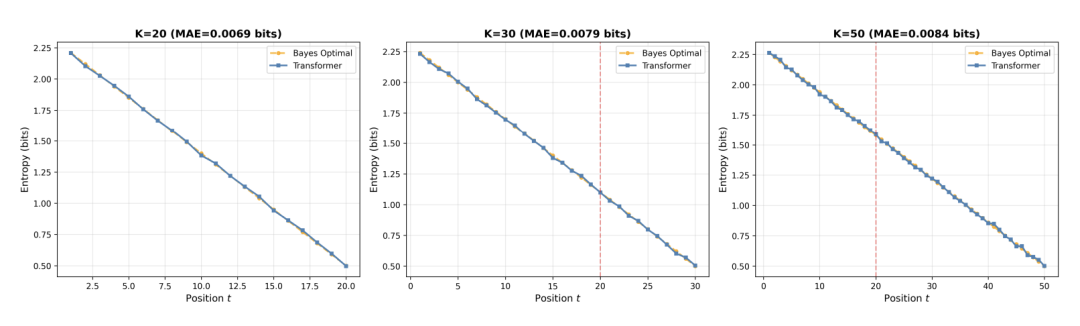
〓 图4. 模型在训练长度 K=20 内完美拟合。在测试长度 K=30 和 K=50 时,误差平滑增长,未出现断崖式下跌,证明模型并未死记硬背。
2、几何表征:推理的三阶段演化
探针实验进一步揭示了 Transformer 内部如何实现这一推理过程。作者将其描述为一个三阶段的几何演化机制。
1. 假设框架构建 (Layer 0)
推理始于坐标系的建立。第 0 层的 Key 向量形成了一个 近似正交的基底 (Orthogonal Basis),将所有可能的假设映射到独立的几何子空间中。
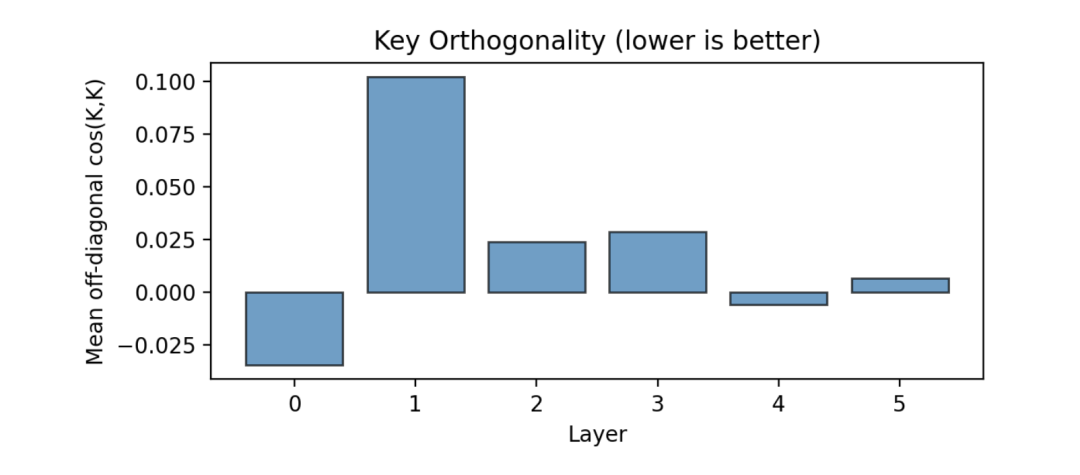
〓 图5. Layer 0 的 Key 向量余弦相似度矩阵。非对角元素接近 0,表明模型构建了正交的假设空间框架。
2. 渐进式假设消除 (Middle Layers)
随着层数加深,Attention 的路由 (Routing) 功能逐渐显现。Query 和 Key 的对齐程度呈现显著的锐化 (Sharpening) 趋势。
这一过程在数学上等价于贝叶斯更新中似然函数的乘法操作,逐层抑制与当前证据不符的假设。
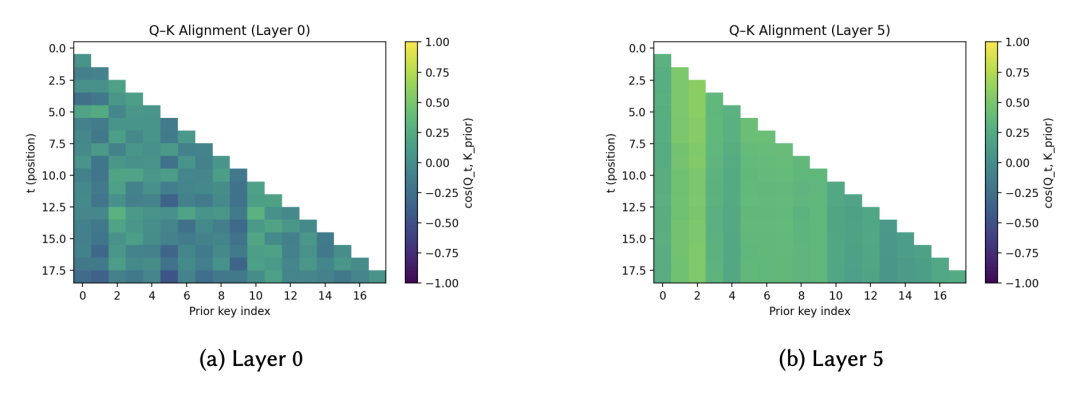
〓 图6. 从 Layer 0(左)的发散关注到 Layer 5(右)的高度聚焦,展示了模型对错误假设的逐步剔除。
3. 熵有序流形 (Late Layers)
当路由结构稳定后,Value 向量 ( ) 在表示空间中并未坍缩为离散点,而是展开成一条光滑的一维流形 (1D Manifold)。
该流形的参数化坐标精确对应于后验熵 (Posterior Entropy)。
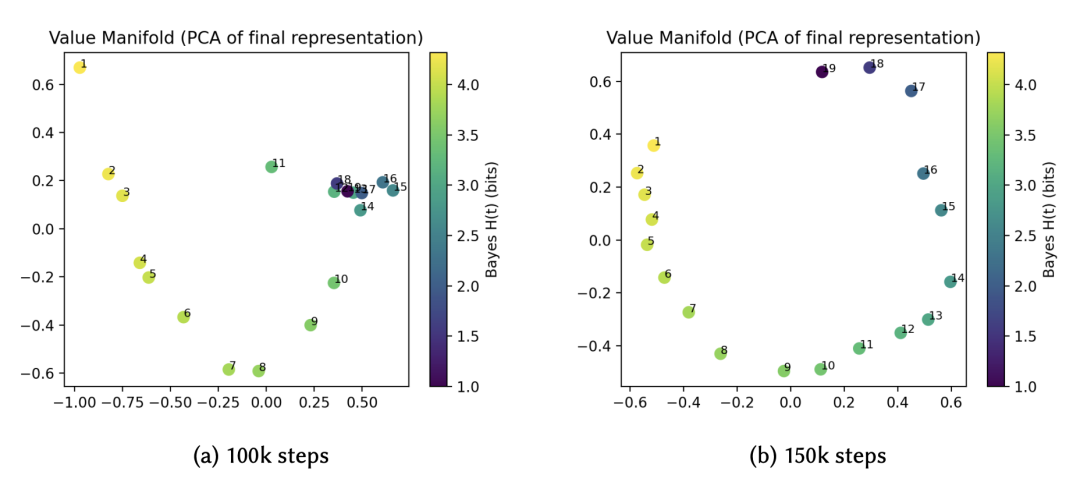
〓 图7. 训练后期,Value 向量的 PCA 投影形成了一条平滑曲线,低熵(高置信度)状态与高熵状态在几何上有序排列。
3、动力学溯源:梯度下降的诱导机制
为何标准的梯度下降能够自发产生上述几何结构?
Paper II 通过全套一阶梯度动力学推导,发现交叉熵损失诱导了一套精妙的正反馈机制。

论文标题:
Gradient Dynamics of Attention: How Cross-Entropy Sculpts Bayesian Manifolds
论文链接:
https://arxiv.org/abs/2512.22473
1. 优势路由法则 (E-step)
Attention Score ( ) 的梯度遵循以下公式:
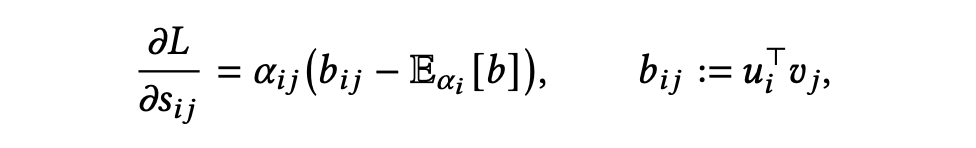
其中 。定义 Advantage 。
物理含义:这里 代表误差梯度方向。当 与误差方向相反(即 越负,有助于减少 Loss)时,Advantage 为正。
结论:梯度下降会增加那些能有效减少 Loss 的位置的注意力权重。
2. 责任加权更新法则 (M-step)
Value ( ) 的更新遵循以下公式:
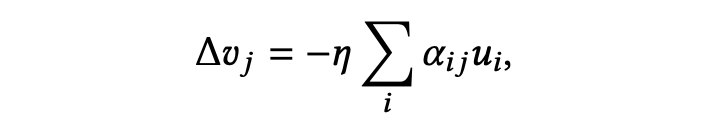
物理含义:Value 向量会被拉向所有关注它的 Query 的上游误差信号 ( ) 的加权平均方向,逐步演化为该簇 Query 的“原型” (Prototype)。

〓 图8. 动力学几何解释
Value 向误差信号 移动,优化 Context ,进而增加兼容性 (使其更负),形成路由与内容的协同演化闭环。
这一动力学过程在结构上等价于隐式的 EM 算法 (Expectation-Maximization)。Attention 权重充当 E 步的“软责任”,而 Value 向量充当 M 步的“原型”。
这也解释了框架-精度解离 (Frame-Precision Dissociation) 现象。Attention 结构通常在训练早期快速稳定,而 Value 内容则在剩余训练中持续在流形上精修。
4、现实映射:从叠加态到思维链
虽然上述结论基于受控环境,但作者在博客 [3] 中指出,在 Pythia, Llama, Mistral 等生产级模型中,同样观察到了类似的几何特征。
关键在于叠加态 (Superposition):在混合任务中,流形结构往往被高维噪声掩盖;但通过领域限制 (Domain Restriction)(如仅关注数学任务),高维表征会坍缩为清晰的熵有序流形 。
〓 图9. 概念图展示了 Pythia、Llama 和 Mistral 内部在特定领域任务下涌现出的相似流形结构。
这一发现为 Chain-of-Thought (CoT) 提供了清晰的几何解释。
对于复杂推理任务,Transformer 面临层数耗尽 (Run out of layers) 的风险,无法在有限的计算步数内完成所有必要的假设消除。
CoT 本质上起到了几何延展器 (Geometric Extender) 的作用。
通过生成中间推理步骤,模型实际上获得了更多的计算轮次,使其能够沿着高置信度的“熵有序流形”进行一系列短距离、稳健的状态转移,从而避免了在低置信度区域进行长距离跳跃所引发的幻觉。
5、结语
这项研究提供了一个统一的视角来理解 Transformer 的智能本质。优化产生几何,几何产生推理 (Optimization gives rise to geometry. Geometry gives rise to inference.) 。
参数矩阵并非随机的统计近似,而是梯度流在交叉熵势能面上“雕刻”出的贝叶斯推理机。
Attention 机制从几何动力学的角度来看,正是这一推理过程的物理载体。
参考文献
[1] Naman Aggarwal, Siddhartha R. Dalal, Vishal Misra. The Bayesian Geometry of Transformer Attention. arXiv preprint arXiv:2512.22471 (2025).
[2] Naman Aggarwal, Siddhartha R. Dalal, Vishal Misra. Gradient Dynamics of Attention: How Cross-Entropy Sculpts Bayesian Manifolds. arXiv preprint arXiv:2512.22473 (2025).
[3] Vishal Misra. Attention Is Bayesian Inference. Medium (Dec 2025). https://medium.com/@vishalmisra/attention-is-bayesian-inference-578c25db4501
