PoPE通过解耦内容与位置信息,显著提升零样本外推能力,性能超越RoPE/YaRN,为长文本处理带来新思路。
原文标题:告别长文微调!PoPE 破解 RoPE 耦合难题,零样本外推超 RoPE/YaRN
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、PoPE在零样本外推上表现出色,这是否意味着它在所有长文本处理场景下都优于RoPE和YaRN?在哪些特定场景下,RoPE 或 YaRN 可能仍然更具优势?
3、文章提到PoPE通过解耦内容和位置信息来提升性能,那么这种解耦是否会带来其他潜在的问题?例如,模型是否会失去一些 RoPE 原本能够捕捉到的内容和位置之间的微妙关联?
原文内容

本文约2000字,建议阅读5分钟本文介绍 PoPE 位置编码,解耦内容与位置,零样本外推性能优于 RoPE/YaRN。
告别长文微调!Schmidhuber 团队新作修正 RoPE 理论缺陷,原生支持零样本无限外推 。
告别长文微调!Schmidhuber 团队新作修正 RoPE 理论缺陷,原生支持零样本无限外推 。
在当前的大模型架构中,Rotary Position Embedding (RoPE) 是处理序列位置信息的主流方案。凭借良好的外推潜力和相对位置编码特性,它成为了众多开源基座模型的首选。
然而,长文本处理依然充满挑战。为了让模型处理超出训练窗口的文本,我们通常需要依赖 YaRN 等插值方法或进行额外的长文微调。
这引发了一个值得深思的问题:RoPE 在处理位置信息时,是否还存在理论上的优化空间?
近日,IDSIA 实验室(Jürgen Schmidhuber 团队)联合 OpenAI 发布的最新论文提供了一个新视角。作者认为,RoPE 的旋转机制在数学上不经意间将词向量的内容信息(What)与位置信息(Where)耦合在了一起。
为了解决这个问题,论文提出了一种基于极坐标的位置编码——PoPE (Polar Coordinate Positional Embedding)。
在未进行长文本微调的情况下,PoPE 在数倍于训练长度的序列上保持了稳定的困惑度(PPL),这一结果值得关注。

论文标题:
Decoupling the "What" and "Where" With Polar Coordinate Positional Embeddings
论文链接:
https://arxiv.org/abs/2509.10534
1、理论分析
要理解 PoPE 的改进,我们需要回到 RoPE 的数学定义。
在 RoPE 中,位置 的查询向量 和位置 的键向量 通过复数旋转计算注意力分数。
如果我们引入极坐标视角,将 和 表示为模长(Magnitude)和相位(Phase)的形式,即 和 。
经过推导,RoPE 的注意力分数可以表示为:
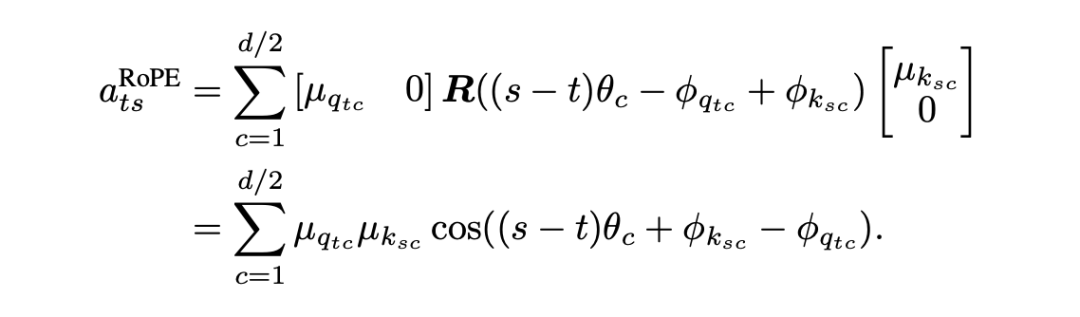
请注意余弦函数内部的 这一项。
这里, 是我们期望的相对位置信息(Where),但 和 实际上由 Key 和 Query 向量本身的初始值决定,代表了内容信息(What)。
这意味着,在 RoPE 的机制下,相对位置的匹配受到内容特征的直接干扰。当模型试图进行纯粹的位置操作(例如“关注前第 5 个 token”)时,这种耦合可能会引入噪声,增加学习难度。
2、极坐标下的显式解耦
针对上述问题,PoPE 的核心思路非常清晰:在数学层面显式解耦内容(模长)与位置(相位)。
PoPE 不再依赖笛卡尔坐标系的旋转混合,而是直接定义向量在极坐标下的属性:
内容提取(What):使用 Softplus 函数从原始输入中提取模长,确保其非负,且仅包含内容强度信息。
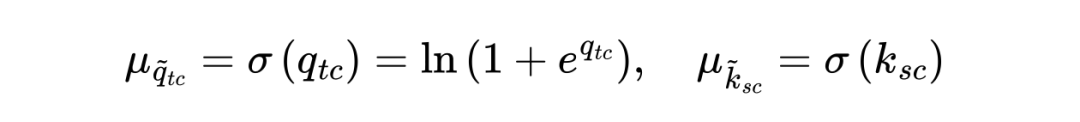
位置注入(Where):显式定义相位只与序列位置有关,摒弃原始向量的相位信息。
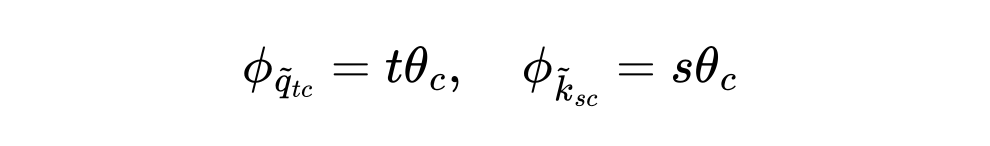
基于此定义,PoPE 的注意力分数计算公式变为:
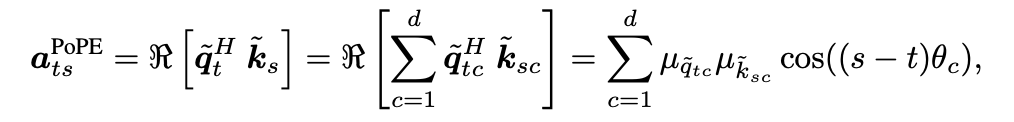
对比 RoPE,PoPE 的余弦项中仅保留了 。此时,注意力分数变成了内容匹配项( )与位置匹配项( )的乘积,两者相互独立。
下图直观地展示了两种方法的差异:

〓 图1. RoPE 与 PoPE 的相对位置编码机制对比
此外,为了增加灵活性,作者还引入了一个可学习的偏置项 来微调每个频率的相对偏移(论文特别指出,该偏置项需初始化为 0 以保证最佳的外推稳定性)。
3、实验结果
PoPE 在实验层面的表现印证了其理论假设的有效性。
1. 诊断性任务:间接索引
为了验证模型是否真的具备独立操作位置与内容的能力,作者设计了一个间接索引任务(Indirect Indexing)。
该任务要求模型根据给定的偏移量(如“左边第 3 个”)定位目标字符,这本质上考察的是指针算术能力。
实验结果显示了显著的性能差异:

〓 表1. 间接索引任务的测试集准确率
该这一结果表明,RoPE 的耦合特性确实限制了其学习精确相对位置规则的能力,而 PoPE 则能较好地掌握这一逻辑。
2. 核心优势:零样本长度外推
在长文本能力的评估上,作者在 OpenWebText 上预训练了上下文长度为 1024 的模型,并在 PG-19 数据集上测试了最长达 10240 token 的序列表现。
值得注意的是,这里的 PoPE 模型并未进行任何针对长文本的微调(Fine-tuning)或插值处理。
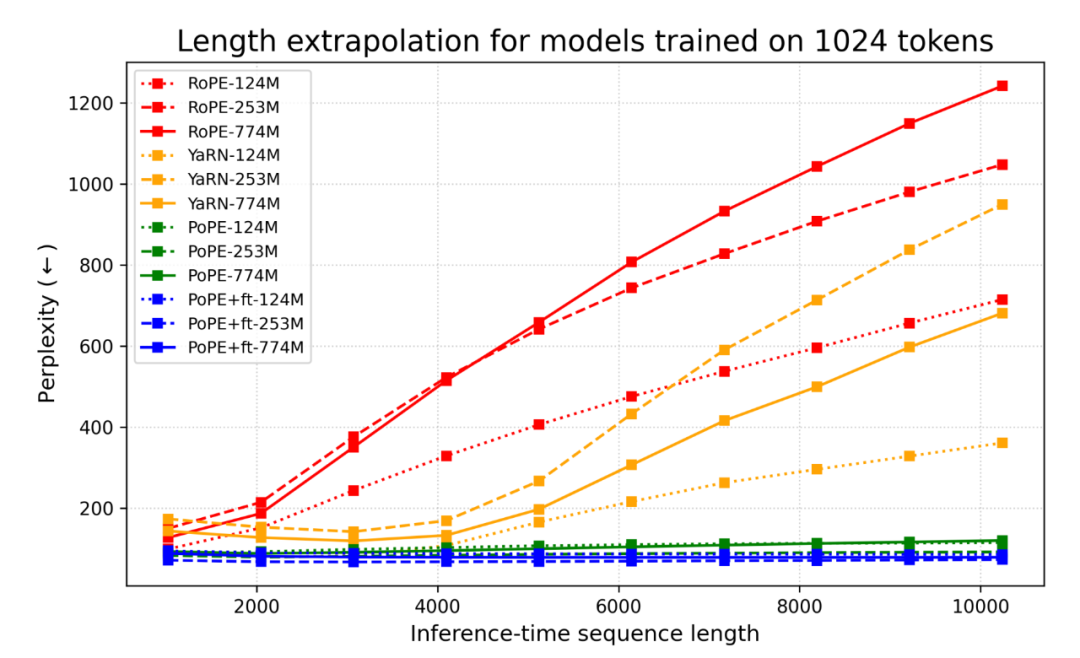
〓 图2. 不同模型在 PG-19 数据集上的测试时长度外推表现
RoPE (红线):当推理长度超过训练长度(1024)时,PPL 显著上升,表明模型难以适应未见过的相对距离。
YaRN (黄线):即使经过专门的长文微调,一旦超过微调设定的窗口,性能也会出现退化。
PoPE (绿线):这条绿线平得简直像出 bug 了一样。在未微调的情况下,模型在 10 倍于训练长度的序列上,PPL 纹丝不动。
这种特性意味着 PoPE 可能具备更好的泛化边界,能够降低对长上下文预训练资源的依赖。
3. 频率利用率分析
为何 PoPE 能取得更好的效果?作者进一步分析了注意力层中不同频率分量的激活情况。
过往针对 RoPE 的研究(如 Gemma 7B)发现,模型倾向于主要利用低频分量,而高频分量往往因被视为噪声而受到抑制。
作者在复现 RoPE 实验时也观察到了类似的稀疏激活模式,如下图所示:
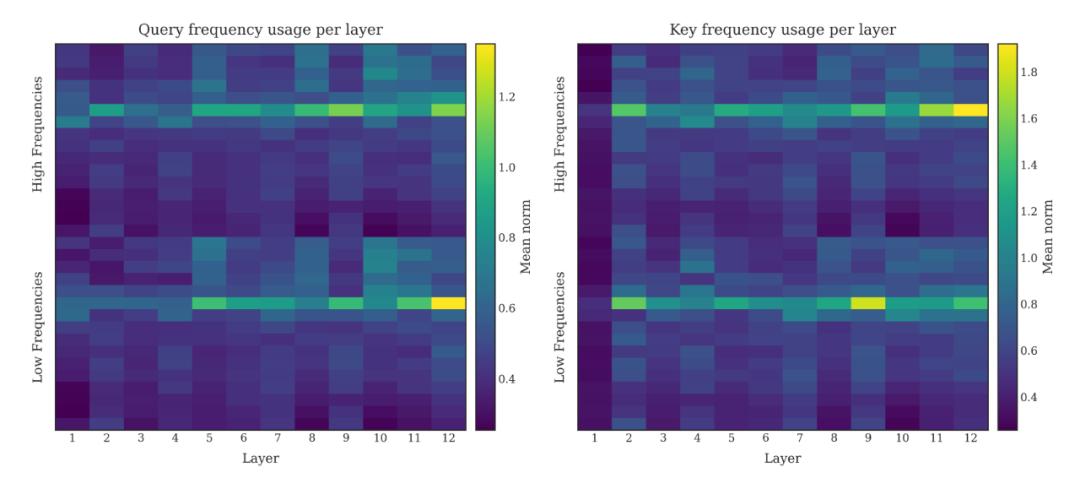
〓 图3. 124M RoPE 模型各层的特征模长热力图
相比之下,PoPE 的热力图显示出了不同的特征:
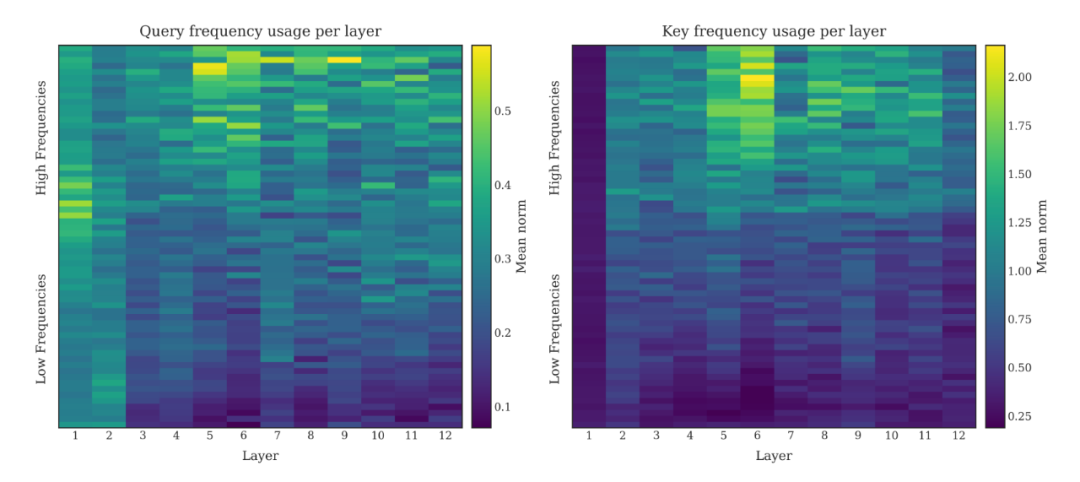
〓 图4. 24M PoPE 模型各层的特征模长热力图
PoPE 的特征在所有频率(从低到高)上都有明显的激活,表明其更充分地利用了表示空间。
4. 语言建模与下游任务性能
除了外推能力,PoPE 在标准的语言建模任务(OpenWebText)上也展现出了优势。在不同参数规模下(124M 到 774M),PoPE 的验证集困惑度(PPL)均低于 RoPE:

〓 表2. OpenWebText 验证集困惑度
在包括 LAMBADA、HellaSwag 在内的多个下游任务零样本评估中,PoPE 同样取得了更高的平均准确率:
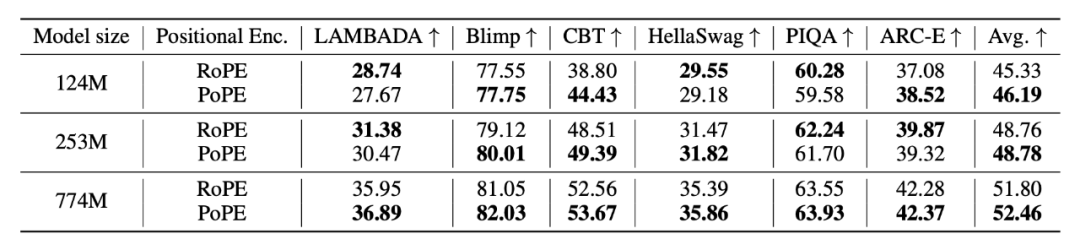
〓 表3. 下游任务零样本性能对比
4、结语
这篇论文通过重新审视 RoPE 的数学性质,指出了其在内容与位置解耦上的不足,并提出了 PoPE 这一修正方案。
核心看点归纳:
理论修正:在极坐标系下显式解耦了模长(内容)与相位(位置)。
外推能力:展现了优异的零样本长度外推性能,不仅优于原始 RoPE,在同等条件下也优于 YaRN。
工程代价:虽然计算逻辑简单,但 PoPE 需要处理复数或双倍维度的模长,在实现上会带来显存带宽的压力。不过作者也提到,可以通过算子融合(Kernel Fusion)在核内实时计算模长,从而消除显存占用的额外开销。
在追求更长上下文和更高推理效率的背景下,PoPE 提供了一个具备扎实理论基础的改进方向。对于正在构建或优化基础模型的开发者而言,这或许是一个值得验证的技术选项。
