Player2开源Pixel2Play!8300小时数据训练,新一代通用游戏AI,可实时交互,零样本玩转多款游戏。
原文标题:开源8300小时标注数据,新一代实时通用游戏AI Pixel2Play发布
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到P2P模型在指令遵循方面表现出色,那么,在实际游戏体验中,AI对复杂指令的理解和执行能力如何?会存在哪些局限性?
3、P2P模型开源了训练数据和代码,这对游戏AI领域的发展有哪些积极意义?同时,可能存在哪些潜在的风险或伦理问题?
原文内容

随着人工智能在代码以及图片生成方面日益成熟,越来越多的研究人员也开始关注 AI 模型在游戏领域中的表现。实际上,游戏在 AI 的发展早期就已经是一个重要的研究方向,许多前期研究聚焦在 Atari,星际争霸,Dota 等热门游戏,并成功训练出了表现超越人类玩家的专用模型。然而,这类模型通常只能在单一游戏环境中运行,缺乏跨游戏的泛化能力。
另一方面,虽然 ChatGPT 和 Gemini 这类模型通用模型在众多任务上已经展现出了卓越的能力,它们却难以在游戏环境中取得好的表现,即便是很简单的射击游戏。
为了解决这一问题,来自 Player2 的研究员们提出了 Pixel2Play(P2P)模型,该模型以游戏画面和文本指令作为输入,直接输出对应的键盘与鼠标操作信号。在消费级显卡 RTX 5090 上,P2P 可以实现超过 20Hz 的端到端推理速度,从而能够真正像人类一样和游戏进行实时交互。P2P 作为通用游戏基座模型,在超过 40 款游戏、总计 8300 + 小时的游戏数据上进行了训练,并能够以零样本(zero-shot)的方式直接玩 Roblox 和 Steam 平台上的多款游戏。
为了促进领域的发展,Open-P2P 团队在没有使用许可限制的情况下开源了全部的训练与推理代码,并公开了所有的训练数据集。
接下来请看 P2P 模型的人机对战:(在 Roblox Rivals 游戏中)
-
论文题目:Scaling Behavior Cloning Improves Causal Reasoning: An Open Model for Real-Time Video Game Playing
-
项目主页:https://elefant-ai.github.io/open-p2p/
-
论文代码:https://github.com/elefant-ai/open-p2p
-
论文数据:https://huggingface.co/datasets/elefantai/p2p-full-data
训练数据
训练游戏 AI 模型需要高质量的游戏画面、文本指令以及对应的操作数据。与海量公开的图文数据不同,这类 “画面 - 操作” 数据在互联网上很少见。尽管已有通过游戏视频反推动作的开源数据集,但开源的大规模高质量人工标注操作数据却还是空缺。为了弥补这一空缺,Open-P2P 项目开源了全部的训练数据集。

如图所示,P2P 所用的训练数据同时包括游戏图像画面与对应的文本指令,并提供了精确的键盘鼠标操作标注
模型设计
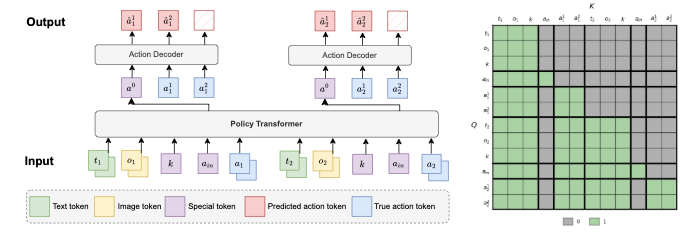
为了保证模型可以做到快速的推理速度,P2P 选择了轻量级模型框架并从零开始训练。
模型主体由一个解码器 Transformer 构成(左图所示),并额外接入一个轻量化的 action-decoder 来生成最终的操作信号。该结构使得模型在推理时只需要对主体模型进行一次前向计算,即可生成 action-decoder 所需的表征信号,从而使得整体推理速度提升 5 倍。
为了实现跨游戏通用性,P2P 采用了自回归的离散 token 序列作为操作输出空间。具体来说,每个操作由 8 个 token 表示:4 个对应键盘按键,2 个对应鼠标在水平与垂直方向上的离散位移,最后两个对应鼠标按键。这样的设计可以涵盖绝大部分游戏的操作需求。
在输入方面,除了当前帧图像与文本指令 token 外,P2P 还会输入真实操作 token,这使得模型能够根据历史操作来做决策,从而更贴近人类玩家的操作习惯。为了保证模型的因果关系,训练时使用了特殊的掩码机制(右图所示),以确保模型在预测时仅能看见历史真实操作。
模型评估
P2P 共训练了四个不同规模的模型,参数量分别为 150M,300M,600M 和 1.2B。在实测中,150M 模型可以达到 80Hz 的端到端推理速度,而最大的 1.2B 模型也能达到 40Hz,完全满足与游戏环境实时交互的需求。
模型评估的标准主要是人工评估,评估环境选取自四款游戏
-
Steam 平台上的 Quake,DOOM
-
Roblox 平台上的 Hypershot,Be a Shark
模型行为评估
在 DOOM 和 Quake 中,每个官卡设置了四个不同的起始位置(Roblox 游戏因联网机制无法固定起点),模型需从指定起点操作至下一个目标点。
人工评估采取了两两比较的方式:将 1.2B 模型生成的游戏录像与另外三个相对较小的模型录像进行人工比对。结果显示,1.2B 模型分别以 80%,83% 与 75% 的偏好度优于 150M,300M 和 600M 模型。下方视频展示了对比片段:
指令遵循评估
研究还测试了 P2P 模型理解并执行文本指令的能力。评估环境选择了 Quake 的一个迷宫关卡,该关卡要求玩家依次点亮三个红色按钮才能开门。
这个任务对于仅凭借视觉信息的模型来说很有挑战,因为 “按下按钮” 和 “不按按钮” 在行动轨迹上几乎没有区别。所以,未接受指令的模型通过率只有 20%。而当模型接收到 “按下红色按钮” 的文本指令后,模型的通过率可大幅提高到 80%,显示出了优秀的文本指令理解和执行能力。
下方视频对比了 1.2B 模型在有指令(左)和无指令(右)的情况下各运行 5 次的表现。
因果混淆分析
因果混淆是行为克隆中常见的难题,在高频的交互环境中尤其突出。例如,一个简单的策略就是直接复制上一帧的操作,这种模型在训练时,但在真实环境测试时表现就会很差。
论文对此进行了系统的研究,发现扩大模型的规模与增加训练模型的数据量能够有效提升模型对因果关系的理解能力,使其不再依赖着泪虚假关联,从而学到更好的操作策略。
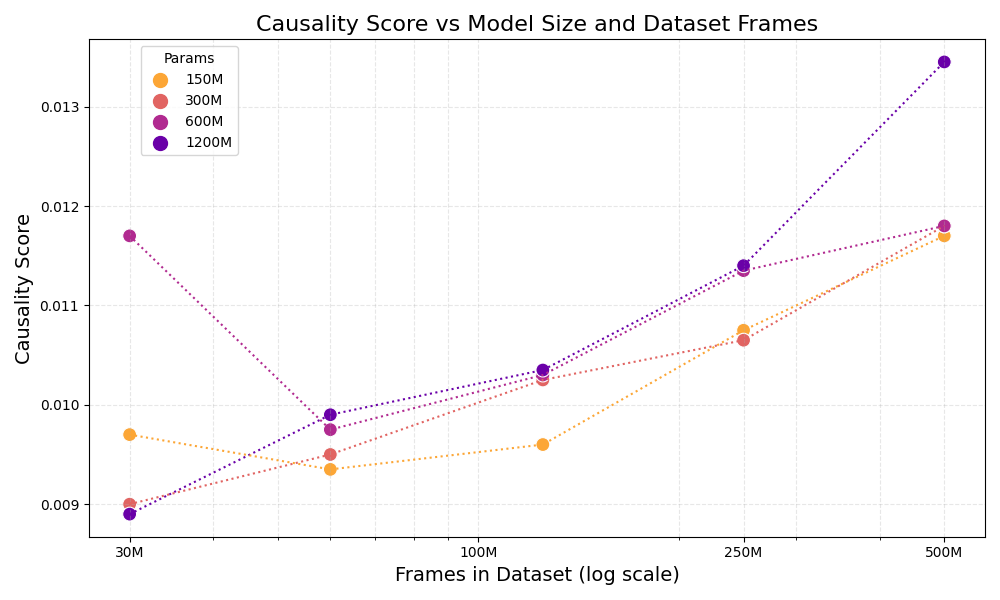
如图所示,随着训练数据增多与模型参数量增加,P2P 模型在因果推断评估中的表现呈上升趋势。
关于作者
本文第一作者岳煜光现任初创公司 Player2 研究员,负责游戏模型的开发和研究。在加入 Player2 之前,他曾先后在 Amazon 和 Twitter 担任研究人员,致力于语言模型与推荐系统的相关研究。
岳煜光博士毕业于德州大学奥斯汀分校(UT-Austin),师从周明远教授,研究方向是强化学习以及贝叶斯统计;此前他于加州大学洛杉矶分校(UCLA)取得硕士学位,本科毕业于复旦大学数学系。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com