AV-NAS:多模态视频哈希新范式,神经架构搜索驱动,音视频联合,Mamba与Transformer自动组队,提升检索效率。
原文标题:SIGIR 2025 | 视频检索新范式!北邮、北大等联合提出AV-NAS:首个音视频哈希搜索架构,让Mamba与Transformer自动“组队”
原文作者:AI前线
冷月清谈:
怜星夜思:
2、AV-NAS 强调了“数据驱动”的重要性,那么在实际应用中,如何避免 NAS 搜索到的结构过度拟合训练数据,从而导致泛化能力下降?
3、AV-NAS 揭示了音频时序建模中“CNN + FFN”优于 Transformer 的结论,这是否意味着在所有音视频任务中,CNN 都比 Transformer 更适合处理音频?这个结论对其他多模态任务有何启示?
原文内容

在海量视频检索场景中,传统方法往往“重视觉、轻听觉”,且网络结构设计更多依赖经验与人工尝试,难以同时兼顾高效存储与快速检索。那么,是否存在一种能够自动找到最优结构、并充分发挥多模态价值的方案?
近日,来自北邮与北大的研究团队提出 AV-NAS,在多模态视频哈希领域首次引入神经架构搜索(NAS),构建了一个同时覆盖 Transformer 与 Mamba 的统一搜索空间。该方法不仅使模型能够自动发现最优的跨模态融合机制(Cross-Mamba),还揭示了一个颇具启发性的结论——在音频时序建模任务中,看似简单的 “CNN + FFN” 结构竟然优于复杂的 Transformer 方案。
目前,AV-NAS 已被 SIGIR 2025 录用,相关代码已正式开源,为多模态视频检索领域提供了一条兼顾“存得下、搜得快”的全新路径。

论文题目:AV-NAS: Audio-Visual Multi-Level Semantic Neural Architecture Search for Video Hashing
论文链接: https://dl.acm.org/doi/10.1145/3726302.3729899
代码链接: https://github.com/iFamilyi/AV-NAS
从“人工设计”到
“数据驱动”的突围
在短视频与流媒体爆炸的时代,假设面对 10 亿条视频,如果用常规的 1000 维浮点向量表示,存储量将高达 8TB;而如果将其压缩为 64 位二进制哈希码,存储仅需 8GB,且通过 XOR 位运算即可实现近似 $O(1)$ 的高速检索。
然而,现有的视频哈希方法面临两个痛点:
-
听觉模态的缺位。大部分方法(如 DSVH、MCMSH、AVH 和 ConMH 等)主要依赖关键帧的视觉信息学习哈希表示,往往忽略背景音乐、语音对白等音频线索;即便有少量工作尝试引入音频,整体仍未充分挖掘声画语义的互补性。
-
架构设计的瓶颈。当前深度哈希函数通常由专家选定固定结构(如 MLP、CNN、LSTM 或 Transformer)进行训练,但手工设计的架构未必是多模态视频语义建模的最佳形态。相比之下,数据驱动的神经架构搜索(NAS)在图像等任务(如 AutoFormer、DARTS 和 GLiT 等)中已证明能发现比手工设计更优的结构,但这一思路在视频哈希场景仍缺乏系统探索。
为此,来自北京邮电大学、北京大学、北京航空航天大学及中国电信人工智能研究院的研究团队联合提出了 AV-NAS。这篇被 CCF-A 类会议 SIGIR 2025 录用的论文,核心立场非常明确:不再依赖经验“拍板”,而是构建一个面向音视频的专用搜索空间,让模型在 NAS 的驱动下自动搜索出最适合视频哈希任务的网络结构 。
统一 Mamba 与
Transformer 的搜索空间
AV-NAS(Audio-Visual Neural Architecture Search)提出了一种多层语义音视频哈希架构搜索框架,能够在统一的搜索空间内自动寻找最优的多模态哈希网络结构。其整体模型如图 1 所示,网络结构包括输入特征提取、Encoder 编码模块、Fusion 融合模块、Transformation 语义变换模块和 Hash Layer 哈希模块等。AV-NAS 设计了一个高效的三阶段架构搜索策略,训练过程中采用对比学习中常用的 InfoNCE 损失作为优化目标。
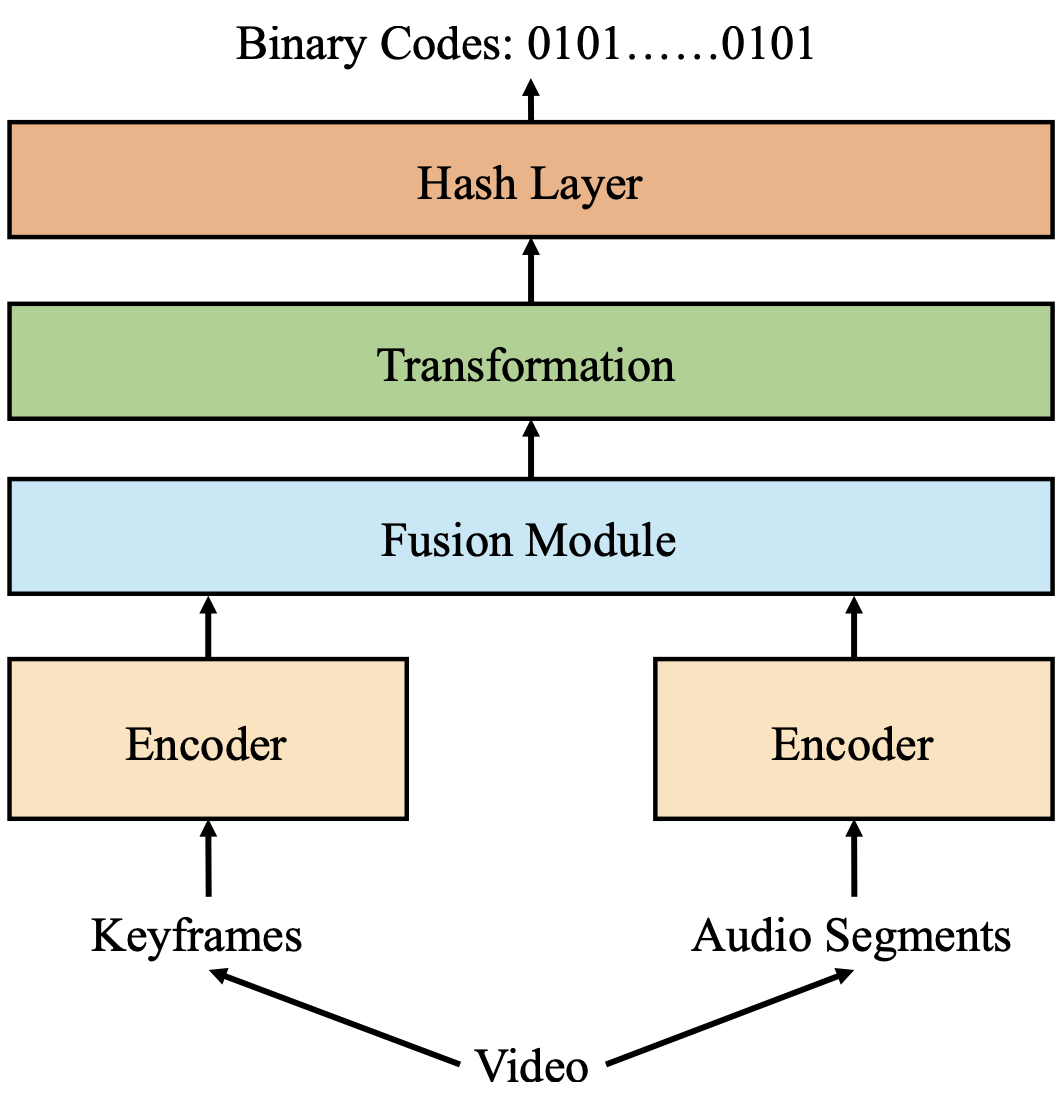
图 1:AV-NAS 整体架构
搜索空间由双路 Encoder 、Fusion 和 Transformation 组成。论文中,作者将可选算子按功能分成 6 类,如图 2 所示。其中既包含 Transformer 组件(SelfAttention / CrossAttention / FFN / LN / Skip),也包含 Mamba/SSM 组件(SelfSSM / CrossSSM 与 Up-Down 变换),并引入 CNN、MLP、GatedAttention、Add、Hadamard 等操作。
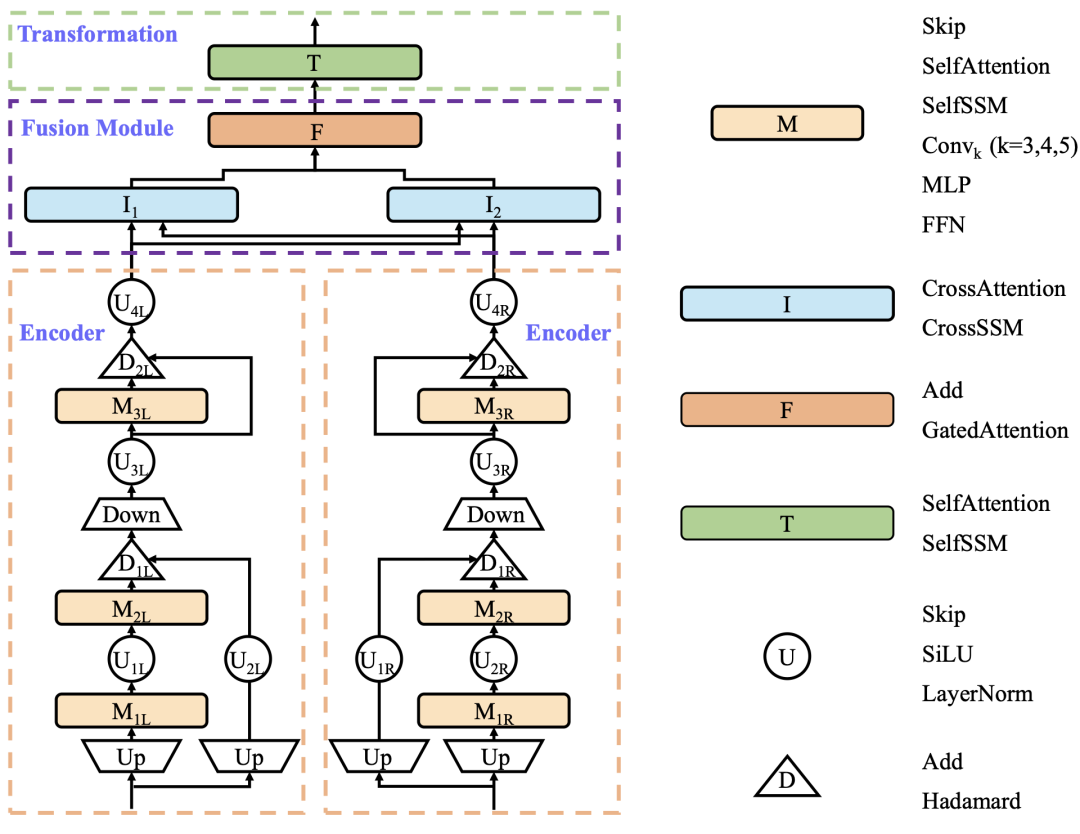
图 2:AV-NAS 的搜索空间包含 6 类操作类型:M 用于序列建模,I 用于跨模态交互,F 用于融合,T 用于变换,U 用于一元操作,D 用于二元操作。
AV-NAS 为视觉信号与音频信号设计了双路 Encoder,分别用于提取各自模态的深层时序语义表示。其关键在于:Encoder 不是固定架构,而是在 NAS 搜索空间中为每个“cell”自动选择最合适的算子组合。论文中把单模态输入记为 X∈ℝm×d,Encoder 的骨架由两段式结构组成,其前向形式为:
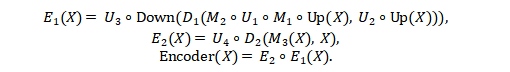
其中 Up-Down 维度变换定义为(用于兼容“先扩维再降维”的结构):
![]()
e 为扩维系数(论文中默认 e=2)。在该骨架上,M,U,D 分别对应不同类型的 cell(序列建模 / 一元变换 / 二元变换),其内部算子可从 SelfAttention,SelfSSM,Convk,MLP,FFN,LN,Skip,…中搜索选择,从而把 Transformer、Mamba、CNN、MLP 等主流范式统一到同一空间中。
论文还展示了该空间对经典结构的“可表示性”。例如,选择特定算子后可复现 Transformer encoder:
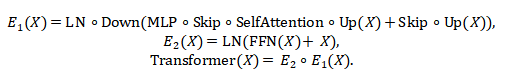
同样,通过 Up-Down 与 SSM(即 SelfSSM)等算子组合,也能兼容 Mamba 的核心形式:
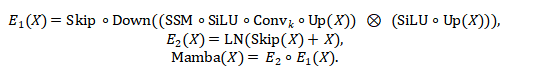
总结来说,AV-NAS 的 双路 Encoder 通过“统一骨架 + 可搜索算子”的模块化设计,可以在数据驱动下针对视觉与音频信息自动挑选最合适的序列建模单元与变换方式,学习更有效的时序语义表征,为后续 Fusion 与哈希编码提供高质量输入。
在视觉与音频分别经过各自的 Encoder 编码后,AV-NAS 得到两路时序特征表示 Ei 与 Ea。融合模块的目标是显式建模声画之间的交互关系,并输出统一的多模态表征。具体来说,先进行双向跨模态交互,再做融合汇聚。在论文中其表示为:
![]()
其中,I 表示跨模态信息交换算子,F 表示融合算子。
AV-NAS 从 Transformer 中的 CrossAttention 机制汲取灵感,提出了一种基于 Mamba 的新型跨模态融合机制,称为 CrossSSM:它借鉴 Cross-Attention 的“用另一模态来调制当前模态”的思想,但将注意力机制替换为基于 SSM 的选择性扫描,从而以更高效的序列建模方式实现跨模态对齐与信息注入,如图 3 和 4。与此同时,搜索空间也保留了更轻量的融合策略,例如 Add、Hadamard 以及门控式融合,使模型能够在“复杂交互”与“高效融合”之间自动权衡,选择最适合数据的融合路径。
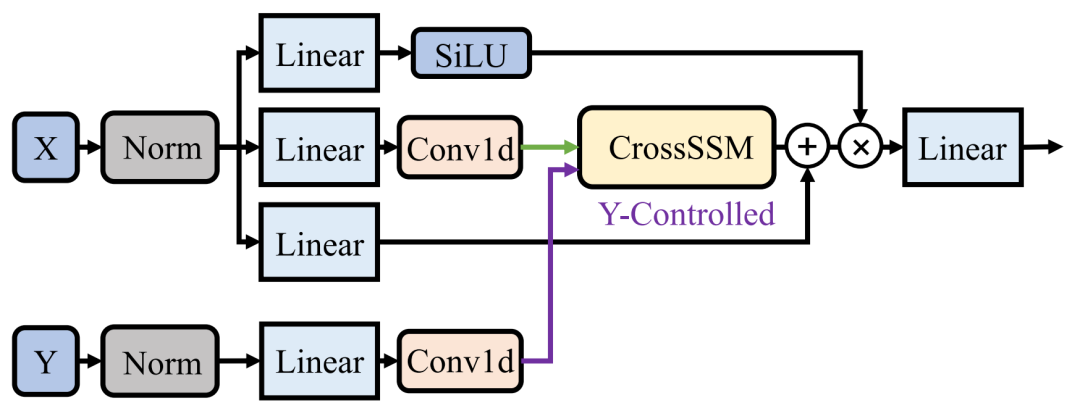
图 3:The CrossMamba Block
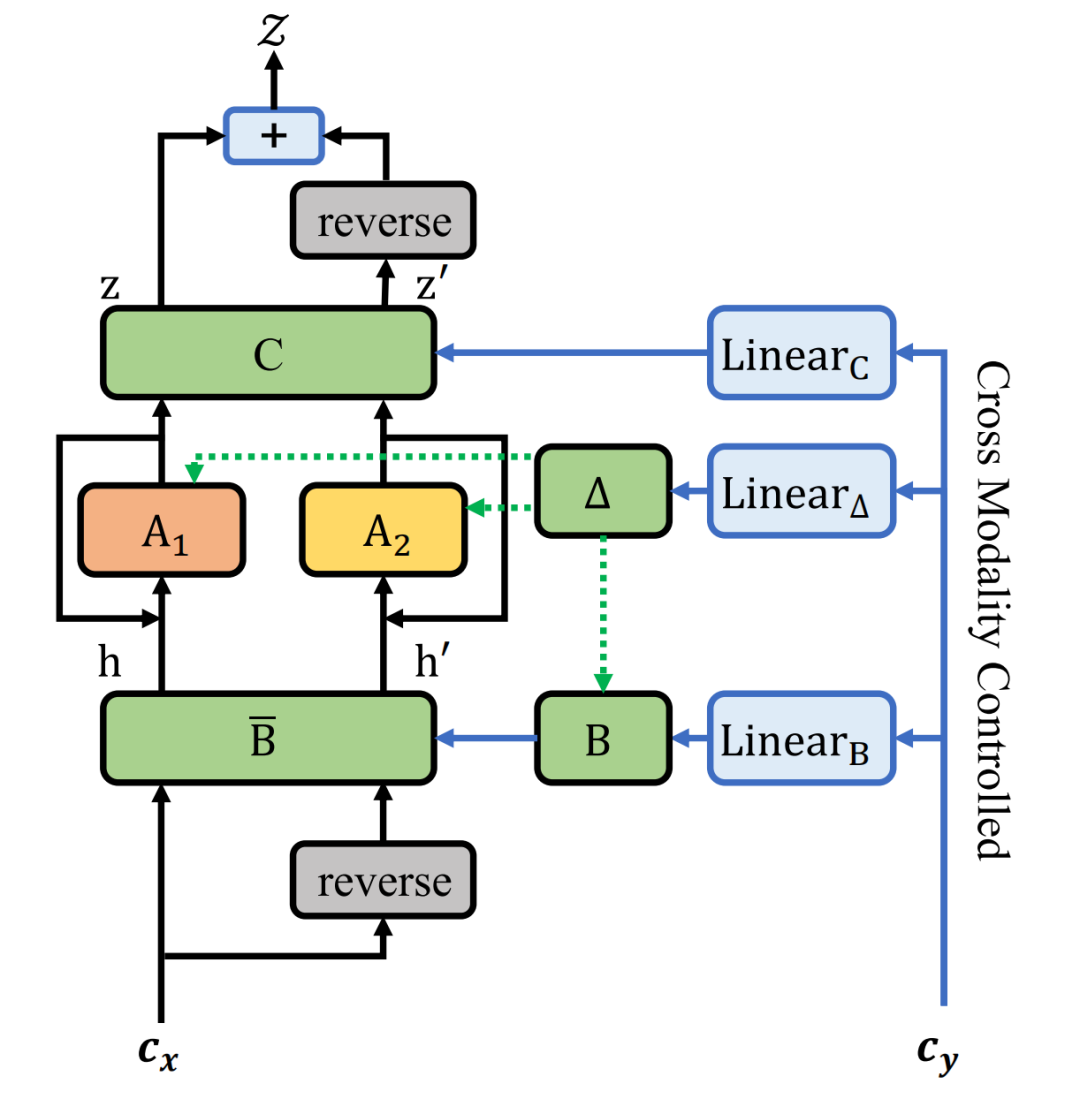
图 4:The CrossSSM Module in CrossMamba(图 3)
融合后的多模态特征仍包含较多冗余信息与复杂时序依赖,因此 AV-NAS 在 Fusion 之后引入 Transformation 模块,用于进一步提炼全局语义表征并生成更“检索友好”的表示。论文将该过程表示为:
h=T(Fo),
其中 Fo 为融合输出,h 为最终序列表示,T 是可搜索的变换算子。搜索空间中为 T 提供两种选择:SelfAttention 或 SelfSSM。
面对约 7.83×1010(每一个模块可能性算子数的连乘) 的巨大组合空间,为了在效率与效果之间取得平衡,AV-NAS 设计了一个“Coarse Search – Pruning – Fine-tune”三阶段流程。
-
Coarse Search(粗搜索):在连续松弛的搜索空间上进行联合优化,同时更新网络权重 W 与架构参数 α。具体做法是借鉴 DARTS,将每个 cell 的离散算子选择表示为 Softmax 加权的混合形式,使 α可被梯度优化;训练过程中按 epoch 在验证集上评估并保存 mAP 最优的(W*α*),得到训练好的 supernet N(W*,A(α*))。
-
Prune(剪枝):将连续架构转为离散结构。对每个混合算子计算 Softmax 概率,保留概率最高的算子、剪除其余候选,从而确定唯一的确定性架构 A*。此时网络结构固定,W 作为后续训练的初始化。
-
Fine-tune(微调):在固定架构 A*上重新训练 / 微调权重,仅优化 W 以充分适配剪枝后的网络,并在验证集上选取表现最佳的权重 W**。最终输出 AW**,作为视频哈希编码的最终模型。
AV-NAS 用 InfoNCE 训练哈希表示:对锚样本 a,取同类正样本 p 与若干异类负样本 {ni},通过拉近 a–p 相似度、拉远 a–ni 相似度来优化检索表征:
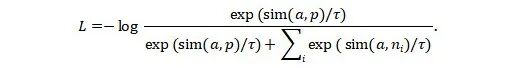
其中 τ为温度系数,sim 通常取余弦相似度函数。这样可促进同类聚合与类间分离,从而增强哈希码的检索判别性。
实验发现:AI 的
选择颠覆人类直觉
作者在两个大型视频检索数据集(ActivityNet 和 FCVID)上验证了 AV-NAS 的有效性。
在同一 AV-NAS 搜索空间下,分别在 ActivityNet 与 FCVID 上得到两套最优结构 Arch-1 和 Arch-2。两者整体框架高度一致,Fusion 与 Transformation 基本相同,差异主要集中在 Encoder 的细节组件。搜索结果在视觉建模的选择上与专家先验一致(如关键帧的时空建模),但在音频时序建模上明显偏离常见选择:更倾向 “FFN + CNN” 组合,而不是纯 Transformer 或 Mamba,体现出 NAS 能发现更贴合音频特性的结构搭配。
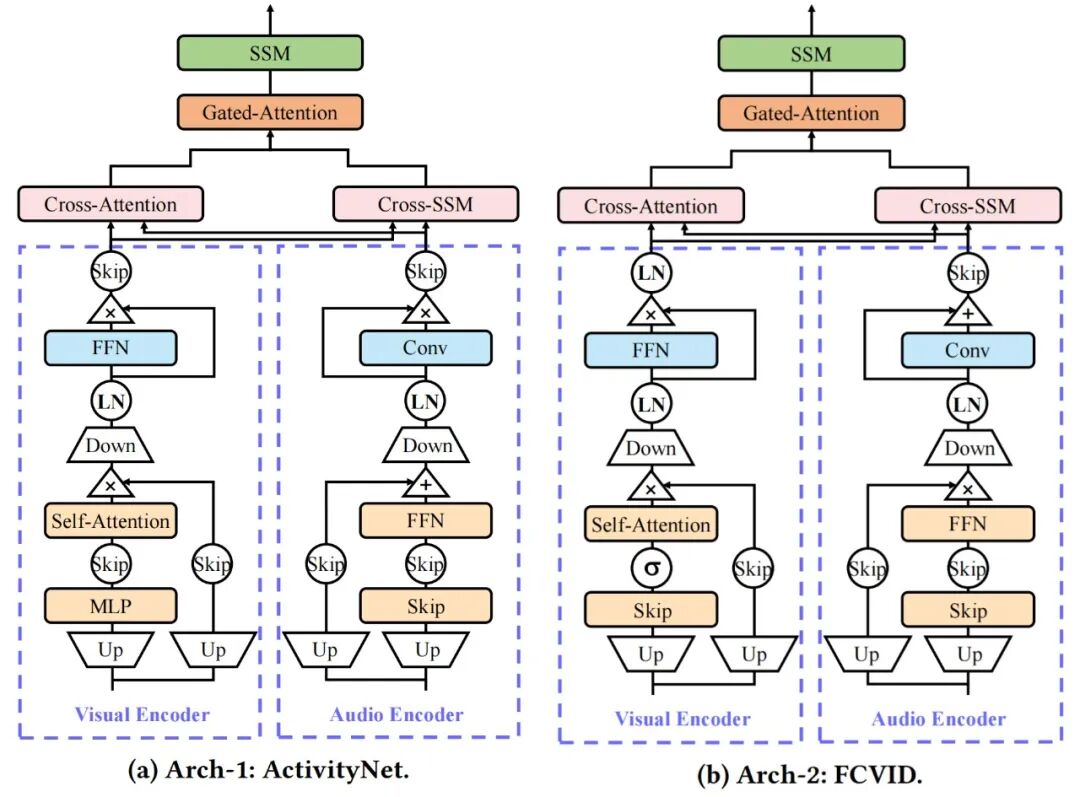
图 5:图 5a 和图 5b 分别展示了在 ActivityNet(架构 1,Arch-1)和 FCVID(架构 2,Arch-2)上搜索得到的网络架构。
表 1(行 3-11, 23-24 )展示了 AV-NAS 的实验效果。AV-NAS 在 mAP 指标上整体优于其他方法,体现了其在大规模视频检索场景中的有效性;相较于 AVHash,提升具有统计显著性(p-value < 0.05)。其中,Arch-1(ActivityNet 最优)与 Arch-2(FCVID 最优)分别取得了在各自数据集上的最高 mAP;在交叉测试中,由于两者结构高度相似、差异主要集中在 Encoder 细节,因此检索指标仍能保持在较高水平且波动很小。
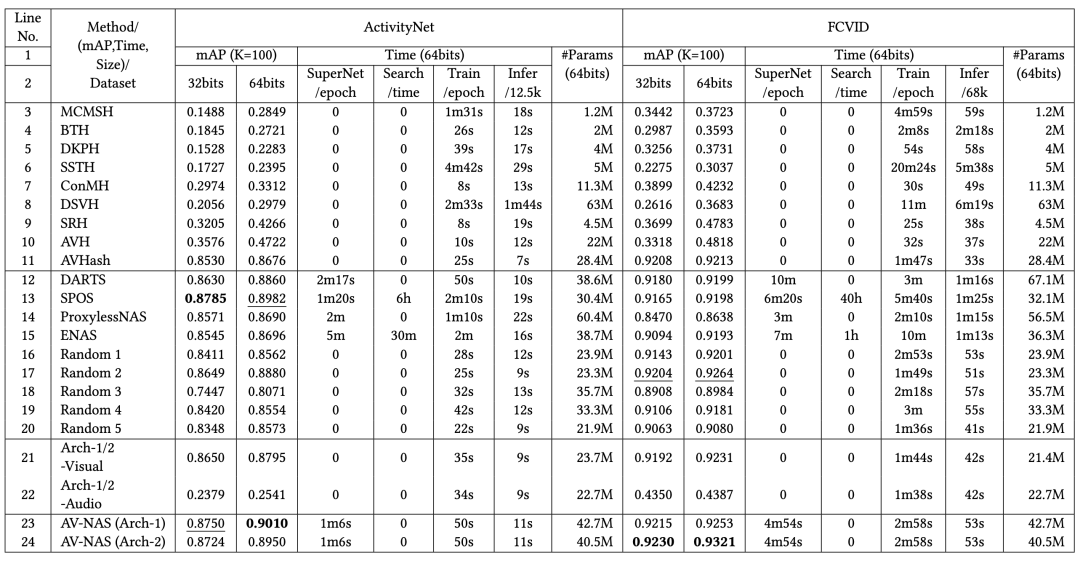
表 1:在 mAP、时间效率 和 模型大小 方面与 SOTA(最先进)方法 的性能对比。
作者将 AV-NAS 与三类“专家手工设计”多模态网络对比:Transformer、Transformer+(加入 cross-attention)、Mamba,对比结果展示在表 2 中。从表中可以看出, AV-NAS 在 ActivityNet/FCVID 的 32-bit 与 64-bit mAP@100 均为最高,相对最强专家基线在 ActivityNet 上提升约 3–4%,在 FCVID 上提升约 1%,证明 NAS 搜索到的结构确实更适配音视频哈希任务。
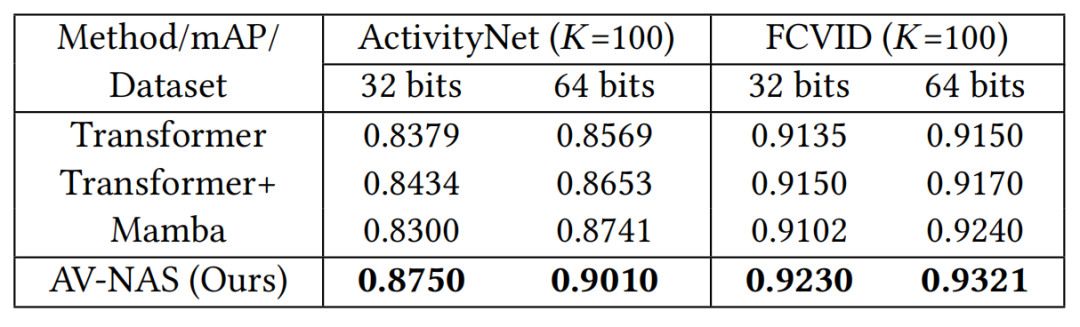
表 2:纯 Transformer 或纯 Mamba 架构与 AV-NAS 搜索得到的架构之间的对比。
进一步观察上一节图 5 中展示的搜索到的网络架构可以发现:在音频语义的时序建模上,AV-NAS 并没有选择更“主流”的纯 Transformer/Mamba,而是更偏好一种 FFN+CNN 的组合来负责音频语义时序建模。直观上,FFN 更擅长整合音高、音色、情绪等更偏全局 / 线性的整体特征;而 CNN 则更容易捕捉局部的短时模式与局部变化。两者结合,有助于更全面地刻画音频语义。
为了验证跨模态交互与融合的有效性,作者进行了两组“单模态”对照实验,结果汇总见表 1 (行 21-22)。去掉音频或去掉视觉(并将 Fusion 替换为 self-fusion)都会明显降低性能,说明声画融合是提升检索质量的关键;视觉通常占主导,但音频能提供稳定增益,与 AVHash 的结论一致。
如表 1 (行 12-20, 23-24)所示,在同一搜索空间下,AV-NAS 相比 DARTS、ProxylessNAS、SPOS、ENAS 在 时间效率与性能稳定性上更有优势,并能在两个数据集上稳定取得最高 mAP;随机搜索结果波动较大,进一步体现系统化 NAS 的必要性。
AV-NAS 是多模态视频哈希领域在 NAS 方向的破冰之作。它不仅证明了“自动搜索”比“手工设计”更可靠,更通过数据驱动的方式揭示了视听多模态处理的最佳实践:视觉依赖时空注意力,音频偏好局部与全局的简单组合,而跨模态融合则是 Mamba (SSM) 大显身手的舞台 。
这项工作为未来大规模视频检索系统的设计提供了全新的思路:与其盲目堆叠复杂的 Transformer,不如把选择权交给数据,让模型自己找到“视”与“听”的最佳平衡点。
参考文献
Hanqing Chen, Chunyan Hu, Feifei Lee, Chaowei Lin, Wei Yao, Lu Chen, and Qiu Chen. 2021. A Supervised Video Hashing Method Based on a Deep 3D Convolutional Neural Network for Large-Scale Video Retrieval. Sensors 21, 9 (2021), 3094.
Yanbin Hao, Jingru Duan, Hao Zhang, Bin Zhu, Pengyuan Zhou, and Xiangnan He. 2022. Unsupervised Video Hashing with Multi-granularity Contextualization and Multi-structure Preservation. In ACM Multimedia. 3754–3763.
Wenna Wang, Xiuwei Zhang, Hengfei Cui, Hanlin Yin, and Yanning Zhang. 2023. FP-DARTS: Fast parallel differentiable neural architecture search for image classification. Pattern Recognit. 136 (2023), 109193:1–109193:11.
Yingxin Wang, Xiushan Nie, Yang Shi, Xin Zhou, and Yilong Yin. 2021. Attention Based Video Hashing for Large-Scale Video Retrieval. IEEE Trans. Cogn. Dev. Syst. 13, 3 (2021), 491–502.
Minghao Chen, Houwen Peng, Jianlong Fu, and Haibin Ling. 2021. AutoFormer: Searching Transformers for Visual Recognition. In ICCV. 12250–12260.
Hanxiao Liu, Karen Simonyan, and Yiming Yang. 2019. DARTS: Differentiable Architecture Search. In ICLR.
Boyu Chen, Peixia Li, Chuming Li, Baopu Li, Lei Bai, Chen Lin, Ming Sun, Junjie Yan, and Wanli Ouyang. 2021. GLiT: Neural Architecture Search for Global and Local Image Transformer. In ICCV. 12–21.
《2025 年度盘点与趋势洞察》由 InfoQ 技术编辑组策划。覆盖大模型、Agent、具身智能、AI Native 开发范式、AI 工具链与开发、AI+ 传统行业等方向,通过长期跟踪、与业内专家深度访谈等方式,对重点领域进行关键技术进展、核心事件和产业趋势的洞察盘点。
力求以体系化视角帮助读者理解年度技术演化的底层逻辑、创新方向与落地价值,并为新一年决策提供参考。内容将在 InfoQ 媒体矩阵陆续放出,欢迎大家持续关注。

你也「在看」吗?👇