几天前,ICLR 2024 的最终接收结果出来了。
大家应该还记得,Mamba 被 ICLR 2024 大会 Decision Pending(待定)的消息在 1 月份引发过一波社区热议。
当时,多位领域内的研究者分析,Decision Pending 的意思是延迟决定,虽然也可能会被拒,但这篇论文得到了 8/8/6/3 的打分,按理说不至于真被拒。

论文审稿页面:https://openreview.net/forum?id=AL1fq05o7H
如今,Decision 已出,Mamba 彻底被拒,悬着的心终于死了。

「Mamba」发布之初即被视为「Transformer 的强劲竞争者」,它是一种选择性状态空间模型(selective state space model),在语言建模方面可以媲美甚至击败 Transformer。而且,它可以随上下文长度的增加实现线性扩展,其性能在实际数据中可提高到百万 token 长度序列,并实现 5 倍的推理吞吐量提升。
但对于 ICLR 审稿人来说,这篇论文还存在重大缺陷(至少针对当前版本)。
手握 8/8/6/3 得分,究竟为什么被拒?
重新查看 OpenReview 页面之后,我们发现了新的审稿意见。
ICLR 区域主席给出的最终说法是:论文使用的评估方法有争议。
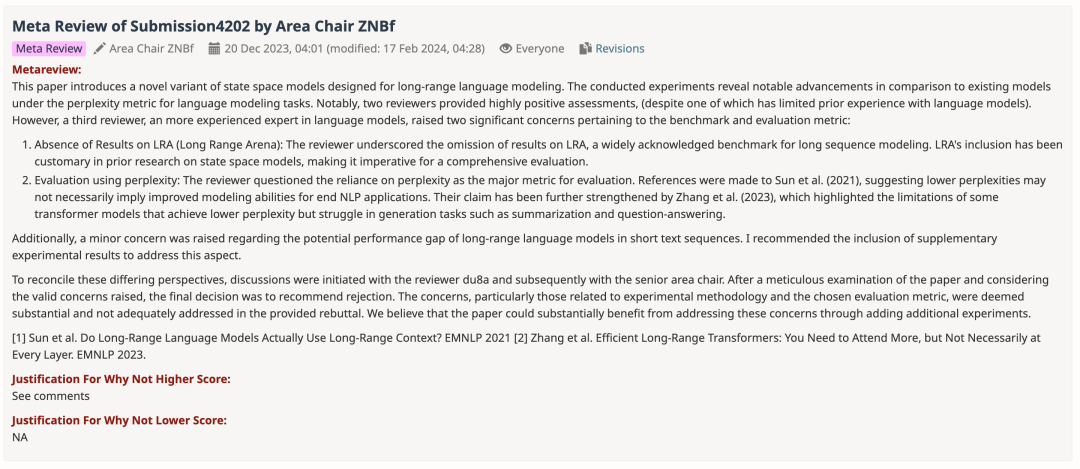
审稿意见整理如下:
本文介绍了一种为远距离语言建模而设计的新型状态空间模型变体。实验表明,在语言建模任务的困惑度指标下,该模型与现有模型相比有显著进步。值得注意的是,两位审稿人给出了非常积极的评价(尽管其中一位审稿人在语言模型方面经验有限)。然而,第三位审稿人,一位在语言模型方面更有经验的专家,提出了两个与基准和评估指标有关的重大问题:
1. 缺少 LRA(Long Range Arena)的结果:审稿人强调缺少 LRA 的结果,而 LRA 是公认的长序列建模基准。在之前的状态空间模型研究中,LRA 已成为惯例,因此必须对其进行全面评估。
2. 使用困惑度进行评估:审稿人质疑将困惑度作为主要评价指标的做法。论文引用了 Sun et al. (2021)(《Do Long-Range Language Models Actually Use Long-Range Context?》)的观点,他们认为较低的困惑度并不一定意味着最终 NLP 应用的建模能力有所提高。Zhang et al. (2023)(《Efficient Long-Range Transformers: You Need to Attend More, but Not Necessarily at Every Layer》)进一步加强了他们的观点,他们强调了一些 transformer 模型的局限性,这些模型虽然实现了较低的困惑度,但在生成任务(如摘要和问题解答)中却举步维艰。
此外,还有人对长序列语言模型在短文本序列中的潜在性能差距表示担忧。我建议加入补充实验结果来解决这方面的问题。
为了调和这些不同的观点,我们与审稿人 du8a 进行了讨论,随后又与高级区域主席进行了讨论。在对论文进行细致审查并考虑到所提出的合理关切后,最终决定建议拒绝该论文。这些问题,尤其是与实验方法和所选评价指标有关的问题,被认为是实质性的,在所提供的 rebuttal 中没有得到充分解决。我们认为,通过增加额外的实验来解决这些问题,对论文将大有裨益。
同样被 ICLR 拒绝的神作:「 Word2vec」
Mamba 的经历,让人们想起了十年前的一篇论文。
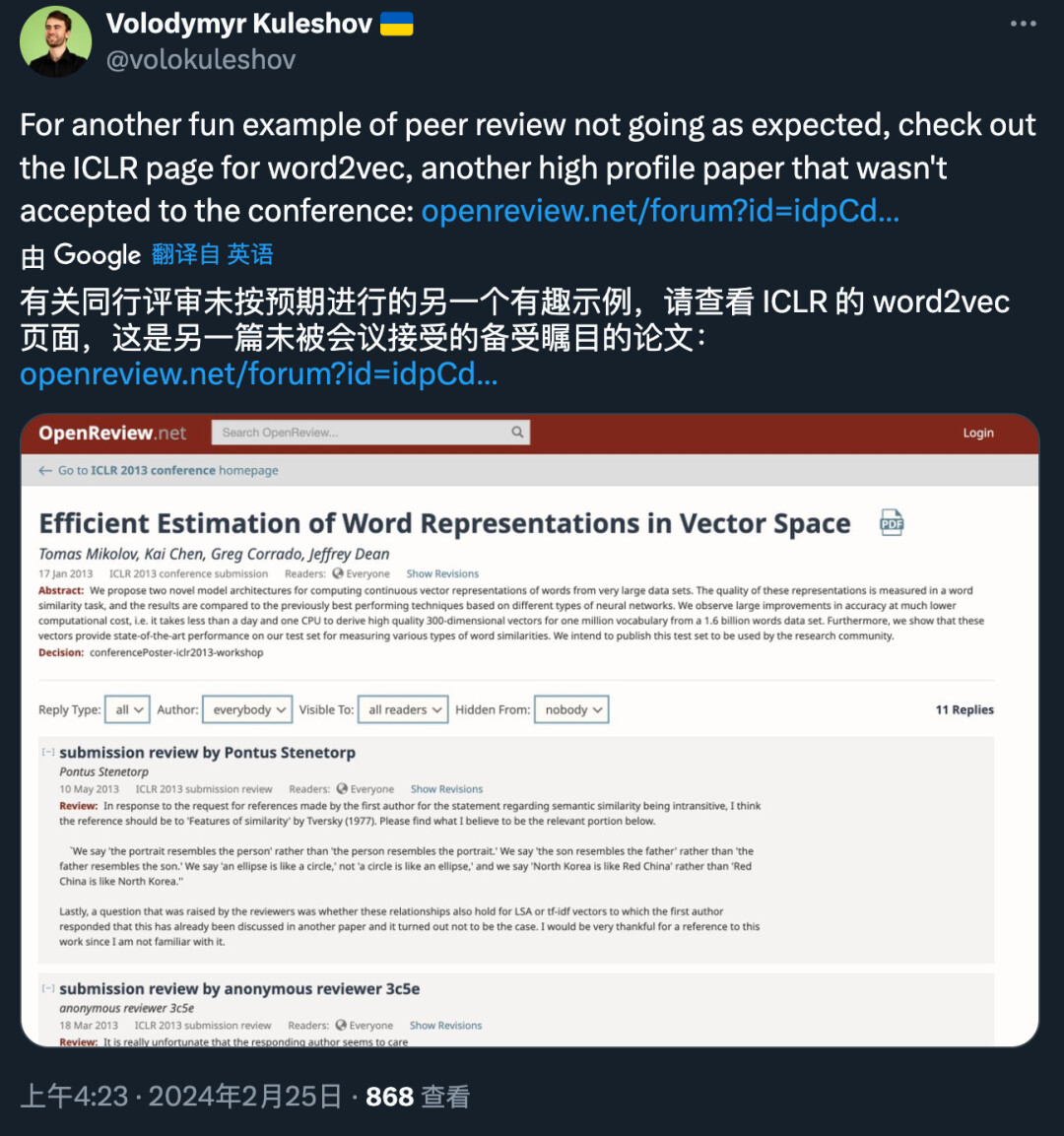
图中提到的是关于的 Word2vec 首篇论文《Efficient Estimation of Word Representations in Vector Space》,由 Tomas Mikolov 等四位谷歌研究者共同完成。

论文链接:https://arxiv.org/pdf/1301.3781.pdf
这篇论文在 2013 年首届 ICLR 会议被拒了,尽管当年的接收率比较高。去年, Tomas Mikolov 在梳理 Word2vec 发展历程的时候还遗憾提到:「这让我想到审稿人预测论文的未来影响是多么困难。」
但细看之下,Word2vec 被拒的原因倒是和一般论文不同。
在 OpenReview 的页面,我们看到当时几位审稿人针对提交版本给到了一波意见,比如补充定义模型的方程等等。
审稿页面:https://openreview.net/forum?id=idpCdOWtqXd60
而 Tomas Mikolov 的回复态度偏强硬,显然也没有充分完善对应每条审稿意见的材料,导致几位审稿人看完了 rebuttal,更生气了。
一位审稿人最终给出「Strong Reject」:

另一位审稿人曾给出「大部分内容清晰良好」的评论,但后来也修改为「Weak Reject」:

还有一位审稿人直白地指出:
「令人遗憾的是,答辩作者似乎只关心他的模型和模型组合的每一个可能的调整,却对合理的科学对比表现出强烈的漠视。」
「作者写道,有许多显而易见的实际任务,他们的词向量应该有所帮助,但却没有展示或提及任何任务。」
「除了他自己的模型、数据集和任务之外,作者似乎更愿意忽略所有其他的东西。我仍然不清楚是模型的哪个部分带来了性能提升。是顶层任务还是词向量的平均化?」
「链接到作者在维基百科上发表的一篇文章并不能作为有力的论据,还不如显示出指出实际差异的方程式。经过审稿人之间的讨论,我们一致认为论文的修订版和随附的 rebuttal 并没有解决审稿人提出的许多问题,审稿人的许多问题(如哪些模型包含非线性)仍未得到回答。」

总之,这次审稿闹得不太愉快。
后来,四位作者 Tomas Mikolov、Kai Chen、Greg Corrado、Jeffrey Dean 和当时在谷歌任职的 Ilya Sutskever 又写了一篇关于 Word2vec 的论文《Distributed Representations of Words and Phrases and their Compositionality》,转投 NeurIPS 且被顺利接收了。
去年,这篇论文还获得了 NeurIPS 2023 的时间检验奖,获奖理由是「这项工作引入了开创性的词嵌入技术 word2vec,展示了从大量非结构化文本中学习的能力,推动了自然语言处理新时代的到来」。
可惜的是,后续几位作者的关系陷入僵局,Tomas Mikolov 透露的版本是:
我在谷歌 Brain 内部多次讨论过这个项目,主要是与 Quoc 和 Ilya,在我转到 Facebook AI 后他们接手了这个项目。我感到非常意外的是,他们最终以「从序列到序列(sequence to sequence)」为名发表了我的想法,不仅没有提到我是共同作者,而且在长长的致谢部分提及了谷歌 Brain 中几乎所有的人,唯独没有我。那时是资金大量涌入人工智能领域的时期,每一个想法都价值连城。看到深度学习社区迅速变成某种权力的游戏,我感到很悲哀。
神作的影响力,时间自会证明
从 Mamba 的 OpenReview 页面来看,本次审稿过程中并没有「不够冷静」的成员。
汇总所有审稿人的意见之后,作者团队及时对论文内容进行了修改和完善,补充了详尽的实验结果和分析。但正如审稿人所说,仍然「缺少 LRA(Long Range Arena)的结果」,导致最终被拒。
与此同时,一位细心的网友发现,热门的开源多模态大模型 CogVLM 也被这次 ICLR 拒了。


对于 Mamba、CogVLM 的作者团队来说,拒稿是一种令人遗憾的结果,但换个角度想,研究的真正价值不会仅由某一个学术会议而界定,也不会因此被埋没。伴随着理论研究的不断突破,Mamba 和 CogVLM 或许将衍生出更多有意义的成果,同样有机会开启一个新的时代。

推荐阅读:

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com