掌握信创服务器数据库NUMA调优:OS配置、绑核策略、超线程协同,解锁国产硬件最佳性能!
原文标题:数据库信创服务器NUMA调优
原文作者:牧羊人的方向
冷月清谈:
怜星夜思:
2、文章中提到了关闭透明大页(THP)对于数据库性能的重要性。但是,在某些其他应用场景下,THP可以提升性能。你认为在信创环境下,如何判断一个应用是否适合开启THP?
3、文章提到了在高并发访问相同内存块的场景下,NUMA绑核可以有效解决性能问题。除了NUMA绑核,你认为还有哪些其他的优化手段可以缓解这种场景下的性能瓶颈?
原文内容
数据库信创服务器多数运行在鲲鹏ARM、海光C86等国产CPU架构下,并且存在多个NUMA节点访问。对于跨NUMA节点的访问,在数据库某些高并发场景下,可能会存在一定的性能问题,针对这些性能问题,如何进行优化。本文先介绍数据库信创服务器OS层的一些配置,然后介绍了NUMA节点的调优和绑核操作,以及超线程协同调优,以更好的提升服务器的资源利用和数据库的性能。
1、操作系统层配置
1)CPU运行频率控制
CPU频率调节器决定了CPU如何调整其工作频率以平衡性能与功耗。对于数据库服务器,稳定且低的查询延迟至关重要,因此推荐设置为performance模式。该模式会使所有CPU核心锁定在支持的最高基础频率上运行,消除了动态调频带来的性能波动和额外的时钟周期开销,确保数据库计算任务获得持续、最强的算力支持。
-
可选值:performance、powersave、ondemand等
-
作用:调节CPU运行频率以平衡性能与功耗
-
推荐值:数据库服务器建议设置为performance模式,最大化计算能力
通过cpupower frequency-info查看频率的配置信息
$ cpupower frequency-info
analyzing CPU 0:
driver: intel_pstate
CPUs which run at the same hardware frequency: 0
CPUs which need to have their frequency coordinated by software: 0
maximum transition latency: Cannot determine or is not supported.
hardware limits: 800 MHz - 4.20 GHz
available cpufreq governors: performance powersave
current policy: frequency should be within 800 MHz and 4.20 GHz.
The governor "performance" may decide which speed to use
within this range.
current CPU frequency: 4.15 GHz (asserted by call to hardware)
boost state support:
Supported: yes
Active: yes
cpupower monitor:实时监控频率与状态
$ cpupower monitor
CPU | C0 | Cx | Freq || C0 | Cx | Freq || POLL | C1 | C2 | C3
0| 4.42| 95.58| 4184|| 4.45| 95.55| 4183|| 0.00| 0.12| 95.43| 0.00
1| 99.55| 0.45| 4187|| 99.58| 0.42| 4187|| 0.00| 0.42| 0.00| 0.00
2| 3.01| 96.99| 4159|| 3.04| 96.96| 4158|| 0.00| 0.08| 96.88| 0.00
3| 98.99| 1.01| 4192|| 99.02| 0.98| 4192|| 0.00| 0.98| 0.00| 0.00
在performance模式下,所有核心的频率应持续在高位,并且Freq不应该出现明显的波动。
2)tuned配置
tuned是针对系统的一项服务,提供配置文件调整机制,根据系统状态调整系统配置,达到系统优化的目的。tuned-adm是配合tuned服务的工具,其预置了多种系统参数配置文件,通过调节调度时间、脏页刷新水位、CPU性能模式等参数,来适应不同的业务。
-
推荐值:数据库服务器建议配置为throughput-peformance模式,通过tuned-adm peformance进行配置
3)超线程控制
超线程技术将一个物理CPU虚拟为两个逻辑核,以提高CPU资源的利用率。对于数据库负载,通常建议开启超线程以提升系统的整体并发处理能力。但是在已实施NUMA绑核的情况下,需要特别注意绑核策略:应将数据库进程绑定到物理CPU(如CPU 0,1,0和1是两个不同的物理CPU),不能绑定到由超线程产生的两个逻辑CPU(例如,CPU 0和1对应同一个物理CPU)。这样可以避免同一个物理核心上的两个高强度线程相互竞争CPU资源,导致性能下降。
-
配置方法:BIOS中设置Logical Processor=Enabled,或通过echo on > /sys/devices/system/cpu/smt/control开启
-
推荐值:根据实际压测结果是否开启,需与绑核策略配合
1)关闭交换空间vm.swappiness
虚拟内存空间,用于存放未被使用的数据或将不活跃的进程移到磁盘上,以释放物理内存空间供其它进程使用。当内存不足时系统频繁的将数据交换到磁盘时,会导致性能下降。在数据库使用场景中需要关闭swap。
-
推荐值:数据库服务器建议设置为0,减少内存交换,如echo 0 > /proc/sys/vm/swappiness
2)关闭透明大页
透明大页是内核自动将小页面合并成大页面的功能,旨在减少TLB未命中次数。但对于数据库应用,强烈建议将其关闭(设为 never)。因为数据库自身有更优化的内存管理策略,内核自动、异步地合并大页会导致不可预测的进程停顿和性能抖动,弊大于利。
-
作用:控制透明大页内存功能
-
默认值:always
-
推荐值:数据库服务器建议禁用以避免碎片化,如echo never > /sys/kernel/mm/transparent_hugepage/enabled
3)系统保留的最小内存空间vm.min_free_kbytes
min_free_kbytes定义了系统保留的最低空闲内存。当系统空闲内存低于此阈值时,内核会开始积极回收内存,优先回收的是页面缓存。对于高吞吐、高并发的数据库服务,设置一个合理的值(如总内存的1%-3%)可以保证系统即使在内存压力下也有足够的内存用于满足即时分配请求。
-
推荐值:保证物理内存有足够空闲空间,防止突发性换页,要求至少有5%的空闲空间。
4)NUMA内存分配:numa_balancing
在NUMA架构中,numa_balancing是内核试图通过迁移页面,使进程内存尽量靠近其运行的CPU的功能。对于已经通过numactl等工具进行了精细绑核的数据库服务器,应关闭此功能。因为数据库自身和绑核策略已经确保了内存访问的本地化,内核的自动平衡反而会引入不必要的页面迁移开销,干扰数据库稳定运行。
-
作用:控制自动内存迁移功能
-
默认值:1(开启)
-
推荐值:数据库服务器开启NUMA绑核后建议关闭,如echo 0 > /proc/sys/kernel/numa_balancing
1)连接队列参数:net.core.somaxconn
net.core.somaxconn定义了TCP监听队列的最大长度。对于可能面临突发高并发连接的数据库,默认值128过低,可能导致连接被丢弃,建议提高至 2048 以上。
-
作用:定义TCP连接等待队列的最大长度
-
默认值:128
-
推荐值:高并发场景建议设置为4096,如echo 4096 > /proc/sys/net/core/somaxconn
2)缓冲区大小参数:net.core.rmem_max、net.core.wmem_max
定义了单个socket读写缓冲区的最大上限。数据库在执行大量数据查询或备份时,需要更大的网络缓冲区来提升吞吐量。建议将两者均设置为 16777216(16MB),为高流量场景预留空间。
-
作用:设置TCP接收/发送缓冲区的最大值
-
默认值:212992
-
推荐值:提升网络吞吐量可设置为16777216,如echo 16777216 > /proc/sys/net/core/rmem_max
3)irqbalance服务
当网卡收到大量请求时,会产生大量的中断,通知内核有新的数据包,然后内核调用中断处理程序响应,把数据包从网卡拷贝到内存。当网卡只存在一个队列时,同一时间数据包的拷贝只能由某一个核处理,无法发挥多核优势,因此引入了网卡多队列介质,这样同一时间不同core可以分别从不同网卡队列中取数据包。在网卡开启多队列时,操作系统通过irqbalance服务来确定网卡队列中的网络数据包交由哪个CPU core处理。但是当处理中断的CPU core和网卡不在一个NUMA时,会触发跨NUMA访问内存。
-
推荐值:irqbalance服务默认开启,根据压测结果是否开启网卡中断绑核,一般不启用网卡中断绑核。
1)IO调度策略/sys/block/$DEVICE-NAME/queue/scheduler
当内核组件要写一些数据时,并不是请求一发出,内核便立即执行该请求,而是将其推迟执行。当传输一个新数据块时,内核需要检查它能否通过。I/O调度程序是介于通用块层和块设备驱动程序之间,所以它接收来自通用块层的请求,试图合并请求,并找到最合适的请求下发到块设备驱动程序中,之后块驱动设备程序会调用一个函数来响应请求。
-
可选值:deadline、cfq、noop、anticipatory
-
作用:控制磁盘I/O请求的排序和合并策略
-
推荐值:数据库场景建议使用deadline算法,可设置为echo deadline > /sys/block/sda/queue/scheduler
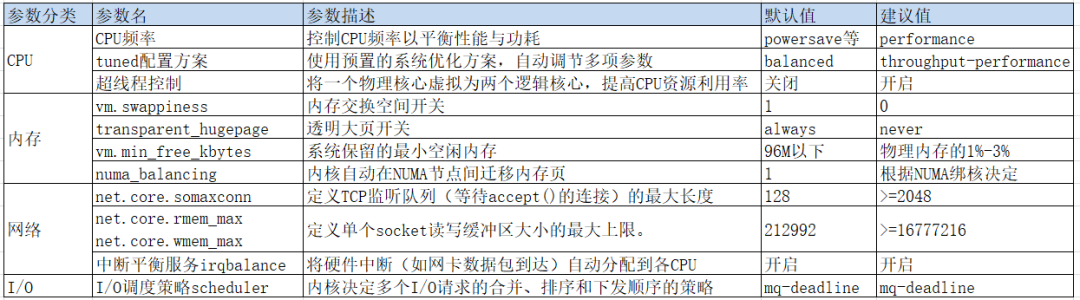
在数据库服务器中操作系统层相关的参数远不止这些,不同数据库的配置可能还有些不同。以下是主要的参数配置情况:
2、跨NUMA节点性能问题
在信创服务器如海光X86架构、鲲鹏ARM架构下,普遍采用NUMA(非统一内存访问)架构。NUMA架构可以提升CPU的处理性能和CPU的扩展性,但是默认情况下非统一的内存访问存在CPU跨NUMA节点访问远程内存的问题,在数据库高并发的业务访问情况下出现性能劣化和高延迟的问题。
1)SMP处理器架构
在多核CPU、多内存通道的服务器架构中,传统的SMP(Sysmmetric Multi-Processor System,对称多处理器系统),由多个具有对称关系的处理器组成。所谓对称,即处理器之间没有主从之分。SMP的结构特征就是「多处理器共享一个集中式存储器」,每个处理器访问存储器所需的时间一致,工作负载能够均匀的分配到所有可用处理器上,极大地提高了整个系统的数据处理能力。
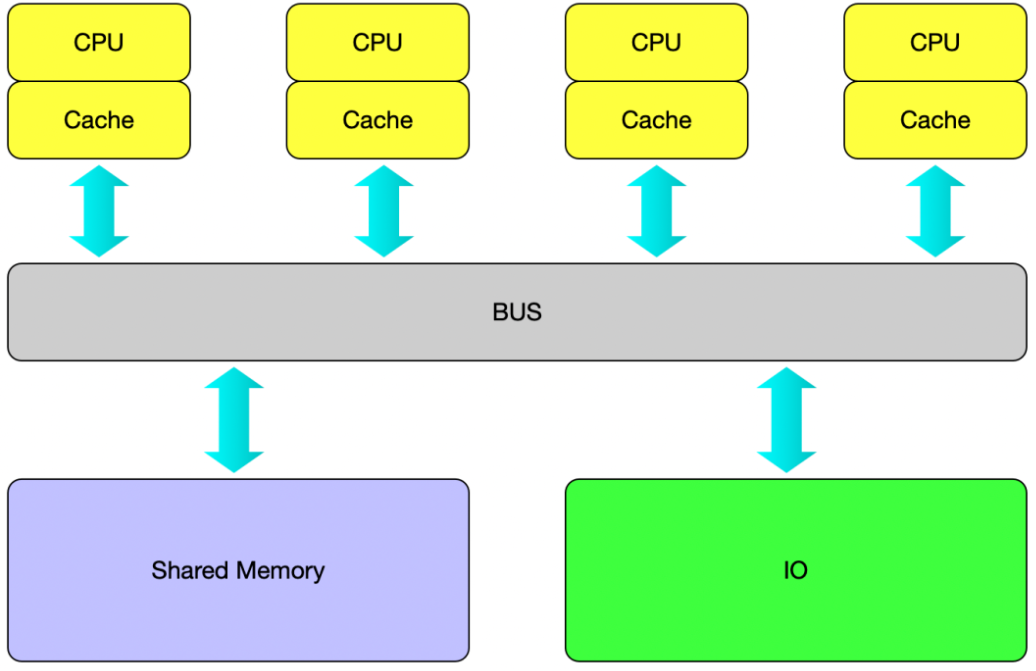
但是传统的SMP(对称多处理)架构存在性能瓶颈:1)如果多个处理器同时请求访问共享资源时,就会引发资源竞争,需要软硬件实现加锁机制来解决这个问题;2)所有CPU共享同一内存总线,当核心数增加时,内存总线的带宽会成为瓶颈。这些问题导致CPU访问内存的延迟升高、吞吐量下降。
2)NUMA处理器架构
NUMA(Non-Uniform Memory Access)是一种多处理器计算机内存设计,它将整个系统划分为多个节点(Node)。每个节点包含一组本地的CPU核心和本地的DRAM内存。节点之间通过高速互连总线(如华为的HCCS、Intel的QPI/UPI)相连。通俗的理解就是NUMA把服务器的 “CPU核+本地内存+PCIe插槽”打包成一个独立的“资源单元”,这个单元就是NUMA节点。以华为鲲鹏920(2-Socket, 64物理核)为例:
-
系统构成:共有2个物理CPU插槽,形成2个NUMA节点。
-
CPU分布:总共64个物理核心,均匀分布在2个节点上。Node 0包含物理核0-31,Node 1包含物理核32-63。
-
内存分布:若服务器总内存为512 GiB,则每个NUMA节点各分配256 GiB本地内存。
可以使用numactl --hardware命令查看本机的具体NUMA拓扑信息。
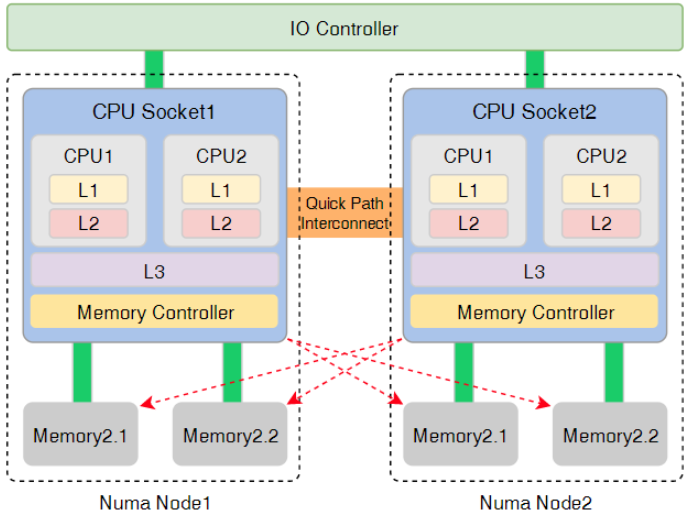
NUMA架构的核心作用是通过区分“本地内存”和“远程内存”来优化内存访问性能:
-
降低内存访问延迟:CPU访问其所在节点的本地内存延迟极低(典型值约80 ns),而访问其他节点(远程内存)则需要通过互连总线,延迟显著增高(典型值约150-200 ns)。
-
提升内存带宽:每个NUMA节点有独立的内存控制器,多节点并行访问内存可以聚合系统总内存带宽,避免了传统SMP(对称多处理)架构中所有CPU争抢单一内存总线的瓶颈。
-
资源隔离:NUMA的节点划分天然提供了一种物理层面的资源隔离。可以将对性能敏感、高并发的业务绑定在特定节点上,避免其受到其他业务的干扰,减少跨节点资源竞争。
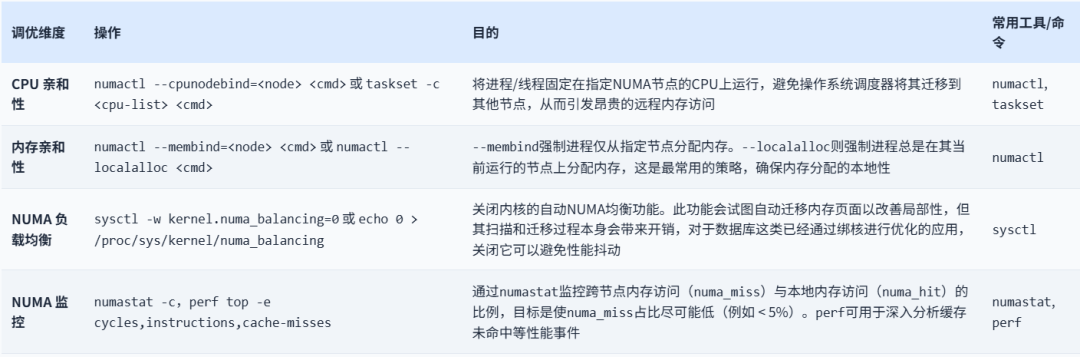
在数据库服务器中,跨NUMA的访问会存在远程内存访问延迟远高于本地内存访问,在高并发的内存访问情况下需要频繁跨节点访问数据,累积的延迟会使查询响应时间大幅增加。因此NUMA调优的核心思想是"让计算靠近数据",即确保进程或线程尽可能访问其本地NUMA节点的内存。
-
CPU亲和性:将进程/线程固定在指定NUMA节点的CPU上运行,避免操作系统调度器将其迁移到其他节点
-
内存亲和性:–membind强制进程仅从指定节点分配内存
-
NUMA负载均衡:关闭内核的自动NUMA均衡功能。
-
NUMA监控:通过numastat监控跨节点内存访问(numa_miss)与本地内存访问(numa_hit)的比例
NUMA绑核,也称为NUMA Pinning,是一种更严格的亲和性策略。它通过工具或系统调用,将一个进程(及其所有线程)的CPU执行和内存分配都强制限制在同一个NUMA节点内。这样可以从根本上保证该进程的所有内存访问都是本地访问,从而获得最低的内存访问延迟和最高的内存带宽。
1)NUMA绑核方式
在启动数据库进程时指定绑定的CPU节点或内存节点
numactl --cpunodebind=0 xxxx
numactl -- membind=0 xxxx
在容器环境中可以通过–cpuset-cpus和–cpuset-mems参数实现绑核。在KVM等虚拟化环境中,也可以通过配置vCPU拓扑和vNUMA来实现。
2)绑核的优点
-
显著降低内存延迟:确保所有内存访问均为本地访问,避免了跨节点的高延迟。实测数据显示,本地内存访问延迟(约80ns)比跨节点(约150ns)低约30-50%。
-
提升缓存局部性:进程被固定在少数几个核心上,可以更有效地利用L1/L2/L3缓存,提高缓存命中率,减少对主内存的访问。
-
降低资源争用:将数据库实例隔离在单个节点内,可以避免与其他节点上的进程争用内存控制器和互连总线带宽,减少性能抖动。
-
性能可预测性:消除因跨节点调度和远程内存访问带来的不确定性,使得数据库性能更加稳定和可预测,基准测试结果的波动性更小。
3)绑核的风险和缺点
-
资源利用率可能下降:如果绑定的数据库实例负载不高,未能充分利用整个NUMA节点的CPU和内存资源,那么其他节点的资源将处于闲置状态,导致整体服务器资源利用率下降。
-
可能导致负载不均衡:在多实例部署场景下,如果未进行合理的手动规划和分配,所有实例可能都挤在同一个NUMA节点上,造成该节点成为性能热点,而其他节点处于空闲中。
-
配置与维护复杂:需要准确识别服务器的CPU-NUMA拓扑,并维护绑定配置。在虚拟化和容器环境中,物理和虚拟拓扑的映射关系使配置更加复杂。
4)绑核性能对比
针对主流开源数据库进行的OLTP基准测试的综合结果。测试中保持硬件、操作系统和数据库配置完全一致,仅改变NUMA绑定策略。NUMA绑核和不绑核的性能对比如下:
|
场景
|
未绑核
|
绑核后
|
性能提升
|
|---|---|---|---|
|
Unixbench跑分
|
基准值
|
提升20%+
|
20%
|
|
MySQL TPC-C测试
|
12,500 QPS
|
20,800 QPS
|
66.4%
|
|
存储虚拟化吞吐
|
基准值
|
提升10%
|
10%
|
|
平均响应时间
|
8.2ms
|
4.7ms
|
42.7%
|
实际上在高并发访问相同内存块的跨NUMA访问的特殊场景下,NUMA绑核后性能提升的比例更高。
当在数据库服务器中高并发访问相同内存块时,不受控的跨NUMA节点访问会引发硬件级别的缓存一致性协议风暴,这直接导致观察到的SYS系统CPU飙高和buf_block_mutex等互斥锁竞争加剧。
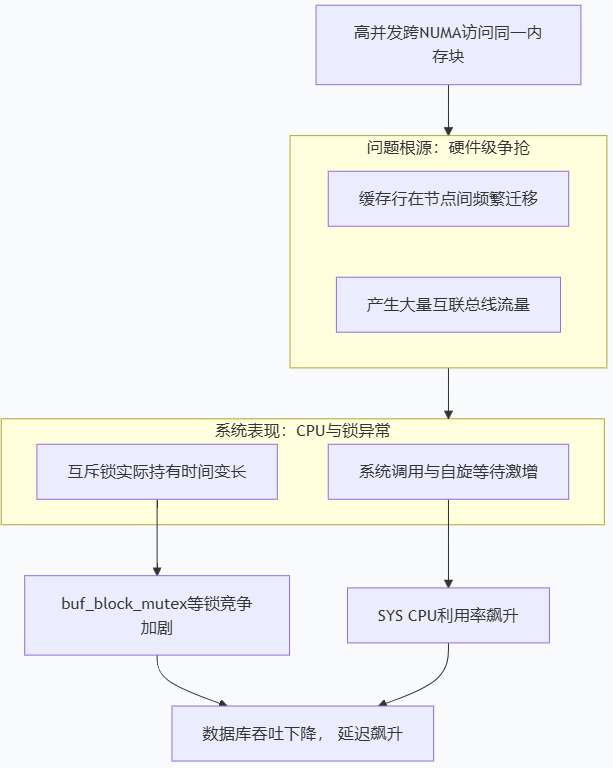
1)缓存一致性风暴
当所有并发线程都要读同一个内存块,这个内存块对应一个缓存行(通常是64字节)。当不同NUMA节点上的线程频繁读取同一内存块时,根据MESI协议,一个缓存行可以同时存在于多个核心的缓存中,并标记为“共享”。但每次有新节点核心要读取时,即使数据未变,也需要通过节点互联总线进行查询和确认,产生大量协议开销。高并发下,这个缓存行在不同节点的缓存间被迅速移动,导致极高的互联延迟和带宽消耗。
2)系统层SYS_CPU飙升
SYS CPU是操作系统内核消耗的CPU,由于节点间为维持缓存一致性而产生的通信(如QPI/UPI中断)激增,内核需要处理这些中断。当线程尝试获取一个锁(如 buf_block_mutex)但失败时,通常会在内核态执行“自旋等待”,即反复检查锁状态直到获取成功。在跨NUMA场景下,自旋等待的循环速度极快,纯消耗CPU周期。由于数据在远程,检查锁状态的延迟极高,导致自旋等待时间被大幅拉长,从而推高SYS CPU。
3)数据库层buf_block_mutex竞争加剧
buf_block_mutex 是InnoDB保护缓冲池中数据页(buf_block_t)结构体的互斥锁。任何线程在读取、修改、获取该页状态前都必须先获得这个锁。跨NUMA访问从两个维度恶化了竞争:
-
锁持有时间被“隐形”延长:线程A(在Node 0)持有锁读取页时,如果线程B(在Node 1)也要读,即使没有修改,B在成功获取锁后,其第一次内存访问也会因缓存行无效化而触发一次高延迟的远程内存读取。这个等待远程数据的过程,本质上延长了锁的“有效持有时间”。
-
锁等待的成本激增:所有在远程节点上等待这个锁的线程,其自旋等待都伴随着高延迟的远程内存访问,等待队列更容易堆积。
因此,在该高并发访问相同内存块数据的场景下,跨NUMA访问直接导致硬件资源(互联总线、CPU周期)被大量浪费在无效的数据搬运和通信上,进而表现为系统SYS CPU和数据库内锁竞争的异常升高。最有效的解决方案是进行NUMA绑核,将计算和其所需的数据锁定在同一个节点内,从根源上消除不必要的远程访问。
3、是否开启超线程
超线程技术是在单个物理CPU内复制部分体系结构状态(如寄存器),使其能够同时处理两个或多个独立的指令流(线程)。在操作系统层会看到两个或更多逻辑处理器。这些逻辑线程共享该物理核心的大部分执行资源,如执行单元、L1/L2缓存、分支预测器等。超线程的作用是当一个线程遇到内存延迟或分支预测错误等阻塞时,允许CPU的执行单元处理另一个线程的指令,从而提高物理CPU的利用率和整体吞吐量。
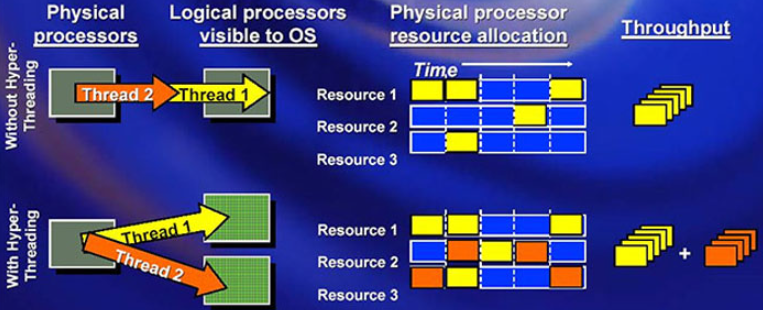
1)开启超线程方法
超线程通过在服务器BIOS进行配置,设置为 Enable (开启) 或 Disable (关闭)。大多数信创服务器BIOS中均提供此选项,通常默认关闭。开启后通过lscpu命令查看,如果"Thread(s) per core"的值为2,表示已经开启了超线程,"CPU(s)"字段会显示总逻辑CPU核数。
2)超线程开启优缺点
开启超线程后可以提升处理器的并发处理能力,尤其是在虚拟化场景下,无需额外的硬件投入就得到2倍的CPU核数。在多任务和高并发的场景下,可以充分利用CPU资源、提高吞吐量,提升并发处理的能力。但是开启超线程存在一定的资源竞争,尤其是在两个逻辑CPU共享同一物理CPU的资源情况下,资源竞争会加剧;在某些场景下可能会出现性能波动,不如物理CPU稳定;并且操作系统需要更精细地管理多个逻辑核心的调度。综合而言,还是开启超线程以提升CPU资源的利用率。
3)NUMA绑核情况下是否开启超线程
NUMA绑核和开启超线程是兼容的,但是在绑核时需要注意逻辑CPU的物理分布。以海光7470服务器测试为例,在NUMA绑核与不绑核、是否开启超线程情况下进行对比发现,在NUMA绑核与不开启超线程下性能是最优的,但是NUMA绑核对于性能提升的作用更大。平衡资源利用和性能下,实际上对于数据库服务器最终会进行NUMA绑核并开启超线程。以海光服务器7470为例,物理CPU核数为96,8个NUMA节点,开启超线程并进行绑核,服务器上部署了3个1主2备数据库实例:
node 0 cpus: 0-11 96-107
…
node 7 cpus: 84-95 180-191
,主节点分配0-3共4个NUMA节点、2个备节点共用4-7个NUMA节点
numactl --cpunodebind=0-3 master
numactl --cpunodebind=4-7 slave1
numactl --cpunodebind=4-7 slave2
# 关闭numa_balancing
echo "kernel.numa_balancing=0" >> /etc/sysctl.conf
sysctl -p
对于数据库主节点而言使用到的是0-47这48个物理CPU,两个备节点共用了48-97这些CPU资源。备节点资源使用相对较少,不用担心备节点切换为主节点后的CPU资源问题。
4、总结
数据库信创服务器的调优是一个系统工程,需要综合考虑操作系统层、数据库应用层和硬件架构特性。在NUMA架构和超线程技术的支持下,调优的核心在于充分发挥国产硬件的架构优势,通过操作系统层的参数配置和绑核策略,减少跨节点内存访问延迟,提高缓存命中率,最终实现数据库性能的显著提升。
参考资料:
-
https://blog.csdn.net/qq_41914036/article/details/155243568
-
https://blog.csdn.net/solihawk/article/details/136312861