V-Thinker让AI学会像人一样‘边画边思考’,通过视觉交互和代码生成,显著提升模型复杂视觉推理能力,并自主创建训练数据。
原文标题:V-Thinker: 让模型像人一样「边画边想」
原文作者:机器之心
冷月清谈:
V-Thinker 框架主要在三个方面进行了系统性探索和创新:
首先,在数据层面,团队引入了**数据演化飞轮**(Data Evolution Flywheel)。其核心思想是让“模型充当造题者”,通过引导大型语言模型(如GPT-5)生成包含视觉交互的推理问题和解决方案,并利用校验机制确保高质量。这一机制使得数据集能够在多样性、质量和难度上实现自动合成、演化并校验,最终构建了 V-Interaction-400K 大规模交互推理数据集。
其次,在训练层面,V-Thinker 采用了一套渐进式视觉训练范式。它首先通过构建 V-Perception-40K 数据集提升模型的细粒度视觉感知能力,随后结合冷启动监督微调(SFT)与强化学习(GRPO)的两阶段训练策略,使模型逐步掌握基于视觉交互的推理能力。强化学习阶段尤其关键,它引导模型在推理过程中自主生成并执行代码,与图像进行实时交互。
最后,在评测层面,团队构建了 **VTBench**,这是一个面向视觉交互推理场景的专家标注基准。它专注于那些必须通过图像交互才能完成的问题,从视觉元素感知、指令指导下的视觉操作,到需要视觉交互的问题解决能力等多个维度评估模型的真实能力。
实验结果表明,V-Thinker 在 VTBench 三类交互任务中表现显著优于基线模型,平均准确率提升超12%。此外,它在 MathVision 等通用视觉推理基准上也取得了约6%的性能提升,这表明视觉操作驱动的推理范式具备向通用视觉推理迁移的潜力。模型甚至在不强制要求交互的任务中也会主动标注图像,展现了视觉交互已内化为其推理策略的一部分。数据飞轮机制也成功实现知识点体系的非线性扩展,覆盖25个领域,形成24,000余个知识点,凸显了其巨大的数据生成潜力。
这些成果共同推动了“Thinking with Images”方向的发展,展现了模型不仅能“看图推理”,还能在推理过程中自主生成并执行代码,与图像进行交互,实现真正意义上的“边画边思考”能力。
怜星夜思:
2、文章提到“让模型充当造题者”这个数据飞轮机制,听起来很高效很前沿。但有没有人会担心,当模型大规模地自我生成和演化数据时,会不会出现一些意想不到的问题?比如,数据会越来越“内卷”,或者偏离真实世界的复杂性和多样性?我们应该如何平衡这种高效与潜在的风险呢?
3、强化学习(RL)在 V-Thinker 这种‘边画边思考’的框架里,肯定是扮演了很关键的角色。大家觉得RL在这里最核心的贡献是什么?同时,它在引导模型实现这种复杂视觉交互推理时,面临的最大挑战会是什么?(比如奖励设计、探索效率、环境模拟等)
原文内容

本文共同第一作者为北京邮电大学博士生乔润祺与硕士生谭秋纳,主要研究方向为多模态推理,其共同完成的工作主要有 、,并曾在 CVPR、ACL、ICLR、AAAI、ACM MM 等多个顶会中有论文发表。本文的通讯作者为博士生导师张洪刚与微信视觉技术中心李琛。
在人类解决复杂视觉问题的过程中,视觉交互往往是重要的认知工具。例如在几何解题中,通过添加辅助线来显式建模空间关系;在常识推理中,也可以通过添加标注来进一步梳理和验证推理过程。
围绕这一问题,早期研究(如 LLaVA-Plus、Visual Sketchpad)开始探索在推理过程中引入视觉操作,以增强模型与图像之间的交互。随着强化学习方法被引入视觉推理训练,模型在复杂视觉场景中的表现得到显著提升。
进一步,o3、DeepEyes、Thyme 等工作表明,模型可以在强化学习的引导下自主生成代码,通过放大、裁剪、旋转等操作与图像进行交互,以此实现基于图像思考的推理范式。
在上述进展的基础上,我们进一步思考:模型是否能够像人一样,在推理过程中实现「边画边思考」的视觉推理范式?为此,我们从数据、训练范式与评测体系等多个方面,对视觉交互推理进行了系统性探索:
-
我们提出 V-Thinker,一个面向视觉交互推理的多模态推理框架。通过冷启动监督微调与强化学习相结合的训练,使模型能够在推理过程中自主生成代码并与图像交互,从而实现「边画边思考」的视觉推理方式。
-
在数据层面,我们提出 Data Evolution Flywheel(数据演化飞轮),能够在多样性、质量与难度三个维度上自动合成、演化并校验视觉交互推理数据,并进一步构建开源了数据集 V-Interaction-400K,为视觉交互推理和图像到代码转换等任务提供了基础支撑。
-
在训练层面,我们设计了一套渐进式视觉训练范式,通过构建 V-Perception-40K 首先提升模型的视觉感知能力,再通过结合监督微调与强化学习的两阶段训练,使模型掌握基于视觉交互的推理能力。
-
在评测方面,我们构建了 VTBench,一个面向视觉交互推理场景的专家标注基准。实验结果表明,V-Thinker 在交互式推理与通用推理任务上均有提升。

-
论文标题: V-Thinker: Interactive Thinking with Images
-
论文链接: https://arxiv.org/abs/2511.04460
-
代码仓库: https://github.com/We-Math/V-Thinker
-
数据集: https://huggingface.co/datasets/We-Math/V-Interaction-400K
目前不仅在 X 上收获了一定的关注度,并在首月数据下载次数突破 10K+。
数据飞轮:
数据合成范式的新思考
为了实现「边画边思考」的视觉推理范式,一个关键挑战在于如何构建支持模型通过代码读取并编辑图像的高质量数据。
我们解决这一挑战的核心思想在于:「让模型充当造题者,而非解题者」。而这源自于一次偶然间的尝试:
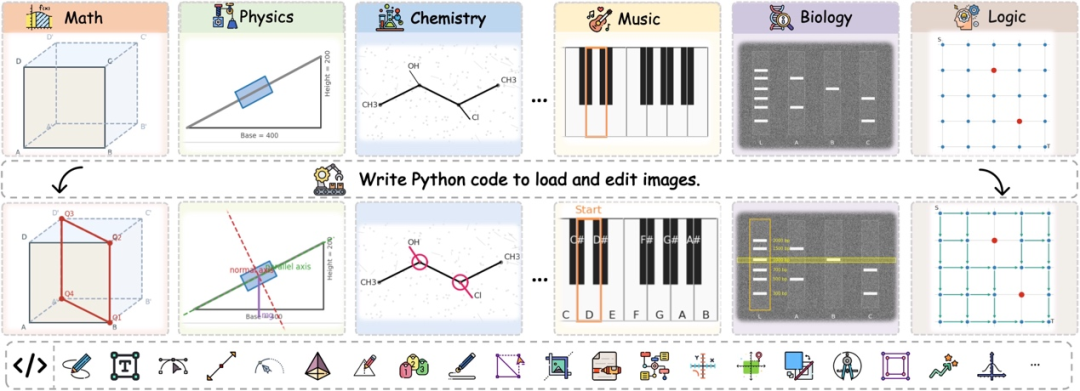
如上图所示,我们尝试将 We-Math 2.0(先前工作)的知识点输入至 GPT-5,引导 GPT-5 生成依赖视觉交互的推理问题(包含原图代码、问题、解题过程、视觉交互代码等),惊喜地发现其所生成的代码通过编译能够渲染出结构、语义一致的高质量图像,并与推理过程保持良好一致性。
基于这一发现,我们有了一个大胆的想法:只要能让知识点体系足够泛化,那就可以自动地构造大规模训练数据。正如本文提出的数据飞轮机制所示,只要能找到对知识点产生增量的有效信号,数据的多样性便可以在迭代过程中不断扩展。
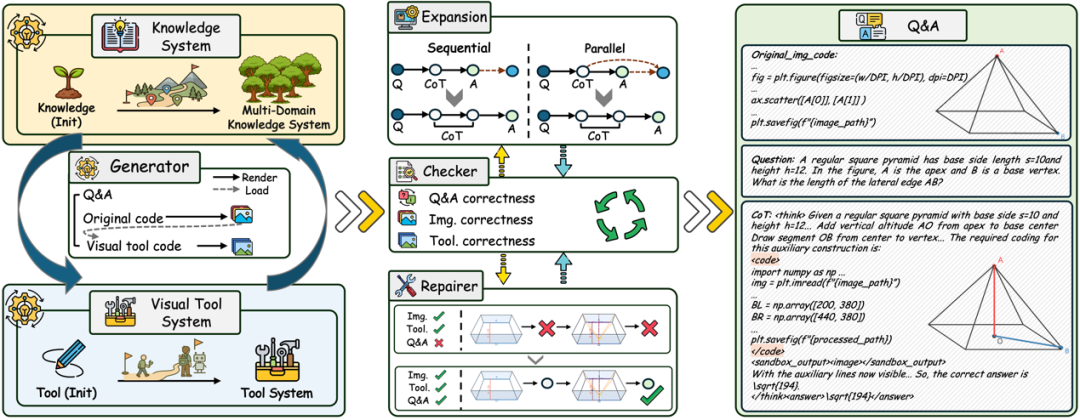
因此,如上图(左)所示,我们首先构造了一个知识点集和工具集合,让模型根据指定知识点生成题目,并要求模型给出这个题目所需的工具。再根据这些工具,生成新的题目召回新的知识点,以此循环迭代。我们发现通过 We-Math 2.0 的知识点和手动构造的工具库做初始,最终通过层次聚类,可以召回出 2W+ 的新知识点,覆盖 25 个领域(数学、物理、音乐等)。
进一步,我们构建了 Checker,分别对问题与答案、原始图像、视觉操作后的图像进行一致性校验。对于在各个维度上均通过校验的样本,为了进一步提升问题难度并增加视觉交互的轮次,我们引入一个拓展器。其基于「推理过程本质上由问题所引导」的思想,通过重构问题,使原始问题的答案作为新的条件,引入额外的视觉交互步骤,从而生成新的问题与对应答案。
此外,对于原始图像与视觉操作后图像均保持正确,但问题与答案一致性存在偏差的样本,我们对其进行筛选,并同样通过问题重构的方式,引导视觉操作后的图像在推理过程中以正确的形式出现在 CoT 中。
通过上述过程的持续迭代,我们最终构建了大规模交互推理数据集 V-Interaction-400K。

渐进式训练:
从感知对齐到交互推理
为解决现有多模态模型在细粒度感知定位能力上的不足,并逐步实现「边画边思考」的视觉推理能力,我们设计了一套渐进式训练体系。
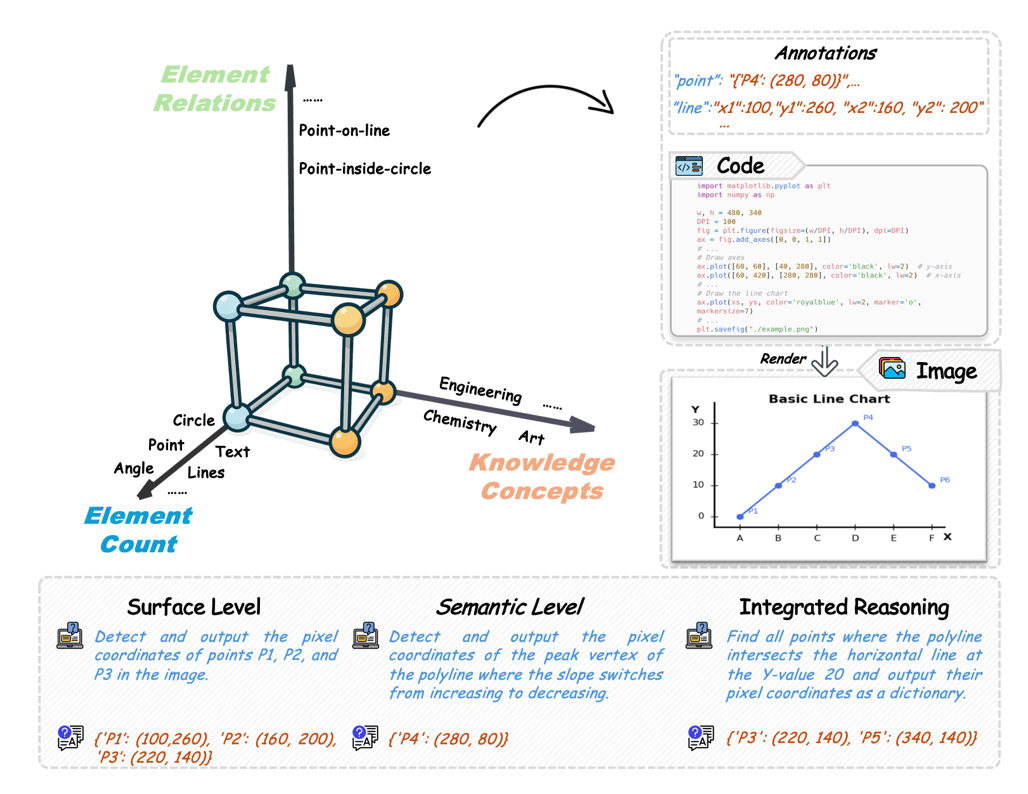
第一阶段(感知能力):我们先对模型的视觉感知能力进行提升。如下图所示,我们依托数据飞轮中让模型充当造题者的核心思想,在感知空间中通过视觉元素关系、元素数量及知识点进行建模,并设计不同层级的问题进行自动合成感知数据,构建感知数据集 V-Perception-40K,以此训练模型的细粒度定位能力。
第二阶段(交互推理能力):我们采用「SFT + GRPO」的训练策略,使模型逐步具备稳定的视觉交互推理能力。
-
冷启动: 通过 V-Interaction-400K 实现初步对齐。
-
强化学习(RL): 我们首先从 V-Interaction-400K 中采样了 3k 条数据(模型在输入原图的情况下作答错误,但在输入视觉编辑后的图片作答正确),并从 We-Math 2.0、MMK12、ThinkLite 等开源工作中进行采样,构成了该阶段的训练数据。
-
训练设定: 训练框架与奖励函数均遵循了 Thyme 的架构与设定,引导模型在推理过程中生成并执行视觉操作代码,在 Sandbox 中执行代码并返回操作后的图片再次输入至模型进行后续推理,使模型能够在推理过程中自主生成代码并与图像交互,实现「边画边思考」的视觉推理范式。
VTBench:
面向视觉交互的评测基准
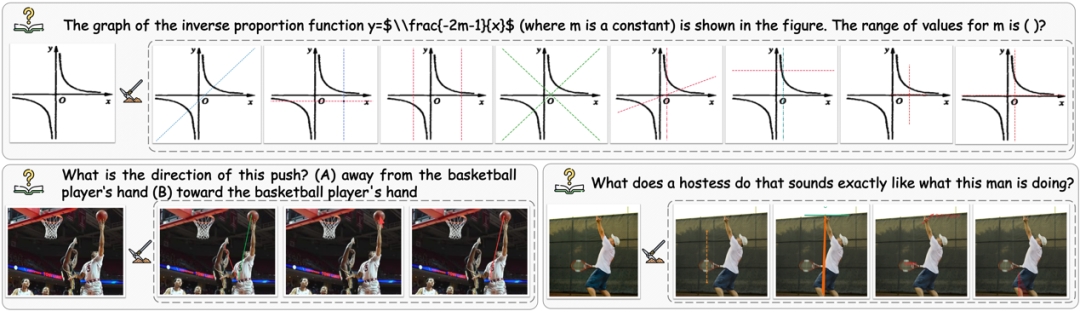
为了进一步评估模型在视觉交互推理场景中的真实能力,我们构建了 VTBench,一个面向依赖视觉交互的评测基准。与现有的 Benchmark 不同,VTBench 聚焦于通过与图像交互才能完成的问题,例如添加辅助线、标注关键区域或修改图像结构。
在构建过程中,所有样本来自多个公开数据集及公共平台,并由人工进行标注。特别地,我们在标注前进行了人工投票筛选:只有当多数认为视觉交互是解题所必需时,样本才会被纳入基准,以此增强所选题目的视觉交互必要性。
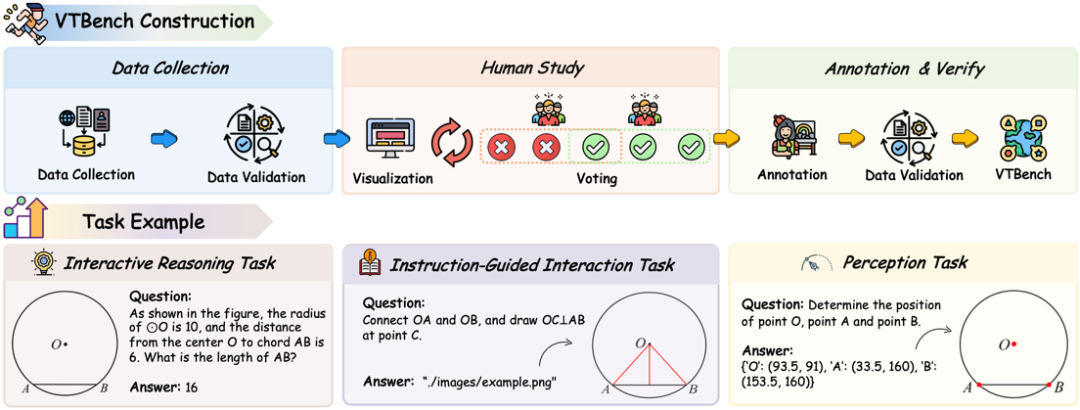
在评测设计上,VTBench 从推理过程的不同阶段出发,构建了三种不同的任务,覆盖从基础感知到交互推理的完整流程。具体而言,如上图所示,包括对视觉元素的感知能力、在明确指令下执行视觉操作的能力,以及在推理过程中面向需要视觉交互任务的解题能力。针对不同类型的任务,模型需要生成可执行代码与图像进行交互,其结果再与人工标注进行对齐评估,以确保评测真正反映模型的视觉交互推理水平。
实验结果
定量分析
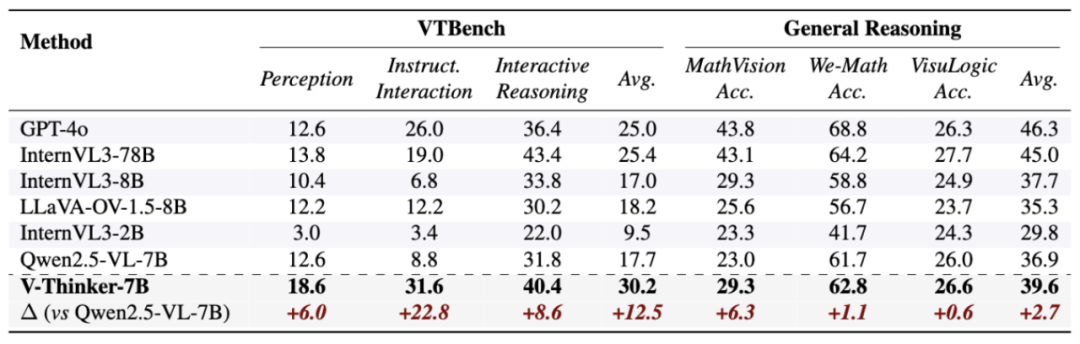
交互式视觉推理能力显著提升: V-Thinker 在 VTBench 的三类交互任务中均显著优于基线模型,平均准确率提升超 12%,其中在 Instruction-Guided Interaction 场景中性能提升超过 22%。
模型在感知、视觉交互能力上仍存在提升空间: 尽管 GPT-4o、Qwen2.5-VL 等模型在通用视觉推理任务中表现出较强能力,但在涉及空间关系建模与点级定位的交互任务中,性能有所下降。这一现象反映出视觉交互能力与推理能力之间仍存在差距。
交互式推理在通用推理场景具备一定泛化性: 在多个通用视觉推理基准中,V-Thinker 在 MathVision 等复杂多步推理任务上取得 6% 的性能提升,表明视觉操作驱动的推理范式不仅适用于交互任务,也具备向通用视觉推理迁移的潜力。
定性分析
视觉交互能力显著提升,并在通用场景有所泛化: V-Thinker 能够稳定生成符合问题需求的图像编辑操作,例如绘制辅助线、标注关键区域或完成结构化重绘。值得注意的是,在部分不强制要求视觉交互的任务中,模型亦会主动对图像进行标注,以辅助中间推理过程,表明视觉交互已逐渐内化为其推理策略的一部分。
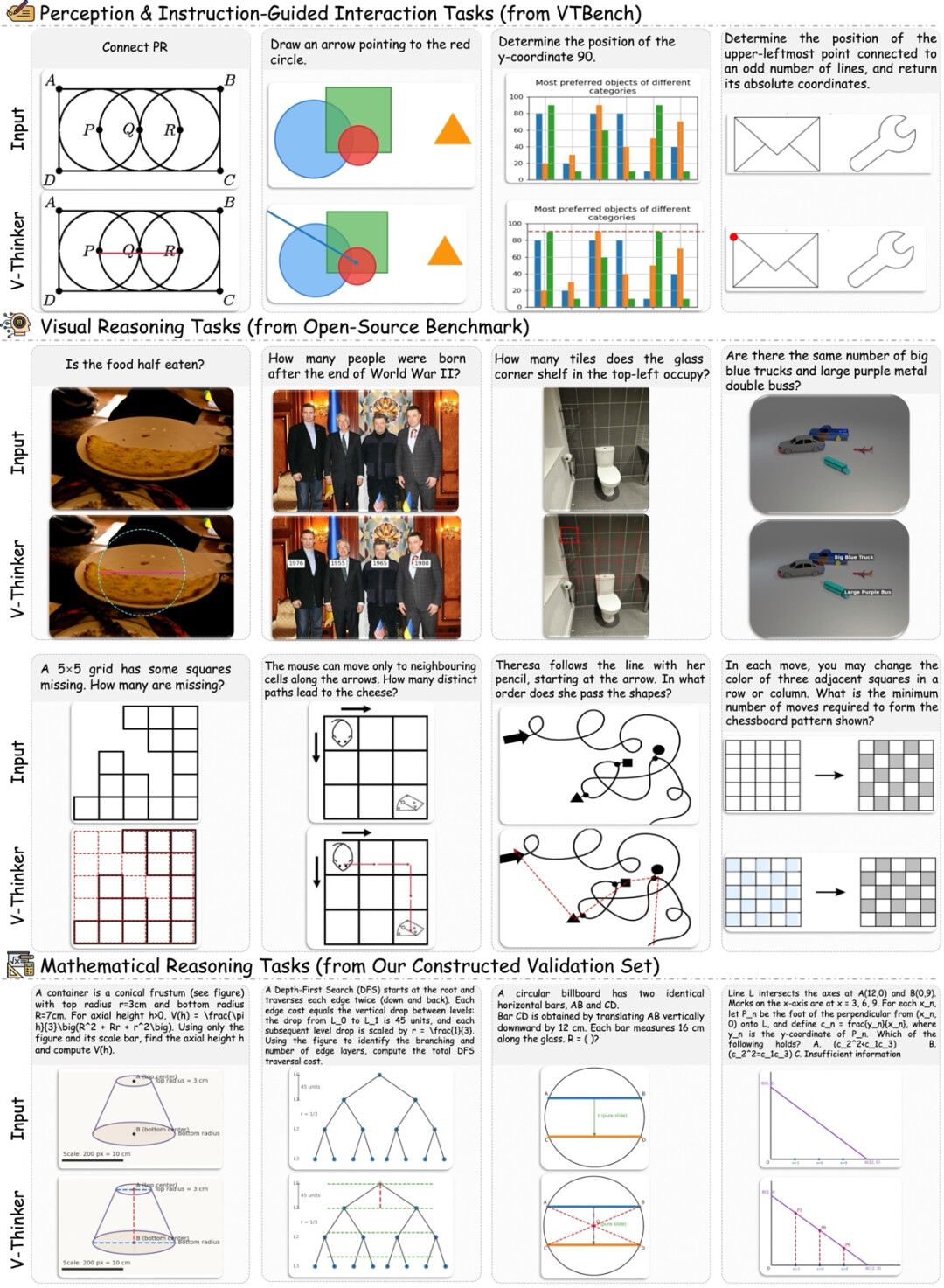
强化学习多路径交互探索能力显著增强: 如下图所示,我们对强化学习阶段的 Rollout 样本进行了可视化,V-Thinker 在同一图像条件下能够生成多样化的交互路径,覆盖更广泛的解空间。这些路径在中间步骤和操作选择上存在明显差异,表明模型在交互推理阶段具备更强的策略多样性,并进一步提升模型的可解释性。
推理过程可视化与可解释性提升: 如下图所示,在完整示例中,V-Thinker 能够在推理过程中自主生成并执行图像编辑代码,并即时渲染中间结果,从而将原本的文本推理过程外化为可观察的视觉中间过程。通过这种「生成—执行—反馈」的交互循环,模型能够在保持推理一致性的同时,使复杂视觉推理过程更加直观且具备更好的可解释性。
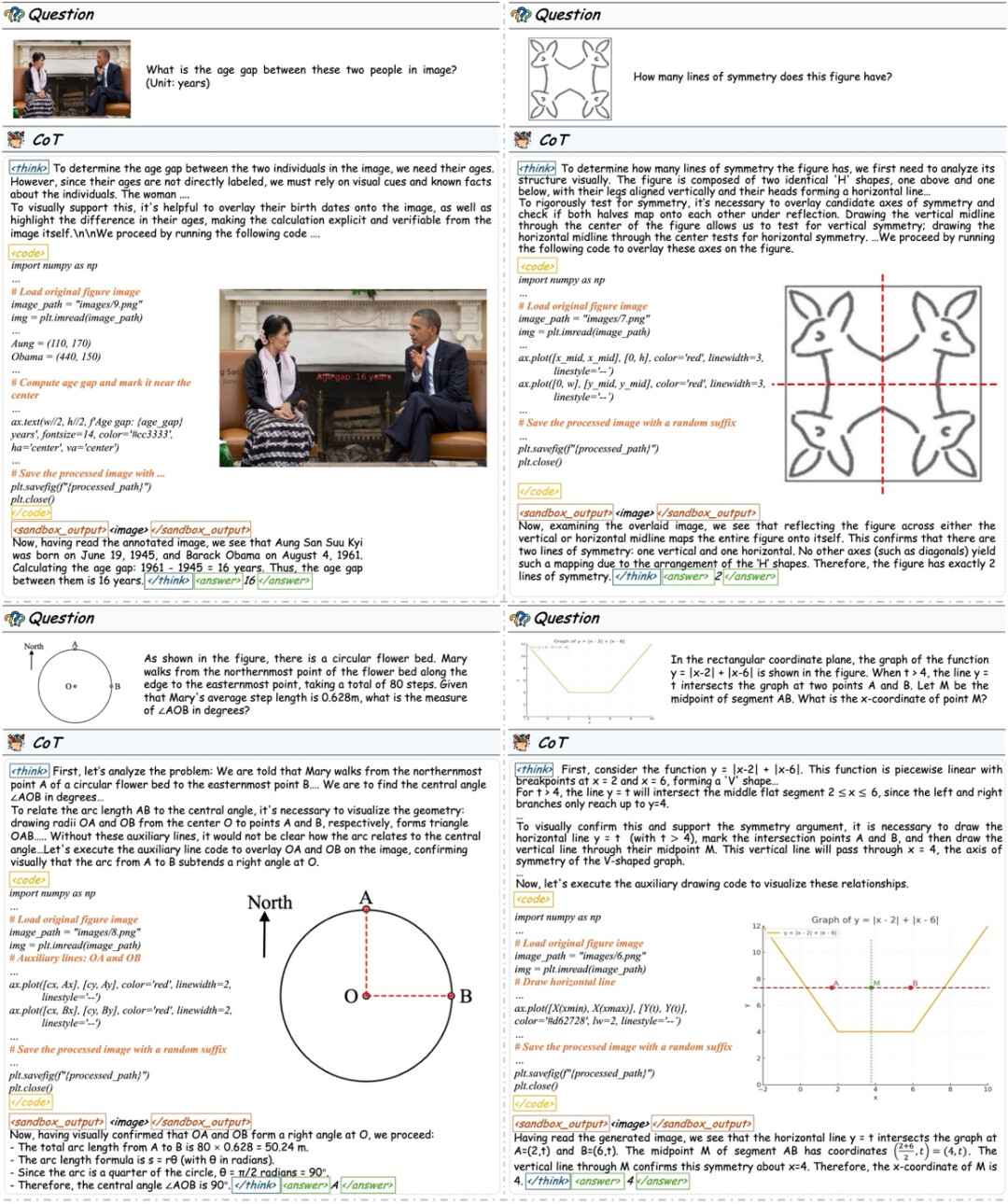
数据飞轮分析:知识系统与数据规模的演化
数据飞轮驱动的知识体系持续扩展: 我们进一步分析了数据飞轮在数据构建过程中的作用。如下图所示,从初始知识点出发,数据飞轮能够持续扩展知识概念与视觉工具,最终形成覆盖 25 个领域、24,000 余个知识点的层次化知识体系。
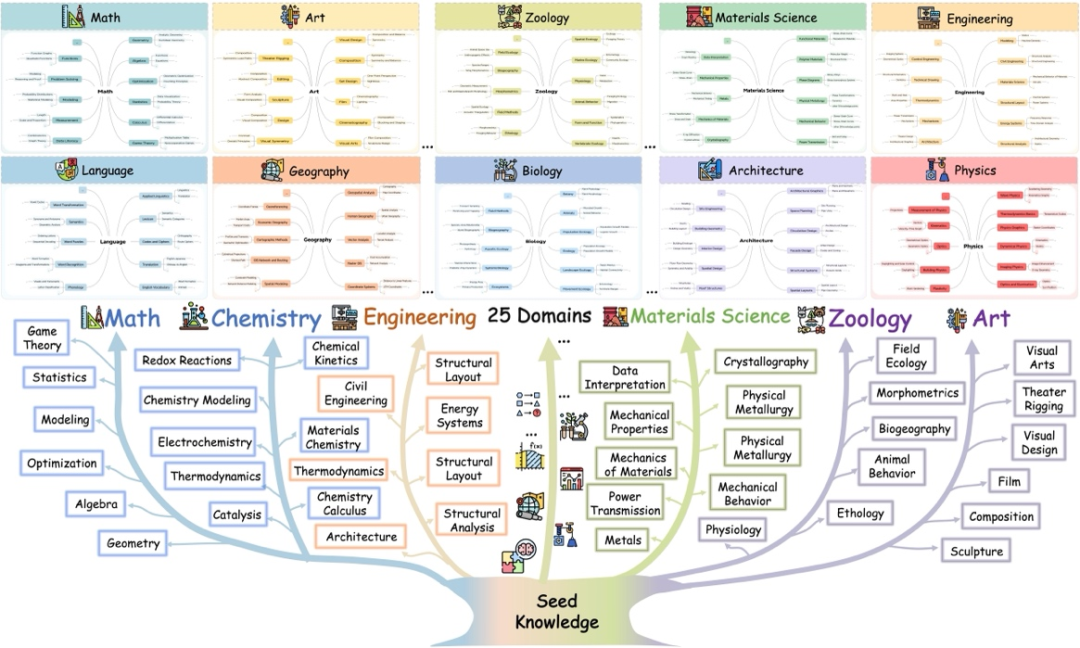
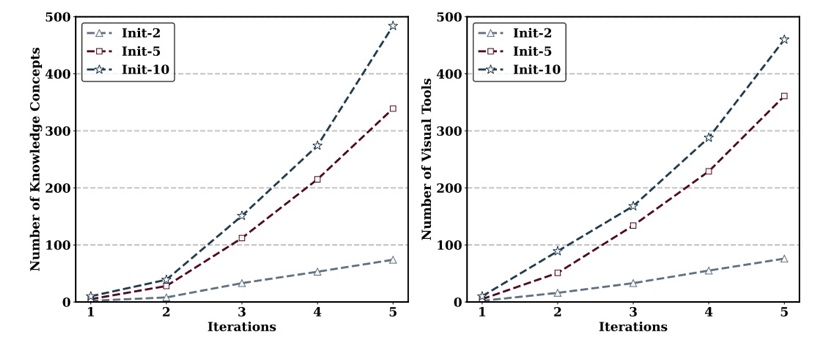
演化轮次与知识规模的非线性增长规律: 此外,我们进一步分析了演化轮次与知识体系及视觉工具规模之间的关系。如下图所示,随着轮次增加,知识点与视觉工具数量呈现明显的非线性增长趋势,在五轮演化后整体规模扩展至初始种子的约 50 倍,且未出现明显饱和。同时,在不同的初始设定下可以看到,更丰富的初始知识点或工具集合能够带来更优的演化轨迹,凸显了初始种子多样性在数据飞轮持续演化过程中的重要作用。
总结与展望
我们希望通过 V-Thinker 可以推动「Thinking with Images」这一方向的进一步发展。在这项工作中,我们渴望展现,模型不仅可以「看图推理」,还可以在推理过程中自主生成并执行代码,与图像进行交互,从而实现真正意义上的「边画边思考」。
围绕这一目标,我们从方法、数据、训练与评测等多个层面进行了系统探索。通过引入代码驱动的视觉交互机制、数据演化飞轮以及渐进式训练范式,V-Thinker 不仅在数学任务中展现出了交互能力,更在通用场景展现出了泛化能力。
此外,在这项工作的实现过程中,我们认为随着模型规模和能力的持续提升,推理范式及应用场景将会有全新的发展可能性。一方面,数据构建范式有望进一步演化,模型充当造题者的下一步或许真的具备创造知识的可能性,毕竟现有知识的源头也是通过人类经验所获得的;另一方面,模型推理能力的上限会带来全新的应用场景。
当然,V-Thinker 这篇工作是我们在这一领域的首次尝试,对于感知能力和交互能力由于算力有限,还有一定的提升空间,例如可以加入不同分辨率的扰动。我们期待未来的多模态大模型能够发展出更加出色、更加接近人类认知方式的视觉交互与推理能力。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com