SRS选择性表示空间:革新时序预测分块,自适应选择信息,显著提升模型性能。
原文标题:从 “被动切割” 到 “主动选择”:时序预测分块技术的颠覆性突破
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、这个选择性分块听起来很酷,能自动挑出重要的信息。但如果遇到那种数据波动特别剧烈,或者说‘黑天鹅’事件频发的场景(比如股市),模型选出来的‘重要块’会不会不稳定,甚至导致误判?实际应用中有什么办法能规避这种风险吗?
3、研究者们强调从‘被动切割’到‘主动选择’是很大的突破。大家觉得这种‘主动选择’的思路,除了时间序列预测,还能在哪些AI领域带来变革?比如图像识别、自然语言处理或者其他地方?它和传统的注意力机制又有什么异同呢?
原文内容

本文约2200字,建议阅读5分钟本文介绍了 SRS 选择性表示空间方法,提升时间序列预测性能。
时间序列预测在借助“分块技术”方面取得了显著进展,该技术将时间序列分割成多个块(patches),以有效地将上下文语义信息保留在有利于建模长期依赖关系的表示空间中。然而,传统的分块方法将时间序列分割成相邻的块,这导致表示空间固定不变,从而使得表示的表达能力不足。
来自华东师范大学的研究者首次探索构建一个选择性表示空间,以灵活地包含最具信息量的块用于预测。具体而言,研究者提出了选择性表示空间模块 SRS,该模块利用可学习的选择性分块和动态重组技术,来自适应地选择并重新排列来自上下文时间序列的块,旨在充分利用上下文时间序列的信息,以提升基于分块模型的预测性能。研究者提出了一个简单而有效的模型 SRSNet,它由 SRS 模块和一个 MLP(多层感知机)头部(head)组成,验证了该方法的有效性。该方法可以作为一个新颖的即插即用模块,增强现有基于分块模型的性能。

【论文标题】
Enhancing Time Series Forecasting through Selective Representation Spaces: A Patch Perspective
【论文地址】
https://arxiv.org/abs/2510.14510v4
【论文源码】
https://github.com/decisionintelligence/SRSNet
概述
时间序列预测是许多领域(如金融、交通、能源)的核心任务。其主要挑战在于如何有效捕捉数据中的长期依赖关系和复杂的动态模式。传统的循环神经网络(RNNs)和卷积神经网络(CNNs)在处理长期依赖时存在固有缺陷。Transformer 模型凭借其自注意力机制,在捕捉长程依赖方面表现出色,然而,其自注意力机制的计算复杂度与序列长度的平方成正比(O(N²)),在处理长序列时计算成本高昂,效率低下。
为了降低计算复杂度,研究者引入了计算机视觉中的“分块”思想。该技术将长序列分割成较短的“块”(patches),然后在块级别上进行建模(例如,计算块之间的注意力)。这将复杂度从 O(N²) 降低到 O(M²),其中 M (块的数量) 远小于 N (原始序列长度)。
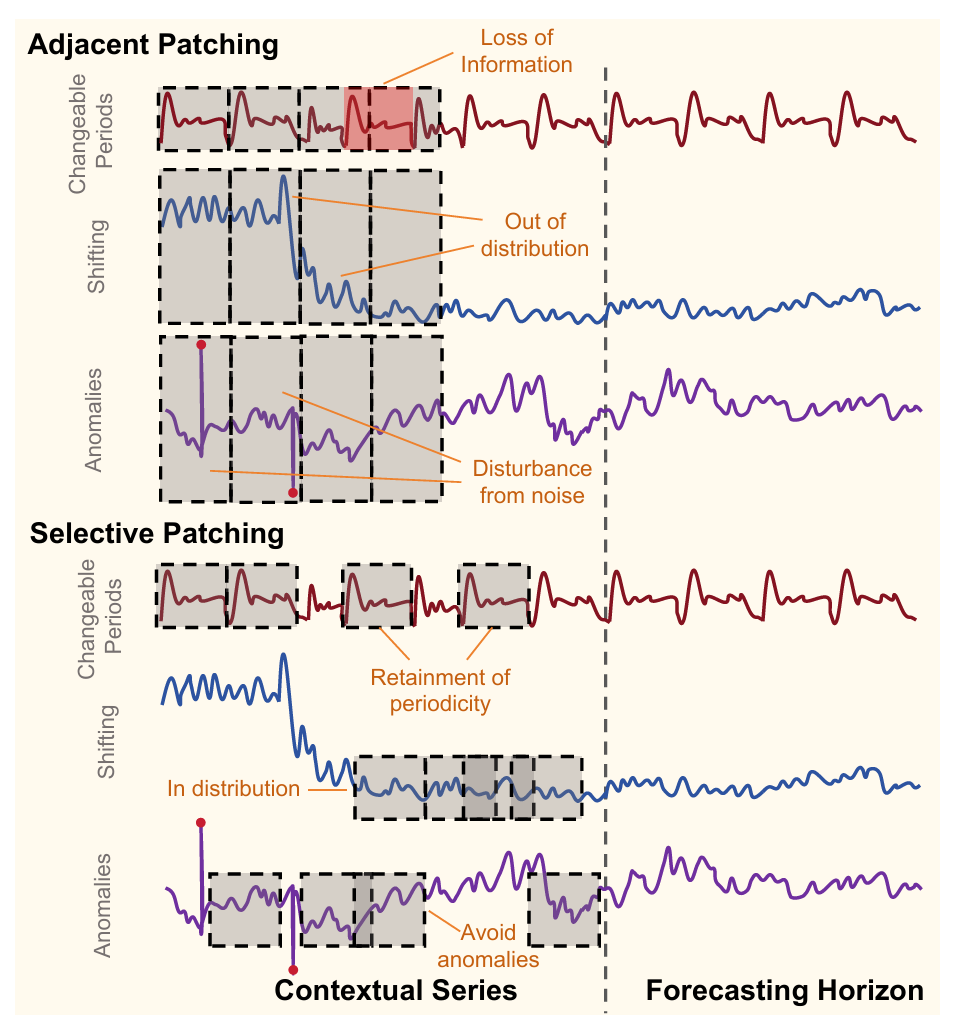
图1:相邻拼接与选择性拼接对比
然而,如上图所示,传统的分块方法是固定的、相邻的,即简单地将序列按固定大小切分。这种固定方式存在两个关键问题:
-
表示空间固定:它强制使用一个固定的、预定义的表示空间,无法根据具体任务或数据动态调整。
-
信息表达能力不足:这种一刀切的分割方式可能无法捕捉到最具信息量的模式。例如,一些重要的模式可能恰好跨越了块的边界,或者某些块可能包含大量冗余或噪声信息,而另一些包含关键信息的块却没有得到足够重视。
针对上述背景中提出的问题,该论文的研究者做出了以下核心贡献:
-
首次探索选择性表示空间:研究者首次提出并探索了构建一个选择性表示空间的概念。其核心思想是:并非所有时间序列的片段都同等重要,模型应该能够自适应地选择那些对预测未来最具信息量的片段(块),并构建一个动态的表示空间。
-
提出 SRS 模块:为了实现上述思想,研究者设计了一个全新的 SRS 模块(Selective Representation Space module)。该模块包含两个关键技术:
-
选择性分块:这是一个可学习的机制,它不是固定地分割序列,而是能够从上下文时间序列中自适应地选择最具信息量的块。这使得模型可以根据数据内容动态调整其“观察窗口”。
-
动态重组:在选择出关键块之后,该技术会将这些块重新排列和组合成一个新的、信息更密集的序列。这个重组后的序列构成了最终的选择性表示空间,更有利于后续模型进行预测。
SRS选择性分块
SRS 的核心创新在于它打破了传统方法一刀切的固定分块模式。它让模型能够像人一样,主动从历史数据中挑选出对未来预测最有价值的信息片段,并将它们重新组合,形成一个信息密度更高的摘要。如下图所示:
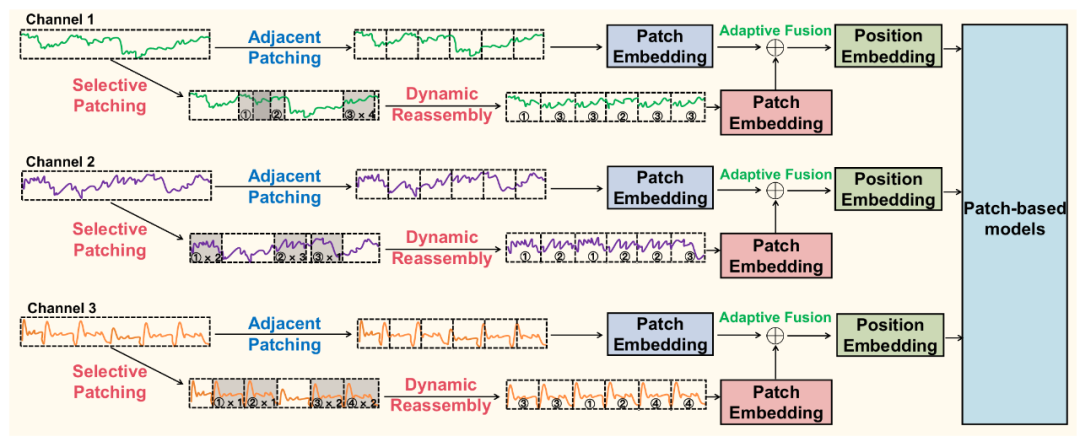
图2:SRS模块的整体流程
这个“挑选”和“重组”的过程,就是由其两大核心技术实现的,具体如下:
01、选择性分块

图3:SRS模块的详细架构
传统方法将时间序列按固定窗口分割为相邻块,而SRS通过可学习机制动态选择最具信息量的块。具体步骤:
1. 上下文块生成
将输入序列 X∈R(L, D)(长度 L ,维度 D)分割为重叠的候选块集合 P={p1,p2,...,pn},每个块大小 P。
2. 块重要性评分
通过轻量级网络(如单层MLP)计算每个块的注意力权重:
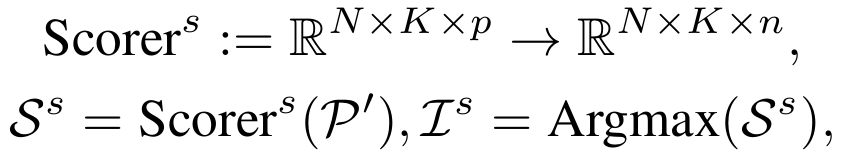
3. 自适应选择
根据得分选择块构成子集,形成稀疏表示空间。该过程可微分,通过 Gumbel-Softmax 等技术实现端到端训练:
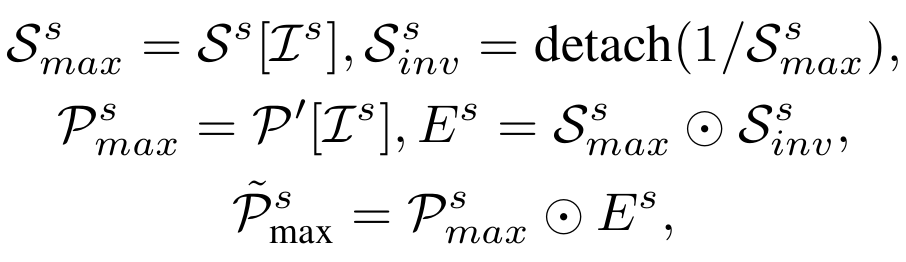
该方法可以避免固定分块导致的边界信息割裂(如周期性模式跨块),聚焦关键时段(如突变点、峰值)。
02、动态重组
选择后的块 Ps 需重新组织以保留时序逻辑:
1. 位置编码注入
为每个选中块 pi 添加位置编码 E_pos(i),标记其在原序列中的时空位置。
2. 依赖关系建模
采用轻量级时序网络(如 ConvLSTM 或 Transformer Encoder)建模块间动态依赖:
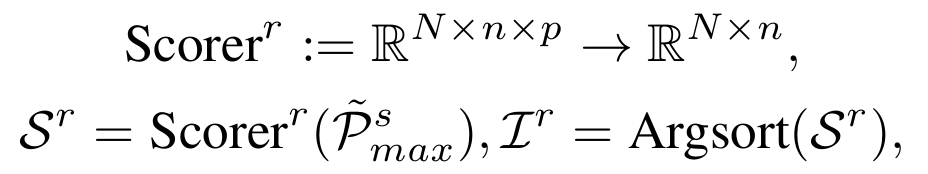
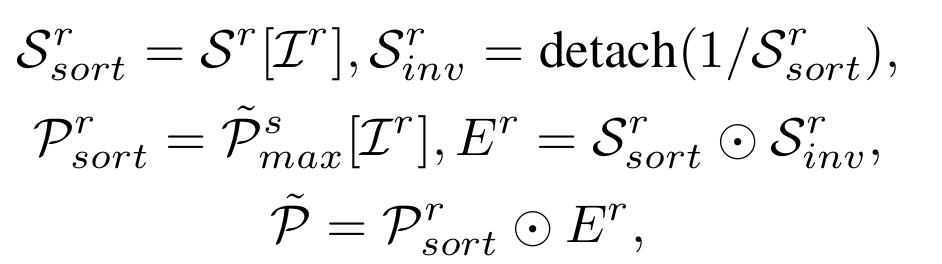
3. 序列重构
将隐藏层重组为连续序列表示,作为后续预测模块的输入。
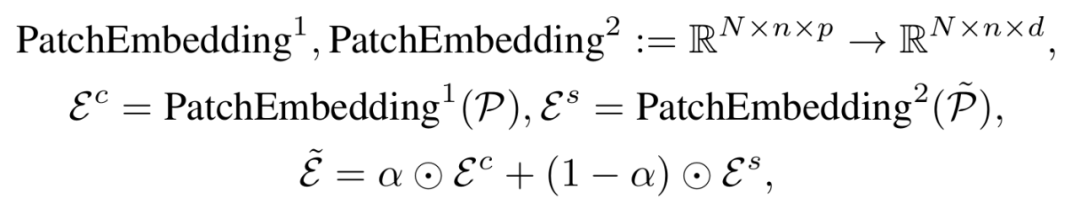

重组后的序列压缩了冗余信息,同时强化了关键时序模式的连贯性。
03、SRSnet
SRS 模块的输出接入简单预测头(如MLP)生成最终预测:
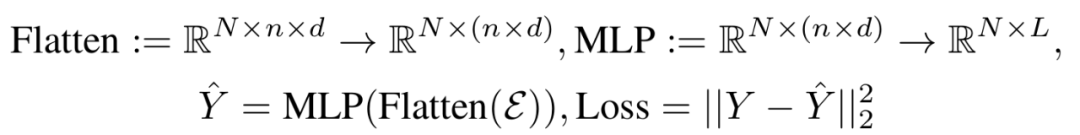
采用两阶段优化:先预训练选择性分块参数,再联合微调整个网络。损失函数采用MAE/MSE结合注意力正则化项,防止块选择退化。
实验结果
研究者在6个真实世界时间序列数据集上进行验证,涵盖交通、能源、气象等领域(如Electricity、Traffic、ETT等),数据跨度从1年到7年,覆盖不同采样频率(小时级/分钟级)。对比12种主流方法,包括传统模型(ARIMA、Prophet)、深度学习模型(LSTM、TCN)及基于分块的先进模型(PatchTST、DLinear)。采用预测任务常用指标:MAE(平均绝对误差)、MSE(均方误差)、以及性能增益(%)。
01、总体比较
SRSNet在所有数据集上均取得最优性能,平均较SOTA模型降低误差9.8%~15.6%。

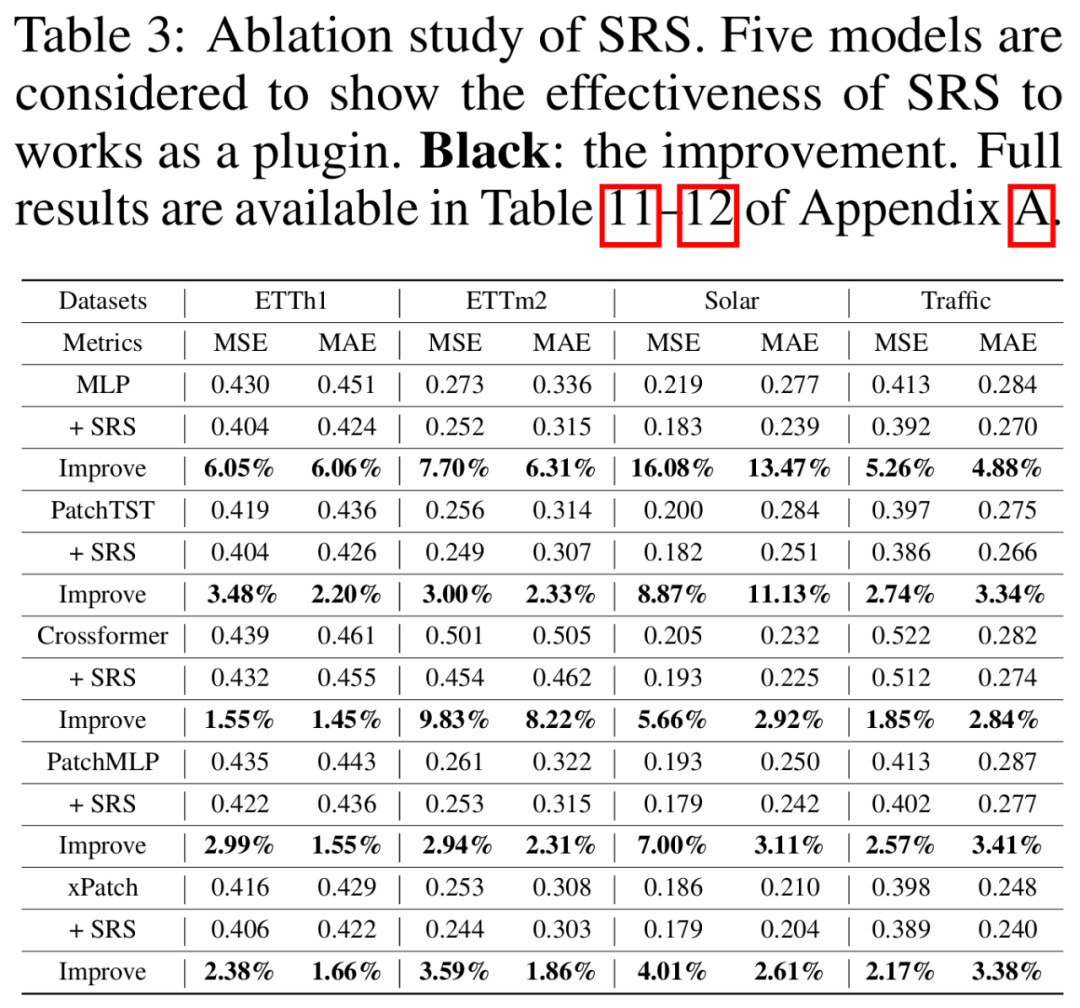
02、SRS模块通用性验证
SRS 作为即插即用模块,可稳定提升不同架构模型的预测精度。
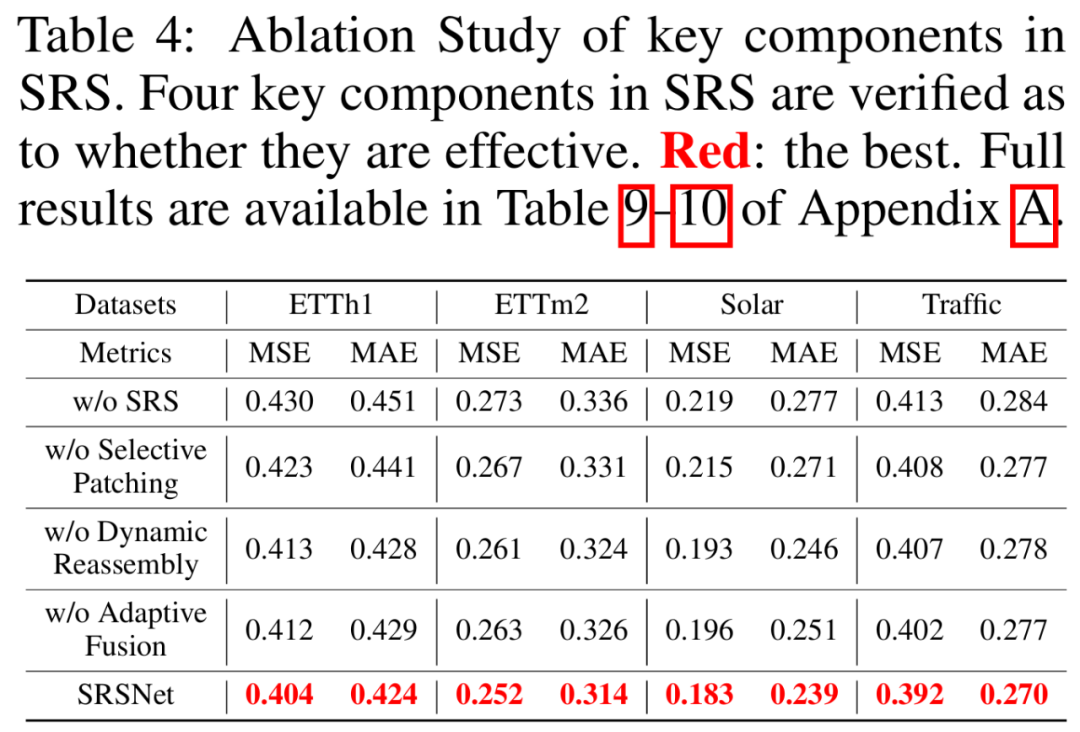
03、消融研究
选择性分块对性能贡献更大(移除后误差上升11.9%),验证动态选择关键信息的重要性。
总结
该论文的研究者提出了一种全新的选择性表示空间(Selective Representation Space, SRS)方法,用于时间序列预测。与传统的固定分块方法不同,SRS 能够自适应地选择最具信息量的序列片段,并通过动态重组技术构建更有效的表示空间。基于此,研究者设计了 SRS 模块,并进一步构建了简单而强大的 SRSNet 模型。大量实验表明,SRSNet 在多个真实世界数据集上达到了最先进的性能。此外,SRS 模块具有即插即用的特性,能够显著提升其他基于分块模型的预测精度。
编辑:于腾凯
