北航VBF++创新性地将不确定性建模引入多模态视频推荐,刷新SOTA,提供可解释融合。
原文标题:打破确定性魔咒!北航团队提出VBF++:用“不确定性建模”刷新多模态视频推荐 SOTA
原文作者:AI前线
冷月清谈:
VBF++的核心思想是将多模态融合过程从传统的“点估计”范式,革新为更具鲁棒性的“分布建模”范式。它为每个视频关联一个潜在的随机融合策略变量,以此量化融合权重的可信度,并保留多种可能的融合解释。
该框架由三大核心组件构成:
1. **上下文感知的结构化先验**:模型不再简单假设所有视频服从相同分布,而是根据视频的语义类别(如动作片、音乐片等)动态调整融合策略的先验分布,使得模态权重分布具有语义适应性。
2. **推荐引导的对抗性优化(RAR)**:为解决重构质量不等于推荐准确性的问题,VBF++引入对抗训练,强制生成的融合策略分布逼近高质量策略集合,从而使变分学习显式地导向推荐排序目标。
3. **基于元学习的域适应**:通过集成元学习器,模型能快速调整参数,有效应对新内容冷启动及跨域推荐的挑战。
实验结果表明,VBF++在MovieLens-10M、TikTok和Kuaishou等真实数据集上全面超越现有SOTA方法,特别是在稀疏数据和跨域推荐方面表现出色。同时,它不仅提升了推荐准确性,更能生成具有可解释性和语义意义的融合策略,为处理多模态数据中的不确定性提供了有效解决方案。
怜星夜思:
2、VBF++用了“上下文感知的结构化先验”,比如根据视频语义学得不同先验分布。听起来很有用,但实际操作中,怎么才能准确、高效地给海量短视频内容划分语义类别?特别是那些内容模糊、混合风格的视频,会不会很难搞?
3、“推荐引导的对抗性优化(RAR)”听着很酷,强制模型生成的融合策略要“好用”。但对抗训练是不是总有那么点“黑盒”的感觉?它会不会带来一些意想不到的负面效果,比如推荐结果的偏差或者对某些长尾内容的关注度下降?
原文内容

论文题目: VBF++: Variational Bayesian Fusion with Context-Aware Priors and Recommendation-Guided Adversarial Refinement for Multimodal Video Recommendation
作者单位: 北京航空航天大学 & 北京邮电大学
参考代码: https://github.com/muhhpu/VBF
痛点:确定性融合的
“不确定性”危机
多模态视频推荐系统在捕捉用户兴趣时,需要高效整合视频的视觉、听觉和文本特征。然而,现有的主流方法(如基于注意力机制或图神经网络的确定性融合方法 [2-3])面临着一个根本性的挑战:它们倾向于为给定的输入计算一个单一的、最优的权重向量,将多模态融合视为寻找“全局唯一最优解”的优化问题 。
这种“点估计”的策略,在面对真实世界短视频生态中的三大“不确定性”时 [5-6],显得尤为脆弱 :
-
认知不确定性 (Epistemic Uncertainty): 面对噪声干扰、模态缺失或语义模糊的短视频内容时,单一的融合方案往往不够鲁棒,忽略了可能存在的多个合理的融合策略空间 。
-
上下文无关的简单先验: 现有的变分方法虽然引入了概率建模,但通常假设视频内容服从相同的简单分布(如标准高斯分布 )[4],忽略了不同语义类别(如动作片对视觉的依赖 vs. 音乐片对听觉的依赖)对模态依赖的结构化差异 。
-
目标错位 (Objective Misalignment): 传统变分自编码器(VAE)优化的证据下界(ELBO)目标主要关注特征重构质量,而推荐系统追求的是排序准确性(Ranking)。重构得好不等于推荐得准 。
范式革新:VBF++ 将融合从
“点估计”升级为“分布建模”
近日,北京航空航天大学和北京邮电大学联合提出了一种全新的概率化框架—VBF++(Variational Bayesian Fusion with Context-Aware Priors and Recommendation-Guided Adversarial Refinement)[1]。
VBF++ 的核心思想是将多模态融合过程重新表述为一个变分推理问题,成功将融合范式从传统的“点估计”转变为更具鲁棒性的“分布建模”范式。
该框架认为:每个视频 Vi 关联一个潜在的随机融合策略变量 Zi,通过捕捉 Zi 的随机性,模型能够量化融合权重的可信度,保留多种可能的融合解释。
VBF++ 的整体框架(图 1)由三大关键组件构成,完美解决了上述挑战:
-
上下文感知的结构化先验 (Context-Aware Prior);
-
推荐引导的对抗性优化 (Recommendation-Guided Adversarial Refinement, RAR);
-
基于元学习的域适应 (Meta-Learner)。
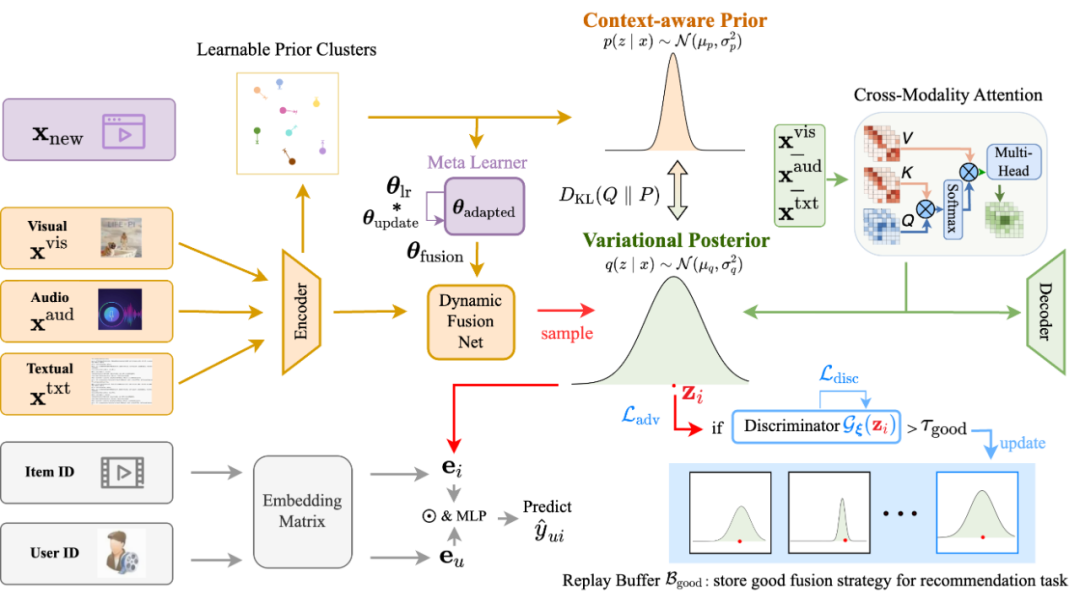
图 1 VBF++ 的分层概率模型框架。包含上下文感知先验、变分后验、动态融合网络及对抗优化模块。
为了解决简单高斯先验的局限性,VBF++ 设计了一个可学习的混合先验机制。
它不是简单地假设所有视频都一样,而是根据视频的语义类别(如动作片、音乐片、纪录片等),动态调整融合策略的先验分布。模型将视频划分为
个语义簇,并为每个簇学习特定的先验分布中心 。
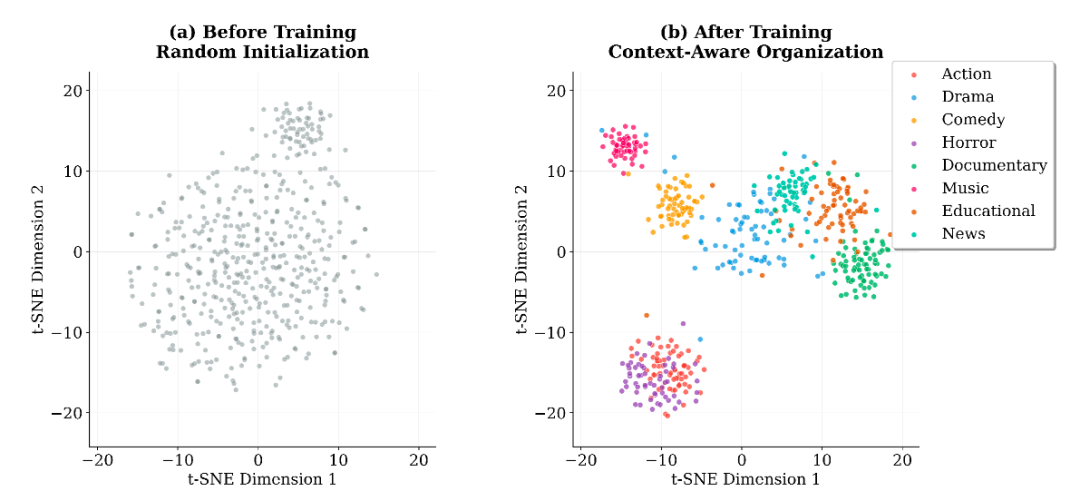
图 2 训练前后融合策略的 t-SNE 可视化。训练后策略自动聚类成有意义的语义群组。
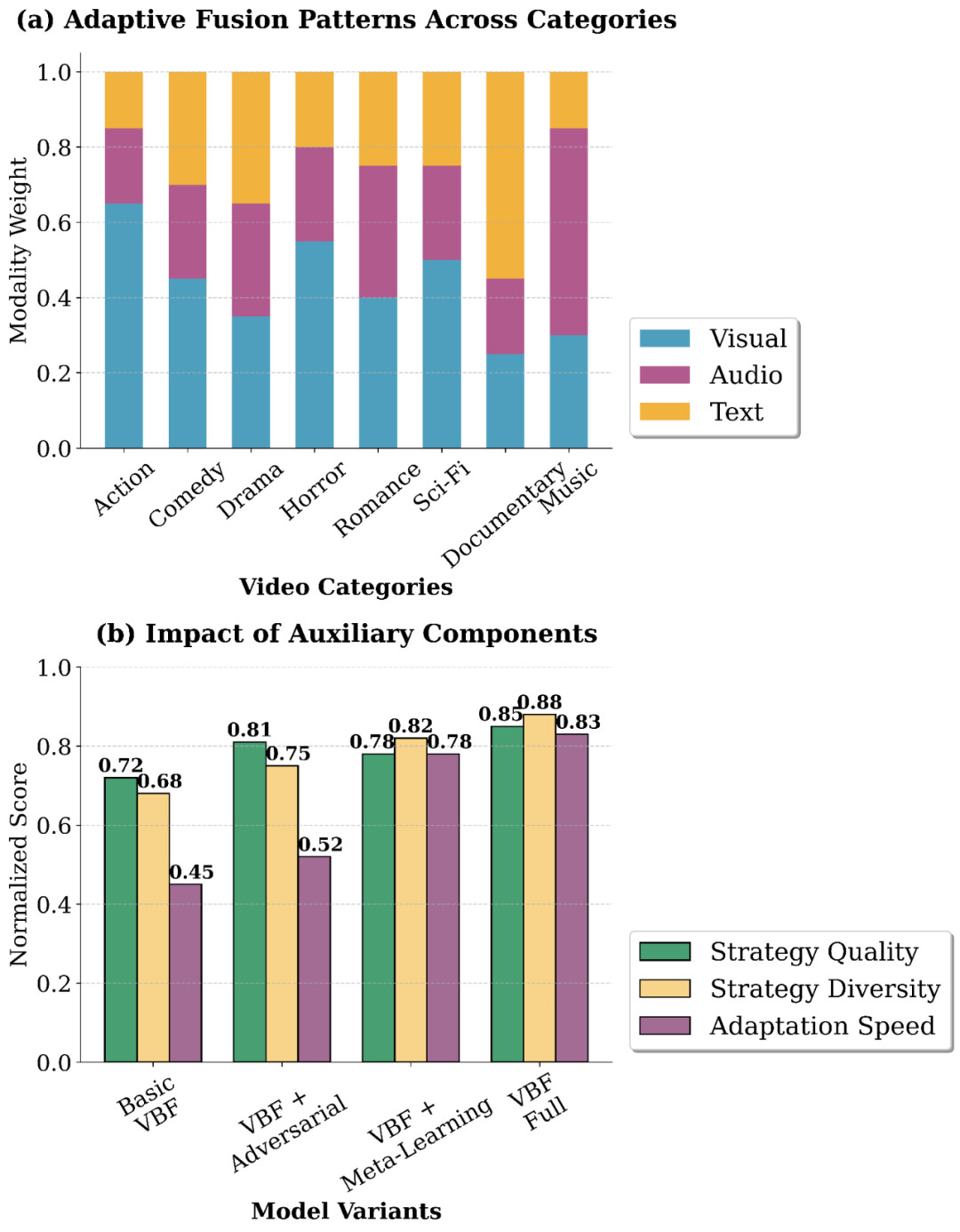
这是 VBF++ 解决“目标错位”的核心利器。
传统的 ELBO 损失侧重重构,VBF++ 引入了 RAR (Recommendation-Guided Adversarial Refinement) 范式:
-
经验回放缓冲区 :首先,模型收集那些推荐损失 较低的、高质量的融合策略 。
-
对抗训练:随后,引入一个判别器 ,通过对抗性训练强制编码器(生成器)生成的融合策略分布 逼近这个高质量策略的集合 。
简而言之,RAR 机制显式地将变分学习导向了推荐排序目标,确保了模型在保持多样性的同时,生成的策略是真正“好用”的。
为了适应快速变化的短视频环境和跨域推荐,VBF++ 集成了元学习器(Meta-Learner)。该模块利用 MAML 思想,通过梯度更新快速调整模型参数θ,实现对新内容和新领域的快速适应,有效解决了新内容的冷启动问题。
实验结果:刷新 SOTA,
兼顾多样性与准确性
VBF++ 在 MovieLens-10M、TikTok 和 Kuaishou 三个真实世界数据集上进行了全面评估,如表 1。
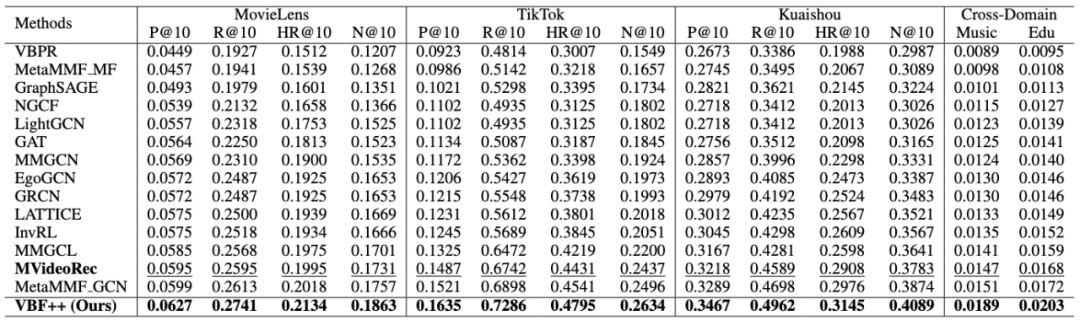
表 1 VBF++ 与现有 SOTA 方法在三个数据集上的性能对比
-
全面 SOTA:VBF++ 在所有数据集和指标上均超越了包括 LightGCN、MMGCN、LATTICE 等 14 种现有的基线方法。
-
稀疏数据表现:在数据稀疏的 TikTok 数据集上,相比最先进的 MVideoRec,Precision@10 提升了 4.7% - 8.3%,证明了概率化融合在处理不确定性和噪声方面的有效性。
-
跨域适应性:在跨域推荐设置下,VBF++ 相比基线取得了 18.0% - 25.2% 的显著提升,验证了元学习与不确定性建模结合后的强大泛化能力。
VBF++ 最大的优势在于保持推荐准确性的同时,量化了融合策略的可信度。图 4 展示了传统注意力机制与 VBF++ 在对同一视频进行 100 次推理时,其融合策略在潜在空间中的分布差异:
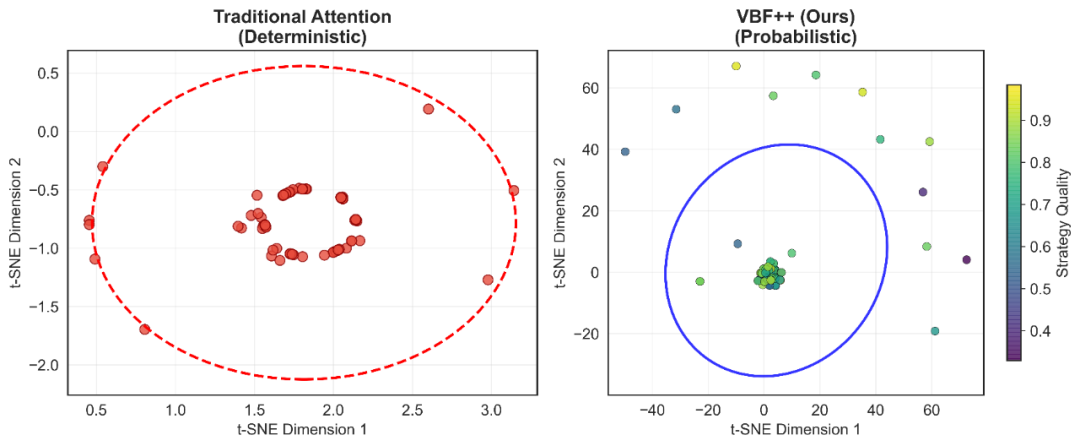
图 4 传统注意力机制(左)与 VBF++(右)在同一输入下的融合策略分布对比。颜色梯度表示策略质量。
-
传统注意力(左):结果几乎坍缩在空间中的同一个点,模型缺乏弹性,无法对融合权重的可信度进行建模。
-
VBF++(右):策略分布呈现出一个结构化的椭圆置信区域,围绕在高质量策略中心附近(绿色 / 黄色点)。这证明模型成功学习到了一个后验分布 ,在保留必要探索空间的同时,确保了准确性。
VBF++ 成功地为多模态视频推荐系统引入了不确定性建模,实现了从确定性点估计到变分贝叶斯融合的范式转变。通过三大创新模块——上下文感知先验、推荐引导的对抗优化和元学习,VBF++ 不仅刷新了 SOTA 性能,更生成了具有可解释性和语义意义的融合策略。这项工作为处理多模态数据中的不确定性和噪声提供了坚实的理论基础和有效的解决方案。
参考文献
Cao, Z., Liu, R., & Chen, Y. (2025). VBF++: Variational Bayesian Fusion with Context-Aware Priors and Recommendation-Guided Adversarial Refinement for Multimodal Video Recommendation. Beihang University & BUPT.
Wei, Y., Wang, X., Nie, L., He, X., Hong, R., & Chua, T. S. (2019). MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video. Proceedings of the 27th ACM International Conference on Multimedia (MM '19), 1437–1445.
Zhang, C., et al. (2021). Mining Latent Structures for Multimedia Recommendation. Proceedings of the 29th ACM International Conference on Multimedia (MM '21).
Liang, D., Krishnan, R. G., Hoffman, M. D., & Jebara, T. (2018). Variational Autoencoders for Collaborative Filtering. Proceedings of the 2018 World Wide Web Conference (WWW '18), 689–698.
Kingma, D. P., & Welling, M. (2014). Auto-Encoding Variational Bayes. International Conference on Learning Representations (ICLR).
Higgins, I., et al. (2017). beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. International Conference on Learning Representations (ICLR).

