清华LimiX模型重塑结构化数据处理,实现「通用」能力,引领工业AI大模型时代。
原文标题:别问树模型了!死磕结构化数据,清华团队把大模型表格理解推到极限
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到LimiX-2M体积很小,甚至能在智能戒指上运行。这种极致的轻量化和通用性,除了文中提到的手势控制和量子化学预测,大家还能想到哪些有趣或者颠覆性的边缘设备应用场景?
3、LimiX的出现被认为是结构化数据领域的一场“范式迁移”。那么,对于我们这些非专业人士来说,这种迁移会如何体现在日常生活中?它最终会给我们带来哪些直观的、能感受到的变化?
原文内容
作者:张倩、Panda
科幻作家刘慈欣在小说《超新星纪元》中描述了一个令人难忘的场景——几个十几岁的孩子被带到一个小山环绕的地方,他们的面前是一条单轨铁路,上面停着十一列载货火车,每列车有二十节车皮。这些车首尾相接成一个巨大的弧形,根本看不到尽头。这些车中,其中一列装的是味精,另外十列装的是盐。
「这么多的味精和盐够我们国家所有的公民吃多长时间?」带孩子们来的大人向他们提问。「一年?」「五年?」「十年?」没有一个孩子答对。最后的答案让他们目瞪口呆:「只够一天」。
这个场景之所以令人难忘,是因为它以一种非常具象的方式向我们展示了这个世界的运转多么难以被普通人准确感知。它的背后是海量的精确数字:负责供应盐和味精的部门需要算出每个周期要生产多少才能满足需求;负责生产的工厂要监控机器运转情况,从一堆精确却晦涩难懂的数字、代码中读出问题;而给机器供电的电力系统也要监测和变压器相关的一切数据,避免非计划停机带来高昂的抢修成本和难以估量的用户损失。
这个世界,就是以这样一种精确的方式运转着。那些数字就像我们每天呼吸的空气,你可能感觉不到它们的存在,但一旦它们出了问题,你的感知将会非常强烈。
也正因如此,这些数据的处理至关重要。由于这些数据往往以固定的行列格式组织,数据之间的结构关系是预先定义好的,因此也被称为「结构化数据」。可以说,我们在工业化社会体验到的几乎所有便利,背后都依赖着这些结构化数据的理解、处理与预测。
然而,在 AI 席卷一切的今天,处理这些最基础的数据,却成了最大的痛点。
我们寄希望于看似无所不能的 LLM 大模型。但现实很骨感:LLM 擅长写诗与编程,但却很难读懂一张简单的电子表格,因为 LLM 的建模方式(涉及到文本的模糊性)与结构化数据所要求的精确性存在巨大 gap,一直达不到生产要求。
这一现状也导致,整个行业都还在用已经存在了十几年的专用模型,每遇到一个新的数据集或者一个新任务可能就要重新训练一个。这就好比为了喝一杯新口味的咖啡,你必须重新造一台咖啡机。这种低效的生产方式与始终追求高效率、强泛化能力的 LLM 领域形成了鲜明对比,也成了阻碍产业发展的一大瓶颈。
这也是为什么,前段时间清华大学与稳准智能联合发布的 LimiX 系列模型让人眼前一亮。作为他们提出的「LDM(结构化数据大模型)」的重要成员,LimiX 做到了 LLM 没有做到的事情,把结构化数据的处理带入了大模型时代。这会改变整个工业 AI 的游戏规则,成为 LLM、具身智能之外通往 AGI 的另一大关键路径。

第一次,在结构化数据上
做到了「通用」!
为什么说 LimiX 的出现有着划时代的意义?
本质是因为,它第一次在结构化数据领域把「通用」这件事做成了!

参加过 Kaggle 的同学都知道,结构化数据领域有很多任务,比如分类、回归、缺失值填补、高维表征抽取、分布外泛化预测……比如根据年龄、舱位等级等乘客特征预测泰坦尼克号乘客是否幸存(分类),基于钻石的克拉重量、切工、颜色、净度等属性预测钻石售价的连续值(回归)等。当然,现实世界的问题远比这些复杂。
在过去的十几年里,解决这些问题主要依靠梯度提升树模型(比如 2014 年发布的 XGBoost、2017 年发布的 CatBoost 等)或 AutoML 集成模型(比如亚马逊在 2020 年提出的 AutoGluon)。就像我们前面所说的,这些模型都是专有模型,每次遇到新任务或新数据集都要重新训练。这和早就实现一个模型通吃各种任务的NLP领域相比,简直落后了不止一个版本!
当然,这些年,有不少研究者尝试将深度学习甚至基础模型思想引入结构化处理领域,像德国 Prior Labs 团队提出的 TabPFN、法国 INRIA 团队提出的 TabICL、加拿大 Layer 6 AI 团队提出的 TabDPT 等都是这一方向的代表。但这些工作都有个特点:它们本质上还是针对不同的任务分别去做专门的预训练,并没有做到真正的通用,而且对于高质量的缺失值填补等任务,这些方法还无法解决。
LimiX 模型()是一个打破僵局的存在。它在性能上碾压前述基础模型,超越 XGBoost、CatBoost、AutoGluon 这样的传统专用模型更是不在话下。

-
LimiX官网:https://www.limix.ai/
-
技术报告:https://arxiv.org/pdf/2509.03505
-
HuggingFace链接:https://huggingface.co/stableai-org
更重要的是,它第一次做到了真正的通用,也就是一个模型,在不进行二次训练的情况下,就能用于分类、回归、缺失值填补、高维表征抽取、因果推断等多达 10 类任务。
简单来说,LimiX 不再像传统模型那样死记硬背某个特定表格的规则,而是通过学习海量数据,能够自主发现样本之间和变量之间的关系并适应不同类型的任务。这使得 LimiX 拥有了类似 GPT 的能力:一个模型,通吃所有任务。对于LLM领域的研究者来说,这个剧情应该很熟悉了,当年语言模型的突破,就是从「横扫xx项NLP记录」开始的。
同时,LimiX 在 benchmark 上的一路领先,也让我们看到了一些优秀 LLM 的来时路。
比如在一场分类任务的对决中,LimiX-16M 在 58.6% 的数据集上都取得了最优结果,断崖式领先。如果再加上其轻量级版本 LimiX-2M 的成绩,整个 LimiX 家族的胜率甚至可以达到 68.9%。
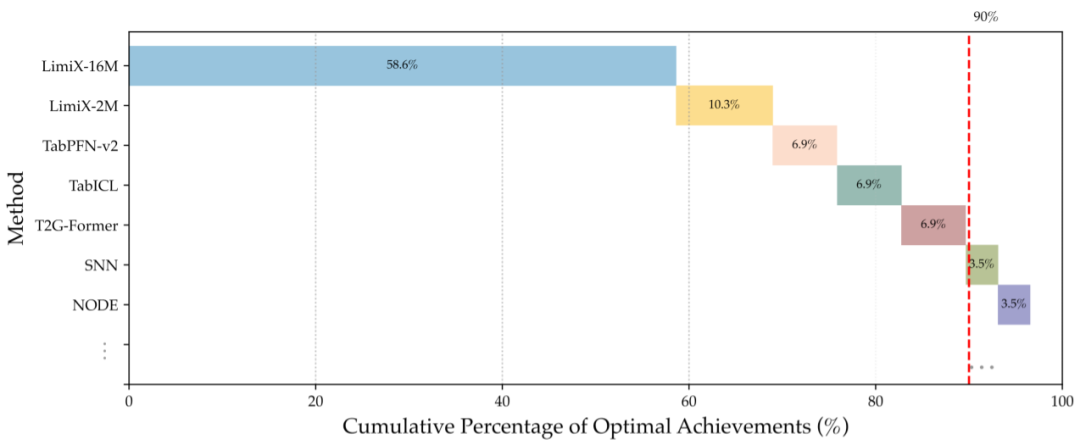
类似的情况也出现在回归任务的 PK 中。同样的,LimiX 的两个模型包揽了前两名,合在一起胜率能达到 62%。和其他模型相比,LimiX-16M 同样是断崖式领先。
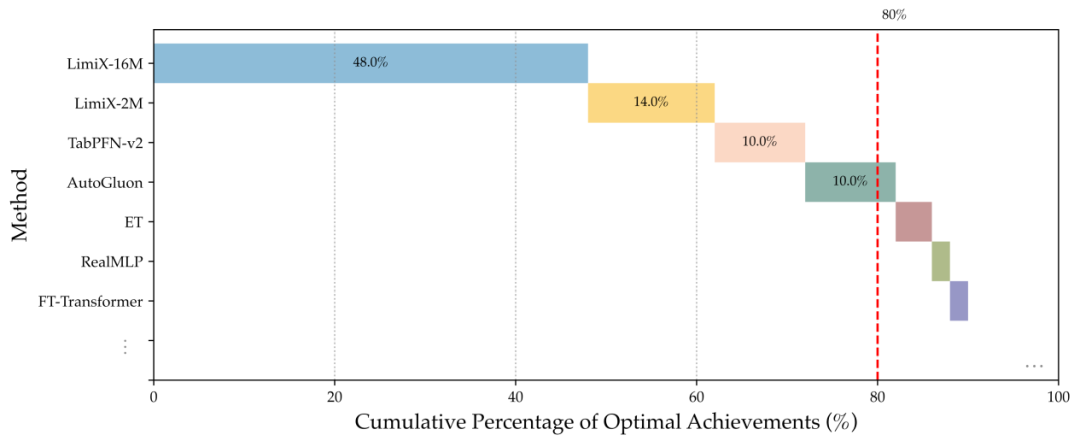
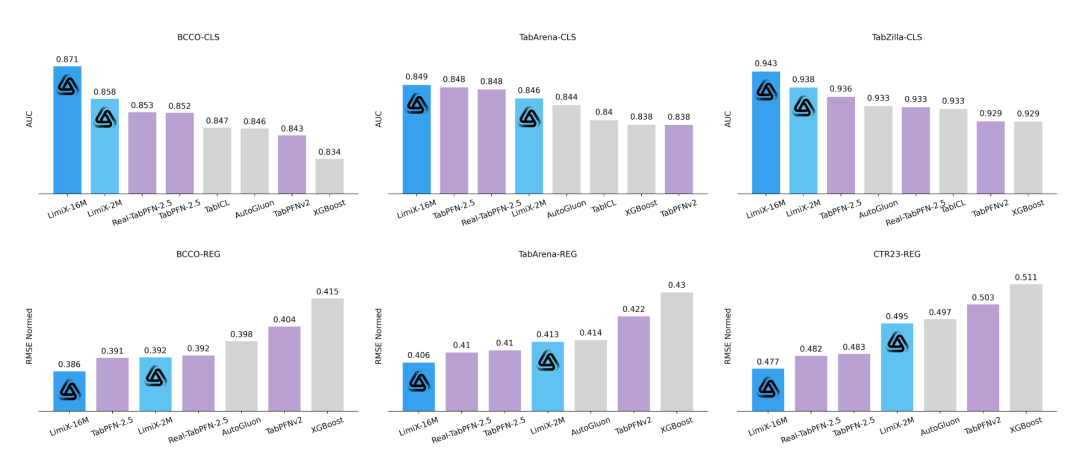
此外,对于近期 Prior Labs 团队的挑战者 TabPFN 2.5,LimiX 成功守擂。可以看到,在涉及分类、回归的六项评测中,LimiX-16M 依然保持着绝对优势。
LimiX 还是一个数据填补神器:在现实数据中,经常会有「缺胳膊少腿」的空值。其它预测模型无法直接解决这个任务,而 LimiX 可以像填空一样,精准预测并补全这些缺失值,且无需额外训练。在所有缺失值插补算法中,LimiX 以绝对优势拿下了 SOTA。
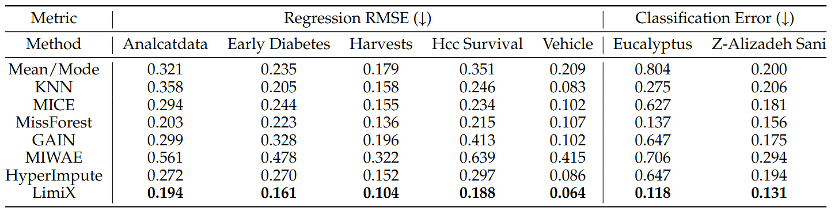
不止是跑分王
现实也能打
有人可能说,跑分好看的模型多了,现实中不还是没一个能打的。
LimiX 还真不是这种情况。它具备惊人的稳健性,使其足以落地实际工业场景。我们了解到,LimiX 已经在一些实际工厂中化身「打工人」了。工厂的任务可不像 Kaggle 赛题那样经过简化处理,随便拿出来一个都千头万绪。
就拿最容易理解的食品生产为例。我们知道,很多食品在出厂之前要经过烘干,如果哪个参数没调好,我们买到手的食品就会出现提前变质等问题。以往,食品厂都是依赖事后检测,也就是先烘干,再测含水量,不合格就返工或报废。但如果能提前预测,成本不就打下来了?
这正是 LimiX 发挥作用的环节,它可以精准建模气流流速、燃烧器温度、设备蒸汽比例等工艺参数与产品含水量的复杂关系,使得预测值与真实值平均偏差不到9%,而且模型能解释92%的结果变化,可靠性极强。
类似的案例还有很多,比如在电力现货市场预测电价时,LimiX 可以将企业内部最优模型的误差从 46.93% MAPE 大幅降低到 25.27% MAPE;而在变压器运行状态诊断中,它能将运行状态诊断错误率降低 93.5%(相较于传统预测模型 XGBoost)。
所以,无论从跑分还是实际落地情况来看,LimiX 都是一个充满变革意味的模型。而且,这个模型不仅企业能用,普通研究者也能上手,因为 LimiX 团队最近开源了一个轻量级版本——。
LimiX-2M
极小模型定义结构化数据理解极限
2M模型就能做结构化数据处理?
是的,LimiX-2M 虽然体积小,但性能却着实惊人:力压 TabPFN-v2 和 TabICL,超越集成学习框架 AutoGluon,仅次于其大哥 LimiX-16M。
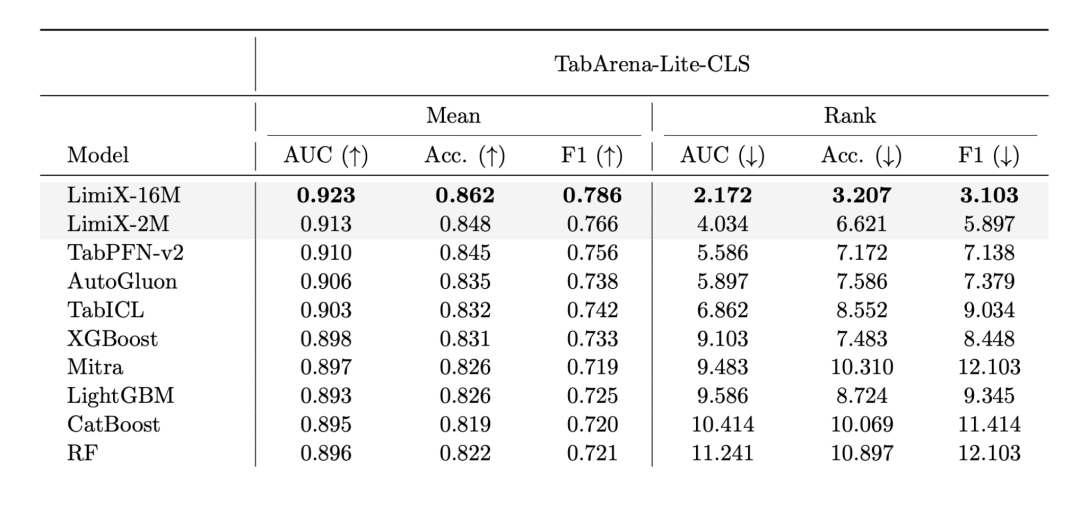
更重要的是,它很小,你甚至能在智能戒指上运行它!
具体来说,它能通过分析戒指传感器收集到的结构化位置信息,识别出佩戴者的手势。这种应用具有非常巨大的想象空间。举个例子,通过与智能家居系统连接,我们可以手势控制家里的各式电器,比如像灭霸一样打个响指,就能开关家里的所有电灯。
当然,在比边缘设备性能更强的设备上,这个小模型的速度也会快得多。
举个例子,如果是处理 958 条、60 维特征的 IMU 数据,在 2 核 CPU、4G 内存的低算力环境(差不多就是个树莓派的配置)下,LimiX-2M 单样本 375 毫秒, 总耗时为 359 秒。相较之下,TabPFN-2.5 的总耗时为 1830 秒,比 LimiX-2M 慢 5 倍。而如果你有一台 RTX 5090,则单样本平均耗时仅 0.206 毫秒,总耗时也只有 197 毫秒,真的可以说是眨眼之间就完成了!
LimiX-2M 不止性能与速度兼备,而且也能轻松地低成本微调——你只需家用显卡就能有效微调它!推理快、门槛低的特点使 LimiX-2M 成为助力研究和应用落地的不二之选:即使是只有一张 4090 显卡的小型科研团队或创业公司,也可以在自己的场景中使用、微调 LimiX-2M,从而开展此前根本无法进行的前沿AI实验。
在量子化学领域,如何去评估小有机分子的一组量子力学性质(包括激发能、振子强度和跃迁概率等)对探索分子特性非常重要。但是目前,这些性质只能通过高精度的量子化学方法(如 TDDFT 或 CC2)计算得出,量子力学性质计算成本高昂且耗时。
通过使用 LimiX-2M 对各类量子力学性质进行预测,预测的拟合优度最高可达 0.711,显著超越 TabPFN-2.5(0.658),经过微调后更是达到了 0.815。这节省了大量的实验成本,允许相关研究人员快速进行高通量分子发现。这再次证明了该模型非常适合边缘设备应用以及科研场景。你不必像 LLM 研究者一样需要大量算力,只需一台日常用来玩游戏的电脑,就能轻松高效地进行实验。
11月 10 日正式发布后,LimiX-2M 在 ModelScope 上已经有超过 1200 次下载,在网上也收获了不少好评。

同时,LimiX 还发布了详细的应用指南(https://zhuanlan.zhihu.com/p/1973033408901964300),手把手教你如何将 LimiX 应用到自己的数据上。无需复杂的格式处理,只要简单的几行代码即可接入最前沿的结构化数据大模型。无论是纯 CPU 的简单尝鲜,还是单 GPU 的深度应用,还是多机多卡的极限推理,LimiX 都能 handle!此外,LimiX 的社区非常活跃,GitHub 上的问题响应速度极快。
一场范式迁移正在发生
从 LimiX 系列模型中,我们能明显感觉到,一个新的时代真的来了。因为和以往不同,LimiX 所展现的绝对不是渐进式的改进,而是一种新的范式迁移。在 LimiX 技术报告中,研究团队甚至报告了 LDM 的 scaling laws。这进一步揭示了该领域正在迈入规模化驱动的新范式。想要更极致的性能?Just scale it!
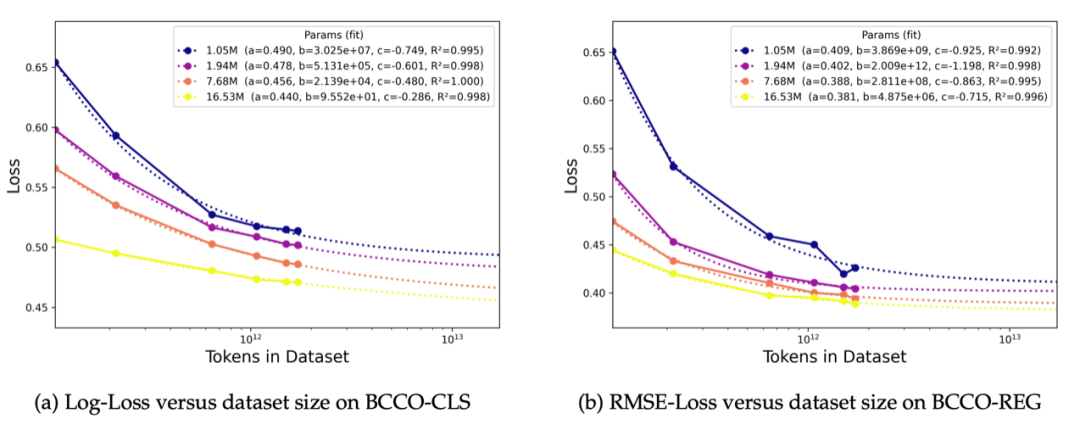
不同参数量模型的分类(左)、回归(右)损失函数随训练数据量的变化趋势。数据量增大时,损失值先快速降低后缓慢下降。
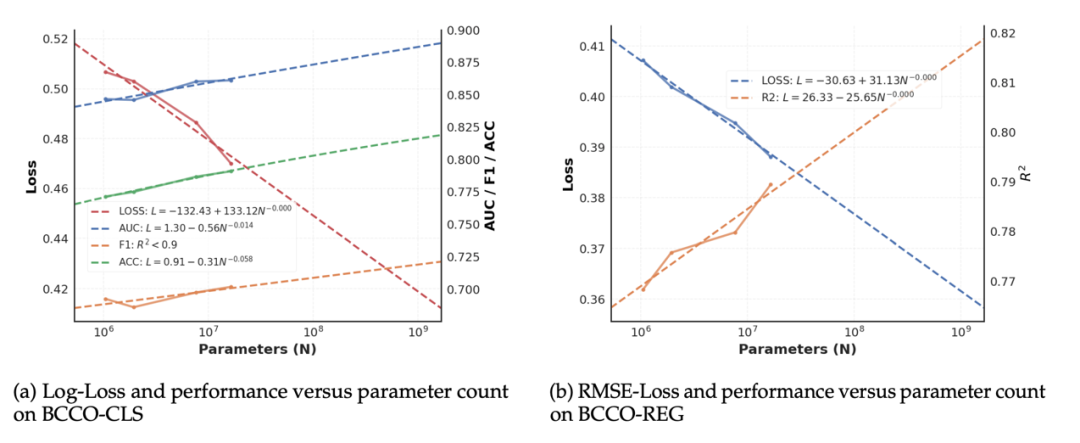
在不受数据集规模或计算预算限制的情况下,下游任务损失与性能随模型参数规模的变化。可以看到,多项性能指标均与模型参数数量 N 呈现明显的依赖关系。
对于大部分人来说,这场从传统专用模型到「LDM」通用模型的迁移可能很难感知。但无论是日常生活中稳定供应的生活必需品,还是背后庞大的工业体系,几乎所有决策都建立在结构化数据的预测与调度之上。而 LDM 正是在这个隐蔽但关键的层面上,重新定义智能的边界,其重要性完全不亚于现在被讨论最多的语言智能和具身智能。更准确地说,它和后两者是互补关系,都是通往 AGI 的关键步骤。
而且,正如清华大学长聘副教授崔鹏所强调的那样:将 AI 与工业场景深度结合,在我国具有格外突出的必要性。工业本身就是我国最具资源禀赋的领域,我们在工业数据的规模、覆盖面、质量,以及相关政策支持的力度上,都远远领先于其他国家。这意味着,一旦在这一领域形成新的技术范式,其落地深度与产业带动力将是全球范围内少有的。
从这个角度来看,LimiX 所取得的成果更加令人欣慰,它力压 Amazon AWS、INRIA 等一系列顶尖机构,在诸多性能测试上登顶。该模型的开源让中国在结构化数据建模领域真正站到了世界前沿。
我们也期待国内团队把这一方向的边界推得更远。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com