Mid-Training成LLM新热点,OpenAI等巨头布局,或将定义AI模型训练未来。
原文标题:Mid-Training 会成为未来的 Pre-Training 吗?
原文作者:机器之心
冷月清谈:
怜星夜思:
2、按照文章说的,如果 Mid-Training 以后跟预训练一样重要,那对我们这些小团队或者个人开发者来说,训练 LLM 的门槛是不是又要高一大截了?
3、文章里提到 Mid-Training 会用“中间数据”,大家觉得这个“中间数据”具体会是哪些类型?它跟 Pre-Training 的海量数据和 Post-Training 的任务数据有啥不一样呢?
原文内容
机器之心PRO · 会员通讯 Week 47
--- 本周为您解读 ③ 个值得细品的 AI & Robotics 业内要事 ---
3. 「人本主义超级智能」未来走得更远?微软为何选择亲自下场打造大模型?
通用 AI 能否杜绝模型递归式自我改进失控的风险?Transformer 架构的「生命周期」已到尽头?动态认知和记忆增强如何实现下一轮 AI 的指数级飞跃?数据已枯竭,合成数据「管用」吗?下一代 AI 的差异化在能力还是个性?...
要事解读① Mid-Training 会成为未来的 Pre-Training 吗?
引言:OpenAI 研究员 Noam Browm 在 2025 年 7 月的播客中抛出「Mid-Training 是新的 Pre-Training」的言论,某种意义上证实了 2024 年 7 月 OpenAI 低调成立「Mid-Training」部门的传言,也让业界开始聚焦于这个介于预训练和后训练之间的环节。伴随越来越多的工作开始探索和完善「Mid-Training」概念,有思潮认为该技术确有可能成为 LLM 训练中不可或缺的阶段。
预训练&后训练之外,Mid-Training 是最具潜力的非共识?
1、在 LLM 的热点聚焦于预训练和后训练时,有报道指出 OpenAI、xAI 都在 2024 年悄然设立「中期训练」(Mid-Training)部门。
① 法国研究实验室&咨询公司 Pleias AI Lab 的研究员 Alexander Doria 梳理发现,OpenAI 在 2024 年 7 月低调成立了一个「中期训练」(Mid-Training)部门,负责改进 OpenAI 的「旗舰模型」,成果包括 GPT4-Turbo 和 GPT-4o,团队贡献显著。[1-1]
② Alexander Doria 引述的招聘信息已被删除,但当前 OpenAI 当前的招聘页面中,Safety Systems team 的职位描述中直观包含「通过有针对性的预训练和 mid-Training 干预措施,使后续的协调工作更加有效和高效。」[1-2]
③ xAI 也被报道在不同渠道的招聘说明中阐述了对 Mid-Training 人才的需求。[1-3] [1-4]
④ 同在 2024 年,微软、零壹万物等机构的研究论文中接连提及对「Mid-Training」不同程度的投入。
2、「Mid-Training」在字面上与「Pre-Training」「Post-Training」高度关联,且有工作将其描述为介于两者之间的环节。然而,截止 2024 年底,不同工作对该术语的定义、理论和算法实现存在诸多差异。
3、2025 年以来,越来越多工作提及「Mid-Training」,导致业界对这个概念的关注持续升温。也有思潮认为,「Mid-Training」有希望成为像预训练和后训练一样重要的训练范式。
① 2025 年 7 月,OpenAI 研究员 Noam Brown 在播客中将 Mid-Training 描述为「新的 Pre-Training」。他表示,当前的预训练模型就像能衍生出其他模型的半成品,mid-training 就像是派生时的预训练,post-training 则完成最终的细化与优化。[1-5]
② Noam Brown 称,mid-training 是通过某些有趣的方式为模型添加新的能力或特性的一种手段,与预训练和后训练间的界限非常模糊,难以给出严谨定义,但它不同于 pre-training 中对大规模语料的广泛学习,也不是 post-training 中针对具体用途的微调,而是一个独立阶段,可以拓展模型的泛化能力和实用性。[1-5]
从有趣的技巧到必要环节,Mid-Training 到底是什么?
1、Mid-Training 的概念仍未得到明确的共识,但业界陆续涌现的探索工作从不同层面验证了 Mid-Training 的效果、机制和理论支撑。
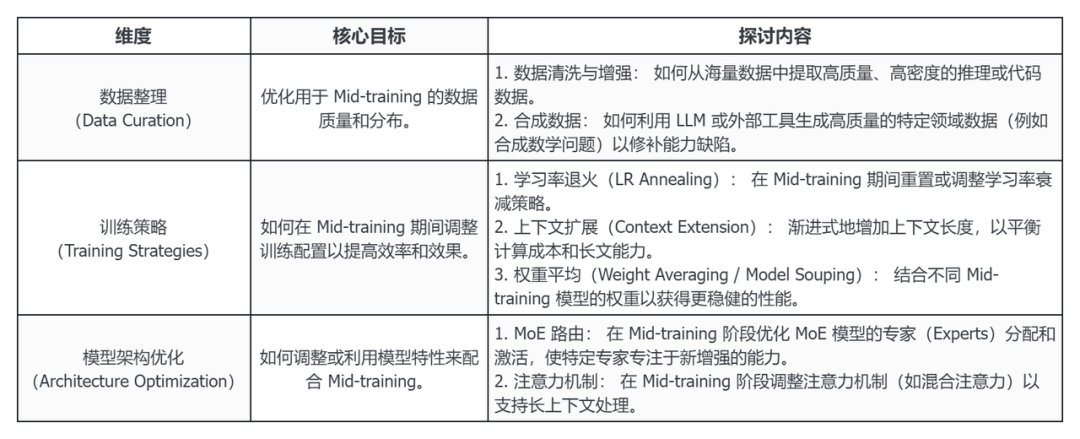
2、北大和美团的研究者在 10 月底发布综述「A SURVEY ON LLM MID-TRAINING」,尝试明确当下 Mid-Training 的定义,并通过数据管理、训练策略和模型架构优化框架三个层面探讨现有的 Mid-Training 工作。[1-6]
① 该综述将 Mid-training 定义为衔接预训练和后训练之间的一个关键阶段(vital stage),其特点是使用的中间数据(intermediate data)和计算资源(computational resources)。
② Mid-training 阶段的定位在于系统地增强 LLM 的特定能力(如数学、编程、推理、长上下文扩展),且必须保持模型基础能力不下降。
表:Mid-Trainning 的优化策略概括[1-6]
3、虽然大多探索都在过往一年多的周期中出现,但「Mid-Training」 并非 2024 新出现的词汇。其词源最早可以追溯到 Google Research 的 ACL 2020 论文「BLEURT」和该团队后续的 WMT 2020 研讨会论文。