打破数据依赖,MIT与NYU团队联合研究FreeFlow,实现无需数据的Flow Map蒸馏,刷新ImageNet生成记录!AI正迈向“无数据”新时代,聚焦内部潜能。 #AI研究 #FlowMap #无数据蒸馏
原文标题:谢赛宁与Jaakkola团队重磅研究:无数据Flow Map蒸馏
原文作者:机器之心
冷月清谈:
然而,主流的Flow Map蒸馏方法依赖于外部数据集来训练“学生模型”模仿强大的“教师模型”。这种策略存在一个核心风险——“教师-数据不匹配”。这意味着静态数据集可能无法完整准确地反映教师模型真实的生成能力,特别是当教师模型经过后期微调或泛化能力超出原始训练集时,甚至当其训练数据无法获取时,这种不匹配会严重限制学生模型的学习潜力。
论文作者敏锐地发现,尽管教师模型在生成过程中可能偏离静态数据,但其生成轨迹的起点始终锚定于【先验分布(Prior Distribution)】。这一发现成为突破口:如果能利用这个始终对齐的基点,就能规避对数据的依赖。
基于此,研究团队提出了“FreeFlow”方法——一个完全无需数据的Flow Map蒸馏框架。其核心是一个有原理依据的“预测-校正”(Predictor-Corrector)框架。在预测阶段,模型根据先验样本和积分区间,自主预测流将“跳跃”到的位置,努力与教师模型的瞬时生成速度保持一致。为了解决自我引用预测可能导致的误差累积,校正阶段则引入了一种基于【分布匹配的机制】,强制将学生模型生成的加噪速度与教师模型重新对齐,确保生成边缘分布的忠实性。
实验结果令人瞩目,FreeFlow在ImageNet上刷新了生成质量记录,在仅需1次函数评估(1-NFE)的情况下,256×256分辨率下FID达到了1.45,512×512分辨率下达到了1.49,远超所有基于数据的基准模型。这项研究不仅证实了外部数据集并非高保真Flow Map蒸馏的必要条件,更预示着AI研究正在从“向外挖掘数据”转向“向内挖掘潜能”的新范式,为生成模型的加速和“无数据”范式转变奠定了坚实基础。
怜星夜思:
2、FreeFlow实现了‘无数据’蒸馏,这真的是AI未来发展的趋势吗?如果AI真的能摆脱对海量数据的依赖,大家觉得哪些领域会最先被颠覆,或者说还有哪些技术挑战需要克服呢?
3、FreeFlow方法的精髓在于利用了“先验分布”作为稳定基点。这个先验分布在实际AI模型中到底是个啥?它的质量和稳定性对模型性能有多大影响?大家觉得这种依赖会不会带来新的隐患?
原文内容
编辑:Panda
前些天,一项「AI 传心术」的研究在技术圈炸开了锅:机器不用说话,直接抛过去一堆 Cache 就能交流。让人们直观感受到了「去语言化」的高效,也让机器之心那条相关推文狂揽 85 万浏览量。参阅报道。

事实上,这还不是近期唯一一项此类研究,NeurIPS 2025 Spotlight 论文《Thought Communication in Multiagent Collaboration》提出了 Thought Communication(思维沟通)概念,让智能体在内部层面传递潜在思维(latent thoughts),实现类似心灵感应的合作。参阅。
如果说前两项研究是在让 AI 摆脱「语言」的束缚,那么今天这项研究则更进一步:它试图让 AI 摆脱对「数据」的依赖。
来自麻省理工学院 Tommi Jaakkola 和纽约大学谢赛宁两个团队的一项联合研究又提出了一种新方法,无需数据,仅从先验分布中采样即可实现 flow map 蒸馏,并且取得了非常出色的性能表现。
这听起来简直像是武侠小说里的「闭关修炼」:不看任何武林秘籍(数据集),仅凭内功心法(先验分布)和宗师的指点(教师模型),就在极短时间内练成了绝世武功。
这篇论文的共一作者为 MIT 四年级博士生 Shangyuan Tong 和纽约大学一年级博士生 Nanye Ma。它不仅刷新了 ImageNet 的生成质量纪录(1-NFE 下 FID 达到 1.45),更重要的是,它向我们展示了一个隐约可见的未来:摆脱对显性数据(如文本、图像)的依赖,转而挖掘和利用模型内部表征或先验分布,正在崛起成为 AI 研究的一个重要新范式。

-
论文标题:Flow Map Distillation Without Data
-
论文地址:https://arxiv.org/abs/2511.19428v1
-
项目页面:https://data-free-flow-distill.github.io/
问题是什么?
我们知道,扩散模型和流模型已经彻底改变了高保真合成领域。
然而,它们需要对常微分方程(ODE)进行数值积分,而这会导致严重的计算瓶颈。
为了解决这一延迟问题,flow map 提供了一种有原理依据的加速途径。它可直接学习 ODE 的解算子,能够在生成轨迹上进行大幅度的「跳跃」,从而绕过繁琐的迭代求解过程。
虽然 flow map 可以从头开始训练,但还有一种更灵活的方案:蒸馏强大的预训练「教师模型」。
这种模块化策略可以实现对最先进的模型的压缩。
该团队观察到,目前主流且最成功的 flow map 蒸馏方法通常是基于数据的,即依赖外部数据集的样本来训练「学生模型」。
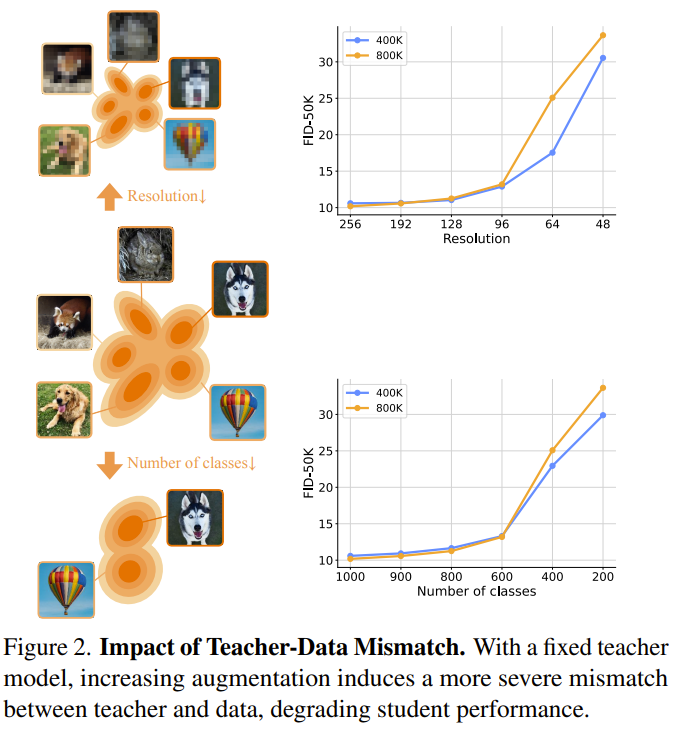
但他们认为,这种被默许的依赖关系引入了一个根本性的风险:教师-数据不匹配。
如图 1 所示,静态数据集可能无法完整或准确地表征教师模型真实的生成能力。
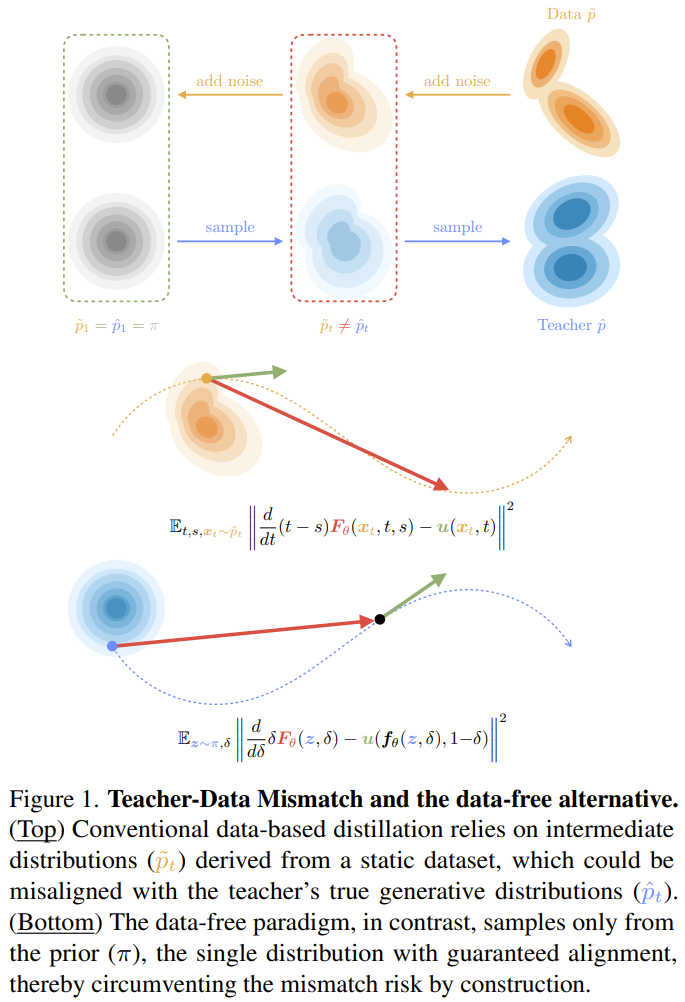
这种差异在实际应用中屡见不鲜:例如,当教师模型的泛化能力超出了其原始训练集时;当后期微调导致教师模型的分布偏离了原始数据时;又或者当教师模型的私有训练数据根本无法获取时。在这些情境下,如果强行要求学生模型在不匹配的数据集上拟合教师模型,将从根本上限制其潜力。
通俗来说,你可以把「教师模型」想象成一位不仅画技高超,还通过后期进修(微调)掌握了独门绝技的艺术大师。而我们手中的「数据集」就好比是他多年前出版的一本旧画册,甚至是市面上随便找来的一本普通参考书。
所谓的「教师-数据不匹配」,就是指这位大师现在的水平和风格(教师模型的真实生成分布)已经远远超出了那本旧画册的范畴(静态数据集)。如果强行让徒弟(学生模型)死盯着这本过时或甚至不对版的画册去学,而不是直接去观察大师现在是如何下笔的,那么徒弟不仅学不到大师现在的真本事,甚至会被画册里的错误误导,从而从根本上限制了其潜力。
解决方案它来了!
幸运的是,这种不匹配并非不可避免。
该团队敏锐地观察到,尽管教师模型的生成路径可能在中间过程中偏离静态数据集,但根据定义,它们在起点处始终锚定于先验分布(Prior Distribution)。
如图 1 所示,先验分布是唯一能保证对齐的基点:它既是教师模型生成的共同起点,也是所有加噪过程的终点。
这一发现带来了一个问题:对数据的普遍依赖真的是必须的吗?
基于此,该团队提出了一种范式转变:可以通过仅从先验分布进行采样,构建一种稳健的、无需数据的替代方案,从而在设计上(by construction)彻底规避「教师-数据不匹配」的风险。
为了践行这一理念,他们引入了一个有原理依据的「预测-校正」(Predictor-Corrector)框架,旨在纯粹从先验分布出发来追踪教师模型的动态。
-
预测阶段(Prediction):该方法首先获取一个先验样本和一个标量积分区间,预测流应当「跳跃」到的位置。团队从理论上证明,当模型的生成速度(Generating Velocity,即模型沿自身预测路径行进的速率)与教师模型的瞬时速度完全一致时,即可达到最优状态 。这使得学生模型宛如一个自主的 ODE 求解器,完全基于自身的演化预测来驾驭教师模型的向量场。
-
校正阶段(Correction):然而,正如所有的自回归数值求解器一样,这种自我引用的预测过程容易导致误差累积,使轨迹逐渐偏离 。为缓解这一问题,团队提出了一种基于分布匹配的校正机制:将模型的加噪速度(Noising Velocity,即由学生模型生成的分布所隐含的加噪流边缘速度)强制拉回,使其与教师模型重新对齐。这一机制充当了稳定器的角色,确保了生成的边缘分布始终忠实于教师模型。
他们将该方法命名为 FreeFlow,以强调其核心特征:一个完全无需数据的 flow map 蒸馏框架。
实验证明有效性
该团队在 ImageNet 上进行了广泛的实验,验证了该方法的有效性。
通过从 SiT-XL/2+REPA 教师模型进行蒸馏,FreeFlow 刷新了最佳成绩:在仅需 1 次函数评估(1-NFE)的情况下,其在 256×256 分辨率下达到了惊人的 1.45 FID,在 512×512 分辨率下达到了 1.49 FID,大幅超越了所有基于数据的基准模型。
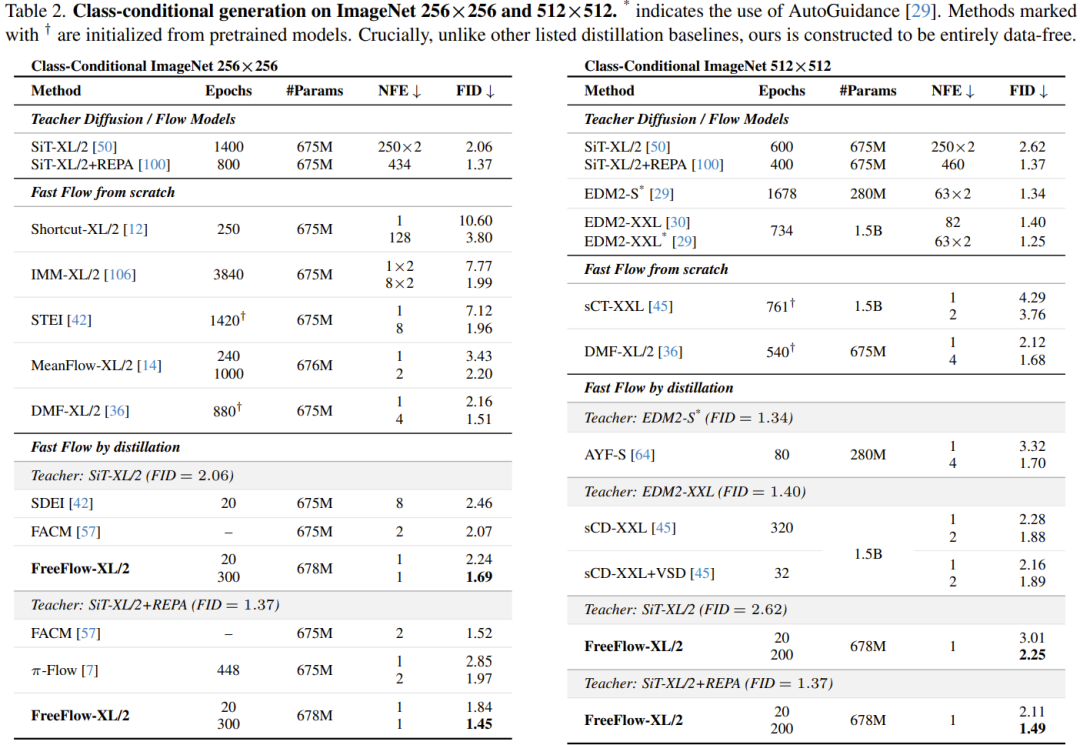

此外,利用其作为快速且一致的代理模型(proxy)的特性,FreeFlow 实现了高效的「推理时扩展」,使得在单步操作中搜索最优噪声样本成为可能。
最终,他们的研究结果证实,外部数据集并非高保真 flow map 蒸馏的必要条件:可以在完全避免「教师-数据不匹配」风险的同时,不牺牲任何性能。
他们表示,这项工作为生成模型的加速提供了更加稳固的基石,并有望推动该领域向「无数据」范式转变。
看起来,AI 正在从「向外挖掘数据」的时代,跨入「向内挖掘潜能」的新纪元。方法详情和实验细节请参阅原论文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com