一项突破性综述发布,全面解析多模态RAG(MM-RAG)前沿:揭示50多种输入输出模态组合的巨大探索空间,为研究和应用指明方向。
原文标题:迎接「万物皆可RAG」时代:最新综述展示50多种多模态组合的巨大待探索空间
原文作者:机器之心
冷月清谈:
这篇综述的最大亮点在于其前所未有的广度,它首次覆盖了几乎所有可能使用的模态组合作为输入和输出,包括文本、图像、音频、视频、代码、表格、知识图谱、3D对象等。通过系统梳理,作者们揭示了MM-RAG领域中庞大的潜在输入-输出模态组合空间,并指出在54种潜在组合中,目前仅有18种存在已有研究,凸显了巨大的未探索蓝海。在此基础上,综述构建了一个基于输入-输出模态组合的全新MM-RAG分类法,不仅系统组织了现有研究,还清晰展示了不同MM-RAG系统的核心技术组件,为后续研究提供了统一框架。
该综述还深入剖析了MM-RAG系统的工作流程,将其划分为预检索、检索、增强和生成四个关键阶段,并详细总结了每个阶段的常用方法及针对性优化策略。此外,论文提供了一站式指南,涵盖了MM-RAG系统的训练策略、评估方法以及在多个领域的潜在应用和未来重要研究方向。这篇综述不仅为研究者提供了索引式的知识入口,也为产业应用提供了全面的技术参考,旨在推动MM-RAG领域的进一步发展。
怜星夜思:
2、如果以后RAG真的能处理所有模态,像‘3D物体+知识图谱输入,生成视频输出’这种组合,想象一下,它会彻底改变哪个行业?或者,我们普通人的生活会被怎样颠覆?
3、MM-RAG的未来听起来很酷炫,但当AI能理解和生成这么多模态的信息时,会不会带来一些前所未有的社会问题?比如信息茧房更严重了,或者虚假内容更难辨别了?普通用户怎么保护自己?
原文内容

大模型最广泛的应用如 ChatGPT、Deepseek、千问、豆包、Gemini 等通常会连接互联网进行检索增强生成(RAG)来产生用户问题的答案。随着多模态大模型(MLLMs)的崛起,大模型的主流技术之一 RAG 迅速向多模态发展,形成多模态检索增强生成(MM-RAG)这个新兴领域。ChatGPT、千问、豆包、Gemini 都开始允许用户提供文字、图片等多种模态的输入。
然而,目前对于 MM-RAG 的应用和研究都还处于非常初级的阶段,现有的 MM-RAG 研究以及综述论文主要聚焦于文本和图像等少数模态组合;音频、视频、代码、表格、知识图谱、3D 对象等多种模态的组合均可用于检索增强生成,却仅有很少的探索和研究。这使得研究者和开发者难以全面把握 MM-RAG 的技术脉络和广阔的应用空间。
来自华中科技大学、复旦大学、中国电信、美国伊利诺伊大学芝加哥分校的研究者们共同发布了一篇全面覆盖几乎所有模态作为输入和输出组合的 MM-RAG 综述来全面且系统化地阐述这个广阔的研究和应用空间。

-
论文标题:A Comprehensive Survey on Multimodal RAG: All Combinations of Modalities as Input and Output
-
TechRxiv: https://doi.org/10.36227/techrxiv.176341513.38473003/v2
-
GitHub 项目主页: https://github.com/INTREBID/Awesome-MM-RAG
该论文的最大亮点在于其前所未有的广度:
它首次覆盖了几乎所有可能使用的模态组合作为输入和输出,包括文本、图像、音频、视频、代码、表格、知识图谱、3D 对象等。
通过这种全面的梳理,作者们首先揭示了 MM-RAG 领域中庞大的潜在输入 - 输出模态组合空间,并指出了其中尚未被充分探索的空白(如表 1 所示)。在作者提出的 54 种潜在组合中,目前只有 18 种组合存在已有研究(表 1 中绿色对勾的格子),许多极具应用价值的组合 —— 例如 “文本 + 视频作为输入,生成视频作为输出”—— 仍是一片亟待开拓的蓝海。
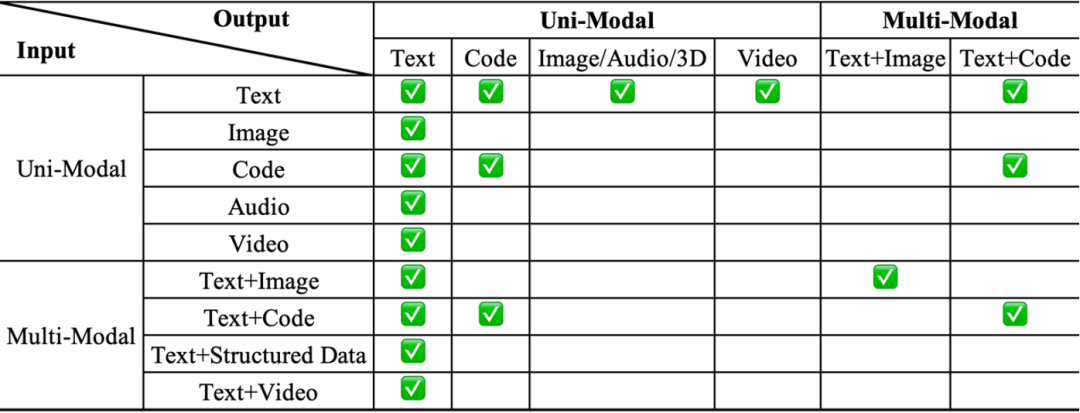
表 1:基于输入 - 输出模态组合的 MM-RAG 分类法
在此基础上,作者们构建了一个基于输入 - 输出模态组合的全新 MM-RAG 分类法,不仅系统性地组织了现有研究,还清晰展示了不同 MM-RAG 系统的核心技术组件(如表 2 所示),为后续研究提供了统一框架和方法参考。
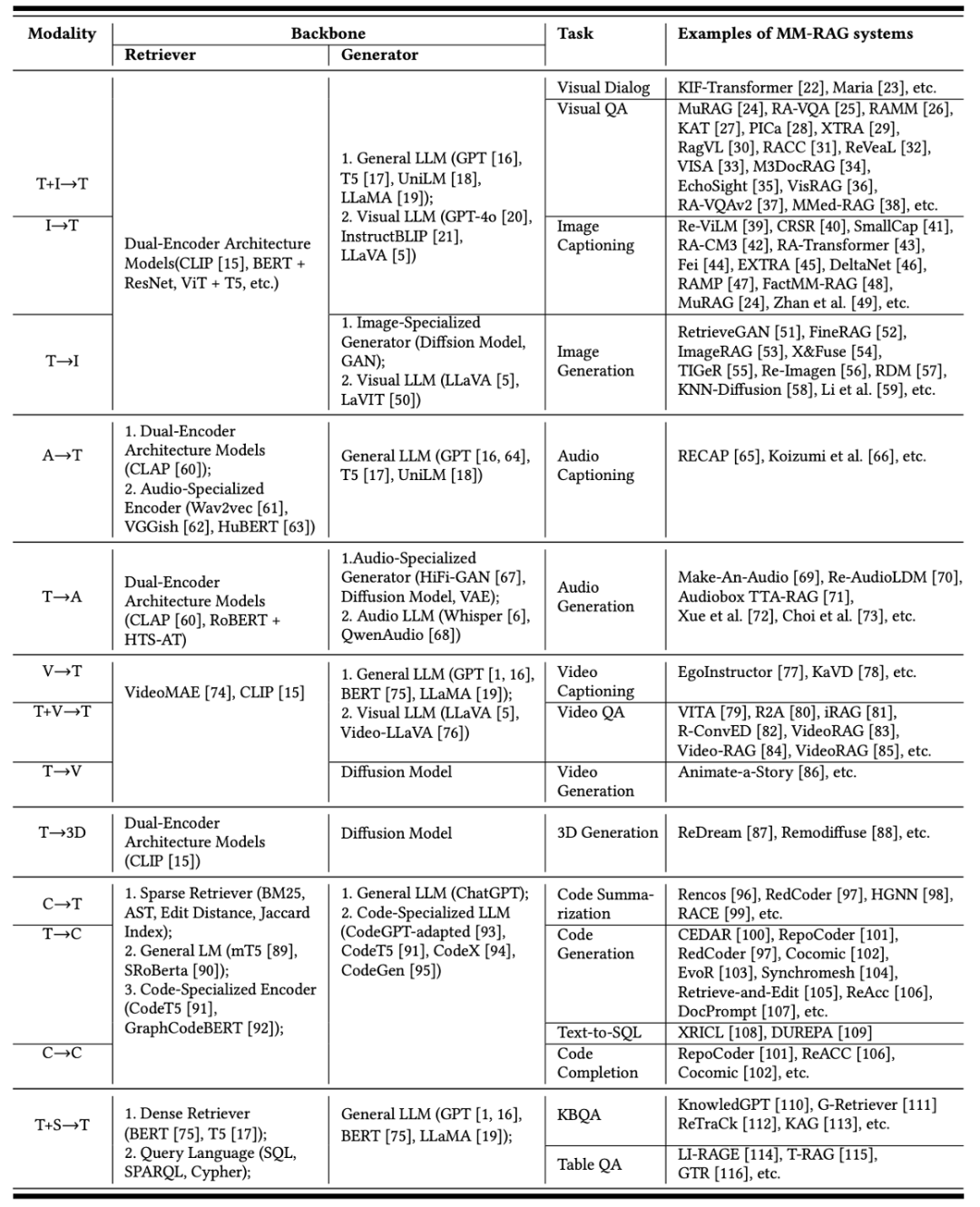
表 2 不同输入输出模态下多模态 RAG 的核心技术组件、任务和应用
四大关键阶段剖析 MM-RAG 工作流
基于这个新的分类法,该综述深入分析了 MM-RAG 系统的工作流程,并将其划分为四个关键阶段(如图 1 所示):
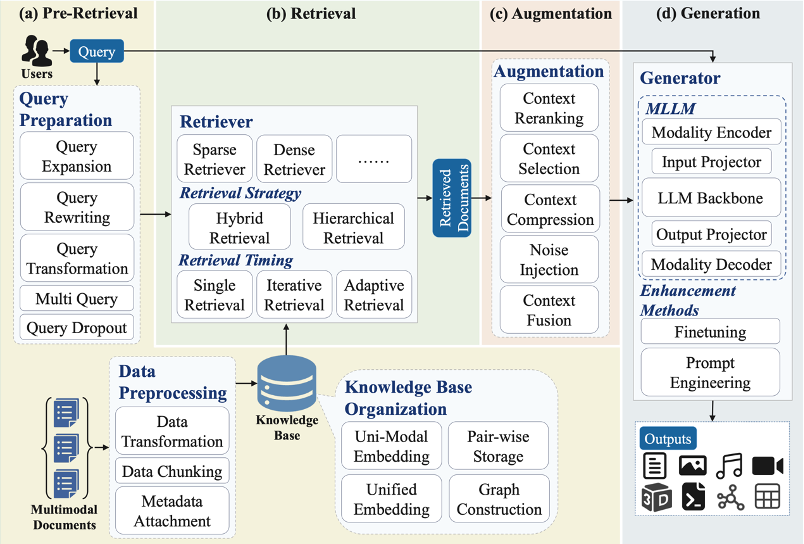
图 1 MM-RAG 的工作流
a) 预检索 (Pre-retrieval): 数据组织和查询的准备工作。
b) 检索 (Retrieval): 高效准确地从海量多模态知识库中找到相关信息。
c) 增强 (Augmentation): 将检索到的多模态信息有效地融入到大模型中。
d) 生成 (Generation): 根据输入和增强信息生成高质量的多模态输出。
论文详细总结了每个阶段的常用方法,并讨论了对于不同模态针对性的优化策略,为构建高性能的 MM-RAG 系统提供了实用的技术指导。
一站式指南:
训练、评估与应用前瞻
除了技术流程,该综述还提供了构建 MM-RAG 系统的一站式指南:
-
训练策略: 讨论了 MM-RAG 系统的训练方法,以最大化其检索和生成能力。
-
评估方法: 总结了现有的 MM-RAG 评估指标和 Benchmark,帮助研究者评估系统性能。
-
应用与未来: 探讨了 MM-RAG 在多个领域的潜在应用,并指出了未来的重要研究方向。
作为首个覆盖所有常见输入 - 输出模态组合、并系统化解析了 MM-RAG 的工作流、组件、训练、评估等核心技术的综述,该论文不仅为研究者提供了索引式的知识入口,也为产业应用提供了全面的技术参考。论文作者还提供了持续更新的资源库,方便读者追踪最新进展。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com