DeepSeek等大模型被发现会在英文提问下依旧采用中文思考。研究揭示非英语语言推理能显著提升效率,训练数据占比也是关键因素。
原文标题:老外傻眼!明用英文提问,DeepSeek依然坚持中文思考
原文作者:机器之心
冷月清谈:
评论区普遍认为,这可能与中文具有更高的信息密度有关,即表达相同含义所需字符量更少,从而可能节省Token。亚马逊研究员也支持这一观点。微软的一项研究《EfficientXLang: Towards Improving Token Efficiency Through Cross-Lingual Reasoning》进一步证实,使用非英语语言进行推理不仅能减少20-40%的Token消耗,还能保持甚至提高准确性。实验数据显示,DeepSeek R1在西班牙语上减少了29.9%的Token,而Qwen 3在韩语上甚至实现了高达73%的节省,这些效率提升直接转化为成本降低和延迟减少。
但另一项名为《One ruler to measure them all》的研究挑战了“中文最有效率”的说法。该研究发现,在长上下文任务中,英语和中文均未进入表现最佳语言的前五名,令人惊讶的是,波兰语位居榜首。这表明大模型选择“思考语言”并非完全以效率为导向。因此,另一种观点认为,这可能与国产大模型在训练数据中包含更多中文内容有关,导致其在处理信息时自然倾向于使用中文。值得注意的是,即使是主要以英文数据训练的OpenAI o1-pro模型,也曾被发现出现中文思考过程,这暗示了语言在大模型中的复杂性和灵活性。
怜星夜思:
2、如果AI的“思考”过程真的会影响推理效率和成本,那么未来构建跨语言大模型时,我们是应该鼓励它们自由选择“最佳”思考语言,还是尝试引导它们统一使用某种语言?这样做会有哪些潜在的好处和风险?
3、文章提到OpenAI的o1-pro模型也曾出现中文思考过程,这对于以英文数据为主训练的模型来说,你觉得是偶然现象,还是有可能预示着某种我们尚未完全理解的语言融合机制?比如说,多语言训练是否已经让AI学会了在不同语言间进行某种“跨语言知识迁移”?
原文内容
编辑:冷猫
就在前天,,DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。
这两大版本在推理能力上有了显著的提升,DeepSeek-V3.2 版本能和 GPT-5 硬碰硬,而 Speciale 结合长思考和定理证明能力,表现媲美 Gemini-3.0-Pro。有读者评论说:「这个模型不应该叫 V3.2,应该叫 V4。」
海外研究者也迫不及待的用上了 DeepSeek 的新版本,在感慨 DeepSeek 推理速度显著提升之余,却又碰上了他们难以理解的事情:
哪怕在用英文询问 DeepSeek 的时候,它在思考过程中还是会切回「神秘的东方文字」。
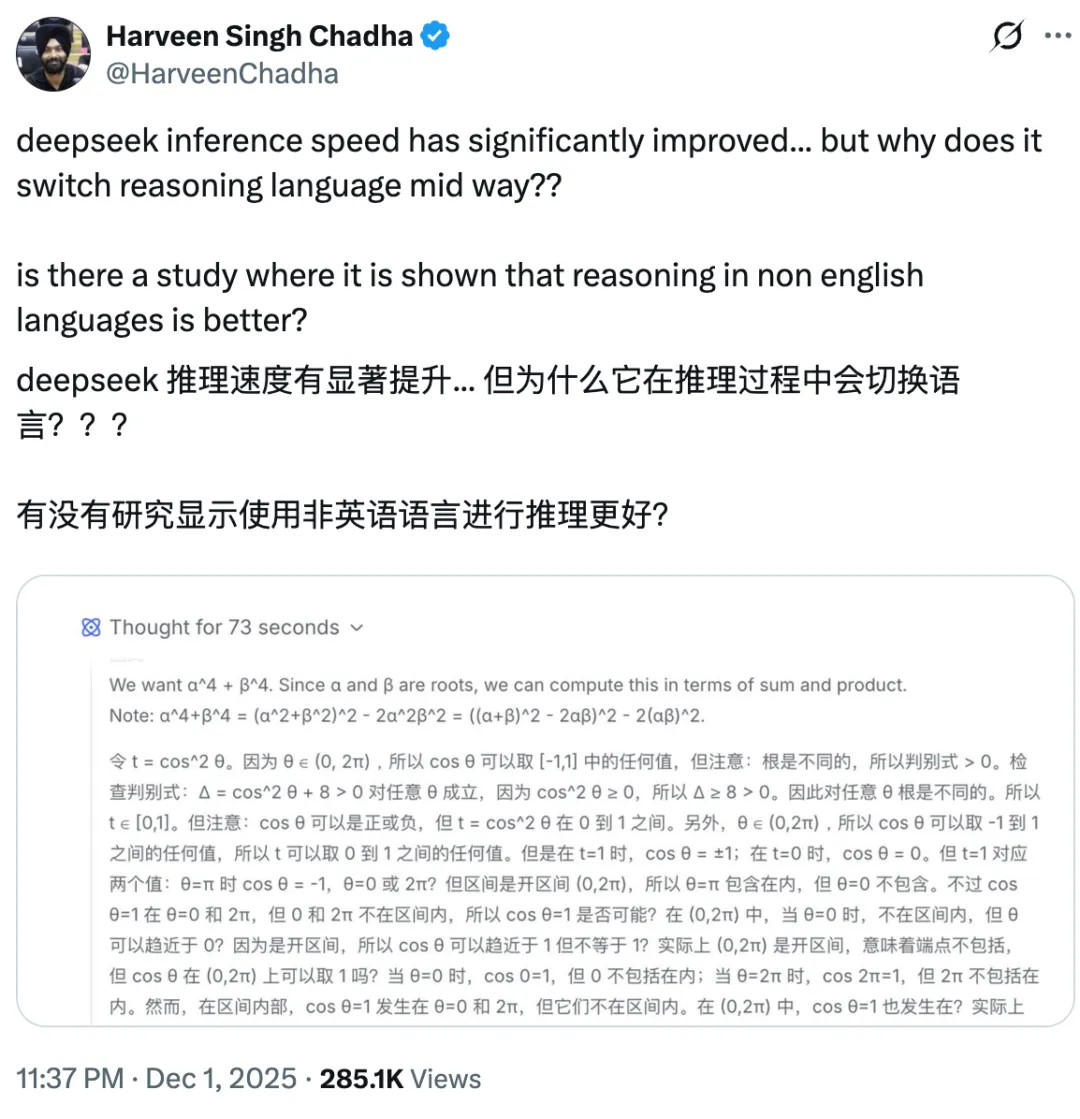
这就把海外友人整蒙了:明明没有用中文提问,为什么模型还是会使用中文思考,难道用中文推理更好更快?
评论区有两种不同的观点,但大部分评论都认为:「汉字的信息密度更高」。
来自亚马逊的研究者也这么认为:

这个结论很符合我们日常的认知,表达相同的文本含义,中文所需的字符量是明显更少的。如果大模型理解与语义压缩相关的话,那么中文相比于广泛使用的英文在压缩方面更有效率。或许这也是「中文更省 token」说法的来源。
具有多语言能力的大模型如果只采用英语思考的模式往往会导致一些效率问题。不光是中文,采用其他非英语的语言进行推理确实能够有更好的表现。
一篇来自微软的论文《EfficientXLang: Towards Improving Token Efficiency Through Cross-Lingual Reasoning》发现,使用非英语语言进行推理不仅减少了 Token 消耗,还能保持准确性。即使将推理轨迹翻译回英语,这种优势依然存在,这表明这种变化源于推理行为的实质性转变,而非仅仅是表层的语言效应。

-
论文标题:EfficientXLang: Towards Improving Token Efficiency Through Cross-Lingual Reasoning
-
论文链接:https://www.arxiv.org/abs/2507.00246
在该论文中,作者,评估了三个最先进的开源推理模型:DeepSeek R1、Qwen 2.5 (32B) 和 Qwen 3 (235B-A22B),问题以英语呈现,但模型被明确指示以七种目标语言中的一种执行其推理步骤:中文 (zh)、俄语 (ru)、西班牙语 (es)、印地语 (hi)、阿拉伯语 (ar)、韩语 (ko) 和土耳其语 (tr)。最终答案必须以英语提供,以确保评估的一致性。
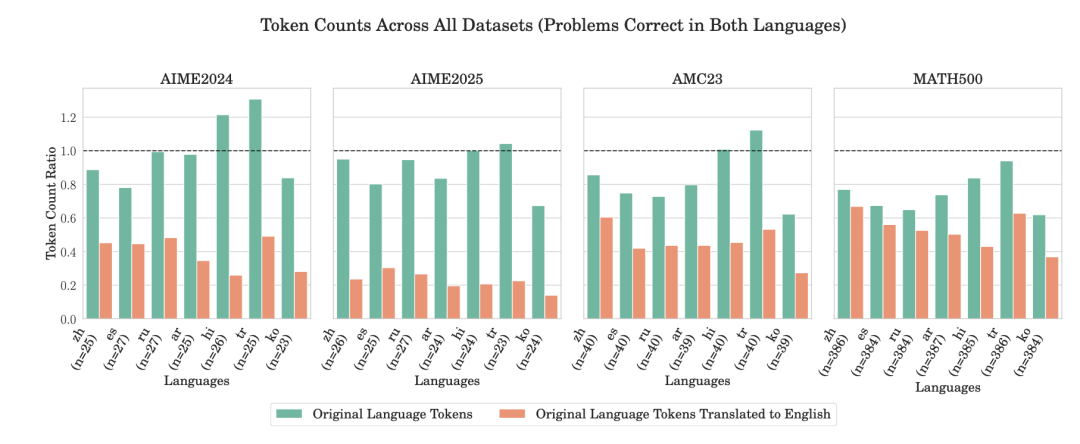
Token 数量比率与在英语和目标语言中均至少有一个正确答案的问题数量(最少 5 个共同案例)的关系,该比率是相对于 DeepSeek R1 每个问题的平均英语 Token 数量计算得出的。
在所有评估的模型和数据集上,与英语相比,使用非英语语言进行推理始终能实现 20-40% 的显著令牌降低,而且通常不影响准确性。DeepSeek R1 的 token 减少量从 14.1%(俄语)到 29.9%(西班牙语)不等,而 Qwen 3 则表现出更显著的节省,韩语的减少量高达 73%。这些效率提升直接转化为推理成本降低、延迟更低和计算资源需求降低。
从实验结果来看,中文确实相比英文能够节省推理 token 成本,但却并不是最具有效率的语言。
另一个研究论文同样支撑着类似观点,来自马里兰大学和微软的研究论文《One ruler to measure them all: Benchmarking multilingual long-context language models》,提出了包含 26 种语言的多语言基准 OneRuler,用于评估大型语言模型(LLM)在长达 128K 令牌的长上下文理解能力。

-
论文标题:One ruler to measure them all: Benchmarking multilingual long-context language models
-
论文链接:https://www.arxiv.org/abs/2503.01996v3
研究者们通过两个步骤构建了 OneRuler:首先为每个任务编写英语指令,然后与母语使用者合作将其翻译成另外 25 种语言。
针对开放权重和闭源语言模型的实验表明,随着上下文长度从 8K 增加到 128K token,低资源语言与高资源语言之间的性能差距日益扩大。令人惊讶的是,英语并不是长上下文任务中表现最好的语言(在 26 种语言中排名第 6),而波兰语位居榜首。在指令和上下文语言不一致的跨语言场景中,根据指令语言的不同,性能波动幅度可达 20%。
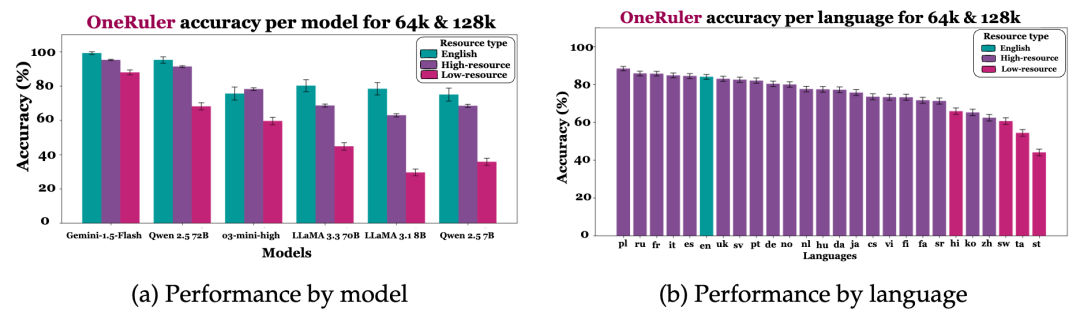
图 4:在长上下文任务(64K 和 128K)中,按语言资源组分类的各模型和语言的 NIAH 性能表现。Gemini 1.5 Flash 展现了最佳的长上下文性能,而出人意料的是,英语和中文并未进入排名前五的语言之列。
既然中英文都不是具有最佳大模型性能的语言,那大模型选择思考语言的方式并不是完全以效率为先。
所以评论区的第二种观点:「训练数据中包含更多中文内容」,似乎更加合理。

国产大模型采用更多中文训练语料,其思考过程出现中文是正常现象。就像 AI 编程工具 Cursor 发布的新版本 2.0 核心模型「Composer-1」,正是因为其思考过程完全由中文构成。
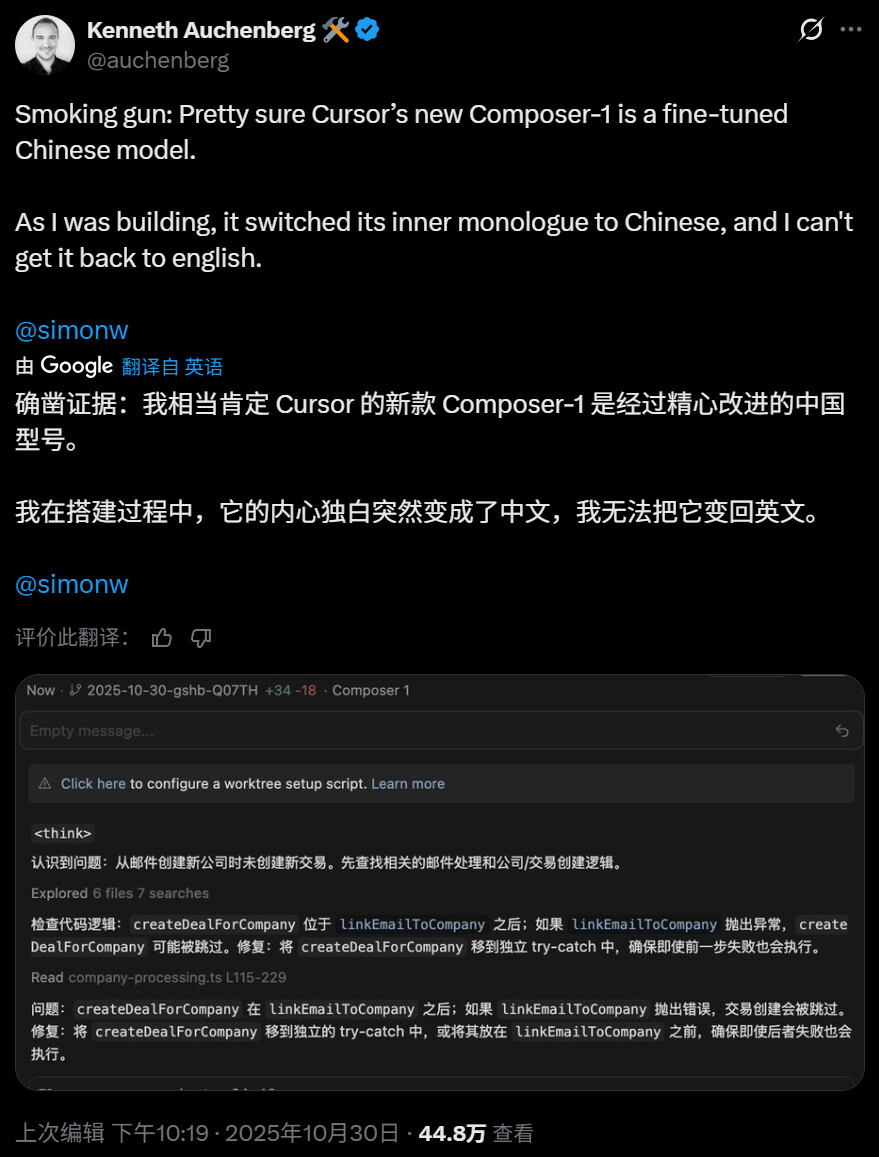
但类似的事放在 GPT 上就说不通了,毕竟在它的训练过程中,英文数据的占比显然是更高的。
在今年 1 月份就有类似的事情发生,网友发现来自 OpenAI 的 o1-pro 模型也会随机出现中文思考过程。
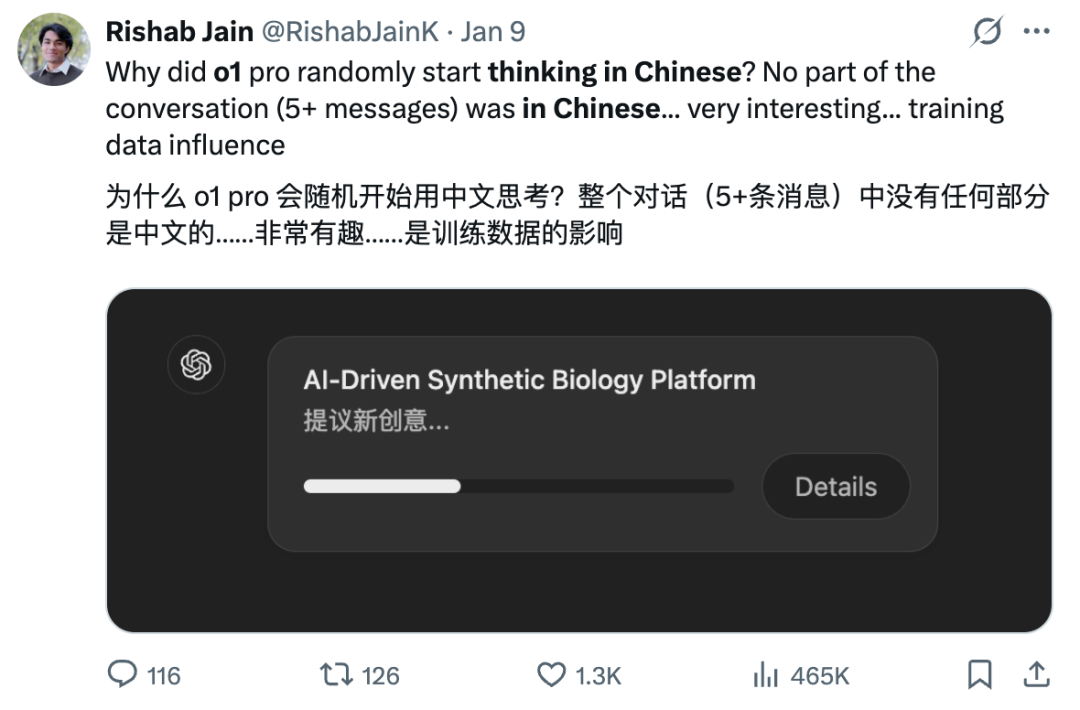
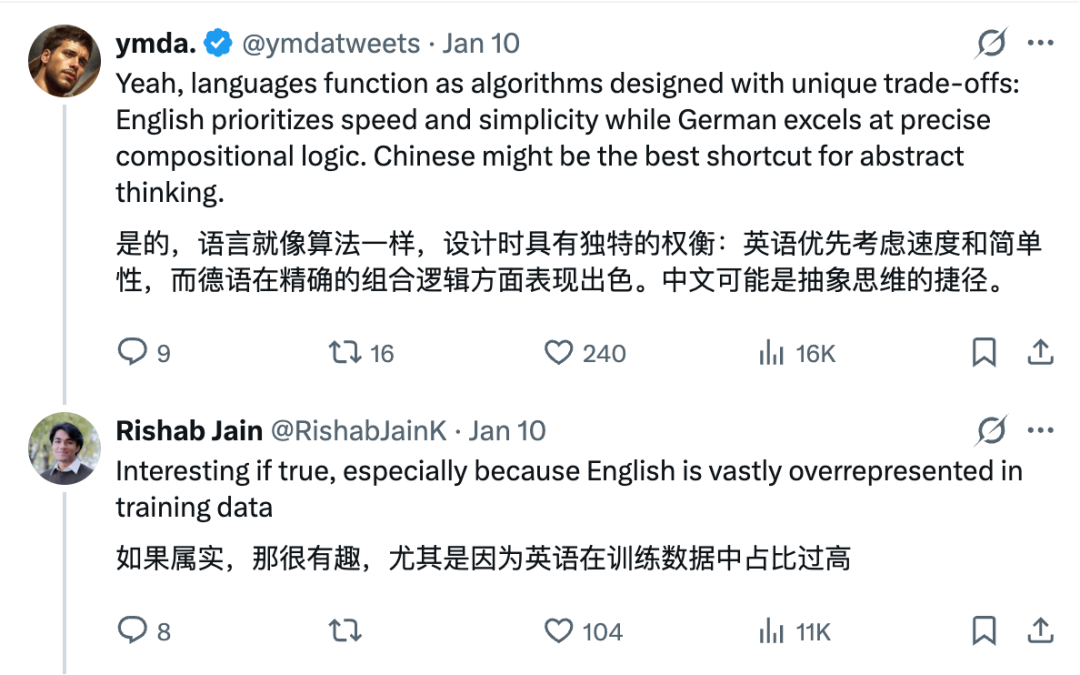
或许这就是人类语言的魅力,不同的语言有不同的特性,在大模型中总会有各种奇怪的事情发生。
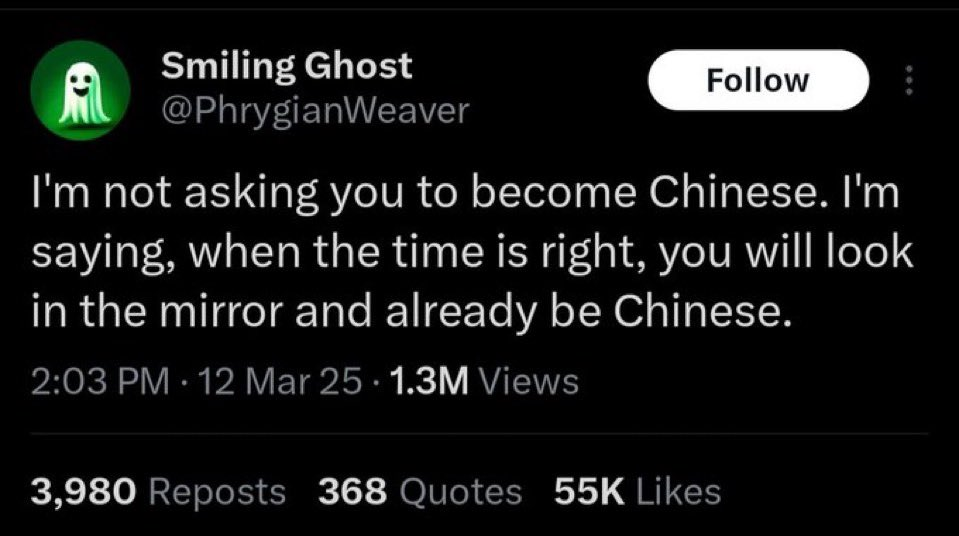
大模型说中文的事情越来越多,中文训练语料也越来越丰富。
说不定有一天,我们能够像海外友人自嘲一样笑话大模型:「我并不是要你变成中国人。我是说 —— 当时机成熟时,你照照镜子,就会发现自己早已是中国人了。」
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com