《从零构建大模型》:跟着大师手把手搭建LLM,实战派学习者的福音!
原文标题:豆瓣评分 9.4,为什么很多人都在推荐这本书?几页就能让你看懂!
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、文章里提到这本书能帮助我们把零散的知识点串起来,这一点我深有体会。但LLM领域发展太快了,除了这种系统的书,大家平时还会通过哪些途径或者说哪些资源来学习最新的知识和技术呢?有没有什么特别推荐的“野路子”?
3、书里强调能“从零手写一个可运行的小型GPT”,这听起来很酷。但在现实中,我们面对的都是动辄千亿参数的大模型,这种“小型GPT”的实践经验,对于我们理解或以后参与真正的大模型开发,到底能有多大的帮助?它的局限性又在哪里呢?
原文内容
作为一个对 LLM 工作原理很感兴趣,但又常常被各种零散教程绕晕的人,我读完 Sebastian Raschka 的《从零构建大模型》之后,其实挺松一口气的。
我原本以为这本书要么会过度简化、要么会高度抽象,甚至可能出现那种你先接受这个公式就好的玄乎讲法,但它其实很踏实,从最基础的模块开始讲起,一步步带你把模型搭出来。
01
信息量够,不会压得人喘不过气
整本书的信息量算大,但内容组织得挺清楚。作者没有一上来就把一堆术语、架构往你脸上砸,而是更像帮你搭好积木的底层,然后带着你一步步往上搭。
阅读过程中我偶尔也会卡住,但不会有那种完全不知道自己在看什么的崩溃感。
02
解释详细但是不花哨
Raschka 对 Transformer 的细节讲得挺透,比如注意力机制、梯度问题之类的,他会解释,也会给例子,但不会为了炫技而堆很多数学推导。对我这样只是想搞懂其中逻辑的人来说,这种平衡刚好。
不过如果你本身就想完全跳过数学,可能还是会觉得有点重。相反,如果你想要非常深入的理论推导,这本书不是论文风那种深度,完全能够理解。
03
能跑,是这本书最大的亮点之一
这本书对我来说最实用的地方就是代码都能跑,而且结构非常清晰。如果你是那种喜欢边看边敲的读者,这本书的代码体验会让人放松不少——至少我没有遇到那种跑不通然后花两小时找问题的崩溃情况。
当然,因为是从零开始写一个小型 GPT,代码量其实不算少,这部分需要你愿意花点时间去跟着操作才行。
04
覆盖整个流程,不只是教你搭个模型
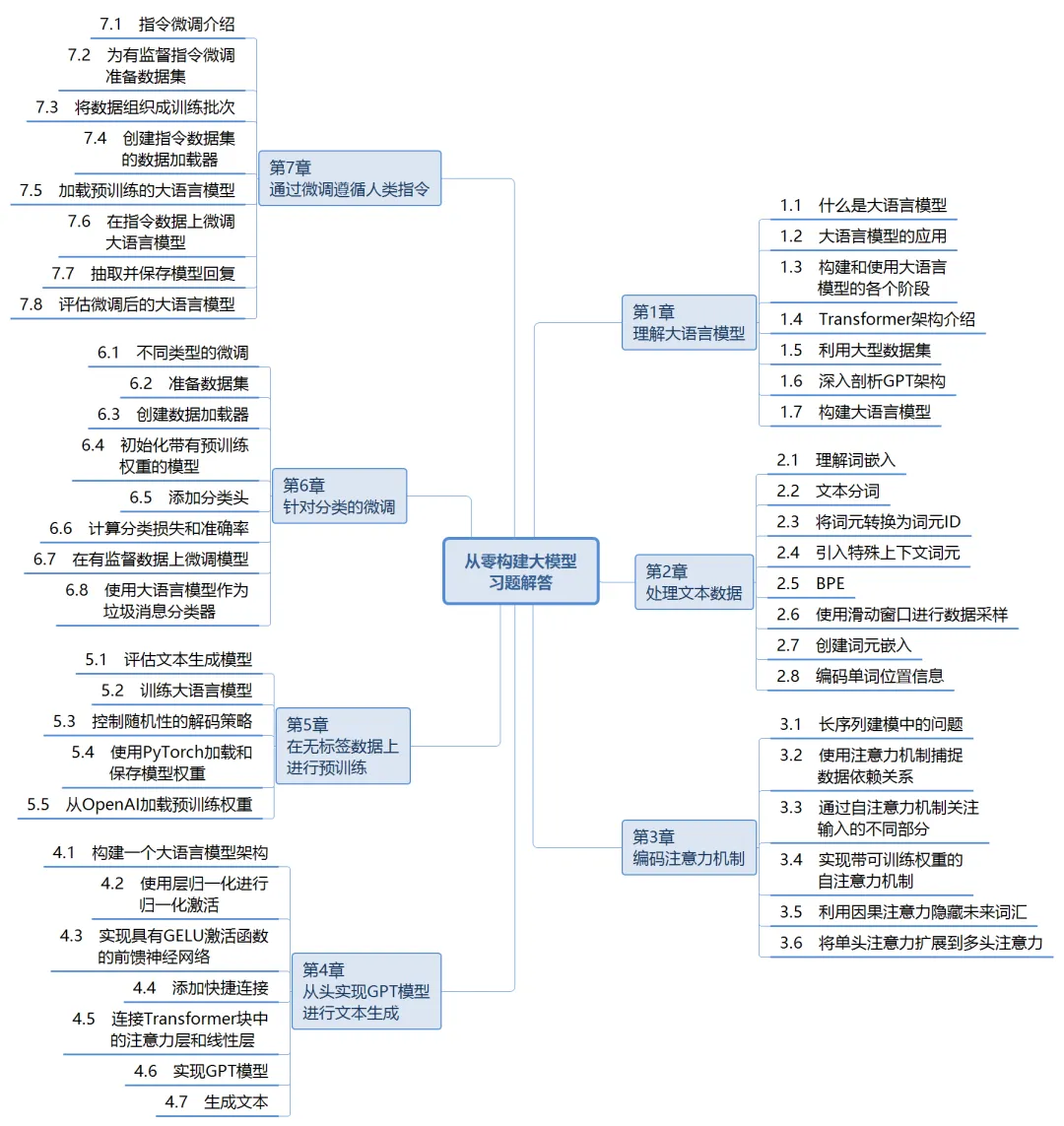
书里从数据准备到预训练、再到微调任务(比如文本分类、指令跟随)都有涉及。它不会让你变成 LLM 大神,但能给你一个比较完整的开发流程印象,让你至少知道一个模型从头到尾都经历了什么。这对你之后训练自己的大模型很有帮助。我挺喜欢这一点,因为它并不只关注模型本体,而是关注整个实际使用的链条。
05
你不会突然开窍,但会变得踏实
读完之后,我不会说自己彻底懂了所有 LLM 原理,但有种我现在知道这些东西是怎么连在一起的感觉。对我来说,这比过度承诺的从小白到专家更真实。
如果你想从零手写一个可运行的小型 GPT,或者想把零散知识整合起来,这本书确实挺适合。
但如果你只是想看点概念、快速了解趋势,那它可能会比你预期更动手型。
06
全网疯传的《从零构建大模型》

覃立波,冯骁骋,刘乾 | 译
在本书中,你将学习如何规划和编写大模型的各个组成部分、为大模型训练准备适当的数据集、进行通用语料库的预训练,以及定制特定任务的微调。此外,本书还将探讨如何利用人工反馈确保大模型遵循指令,以及如何将预训练权重加载到大模型中。还有惊喜彩蛋 DeepSeek,作者深入解析构建与优化推理模型的方法和策略。