高德发布地铁智能图文引导,告别站内迷路。全程指引,提升出行体验,让“最后一公里”不再是难题。
原文标题:打通出行最后一公里|高德面向地铁场景的多模态智能图文引导系统
原文作者:阿里云开发者
冷月清谈:
项目设计上,高德根据地铁站点的复杂度与重要度进行分层规划,针对极度复杂或重要的站点,提供AR/VR等高科技精准服务; 对一般复杂或重要的站点,则通过图文引导、文字提示等差异化服务提升用户体验。
技术层面,系统通过定制化APP采集包含多媒体和IMU传感器数据,并结合语音大模型(FunAsr)和多模态大模型(Qwen-VL)进行自动化审核。在图文生产中,不仅能自动选帧以保证图片清晰度,还创新性地引入基于Segment-Anything、Kontext-Dev和ComfyUI的“人物擦除”技术,有效去除图片中的人物,确保引导信息的清晰度和美观性。目前,该项目已覆盖超过4万条地铁站内通行路径,并获得用户积极反馈。
怜星夜思:
2、文章里提到一个挺有意思的技术点是“人物擦除”,就是用AI把采集到的引导图片里的人P掉,让画面更干净。这技术确实很实用,但是大家有没有想过,AI这样改动真实影像数据,在隐私和伦理方面会不会引起一些讨论或者潜在的问题呢?
3、高德这次是针对地铁站做了这种精细化的多模态引导。除了地铁,大家觉得还有哪些场景的“最后一公里”导航痛点特别突出,急需类似甚至更创新的多模态引导解决方案呢?比如大型商场、医院、机场、甚至大学校园内部?为什么会是这些场景?
原文内容

一、背景
你是不是也有过刚刷完进站闸机,抬头十几条指示牌,一脸懵;换乘只隔一条站台 最后走到腿软还绕回原点;地铁口连商场没指路牌,硬生生逛成“买单人流”。
面对日益多样化的用户场景和亟待提升的用户体验指标,现有的通用引导策略已显不足。而高德地图的公交接驳指引项目是从“以交通方式为中心”到“以用户完整行程为中心”的升级。通过激活数据关联价值,为用户提供无缝的端到端出行体验。
精细化指引——填补“最后一公里”导航空白
现代地铁站,尤其是换乘枢纽站往往具有多层结构、多个出口、多条线路交汇的特点。然而站内指引信息呈现碎片化,路径指引不连贯,同时存在部分引导信息缺失,引导信息混乱错乱等问题。
导航软件受限于地铁站空间结构和定位信号不准等原因,只能指引到地铁站出入口,进入站内后便“失联”。图文引导通过清晰的路径图示和分步说明,帮助用户“按图索骥”,降低迷路概率。同时打通了“地面到站台”的最后一环,实现从“家门到车厢”的全流程连续导航,提升出行体验的完整性。
二、产品设计
分层与分类
从场站复杂度和重要度方面综合考虑ROI,有重点有取舍的完善引导体系:
-
场站极度复杂且重要地铁站=>打造新时代AR/定点VR的科技感精准精品导航服务。
-
场站极度复杂重要度一般或场站复杂度一般但非常重要的地铁站=>提供图文引导,打造优于竞品的差异化贴心服务。
-
场站不复杂但重要度极高或场站复杂度一般重要度一般的地铁站=>提供文字提示,轻巧灵活保用户无忧。

图一 产品策略划分
考虑因素
场站复杂度主要因为立体化设计、换乘通道过长、出口分布复杂或标识系统不足导致,具体影响参数是地铁楼层数,换乘线路数,出入口数量,出入口相对位置等。
场站重要度主要是看周边是否有高优景区或高德推荐,机场火车站,高优酒店,特色商业街/步行街/购物中心,,以及场站的热度(规划量)。
拓展精细化多模态引导信息透出
VR(支持少量)
图文(已完成)


三、技术方案
整体架构

图二 业务架构图
采集
采集模块划分
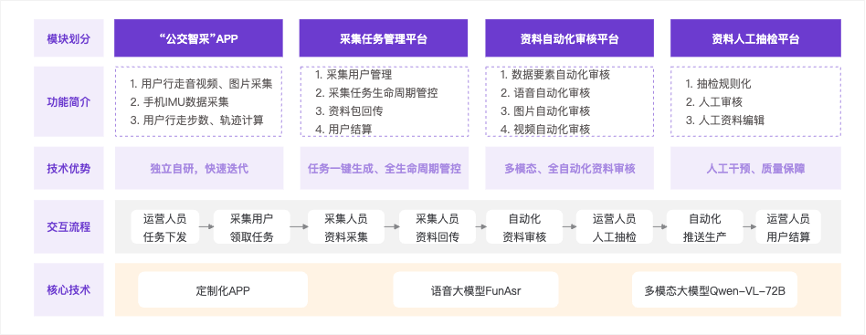
图三 采集模块示意图
采集任务
采集任务以“任务包”的形式组织,一个任务包对应一个具体的地铁站点。采集人员使用定制化的APP领取并执行任务。任务内容覆盖进站、出站、换乘等场景,需要采集包含起点/终点照片、过程视频等多媒体数据,并同步记录手机的IMU传感器数据。视频语音中要包含标准的动作指令(如左转、右转)和行为指令(如过安检、上扶梯)等用于后续的资料审核和图文制作。
数据处理与审核流程:
采集完成的数据将进入一个自动与人工相结合的资料审核流程:
-
数据回传: 采集人员通过APP将数据包上传至采集任务管理平台。
-
自动化审核: 数据首先进入资料自动化审核平台,该平台利用语音大模型(FunAsr)和多模态大模型(Qwen-VL-72B)对语音、图像、视频等数据进行初步的自动化、多模态审核,大幅提升效率。
-
人工抽检与质保: 自动化审核后,运营人员在资料人工抽检平台根据规则进行抽检和必要的人工编辑,作为质量保障的最后一道防线。
整个采集流程从运营人员在管理平台下发任务开始,到采集人员领取任务、采集数据、回传资料,再到系统自动化审核、人工抽检、推送生产,最后由运营人员完成用户结算,形成了一个从任务生成到价值实现的全生命周期闭环管理,确保了数据采集的高效、高质量和流程可控。
图文生产
图文引导旨在解决点到点之间的路径引导,用于解决进出站/换乘过程中寻路困难的问题。基于采集回传的音视频资料,结合语音、视觉和多模态大模型等多方面的技术能力,产出了包括引导场景图片、引导文案、转向动作箭头指引、引导牌标识等多要素的引导图文信息。

图四 引导图流程示意图
视频自动选帧
自动化选帧
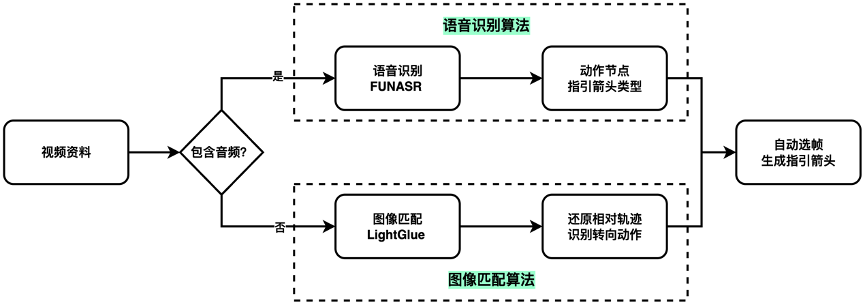
图五 自动化选帧流程图
通过语音和动作识别结果直接获取得关键帧很多是模糊或者失焦,为保证图片效果需要选取清晰、视角正、视野大的图片。效果如图六所示。
清晰度判断
利用经典的 Tenengrad和滑动窗口算法从视频中筛选相对清晰的图片。其核心原理是,图像越清晰,边缘就越锐利,梯度值也越大。具体流程为:首先计算每一帧图像的梯度幅值均值作为其清晰度得分,然后通过一个30帧的滑动窗口,在窗口内选出得分最高(即最清晰)的那一帧。这种方式能有效剔除明显模糊的帧,并确保选中的是邻近帧中的相对最佳图片,但无法保证绝对清晰度,尤其在整段视频都模糊的情况下。
视角正&视野大
视角和视野的判断,基本都需要一些画面语义理解,纯依赖视觉算法比较会有不足。主要使用Qwen-VL 筛选。

图六 选帧效果对比图
引导信息生成
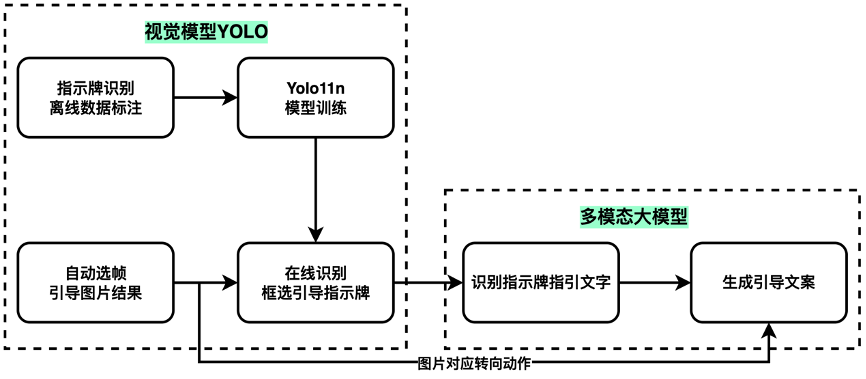
图七 引导信息生成流程图
人物擦除
采集回传的资料中普遍存在有人的情况,为保证图片效果需要在保证图片语义的同时将人擦除掉。传统的图像擦除技术在处理在人物较多、背景较复杂的情况时,效果不佳、易产生伪影和黑块。传统擦除效果如图所示,在此基础上利用 ComfyUI、SAM 和Kontext-Dev 等最新开源模型搭建了一套人物擦除体系。
方案设计,如图八所示:
1.使用Segment-Anything对原始图片进行语义分割,生成人物、背包、行李箱等擦除区域蒙版。
2.使用 Kontext-Dev 对蒙版区域进行局部重绘,尽量使修改区域限制在蒙版区域内以保证语义和细节不丢失。因为每张图片所处的场景不同,使用 Qwen-72B-VL 针对每张图实时生成 Kontext-Dev 使用得正向提示词。
3.在提示词中要求画面亮度、色彩微调。
4.使用ComfyUI进行流程驱动。
擦除效果对比如图九所示:

图八 ComfyUI局部重绘流程图

图九 人物擦除效果对比
数据发布
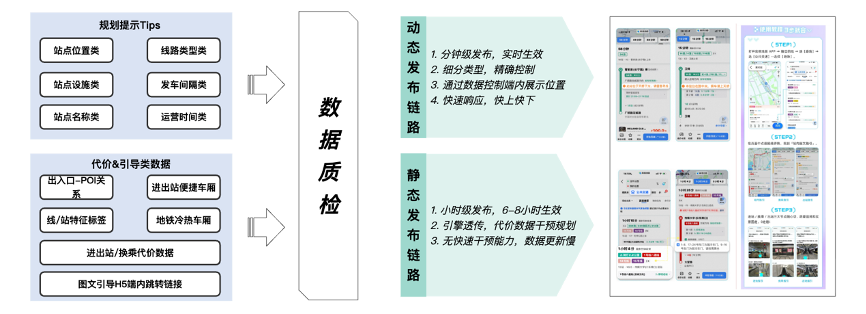
图十 数据发布示意图
四、成果
在大家的共同努力与支持下,我们的【地铁站内图文引导项目】已顺利完成并正式上线/发布!
内容全面覆盖
全面覆盖地铁站内进站、出站、换乘等场景,精准呈现超4万条通行路径,让乘客在复杂站点也能轻松导航。
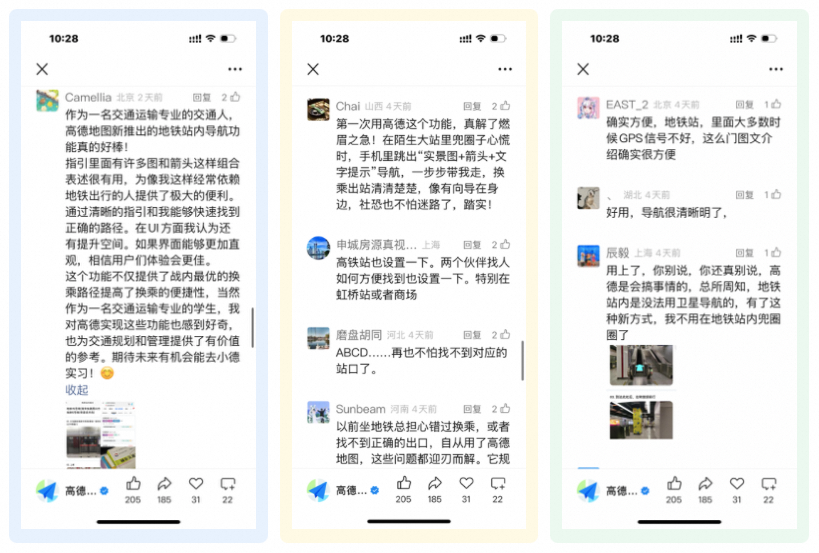
用户反馈积极
我们怀着忐忑的心情推出产品,却意外收获了众多用户真诚的好评。每一条肯定都让我们倍感惊喜与感动,也更加坚定了我们持续优化、用心做事的初心。
Qwen-Image,生图告别文字乱码
针对AI绘画文字生成不准确的普遍痛点,本方案搭载业界领先的Qwen-Image系列模型,提供精准的图文生成和图像编辑能力,助您轻松创作清晰美观的中英文海报、Logo与创意图。此外,本方案还支持一键图生视频,为内容创作全面赋能。
点击阅读原文查看详情。