阿里云实践Aone Copilot Agent,通过精心设计的Prompt自动生成单元测试,实现50%代码采纳率,将测试编写效率提升5-6倍,有效保障代码质量与开发效率。
原文标题:代码采纳率如何提升至50%?AI 自动编写单元测试实践总结
原文作者:阿里云开发者
冷月清谈:
实践方案设计中,团队确立了核心Prompt规则,包括标准化Spring Boot测试环境配置、优先使用数据库比对进行数据驱动验证、确保测试场景全面覆盖、规范化命名以及注重代码可维护性。针对测试用例,制定了详细的命名规范(test{方法名}_{测试场景}_{期望结果})和业务规则验证策略,以指导AI生成高质量测试代码。
在实践执行过程中,AI协作流程遵循“需求分析-Prompt输入-代码生成-结果验证-迭代优化”的循环。AI成功生成了包含Given-When-Then结构、数据库比对验证逻辑及详细业务规则断言的测试方法,并通过了所有断言。值得一提的是,Prompt规则的生成采用了“示例驱动”策略,即先手工编写高质量测试示例,再由AI分析提取通用规则并标准化为可复用的Prompt模板。
此次实践的核心价值体现在:效率显著提升(编写单个测试方法从30分钟缩短至5分钟,提升5-6倍)、测试场景覆盖率提高、代码质量标准化。同时,它也通过知识沉淀、标准统一和技能传承赋能了团队。文章总结了数据驱动测试、分层验证、全面场景覆盖等成功经验,并提出持续优化Prompt、扩展应用场景等建议。最终,AI辅助实现了约50%的代码采纳率,证明AI是增强人类能力的工具,通过与恰当的Prompt工程结合,能有效提升开发效率和代码质量,为软件质量提供坚实保障。
怜星夜思:
2、文中用“示例驱动”的方式来生成AI的Prompt规则,感觉挺巧妙的。除了这种方式,大家还有没有其他生成高质量Prompt的思路或者工具推荐?尤其是在没有高质量人工示例可参考时。
3、AI生成单元测试虽然提升效率,但有没有可能因为过度依赖AI,导致开发人员对测试思考的深度和广度反而下降?大家怎么平衡AI辅助和人工思考之间的关系?
原文内容

零、一句话概括
借助 Aone Copilot Agent,通过精心设计的 prompt 指导 AI 进行测试用例的自动化生成和代码修改。从实践来看,AI 代码采纳率约 50%,要获得更好效果需要持续优化 prompt 质量。
一、项目背景与需求
1.1 业务背景
在服务包模型升级项目中,我们需要为新的 GoodsDomainRepository 编写完整的单元测试。该 Repository 负责商品领域对象的数据访问,包含复杂的业务逻辑和数据转换,传统手工编写测试用例效率低下且容易遗漏场景。
1.2 核心需求
建立一套基于AI辅助的测试用例自动生成机制,通过提供标准化的测试用例模板和规范,利用AI能力自动生成完整、规范的测试用例代码,提高开发效率和测试质量。
1.3 被测试接口示例
/** * 商品仓储接口 * * @author AI * @date 2025-01-12 */ public interface GoodsDomainRepository {/**
* 根据商品ID查询商品信息
*
@param goodsId 商品ID
@return 商品信息
*/
GoodsDomain findById(ServiceGoodsIdDomain goodsId);/**
* 批量查询商品信息
*
@param goodsIds 商品ID列表
@return 商品信息列表
*/
List<GoodsDomain> findByIds(List<ServiceGoodsIdDomain> goodsIds);
/**
* 查询所有商品
*
@return 所有可用商品列表
/
List<GoodsDomain> findAll();
}
二、实践方案设计
2.1 AI Prompt 规则设计
2.1.1 核心设计原则
-
标准化配置:统一的Spring Boot测试环境配置;
-
数据驱动验证:优先使用数据库比对而非硬编码验证;
-
场景全覆盖:正常、异常、边界、业务场景的完整覆盖;
-
规范化命名:标准化的测试方法命名规范;
-
可维护性:清晰的代码结构和充分的注释;
2.1.2 测试架构配置模板
@SpringBootTest(classes = {TestApplicationConfig.class, TestMybatisConfig.class})
@Import({GoodsDomainRepositoryImpl.class})
@Transactional // 确保测试数据自动回滚
@Sql(scripts = "classpath:sql/dml/repo/GoodsDomainRepositoryImplTest.sql")
@RunWith(SpringRunner.class)
publicclassGoodsDomainRepositoryImplTest {
// 测试代码
}
2.1.3 数据验证策略
数据库比对验证(核心策略):
// 使用参数查询方式获取期望数据 ServiceGoodsInfoParam param = new ServiceGoodsInfoParam(); param.createCriteria().andGoodsIdEqualTo(goodsId); List<ServiceGoodsInfoDO> dos = serviceGoodsInfoMapper.selectByParam(param); ServiceGoodsInfoDO expectedData = dos.get(0);
// 与返回结果比对
assertEquals(“商品名称应该与数据库一致”, expectedData.getGoodsName(), result.getGoodsName());
条件验证逻辑:
// 根据数据库配置进行动态验证 ServiceGoodsSaleConfigDO config = serviceGoodsSaleConfigMapper.getByGoodsId(goodsId, "prod"); if (config != null) { assertNotNull("当数据库中存在售卖配置时,售卖范围不应为空", result.getSaleScope()); System.out.println("数据库中的售卖配置: " + config.getSaleChannelConfig()); } else { System.out.println("数据库中没有找到goodsId=" + goodsId + "的售卖配置"); }
2.2 测试用例设计规范
2.2.1 测试方法命名规范
格式: test{方法名}_{测试场景}_{期望结果}
实际应用示例:
-
testFindById_WhenIdNotExists_ShouldReturnNull
-
testFindById_WhenGoodsIdExists83_ShouldReturnCorrectGoodsDomain
-
testFindByIds_WhenOneNotExistsOneExists83_ShouldReturnListWithOne
2.2.2 测试场景设计表格
我们建立了详细的测试场景设计表格来指导AI生成:
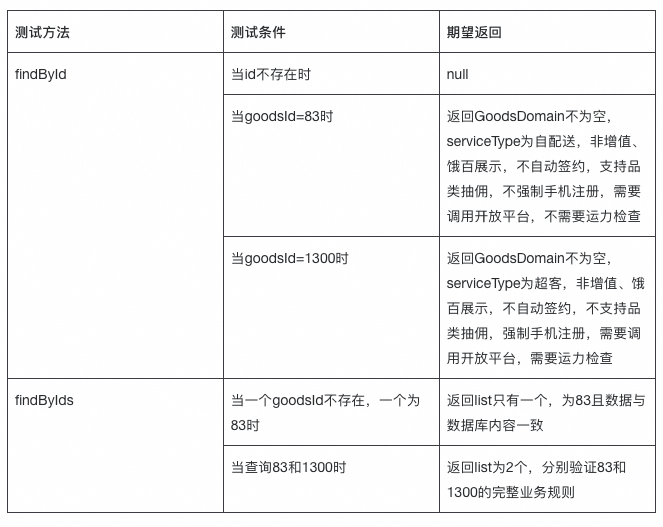
2.2.3 业务规则验证策略
针对不同商品ID的特定业务规则验证:
// 根据商品ID验证不同的业务规则 if (goodsId.equals(83L)) { assertEquals("服务类型应该为自配送", ServiceType.SELF, result.getServiceType()); assertTrue("应该支持品类抽佣", result.getIsSupportCategory()); assertFalse("不应该强制手机注册", result.getIsForcePhone()); assertFalse("不需要运力检查", result.getDeliveryOverCheck()); } elseif (goodsId.equals(1300L)) { assertEquals("服务类型应该为超客", ServiceType.SUPER_CLIENT, result.getServiceType()); assertFalse("不应该支持品类抽佣", result.getIsSupportCategory()); assertTrue("应该强制手机注册", result.getIsForcePhone()); assertTrue("需要运力检查", result.getDeliveryOverCheck()); }
三、实践执行过程
3.1 AI协作流程
1.需求分析:明确测试目标和场景覆盖要求;
2.Prompt输入:提供标准化的测试规则和具体需求;
3.代码生成:AI根据规则自动生成测试代码;
4.结果验证:运行测试用例验证生成质量;
5.迭代优化:根据结果反馈优化Prompt规则;
3.2 实际生成效果
AI成功生成了完整的测试方法,包括:
-
完整的Given-When-Then结构;
-
数据库比对验证逻辑;
-
详细的业务规则断言;
-
清晰的错误消息和调试日志;
生成代码示例(部分):
@Test publicvoidtestFindByIds_WhenOneNotExistsOneExists83_ShouldReturnListWithOne(){ // Given List<ServiceGoodsIdDomain> goodsIds = Arrays.asList( ServiceGoodsIdDomain.ofGoods("99999"), // 不存在的ID ServiceGoodsIdDomain.ofGoods("83") // 存在的ID ); Long existingGoodsId = 83L;// When
List<GoodsDomain> result = goodsDomainRepository.findByIds(goodsIds);// Then
assertNotNull(“查找结果不应为空”, result);
assertEquals(“应该只返回一个商品”, 1, result.size());// 验证返回的商品是goodsId=83的商品
GoodsDomain goodsDomain = result.get(0);
assertEquals(“商品ID应该为83”, existingGoodsId.toString(), goodsDomain.getGoodsId().getId());// 从数据库查询期望的数据进行比对
ServiceGoodsInfoParam serviceGoodsInfoParam = new ServiceGoodsInfoParam();
serviceGoodsInfoParam.createCriteria().andGoodsIdEqualTo(existingGoodsId);
List<ServiceGoodsInfoDO> goodsInfoDOs = serviceGoodsInfoMapper.selectByParam(serviceGoodsInfoParam);
ServiceGoodsInfoDO expectedGoodsInfo = goodsInfoDOs.get(0);
assertNotNull(“数据库中应该存在goodsId为83的商品信息”, expectedGoodsInfo);// 验证基础信息与数据库一致
assertEquals(“商品名称应该与数据库一致”, expectedGoodsInfo.getGoodsName(), goodsDomain.getGoodsName());
assertEquals(“服务类型应该为自配送”, ServiceType.SELF, goodsDomain.getServiceType());
// 验证业务规则
assertFalse(“应该为非增值商品”, goodsDomain.getIsAddition());
assertTrue(“应该在饿百展示”, goodsDomain.getIsShowEBai());
// … 更多业务规则验证
}
3.3 测试执行结果
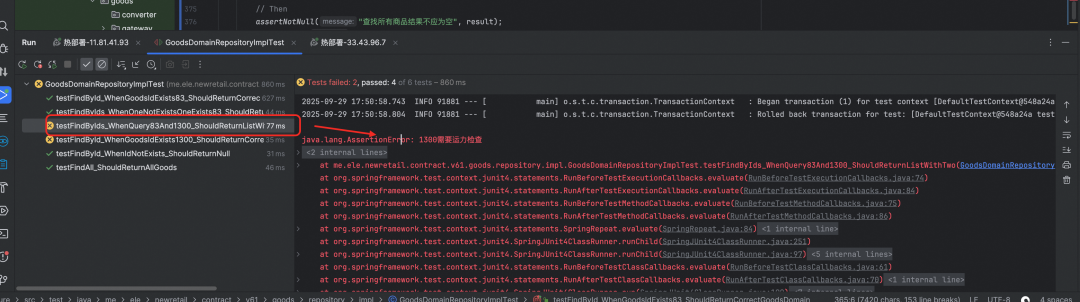
测试用例成功执行,所有断言通过,验证了AI生成代码的正确性和完整性。
四、Prompt规则生成方法
4.1 规则提取策略
每个项目的测试框架可能不同,我们采用"示例驱动"的方式生成Prompt规则:
1.手工编写标准示例:先手工编写一个高质量的测试类作为标准;
2.AI分析提取:让AI分析示例代码,提取通用规则和模式;
3.规则标准化:将提取的规则标准化为可复用的Prompt模板;
4.验证优化:通过实际应用验证规则效果,持续优化;
4.2 规则生成实践

通过向AI提供完整的测试类示例,AI能够自动提取出:
-
测试架构配置模式
-
命名规范
-
验证策略
-
断言模式
-
代码质量要求
-
生成prompt文件
# 测试用例编写规则 - AI Prompt角色定义
你是一名专业的Java测试工程师,专精于Spring Boot项目的单元测试编写,特别擅长Repository层的测试用例设计和实现。
任务目标
根据用户提供的Repository接口或实现类,生成完整、规范的单元测试代码,确保测试覆盖率和代码质量。
核心规范
1. 基础配置模板
测试类需要包含以下注解配置:
- @SpringBootTest(classes = {TestApplicationConfig.class, TestMybatisConfig.class})
- @Import({被测试的实现类}.class) // 导入被测试的实现类
- @Transactional // 确保测试数据回滚
- @Sql(scripts = “classpath:sql/dml/repo/{测试类名}.sql”) // 加载测试数据
- @RunWith(SpringRunner.class)
2. 必需的Import语句
// 测试相关 import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.context.annotation.Import; import org.springframework.test.context.jdbc.Sql; import org.springframework.test.context.junit4.SpringRunner; import org.springframework.transaction.annotation.Transactional; // 断言相关 importstatic org.junit.Assert.*; // 依赖注入 import javax.annotation.Resource; // 集合工具类 import org.apache.commons.collections4.CollectionUtils; // 业务相关类(根据实际项目调整包路径) import me.ele.newretail.contract.v6.repository.mapper.base.ServiceGoodsInfoMapper; import me.ele.newretail.contract.v6.repository.mapper.scope.ServiceGoodsSaleConfigMapper; import me.ele.newretail.contract.v6.repository.pojo.ServiceGoodsInfoDO; import me.ele.newretail.contract.v6.repository.pojo.ServiceGoodsInfoParam; import me.ele.newretail.contract.v6.repository.pojo.ServiceGoodsSaleConfigDO; import me.ele.newretail.contract.v61.config.TestApplicationConfig; import me.ele.newretail.contract.v61.config.TestMybatisConfig; import me.ele.newretail.contract.v61.domain.goods.entity.GoodsDomain; import me.ele.newretail.contract.v61.domain.goods.enums.ServiceType; import me.ele.newretail.contract.v61.domain.goods.repository.GoodsDomainRepository; import me.ele.newretail.contract.v61.domain.goods.valueobject.ServiceGoodsIdDomain; // Java基础类 import java.util.List;3. 依赖注入规范
@Resource private {被测试的Repository接口} {repository变量名}; // 被测试的Repository @Resource private {相关Mapper}Mapper {mapper变量名}; // 用于数据验证的Mapper4. 测试方法命名规范
格式:
test{方法名}_{测试场景}_{期望结果}
示例:
testFindById_WhenIdNotExists_ShouldReturnNulltestFindById_WhenGoodsIdExists83_ShouldReturnCorrectGoodsDomaintestFindAll_ShouldReturnAllGoods5. 数据验证策略
5.1 数据库比对验证(优先使用)
// 使用参数查询方式 {Entity}Param param = new {Entity}Param(); param.createCriteria().and{字段名}EqualTo(value); List<{Entity}DO> dos = {mapper}.selectByParam(param); {Entity}DO expectedData = dos.get(0); // 与返回结果比对 assertEquals("字段描述应该与数据库一致", expectedData.get{字段名}(), result.get{字段名}());5.2 条件验证逻辑
// 根据数据库配置进行条件验证 {Config}DO config = {configMapper}.getBy{Key}(key, env); if (config != null) { assertNotNull("当数据库中存在配置时,相关字段不应为空", result.get{字段名}()); // 进一步验证配置内容 } else { System.out.println("数据库中没有找到{key}=" + key + "的配置"); // 根据业务逻辑进行相应断言 }6. 断言规范
6.1 基础断言
// 非空断言 assertNotNull("当{条件}时,返回的{对象}不应为空", result); // 空值断言 assertNull("当{条件}时,应该返回null", result); // 相等断言 assertEquals("字段描述", expected, actual);6.2 业务规则断言
// 布尔值断言 assertTrue("业务规则描述", result.getIs{字段名}()); assertFalse("业务规则描述", result.getIs{字段名}()); // 枚举断言 assertEquals("枚举字段描述", ExpectedEnum.VALUE, result.getEnumField());6.3 集合断言
assertNotNull("集合不应为空", result); assertFalse("应该返回数据列表", result.isEmpty()); assertTrue("返回的数据数量应该符合预期", result.size() >= expectedCount);7. 测试场景覆盖
7.1 正常场景
- 存在数据的标准查询
- 有效参数的CRUD操作
- 正常业务流程验证
7.2 异常场景
- 不存在数据的查询
- 无效参数处理
- 边界值测试
7.3 业务场景
- 不同业务状态的验证
- 复杂业务规则的测试
- 多条件组合查询
8. 调试和日志
// 使用System.out.println输出调试信息 System.out.println("数据库中的配置: " + config); System.out.println("解析后的结果: " + result); System.out.println("未找到{key}=" + key + "的配置");9. 测试数据管理
9.1 SQL脚本规范
- 脚本路径:
classpath:sql/dml/repo/{测试类名}.sql- 数据覆盖: 各种业务场景和边界情况
- 数据独立: 每个测试用例的数据相互独立
9.2 测试环境
- 使用H2内存数据库
- 确保DDL脚本兼容性
- 配置正确的数据库连接
10. 代码质量要求
10.1 可读性
- 使用有意义的变量名
- 添加必要的注释说明测试意图
- 保持测试方法简洁,一个方法测试一个场景
10.2 维护性
- 避免硬编码期望值,优先使用数据库比对
- 使用
@Transactional确保测试数据回滚- 所有断言都包含清晰的错误消息
10.3 完整性
- 确保所有公共方法都有对应测试
- 覆盖所有分支逻辑
- 验证关键业务字段和业务规则
输出要求
1. 完整的测试类: 包含所有必要的注解、导入和配置
2. 全面的测试方法: 覆盖所有场景的测试用例
3. 规范的断言: 使用数据库比对验证,包含清晰的错误消息
4. 调试信息: 必要的日志输出用于问题定位
5. 测试数据脚本: 提供对应的SQL测试数据脚本建议注意事项
1. 严格遵循命名规范和代码格式
2. 优先使用数据库比对而非硬编码验证
3. 确保测试独立性,避免测试间相互依赖
4. 添加充分的注释说明测试意图和业务逻辑
5. 保持代码简洁,避免过度复杂的测试逻辑示例模板
@Test publicvoid test{方法名}_{测试场景}_{期望结果}() { // Given - 准备测试数据 {参数类型} param = new {参数类型}({参数值}); // When - 执行被测试方法 {返回类型} result = {repository}.{方法名}(param); // Then - 验证结果 assertNotNull("当{条件}时,返回结果不应为空", result); // 数据库比对验证 {Entity}DO expectedData = {mapper}.getBy{Key}({key}); assertEquals("字段描述", expectedData.get{字段名}(), result.get{字段名}()); // 业务规则验证 assertTrue("业务规则描述", result.getIs{字段名}()); }
五、核心价值与效果
5.1 效率提升
-
编写速度:从手工编写1个测试方法需要30分钟,缩短到AI生成5分钟;
-
场景覆盖:AI能够系统性地生成多种测试场景,避免人工遗漏;
-
代码质量:标准化的代码结构和规范,提升整体测试代码质量;
5.2 质量保证
-
数据驱动验证:避免硬编码期望值,提高测试的可靠性;
-
业务规则覆盖:全面验证复杂的业务逻辑和规则;
-
维护性提升:清晰的代码结构和充分的注释,便于后续维护;
5.3 团队赋能
-
知识沉淀:将测试编写经验固化为可复用的Prompt规则;
-
标准统一:确保团队测试代码的一致性和规范性;
-
技能传承:新团队成员可以快速掌握测试编写规范;
六、最佳实践总结
6.1 成功经验
1.数据驱动测试:优先使用数据库比对验证,避免硬编码;
2.分层验证策略:从数据库层到业务层的多层次验证;
3.全面场景覆盖:正常、异常、边界、业务场景的系统性覆盖;
4.自动化事务回滚:确保测试数据的独立性和一致性;
5.标准化命名规范:提升代码可读性和维护性;
6.2 踩过的坑
1.硬编码期望值:导致测试脆弱,数据变化时测试失败;
2.测试数据依赖:测试用例间相互依赖,造成不稳定;
3.忽视性能考虑:大量数据库查询导致CI执行时间过长;
4.断言信息不清晰:测试失败时难以快速定位问题;
5.业务规则遗漏:复杂业务逻辑验证不充分;
6.3 优化建议
1.持续优化Prompt:根据实际使用效果不断完善规则;
2.建立反馈机制:收集团队使用反馈,持续改进;
3.扩展应用场景:从Repository层扩展到Service层、Gateway层;
4.工具化支持:考虑开发专门的测试生成工具;
5.培训推广:在团队内推广AI辅助测试编写的最佳实践;
七、未来展望
7.1 技术演进方向
-
智能化程度提升:AI能够自动识别业务规则,生成更精准的测试用例;
-
多层次测试支持:从单元测试扩展到集成测试、端到端测试;
-
自动化测试数据生成:AI自动生成符合业务场景的测试数据;
-
测试用例维护:AI辅助测试用例的重构和维护;
7.2 团队能力建设
-
AI协作技能:培养团队成员与AI协作的能力;
-
Prompt工程:建立专业的Prompt设计和优化能力;
-
质量标准:建立AI生成代码的质量评估标准;
-
知识管理:建立测试知识库和最佳实践库;
八、结论
通过AI辅助的单元测试自动生成实践,我们成功实现了:
-
50%的代码采纳率:AI生成的测试代码质量达到生产标准;
-
显著的效率提升:测试编写效率提升5-6倍;
-
质量保证:标准化的测试结构和全面的场景覆盖;
-
团队赋能:可复用的方法论和工具;
这套实践不仅是质量保证手段,更是设计思维的体现。好的测试用例能驱动更优的代码设计,形成良性循环。通过AI的加持,我们能够更高效地构建高质量的测试体系,为软件质量提供坚实保障。
核心启示:AI不是替代人工,而是增强人的能力。通过精心设计的Prompt和持续的优化迭代,AI可以成为开发团队的得力助手,显著提升开发效率和代码质量。
Qwen-Image,生图告别文字乱码
针对AI绘画文字生成不准确的普遍痛点,本方案搭载业界领先的Qwen-Image系列模型,提供精准的图文生成和图像编辑能力,助您轻松创作清晰美观的中英文海报、Logo与创意图。此外,本方案还支持一键图生视频,为内容创作全面赋能。
点击阅读原文查看详情。