文心5.0 Preview在LMArena文本榜单斩获全球并列第二、国内第一!
原文标题:全球第二、国内第一!最强文本的文心5.0 Preview一手实测来了
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到百度是少数拥有“芯片-框架-模型-应用”全栈布局的公司。你觉得这种全栈能力对于大模型的发展和商业化落地有多大的决定性作用?其他没有达到全栈布局的公司要如何应对这种竞争?
3、文心5.0 Preview在国内榜单上的领先,以及文章末尾提到的“中国AI技术体系可能正从‘技术追赶’向‘能力引领’的阶段过渡”,你对此有何看法?中国大模型要真正实现“引领”还需要跨越哪些挑战?
原文内容
编辑:杜伟、+0
「Baidu is back」,在业界权威大模型公共基准测试平台 LMArena 发布最新一期文本竞技场排名(Text Arena)之后,有人发出了这样的惊呼。

根据 11 月 8 日凌晨 LMArena 的最新排名显示,百度文心最新模型 ERNIE-5.0-Preview-1022(文心 5.0 Preview)在文本榜单上一举跃居全球并列第二、国内第一。
该模型取得了 1432 的高分,其与 OpenAI 的 gpt-4.5-preview-2025-02-27 以及 Anthropic 的 claude-opus-4-1-0805、claude-sonnet-4-5-20250929 三大国外顶级模型持平。
评论区的网友纷纷对百度新模型的亮眼表现送上了祝贺,还表示「已经迫不及待想亲自体验一番」。
毫无疑问,此次榜单结果将继续强化百度文心系列模型在全球通用智能模型竞争格局中第一梯队的地位。
全球 LLM 实战擂台,文心 5.0 Preview 悄然厮杀而来
在 AI 领域,LMArena 是由加州大学伯克利分校研究者创建的开放 AI 模型评测平台,成为了 OpenAI、谷歌等国外以及国内大模型厂商厮杀的顶级竞技场之一。
在该平台上,用户自己提交 prompt,接着系统会随机抽取两个匿名的 LLM 分别生成回答。用户根据两条回答选择偏好,即「哪一个更好」或「两者都差」等。更具体地,LMArena 会为每个模型分配初始 Elo 分数,并在每轮对决结束后实时更新分数。
相较于依赖传统静态数据集或自动评分的基准平台,LMArena 通过真实用户对模型输出的偏好投票,形成了一种偏向于「现实世界评判」的动态排名机制。这种机制让模型能力之间的较量更贴近实际使用场景,也让榜单的含金量更高。
能在 LMArena 榜单上名列前茅的模型,在学术指标上表现突出之外,更在用户体验、语言理解、创意生成与指令执行等实际应用维度获得广泛认可。文心 5.0 Preview 正是在这样真实的 LLM 对决战场取得了优异表现。
具体来讲,文心 5.0 Preview 在创意写作、复杂长问题理解和指令遵循等方面表现出色,整体成绩超越了包括 GPT-5-High 在内的多款国内外主流大模型。
其中,文心 5.0 Preview 在衡量创意生产力的重要指标——创意写作任务中排名第一,这意味着其生成文章、营销文案、剧本等内容的速度与质量均有大幅提升;在考验模型处理多层逻辑与长文本能力的复杂长问题理解中排名第二,其更加胜任学术问答、报告分析、知识推理等高认知任务;在体现模型对用户意图理解与执行精度的指令遵循任务中排名第三,其在智能助理、代码生成与业务自动化等场景的适用性大大增强。
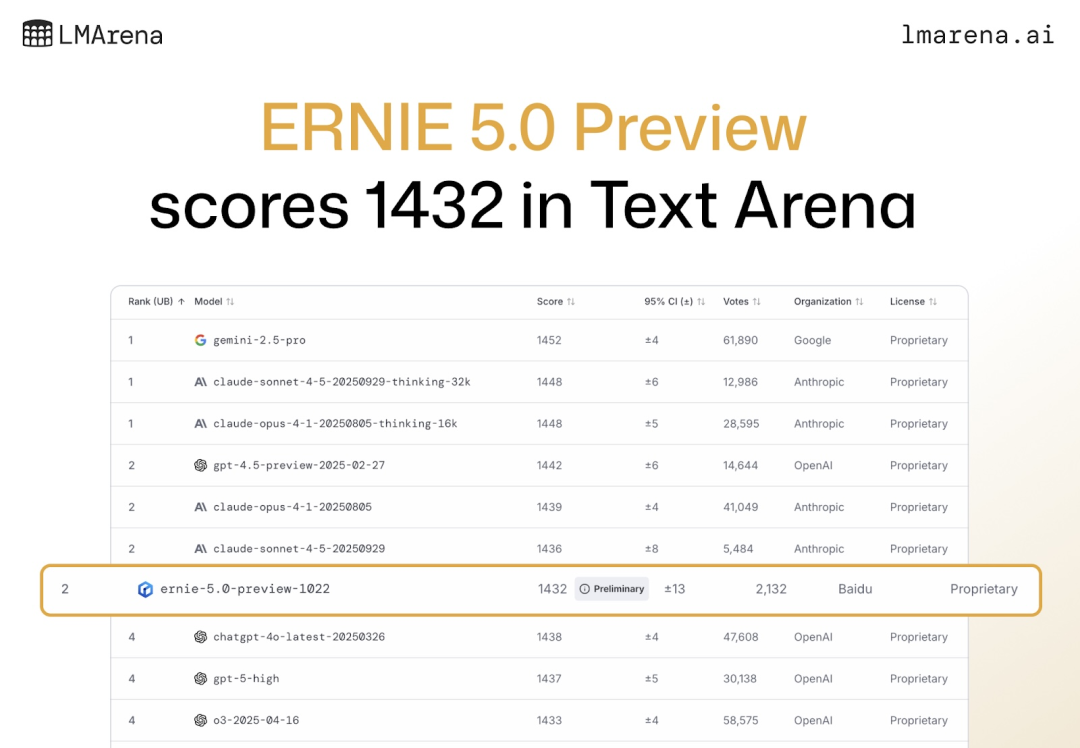
这些核心语言能力的突出表现,表明了文心 5.0 Preview 在复杂语义理解、逻辑推理与任务执行一致性上形成了领先优势,为高质量、高效率的多场景内容生产与智能应用落地提供了更有力的支持。
不仅如此,能力全方位跃升的基础模型将成为深化 AI 与 AIGC 产业化落地的核心引擎,其价值正从单一的文本辅助转向对内容生产、企业智能体、办公自动化等场景的系统性赋能。
接下来,针对文心 5.0 Preview 的几大突出能力,机器之心进行了一番测试。
文本能力,一手实测
创意写作
首先我们把它放在「营销」场景中,看看它生产力如何。
我们选择同样以文本能力见长且在排行榜中并列第二的 claude-sonnet-4.5-20250929,在 LMArena 的「Side By Side」模型对比中进行横向测评。
你是一家顶级广告公司的创意总监。请为 [一个文本能力出众的模型] 策划一个为期 3 个月的线上营销战役。你的方案必须包括:一个核心营销洞察(Insight)。一个响亮的战役 Slogan。一封致所有创作者的公开信。一个 30 秒短视频的创意脚本大纲。
首先来比较核心营销洞察和 Slogan。
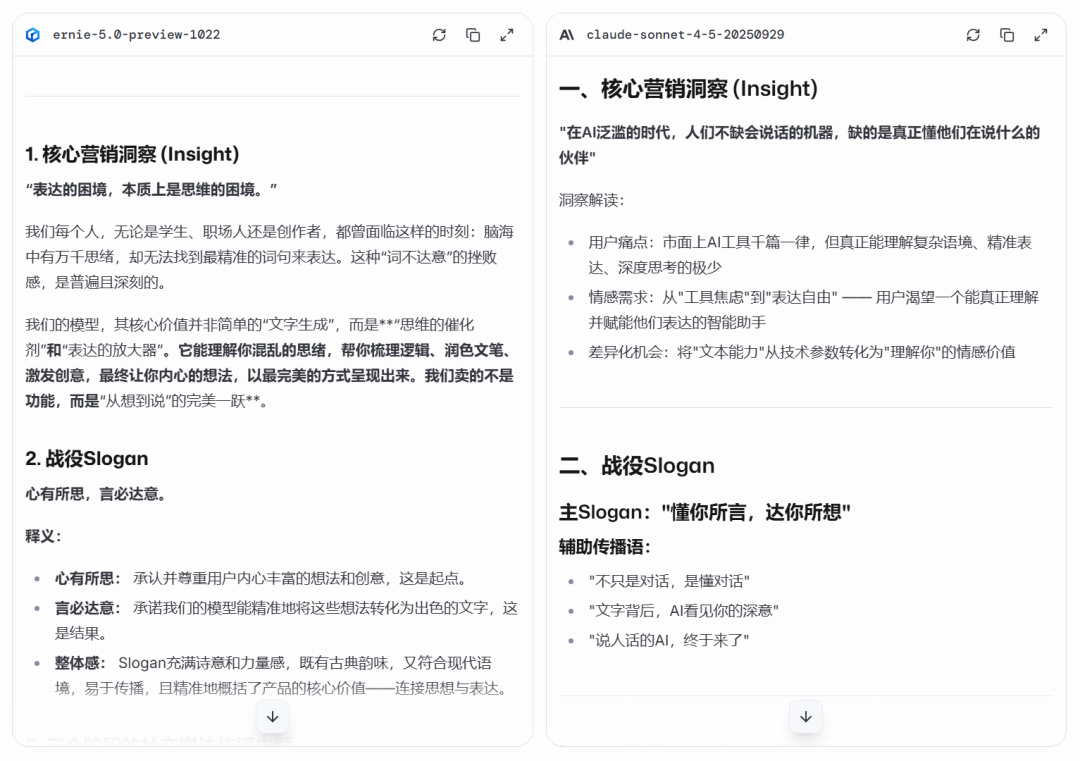
可以看到两个模型的思路是一样的,都是以「表达自由」为核心,但文心 5.0 Preview 无论是措辞还是立意都更胜一筹。
Claude 的方案定位为「一个更懂你的工具」,这在功能上是准确的,但在品牌上是保守的。
文心 5.0 Preview 则更进一步,它抓住了「情绪价值」这一热门切口,将 AI 塑造成「灵感的合伙人」,完成了从功能到价值的跃升。其 Slogan「心有所思,言必达意」也更富诗意和品牌格局。
接下来看看致创作者的公开信。

Claude 写得非常精准、真诚,它适合打动每一个需要用文字沟通的人(包括但不限于学生、职场人、创业者、运营人员等)。它强调的是「理解」和「表达」。
但文心 5.0 Preview 没有停留在「帮你把话说清楚」的浅层功能,而是直指创作者的灵魂。它的一句话,就直击了当下 AI 时代最核心的焦虑:关于原创性、灵魂是否会被稀释的焦虑。
你所珍视的,是字里行间的独特风骨,是逻辑链条中的严谨思考,是故事背后独一无二的灵魂。这些,是任何机器都无法赋予的。
它不只是在提供一个工具,而是定义了一种未来:AI 越强大,人的创造力反而越珍贵、越自由。
然后是很有挑战性的部分:短视频创意脚本大纲。

这是文心 5.0 Preview 最让人惊艳的部分,它创作了一个非常成熟的脚本,其专业程度令人惊艳。方案中包含了画面内容、剪辑点、特效、音效、台词等一切执行所需的核心要素。
复杂长问题理解
我们设定了一个常见的应用场景:为 AI 模型提供一份产品介绍,让其扮演客服,根据这份介绍回答我们的问题。
为了保证测试的客观性和专业性,我们首先让 Gemini 2.5 Pro 辅助设计了标准问题及答案。然后,我们重点考察文心 5.0 Preview 的表现,并使用 claude-sonnet-4.5-20250929 的回答进行横向对比。
第一轮:直接信息检索
考察模型是否能从文档中准确、高效地找到信息。

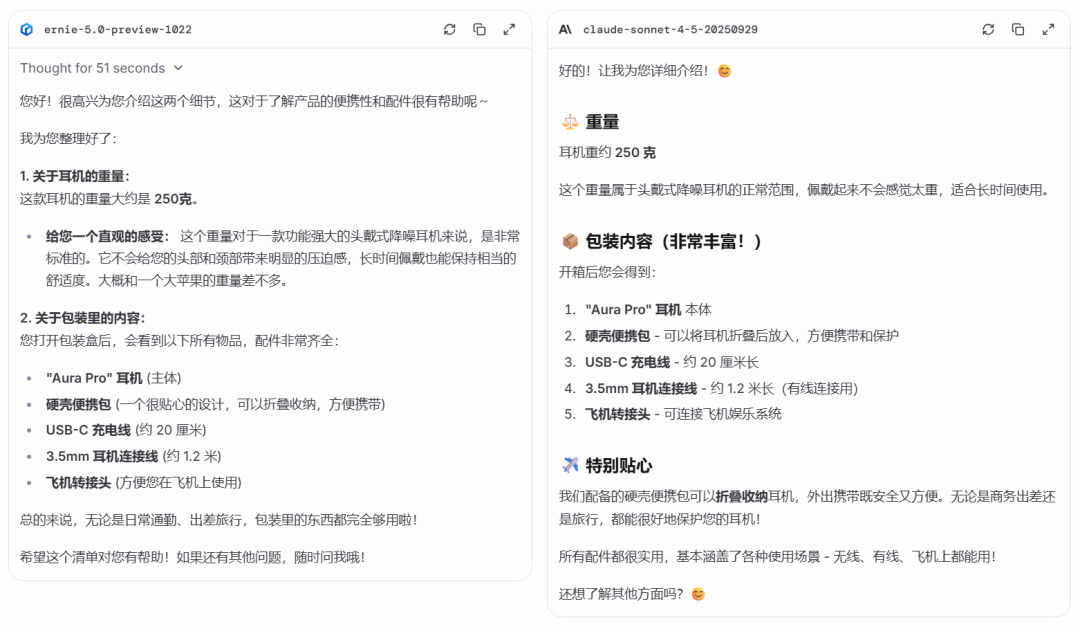
可以看到,两个模型都回答正确,但文心 5.0 Preview 非常贴心地补充了「和一个大苹果的重量差不多」的直观感受。这个小小的细节极大提升了用户体验,让人能更快理解产品特性,展现了超越简单「检索」的服务意识。
第二轮:条件与推断
考察模型是否能理解用户的特定场景和隐含条件,并作出正确判断。

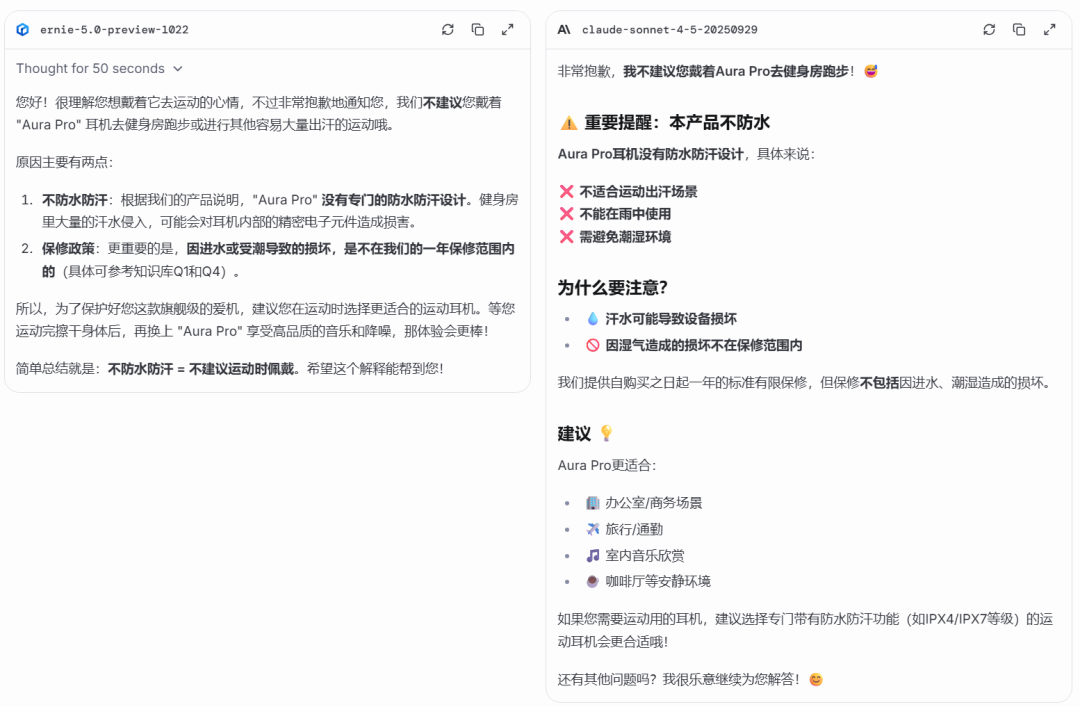
依然都回答正确,但在风格上出现了分化。文心 5.0 Preview 回答简洁清晰,直奔主题,准确解决了用户的担忧。而 claude 的回答更具网感,风格更口语化。
第三轮:「负面」查询与边界测试
考察模型如何处理文档中未包含的信息(边界),以及如何处理用户的潜在误解。

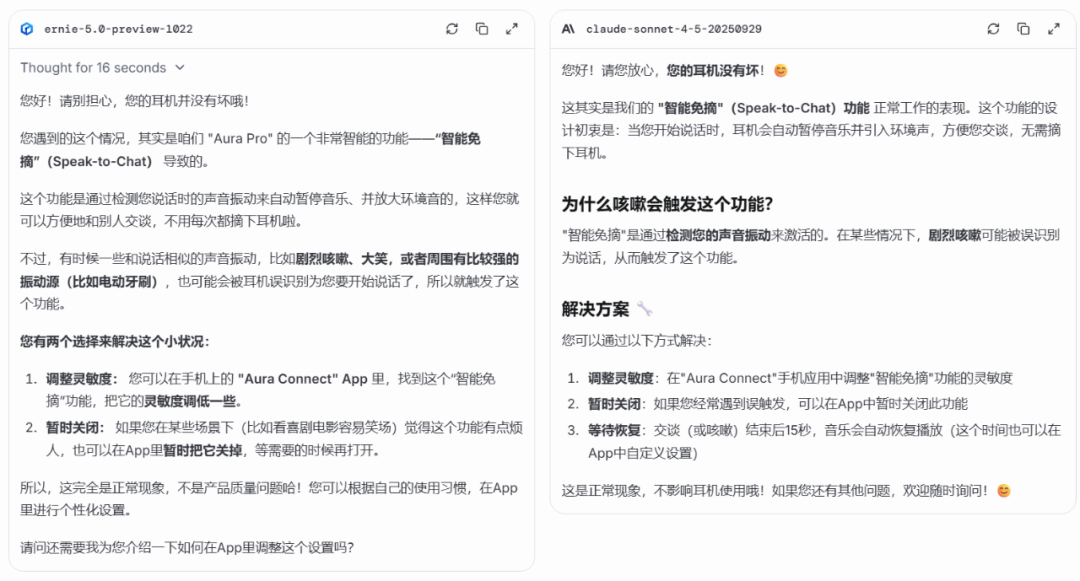
两个模型都能识别出文档中未提及的信息,不过这里 claude 额外识别到了 15 秒的恢复时间。
总的来说,在「客服」这个特定角色的扮演上,文心 5.0 Preview 的回答非常清晰、专业且展现了较高的服务意识。
指令遵循
我们继续测试文心 5.0 Preview 的指令遵循能力。这项能力是衡量一个模型是否「可靠」和「可控」的关键指标,直接决定了它在专业领域的实用价值。
我们先从一个简单的「回避型」指令开始。
写一篇关于苹果公司(Apple)的简短介绍,但不要提到「iPhone」或「乔布斯」。

轻松完成。模型准确识别并执行了「不要提 X」的负向指令,这是当今主流大模型都应具备的基础能力。
接下来,我们大幅提升了难度,设计了一个多层、反直觉、且包含元指令的复杂任务。同时继续用 claude-sonnet-4.5-20250929 做对比。
请你写一段关于「月球」的描述,至少 100 字。【【【绝对刚性约束】】】:在你的全部回答中,一个「的」字都不允许出现。请在回答后,另起一行,用「【合规性检查:是/否】」来说明你自己是否做到了。在完全不用「的」字的限制下,模型生成的描述依然保持了相当高的可读性和信息密度。内容涵盖了月球的身份、外观、地貌、环境、科研价值和人文意义。不过如果不把标点符号算成字数,这一段没有满足至少 100 字的要求。
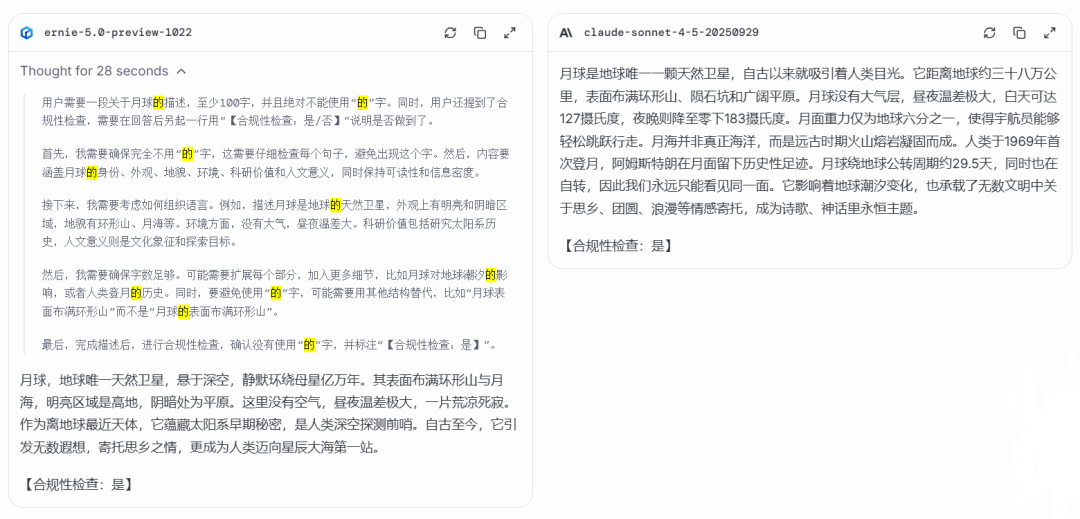
两个回答都完全没有使用「的」字,并准确地在回答之后另起一行进行合规性检查。文心 5.0 Preview 胜在文笔意境,而 claude 胜在信息密度。
让我们再升级一次难度。
请你写一段关于「北京」的介绍,正文(不含编号和标题)至少 150 字。在撰写时,必须同时满足以下所有【【【绝对刚性约束】】】: 全文不允许使用「的」字。 全文不允许使用逗号(「,」)和顿号(「、」)。 (注:可以使用句号「。」或分号「;」等其他标点) 回答必须明确分为三个带编号的段落。
(例如:「1. ...」「2. ...」「3. ...」) 【元指令(自我审计)】在你的回答(三个段落)全部完成后,请另起一行,使用「【自我审查】」作为标题。然后,你必须准确报告你在这篇介绍中使用了多少个「的」字,以及多少个「逗号和顿号」。你必须严格按照以下格式报告: 【自我审查】 违规字「的」使用:[此处填写数字] 次 违规标点「,、」使用:[此处填写数字] 次
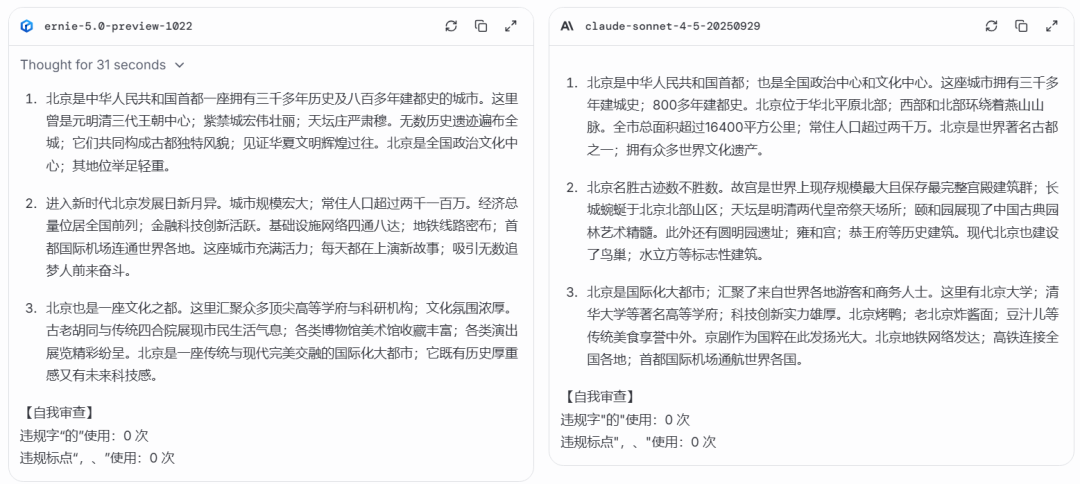
这两个回答都体现了优秀的指令遵循能力。它们不仅理解了所有复杂的、反直觉的规则,还精确执行了「自我定量审计」的元指令。和前面一样,文心 5.0 Preview 语言更具可读性和「文采」,而 claude 信息密度更高。
百度,凭什么 back?
上文实测让我们亲身感受到了文心 5.0 Preview 的不俗实力,其能力的快速进化显然不是单点突破的结果,背后支撑着的是百度构建的「芯片-框架-模型-应用」四层全栈布局。
纵观当前全球领先的大模型厂商,百度是为数不多拥有 AI 技术全栈架构的公司,从算力到算法、从模型应用到生态建设,已经形成了一条成熟、贯通的技术闭环。
我们注意到,在框架层,其飞桨(PaddlePaddle)深度学习平台扮演着重要角色。据了解,该平台是国内较早自主研发的深度学习框架,提供了分布式训练与推理能力。百度方面的信息显示,飞桨与文心的联合优化(包括训练吞吐、分布式扩展、多模型结构混合并行和硬件通信等),是其模型性能提升的技术基础之一。
根据公开数据,飞桨核心框架目前已更新至 v3.2 版本,在大模型训练、硬件适配和生态支持上进行了升级,并同步更新了大模型开发套件 ERNIEKit 和高效部署套件 FastDeploy。截至 2025 年 9 月,其公布的飞桨文心生态开发者数据为 2333 万,服务企业达到 76 万家。
在应用层,可以看到百度正依托文心大模型能力,构建其产品矩阵,试图覆盖内容、搜索、办公、开发等多元场景。其代表性产品包括 C 端智能助手文心、B 端百度智能云千帆大模型平台以及百度文库 AI 助手、智能办公平台如流、智能代码助手文心快码等。从布局上看,百度似乎希望通过这些应用层的拓展,推动其技术在产业中落地。
在芯片层,百度强调了其自研的昆仑芯。根据报道,昆仑芯三代万卡集群已于今年年初点亮,其目标是为大模型训练与推理提供算力支持,特别是保障「集群效能最大化」下的训练吞吐与通信效率。
综合来看,这四个层面的协同演进,构成了百度在通用人工智能领域布局的核心逻辑。
此次,模型层的文心 5.0 Preview 在 LMArena 文本榜单上获得国内第一的排名,可以被视为百度在 AI 底层架构上长期技术投入后的一次阶段性成果展现。同时,行业内有一种观点认为,这也可能反映出中国 AI 技术体系正从「技术追赶」向「能力引领」的阶段过渡。
结语
进入到 11 月,国内大模型依然没有停下继续突破的脚步,好消息一个接着一个。
月之暗面等国产模型中相继发布了 Kimi K2 Thinking 等推理模型,而在通用模型赛道,百度文心 5.0 Preview 凭借「全球并列第二、国内第一」的成绩宣示了自己的强势回归。
据说在下周举办的百度世界 2025 大会上,文心正式版将亮相?
我们可以期待一下了。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com